SHARD: cell-keyed residual splitting for alignment-resistant private dense retrieval
Pith reviewed 2026-07-01 06:39 UTC · model grok-4.3
The pith
Splitting each embedding into a public prefix and C cell-keyed private residuals under separate keys raises the cost of alignment attacks proportionally to C.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The centred embedding is rotated and split into a short public prefix driving stage-1 retrieval and a private residual sharded into C cells, each rotated under a separate secret key; the residual is reranked under CKKS, where the keys cancel and the inner product stays exact. One parameter C spans the global-linear baseline to per-document micro-keys, making the keyed residual a cancellable template for text embeddings, the first such scheme for dense retrieval.
What carries the argument
cell-keyed residual splitting, which divides the private residual into C cells each under its own rotation key to force alignment attacks to scale with C
If this is right
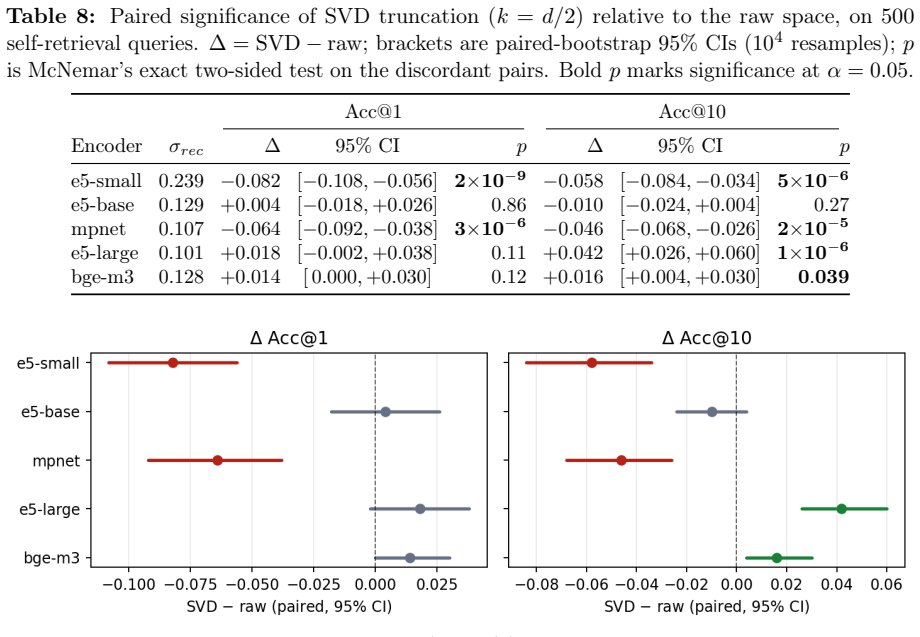
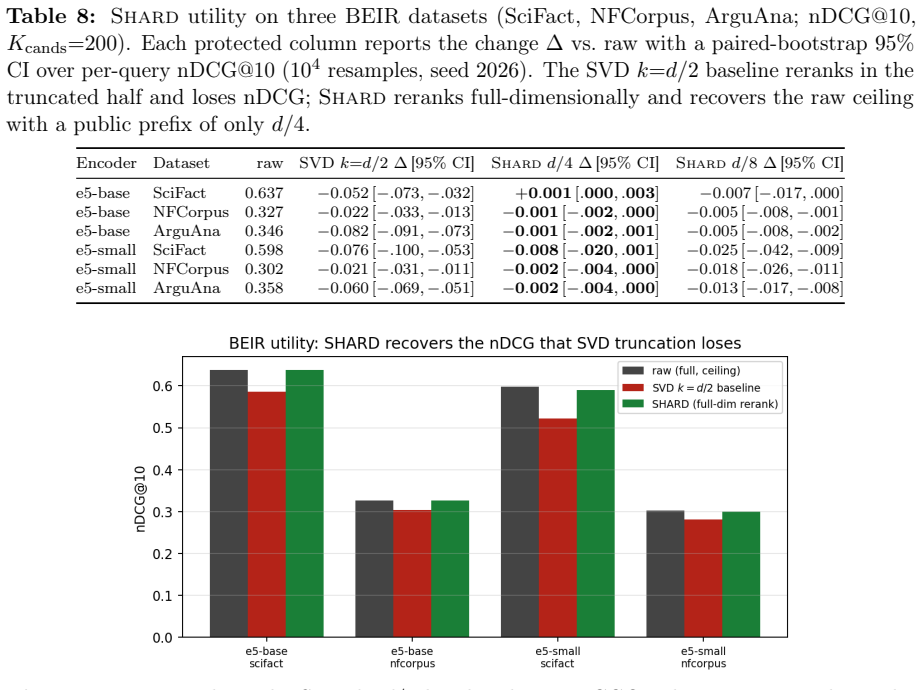
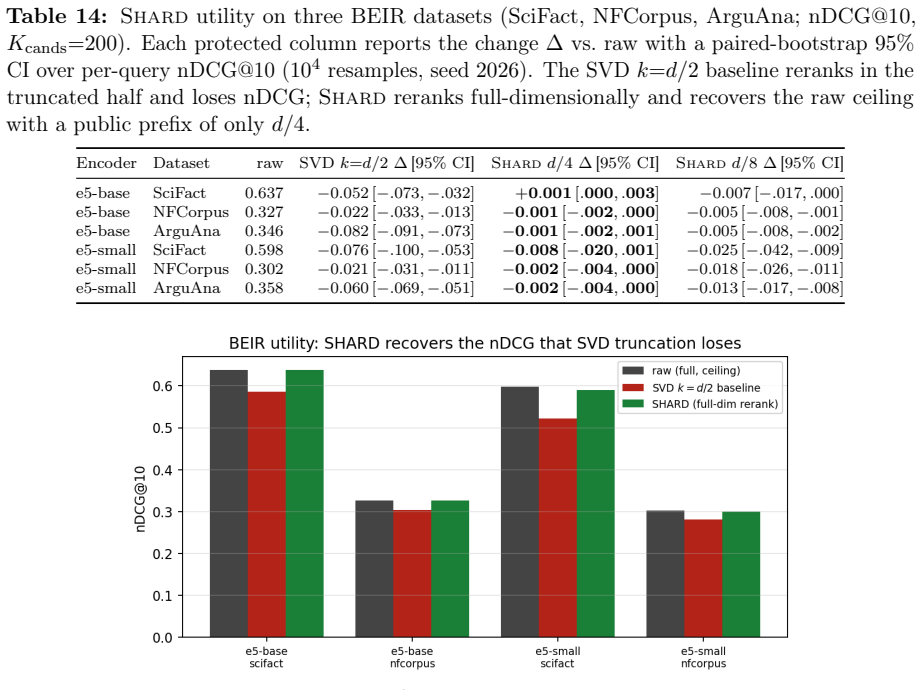
- Full-dimensional reranking returns the raw-space nDCG@10 that half-SVD truncation gives up.
