AdaTok: Self-Budgeting Image Tokenization with Quality-Preserving Dynamic Tokens
Pith reviewed 2026-06-27 22:40 UTC · model grok-4.3
The pith
A discrete image tokenizer can learn its own variable token budget per image in a single forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
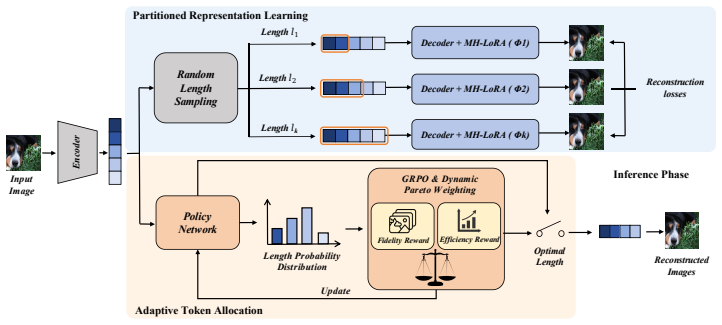
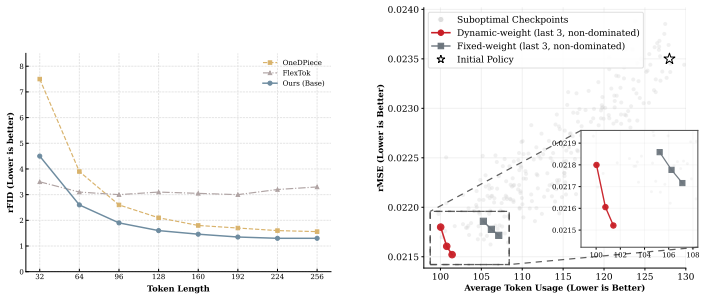
The central claim is that actionable elasticity requires a representation-allocation co-design: token prefixes must remain decodable across budgets, and the tokenizer must learn which prefix each image needs. AdaTok realizes this by combining Prioritized Representation Learning, which orders tokens via nested tail masking and resolves budget-dependent semantic shift with Multi-Head LoRA decoder heads, and Adaptive Token Allocation, which trains a deterministic-group GRPO policy over candidate budgets using Dynamic Pareto Weighting. The resulting AdaTok-Adaptive model attains rFID 1.50 at an average of approximately 118 tokens, outperforming fixed-length discrete 1D baselines at comparable bu
What carries the argument
Prioritized Representation Learning with nested tail masking and Multi-Head LoRA decoder heads, paired with Adaptive Token Allocation via a deterministic-group GRPO policy.
If this is right
- Shorter adaptive token sequences yield approximately 2.1 times higher throughput in autoregressive image generation compared with a fixed 256-token decode.
- Token count becomes a learned, content-conditioned output of the tokenizer rather than an externally chosen hyperparameter.
- Dynamic Pareto Weighting during policy training removes the need for manual fidelity-efficiency trade-off sweeps.
- The same representation-allocation co-design produces better reconstruction quality than existing discrete 1D elastic baselines at matched average budgets.
Where Pith is reading between the lines
- The same prefix-decodability requirement could be tested in audio or video tokenizers to see whether content-adaptive budgets generalize beyond images.
- If the learned allocation policy correlates with perceptual complexity, it might serve as an unsupervised measure of image difficulty for downstream tasks.
- Removing the need for post-hoc length tuning could simplify the training pipeline for large vision-language models that currently rely on fixed token grids.
Load-bearing premise
Multi-Head LoRA decoder heads can resolve budget-dependent semantic shift so that any token prefix reconstructs correctly without separate training for each length.
What would settle it
Train a single fixed-length 1D tokenizer at the exact average token count used by AdaTok-Adaptive and measure whether its rFID on the ImageNet validation set equals or beats 1.50; if it does, the adaptive allocation step adds no measurable benefit.
