GraphPINE: Graph Importance Propagation for Interpretable Drug Response Prediction
Pith reviewed 2026-05-22 20:25 UTC · model grok-4.3
The pith
GraphPINE initializes node importance from literature-curated gene graphs to make drug response predictions more interpretable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
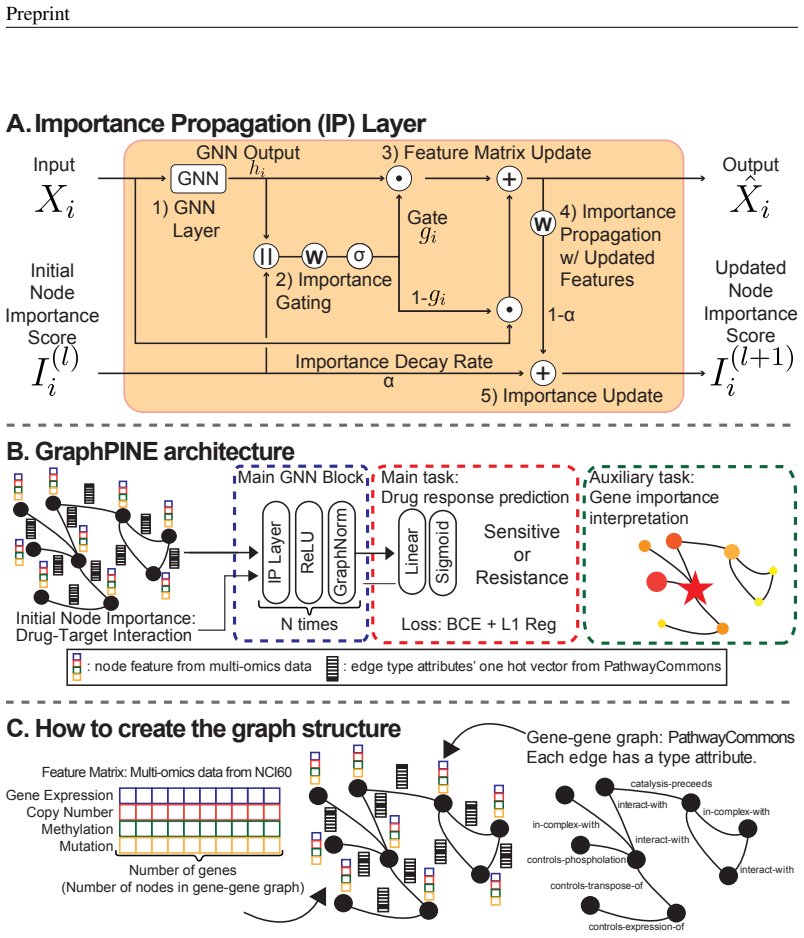
GraphPINE leverages curated gene-gene and drug-target interaction graphs, weighted by article counts, to initialize node importance for over 5,000 gene nodes. An importance propagation layer updates both the feature matrix and node importance in an LSTM-like sequential format, combining GNN-based propagation. This enables informed feature learning and yields a PR-AUC of 0.894 and ROC-AUC of 0.796 across 952 drugs for cancer drug response prediction.
What carries the argument
The importance propagation layer, which unifies updates for the feature matrix and node importance while performing GNN-based graph propagation of feature values.
If this is right
- Node importance scores incorporate prior knowledge from literature, supplying complementary interpretability beyond attention or gradient methods.
- The LSTM-like sequential update format distinguishes the method from standard GNN gating approaches and supports joint feature and importance refinement.
- The model produces improved graph representations through informed feature learning tied to known biological relationships.
- Performance reaches a PR-AUC of 0.894 and ROC-AUC of 0.796 when applied to large-scale cancer drug screening data across 952 drugs.
Where Pith is reading between the lines
- The same prior-initialization strategy could be tested on other graph-structured biomedical tasks such as adverse event prediction or protein function annotation.
- Comparing results when the gene graph is replaced by a random or purely data-driven graph would quantify how much the literature weighting contributes versus the propagation mechanism alone.
- The approach opens a route to hybrid models that keep biological network constraints active throughout training rather than only at initialization.
Load-bearing premise
The curated gene-gene graph and drug-target interaction graph, weighted by article count, provide an accurate and unbiased initialization of node importance that improves rather than constrains the learned representations.
What would settle it
Retraining the model with randomly initialized node importance instead of the literature-weighted prior and checking whether PR-AUC and ROC-AUC remain at or above 0.894 and 0.796 would test the necessity of the initialization step.