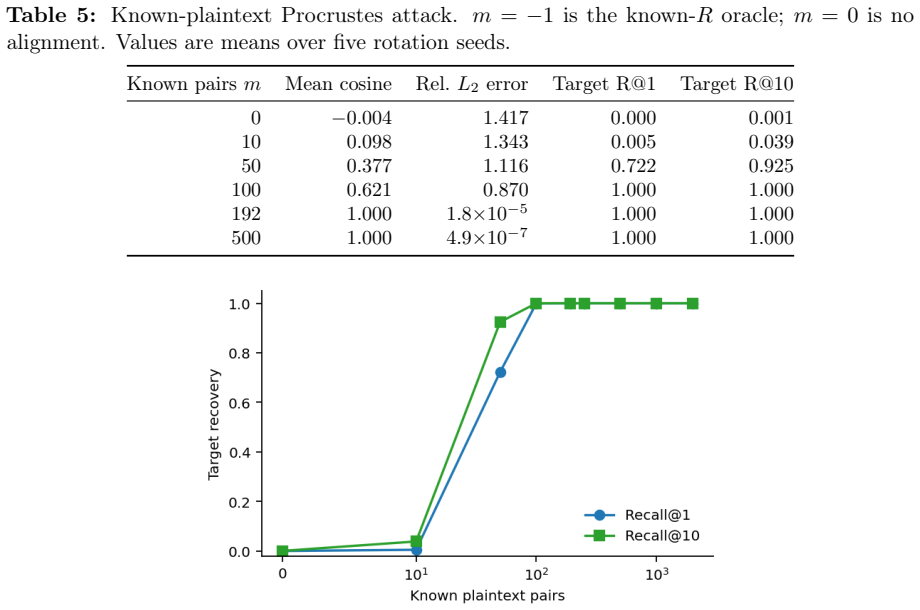
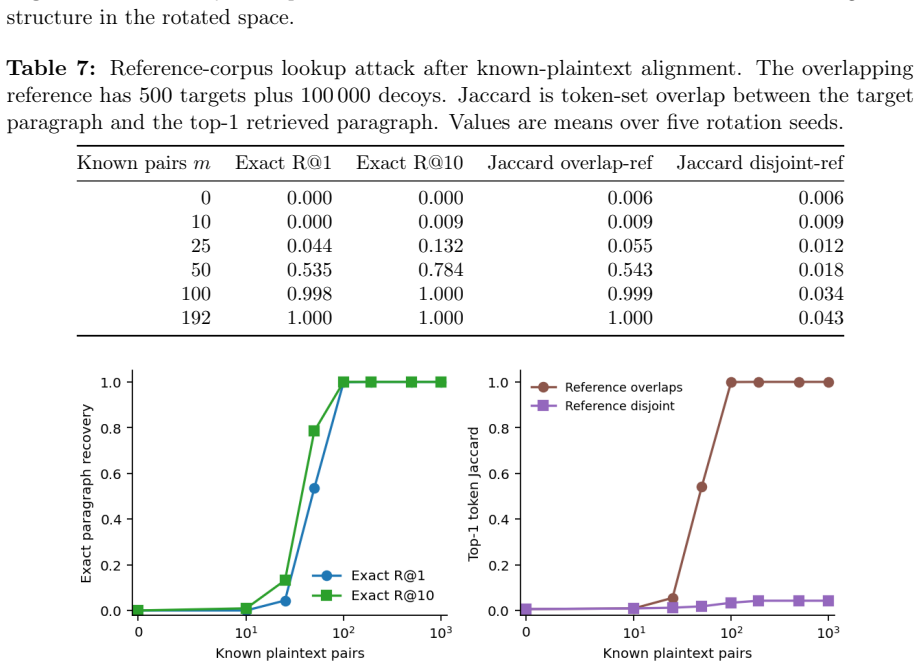
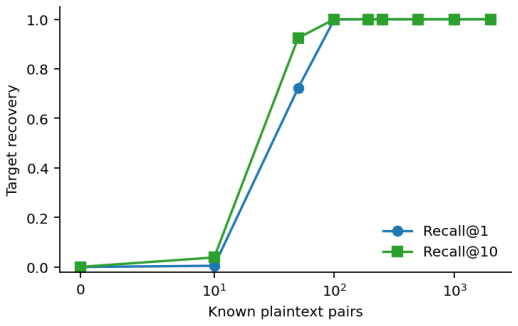
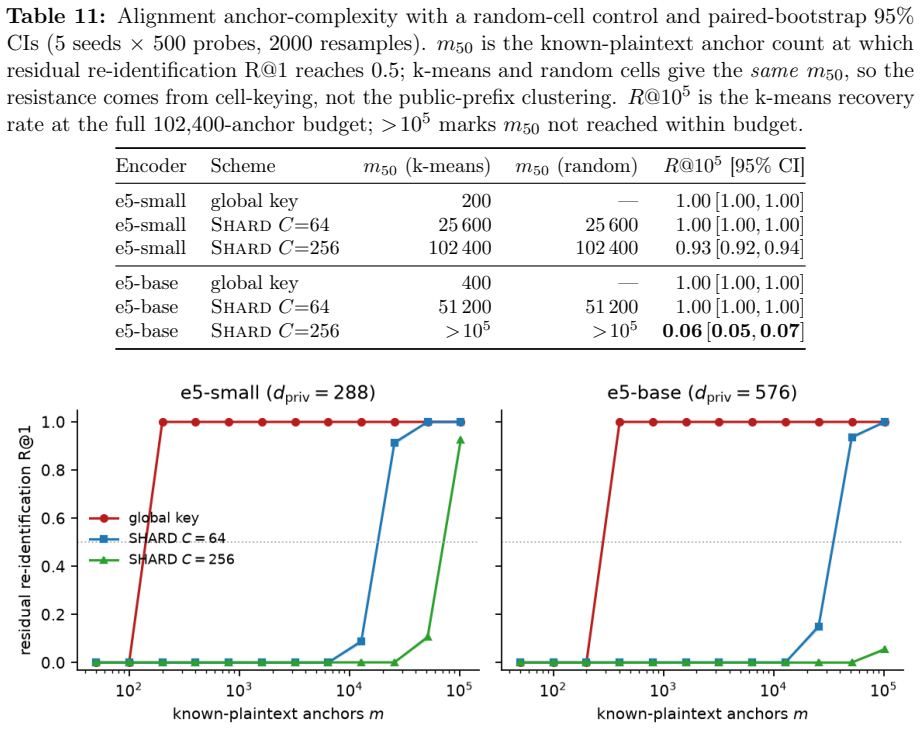