Figures

read the original abstract
Image tokenizers, from 2D grids to recent 1D sequences, typically encode every image with the same fixed number of tokens. Yet visual complexity is highly heterogeneous, so a uniform budget overspends on simple inputs and underserves complex ones. Existing elastic tokenizers expose variable-length reconstructions, but often leave token length as a deployment-time operating point, a search target, or an external prediction rather than an output of the tokenizer itself. In this work, we ask whether a discrete visual tokenizer can budget itself in one pass. Our central finding is that actionable elasticity requires a representation--allocation co-design: prefixes must remain decodable across budgets, and the tokenizer must learn which prefix each image needs. We propose AdaTok, a self-budgeting discrete 1D tokenizer. AdaTok combines Prioritized Representation Learning, which orders tokens with nested tail masking and resolves budget-dependent semantic shift through Multi-Head LoRA decoder heads, with Adaptive Token Allocation, which trains a lightweight deterministic-group GRPO policy over candidate budgets. Dynamic Pareto Weighting balances fidelity and efficiency during policy training without manual trade-off sweeps. On ImageNet-1K, AdaTok-Full reaches rFID 1.31 at 256 tokens, while AdaTok-Adaptive attains rFID 1.50 using only ~118 tokens on average, outperforming discrete 1D baselines at comparable budgets. In autoregressive image generation, the shorter adaptive representation yields ~2.1x throughput over a fixed 256-token decode, suggesting that visual token count can be learned as a content-conditioned output rather than set as a fixed hyperparameter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaTok, a self-budgeting discrete 1D image tokenizer. It combines Prioritized Representation Learning (nested tail masking to order tokens plus Multi-Head LoRA decoder heads to resolve budget-dependent semantic shift) with Adaptive Token Allocation (a deterministic-group GRPO policy over candidate budgets, trained via Dynamic Pareto Weighting). On ImageNet-1K the method reports AdaTok-Full at rFID 1.31 with 256 tokens and AdaTok-Adaptive at rFID 1.50 with ~118 tokens on average, outperforming fixed discrete 1D baselines, together with a claimed 2.1x throughput gain in autoregressive generation.
Significance. If the representation-allocation co-design is shown to work, the result would demonstrate that token budget can be learned as a content-conditioned output of the tokenizer itself rather than fixed at training or deployment time, which would be a meaningful efficiency advance for autoregressive vision models.
major comments (3)
- [Abstract] Abstract: the central claim that Multi-Head LoRA heads eliminate budget-dependent semantic shift and that the GRPO policy learns effective per-image allocation from prioritized representations alone is load-bearing, yet the abstract supplies no ablations, policy-entropy measurements, or quantitative validation that these components succeed; without such evidence the reported rFID 1.50 at ~118 tokens cannot be attributed to self-budgeting.
- [Adaptive Token Allocation] Adaptive Token Allocation section: the deterministic-group GRPO policy is presented as converging without external labels or post-hoc tuning, but no analysis is given of how Dynamic Pareto Weighting avoids introducing implicit external signals or of the policy's sensitivity to the candidate budget set; this directly affects whether the elasticity is truly self-budgeting.
- [Prioritized Representation Learning] Prioritized Representation Learning section: the nested tail masking is claimed to produce decodable prefixes at every budget, but no reconstruction-quality curves or prefix-decodability metrics across budgets are referenced to confirm that the Multi-Head LoRA heads are the operative mechanism rather than an artifact of the training schedule.
minor comments (2)
- [Abstract] Abstract: expand the first use of 'rFID' and state the exact baseline definitions and error-bar protocol used for the throughput and rFID comparisons.
- [Methods] The free parameters (candidate budget set, LoRA ranks and heads) are listed in the axiom ledger but receive no explicit discussion of how they were chosen or ablated.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying the existing evidence in the manuscript and indicating where revisions have been made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Multi-Head LoRA heads eliminate budget-dependent semantic shift and that the GRPO policy learns effective per-image allocation from prioritized representations alone is load-bearing, yet the abstract supplies no ablations, policy-entropy measurements, or quantitative validation that these components succeed; without such evidence the reported rFID 1.50 at ~118 tokens cannot be attributed to self-budgeting.