Figures



read the original abstract
Explainability is necessary for many tasks in biomedical research. Recent explainability methods have focused on attention, gradient, and Shapley value. These do not handle data with strong associated prior knowledge and fail to constrain explainability results based on known relationships between predictive features. We propose GraphPINE, a graph neural network (GNN) architecture leveraging domain-specific prior knowledge to initialize node importance optimized during training for drug response prediction. Typically, a manual post-prediction step examines literature (i.e., prior knowledge) to understand returned predictive features. While node importance can be obtained for gradient and attention after prediction, node importance from these methods lacks complementary prior knowledge; GraphPINE seeks to overcome this limitation. GraphPINE differs from other GNN gating methods by utilizing an LSTM-like sequential format. We introduce an importance propagation layer that unifies 1) updates for feature matrix and node importance and 2) uses GNN-based graph propagation of feature values. This initialization and updating mechanism allows for informed feature learning and improved graph representation. We apply GraphPINE to cancer drug response prediction using drug screening and gene data collected for over 5,000 gene nodes included in a gene-gene graph with a drug-target interaction (DTI) graph for initial importance. The gene-gene graph and DTIs were obtained from curated sources and weighted by article count discussing relationships between drugs and genes. GraphPINE achieves a PR-AUC of 0.894 and ROC-AUC of 0.796 across 952 drugs. Code is available at https://anonymous.4open.science/r/GraphPINE-40DE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GraphPINE, a GNN architecture for interpretable cancer drug response prediction. It initializes node importance using curated gene-gene and drug-target interaction graphs weighted by article counts, then optimizes this importance during training via a novel importance propagation layer that jointly updates the feature matrix and node importance in an LSTM-like sequential format while performing GNN-based graph propagation. The model is evaluated on drug screening and gene data for over 5,000 genes and 952 drugs, reporting aggregate PR-AUC of 0.894 and ROC-AUC of 0.796. Code is provided at an anonymous repository.
Significance. If validated, the approach of embedding domain-specific prior knowledge directly into GNN node importance initialization and propagation could meaningfully advance interpretable models for drug response by moving beyond post-hoc analysis. The open code supports reproducibility, which is a clear strength.
major comments (2)
- [Abstract] Abstract: The reported PR-AUC of 0.894 and ROC-AUC of 0.796 are given only as aggregates with no baseline comparisons, error bars, ablation studies, or training details for the propagation layer. This prevents any evaluation of the central claim that the article-count-weighted prior initialization drives the performance.
- [Abstract] Abstract / Methods description: No quantitative comparison is provided between the proposed initialization and uniform/random node importance or an architecture with the graphs removed. This leaves untested the assumption that the curated gene-gene + DTI prior is net beneficial rather than neutral or constraining, which is load-bearing for the stated contribution.
minor comments (1)
- The description of the importance propagation layer as 'LSTM-like' would benefit from an explicit equation or pseudocode to clarify the update rules for feature matrix and node importance.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive remarks on the significance and reproducibility of GraphPINE. We address each major comment below and will incorporate revisions to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported PR-AUC of 0.894 and ROC-AUC of 0.796 are given only as aggregates with no baseline comparisons, error bars, ablation studies, or training details for the propagation layer. This prevents any evaluation of the central claim that the article-count-weighted prior initialization drives the performance.
Authors: We agree that the abstract would benefit from additional context. In the revised version we will expand the abstract to reference key baseline comparisons and the outcomes of ablation studies on the importance propagation layer. We will also add error bars for the reported metrics and include a brief description of the training procedure for the propagation layer. These updates will be supported by expanded results in the main text. revision: yes
-
Referee: [Abstract] Abstract / Methods description: No quantitative comparison is provided between the proposed initialization and uniform/random node importance or an architecture with the graphs removed. This leaves untested the assumption that the curated gene-gene + DTI prior is net beneficial rather than neutral or constraining, which is load-bearing for the stated contribution.
Authors: We recognize the value of directly testing the contribution of the curated prior. We will add ablation experiments comparing the article-count-weighted initialization against uniform and random initializations, as well as a graph-removed variant. These results, including quantitative metrics, will be presented in the Results section with corresponding references added to the abstract and Methods description. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper initializes node importance from external curated gene-gene and DTI graphs (weighted by article count from literature) as domain-specific prior knowledge, then optimizes these values during training inside an LSTM-like importance propagation layer within a GNN. The reported PR-AUC 0.894 and ROC-AUC 0.796 are obtained by evaluating the trained model on held-out drug response data across 952 drugs. This setup keeps the performance metric independent of the initialization inputs by construction, with no equations or steps that reduce a claimed prediction back to a fitted parameter or self-citation. No self-definitional loops, fitted-input-as-prediction, or load-bearing self-citations appear in the abstract or method description; the central claim rests on empirical evaluation against external benchmarks rather than tautological reproduction of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Curated gene-gene and drug-target interaction graphs weighted by article count accurately reflect biological relationships suitable for initializing node importance.