Authors: The abstract is intentionally concise and summarizes the core contributions and results. The full manuscript contains the requested ablations, policy-entropy measurements, and quantitative validations in the experimental sections, which attribute the rFID 1.50 performance to the self-budgeting components. To address the concern directly in the abstract, we have revised it to include a brief reference to these supporting experiments. revision: yes
-
Referee: [Adaptive Token Allocation] Adaptive Token Allocation section: the deterministic-group GRPO policy is presented as converging without external labels or post-hoc tuning, but no analysis is given of how Dynamic Pareto Weighting avoids introducing implicit external signals or of the policy's sensitivity to the candidate budget set; this directly affects whether the elasticity is truly self-budgeting.
Authors: The Adaptive Token Allocation section explains that Dynamic Pareto Weighting balances fidelity and efficiency using only internal metrics during policy training, without external labels. We have added explicit analysis in the revised manuscript demonstrating the absence of implicit external signals and including sensitivity results with respect to the candidate budget set, further confirming the self-budgeting property. revision: yes
-
Referee: [Prioritized Representation Learning] Prioritized Representation Learning section: the nested tail masking is claimed to produce decodable prefixes at every budget, but no reconstruction-quality curves or prefix-decodability metrics across budgets are referenced to confirm that the Multi-Head LoRA heads are the operative mechanism rather than an artifact of the training schedule.
Authors: The Prioritized Representation Learning section details the nested tail masking and the role of Multi-Head LoRA heads in resolving semantic shift. The overall rFID results at varying budgets provide supporting evidence. We have revised the section to reference additional reconstruction-quality curves and prefix-decodability metrics that isolate the contribution of the Multi-Head LoRA heads. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained via training
full rationale
The paper's central claim rests on training a tokenizer with nested tail masking, Multi-Head LoRA heads, and a GRPO policy for adaptive allocation, with reported rFID values obtained from ImageNet-1K experiments rather than by algebraic reduction to fitted inputs. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or method descriptions; the policy is explicitly trained on prioritized representations with Dynamic Pareto Weighting, and performance is benchmarked externally. The mechanisms (LoRA heads resolving semantic shift, GRPO learning budgets) are presented as empirical outcomes of optimization, not tautologies, making the derivation independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- candidate budget set
- Multi-Head LoRA ranks and heads
axioms (1)
- domain assumption Prefixes of the token sequence remain decodable to usable reconstructions at any budget
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
International Conference on Machine Learning , pages=
simple diffusion: End-to-end diffusion for high resolution images , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[4]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Magvit: Masked generative video transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[6]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Language Model Beats Diffusion--Tokenizer is Key to Visual Generation , author=. arXiv preprint arXiv:2310.05737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
European Conference on Computer Vision , pages=
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[8]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[9]
Emu3: Next-Token Prediction is All You Need
Emu3: Next-token prediction is all you need , author=. arXiv preprint arXiv:2409.18869 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Autoregressive model beats diffusion: Llama for scalable image generation , author=. arXiv preprint arXiv:2406.06525 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2411.00776 , year=
Randomized autoregressive visual generation , author=. arXiv preprint arXiv:2411.00776 , year=
-
[12]
Auto-Encoding Variational Bayes
Auto-Encoding Variational Bayes , author=. 2nd International Conference on Learning Representations (ICLR) , year=. 1312.6114 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[14]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[15]
Finite Scalar Quantization: VQ-VAE Made Simple
Finite scalar quantization: Vq-vae made simple , author=. arXiv preprint arXiv:2309.15505 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Advances in Neural Information Processing Systems , volume=
An image is worth 32 tokens for reconstruction and generation , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Cognition , volume=
Linguistic complexity: Locality of syntactic dependencies , author=. Cognition , volume=. 1998 , publisher=
1998
-
[18]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[19]
Proceedings of the National Academy of Sciences , volume=
Word lengths are optimized for efficient communication , author=. Proceedings of the National Academy of Sciences , volume=. 2011 , publisher=
2011
-
[20]
science , volume=
Reducing the dimensionality of data with neural networks , author=. science , volume=. 2006 , publisher=
2006
-
[21]