Reference graph
Works this paper leans on
-
[1]
Quantifying attention flow in transformers,
Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. arXiv preprint arXiv:2005.00928,
-
[2]
Differentiable scaffolding tree for molecular optimization
Tianfan Fu, Wenhao Gao, Cao Xiao, Jacob Yasonik, Connor W Coley, and Jimeng Sun. Differentiable scaffolding tree for molecular optimization. arXiv preprint arXiv:2109.10469, 2021a. Tianfan Fu, Cao Xiao, Xinhao Li, Lucas M Glass, and Jimeng Sun. Mimosa: Multi-constraint molecule sampling for molecule optimization. In Proceedings of the AAAI Conference on A...
-
[3]
Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks. arXiv preprint arXiv:1905.12265,
- [4]
-
[5]
Yoshitaka Inoue, Hunmin Lee, Tianfan Fu, and Augustin Luna. drgat: Attention-guided gene assessment of drug response utilizing a drug-cell-gene heterogeneous network. arXiv preprint arXiv:2405.08979,
-
[6]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Pathway Commons 2019 Update: integration, analysis and exploration of pathway data
Igor Rodchenkov, Ozgun Babur, Augustin Luna, Bulent Arman Aksoy, Jeffrey V Wong, Dylan Fong, Max Franz, Metin Can Siper, Manfred Cheung, Michael Wrana, Harsh Mistry, Logan Mosier, Jonah Dlin, Qizhi Wen, Caitlin O’Callaghan, Wanxin Li, Geoffrey Elder, Peter T Smith, Christian Dallago, Ethan Cerami, Benjamin Gross, Ugur Dogrusoz, Emek Demir, Gary D Bader, a...
work page 2019
-
[8]
ISSN 0305-1048. doi: 10.1093/nar/gkz946. URL https://doi.org/10.1093/nar/gkz946. Eric Sayers. The e-utilities in-depth: parameters, syntax and more. Entrez Programming Utilities Help [Internet],
-
[9]
Learning important features through propagating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. arXiv preprint arXiv:1704.02685,
-
[10]
11 Preprint Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
12 Preprint A I MPLEMENTATION DETAILS AND HYPERPARAMETER TUNING A.1 D ATA PREPROCESSING AND NETWORK CONSTRUCTION We integrated multiple data sources to create a comprehensive gene-gene interaction network and DTI dataset. Our approach involves several key steps. A.1.1 D ATA INTEGRATION Let G = g1, g2, ..., gn be the set of all genes, and D = d1, d2, ..., ...
work page 2010
-
[12]
The model architecture incorporates 3 Importance Propagation Layers (L = 3), each containing 64 hidden units. To balance model performance and interpretability, we set the importance regularization coefficientλ to 0.01 and the importance threshold τ to 0.1. All experiments were conducted on NVIDIA Tesla A100 GPUs with 80 GB memory. The average training ti...
work page 2019
-
[13]
with binary classification objective and log loss metric. Hyperparameters were tuned using Optuna, including num leaves (31–255), learning rate (1e-3 to 1.0), feature fraction (0.1–1.0), bagging fraction (0.1–1.0), bagging freq (1– 7), min child samples (5–100), lambda l1 and lambda l2 (1e-8 to 10.0), and num boost round (100–2000). Multiple Layer Percept...
work page 2000
-
[14]
and Graph Transformer models (Yun et al., 2019), we used a similar hyperparameter tuning configuration as for MPNN, GCN, and GINE. However, for GAT and Graph Transformer, we also included the number of attention heads, which was selected from {1, 2, 4}. This additional parameter helps in controlling the number of attention mechanisms in the model, enablin...
work page 2019
-
[15]
Rank Gene Name Evidence (PMID) 1 CDK1 37635245 2 NDE1 - 3 INCENP - 4 EEF1D - 5 NEDD1 - 6 CDT1 35931300 7 CSNK2B - 8 TPX2 - 9 ERCC6L - 10 FLNA - To set up a zero-shot prediction scenario, we randomly selected 70% of unique cell lines and 60% of unique NSC identifiers for the training and validation sets. The remaining cell lines and NSC identifiers were us...
work page 2061
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.