Medical Image Computing and Computer-Assisted Intervention--MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. Medical Image Computing and Computer-Assisted Intervention--MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 , pages=. 2015 , organization=
2015
-
[22]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Efficient-vqgan: Towards high-resolution image generation with efficient vision transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
Vector-quantized Image Modeling with Improved VQGAN
Vector-quantized image modeling with improved vqgan , author=. arXiv preprint arXiv:2110.04627 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
First Workshop on Scalable Optimization for Efficient and Adaptive Foundation Models , year=
Adaptive length image tokenization via recurrent allocation , author=. First Workshop on Scalable Optimization for Efficient and Adaptive Foundation Models , year=
-
[26]
Freeman and Antonio Torralba and Phillip Isola , title =
Shivam Duggal and Sanghyun Byun and William T. Freeman and Antonio Torralba and Phillip Isola , title =. CoRR , volume =. 2025 , url =
2025
-
[27]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =
2024
-
[28]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[29]
Imagefolder: Autoregressive image generation with folded tokens, 2024
Imagefolder: Autoregressive image generation with folded tokens , author=. arXiv preprint arXiv:2410.01756 , year=
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[32]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
arXiv preprint arXiv:2509.11452 , year=
Learning to optimize multi-objective alignment through dynamic reward weighting , author=. arXiv preprint arXiv:2509.11452 , year=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Autoregressive image generation using residual quantization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
Advances in Neural Information Processing Systems , volume=
Movq: Modulating quantized vectors for high-fidelity image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maskgit: Masked generative image transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
arXiv preprint arXiv:2501.10064 , year=
One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression , author=. arXiv preprint arXiv:2501.10064 , year=
-
[38]
arXiv preprint arXiv:2501.03120 , year=
Cat: Content-adaptive image tokenization , author=. arXiv preprint arXiv:2501.03120 , year=
-
[39]
Principal Components
" Principal Components" Enable A New Language of Images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Autoregressive image generation using residual quantization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Advances in neural information processing systems , volume=
Conditional image generation with pixelcnn decoders , author=. Advances in neural information processing systems , volume=
-
[42]
International conference on machine learning , pages=
Generative pretraining from pixels , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[43]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[44]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image-to-image translation with conditional adversarial networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
All are worth words: A vit backbone for diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
2020 IEEE International Symposium on Information Theory (ISIT) , pages=
Stochastic bottleneck: Rateless auto-encoder for flexible dimensionality reduction , author=. 2020 IEEE International Symposium on Information Theory (ISIT) , pages=. 2020 , organization=
2020
-
[47]
The journal of machine learning research , volume=
Dropout: a simple way to prevent neural networks from overfitting , author=. The journal of machine learning research , volume=. 2014 , publisher=
2014
-
[48]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[49]
Vision Transformers Need Registers
Vision transformers need registers , author=. arXiv preprint arXiv:2309.16588 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
generation: Taming optimization dilemma in latent diffusion models , author=
Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[51]
arXiv preprint arXiv:2409.16211 , year=
Maskbit: Embedding-free image generation via bit tokens , author=. arXiv preprint arXiv:2409.16211 , year=
-
[52]
arXiv preprint arXiv:2502.13967 , year=
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length , author=. arXiv preprint arXiv:2502.13967 , year=
-
[53]
arXiv preprint arXiv:2410.08368 , year=
Elastictok: Adaptive tokenization for image and video , author=. arXiv preprint arXiv:2410.08368 , year=
-
[54]
Advances in Neural Information Processing Systems , volume=
Visual concepts tokenization , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
International Conference on Machine Learning , pages=
Learning ordered representations with nested dropout , author=. International Conference on Machine Learning , pages=. 2014 , organization=
2014
-
[56]
Advances in Neural Information Processing Systems , volume=
Matryoshka representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
Autoregressive image generation without vector quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[59]
Advances in neural information processing systems , volume=
Dynamicvit: Efficient vision transformers with dynamic token sparsification , author=. Advances in neural information processing systems , volume=
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A-vit: Adaptive tokens for efficient vision transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.