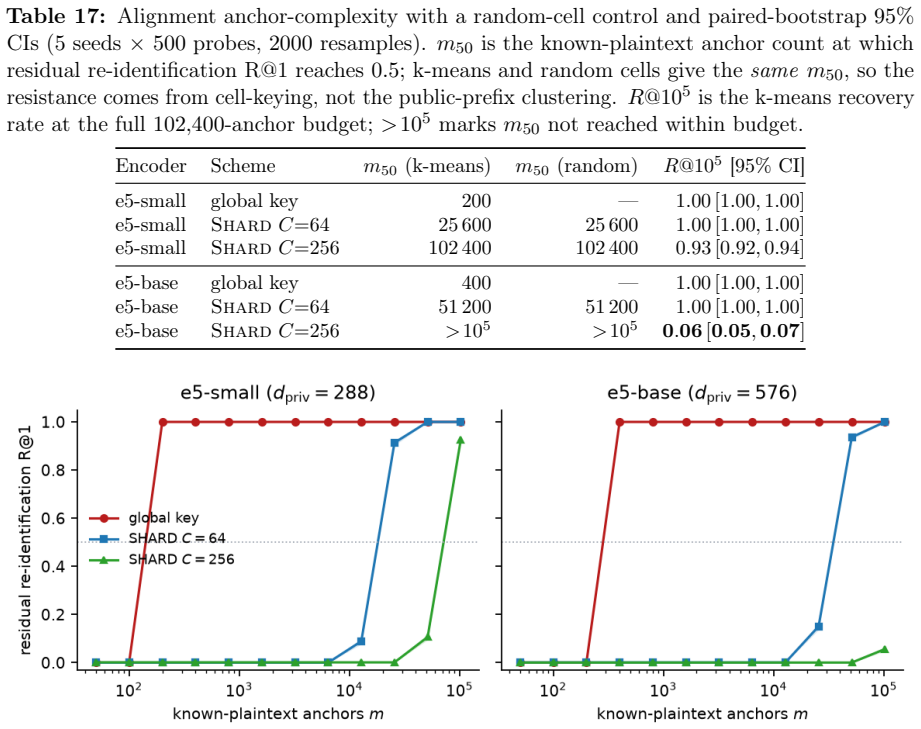
- Recovering the cell-keyed residual under a diffuse known-plaintext leak costs about C times more anchors.
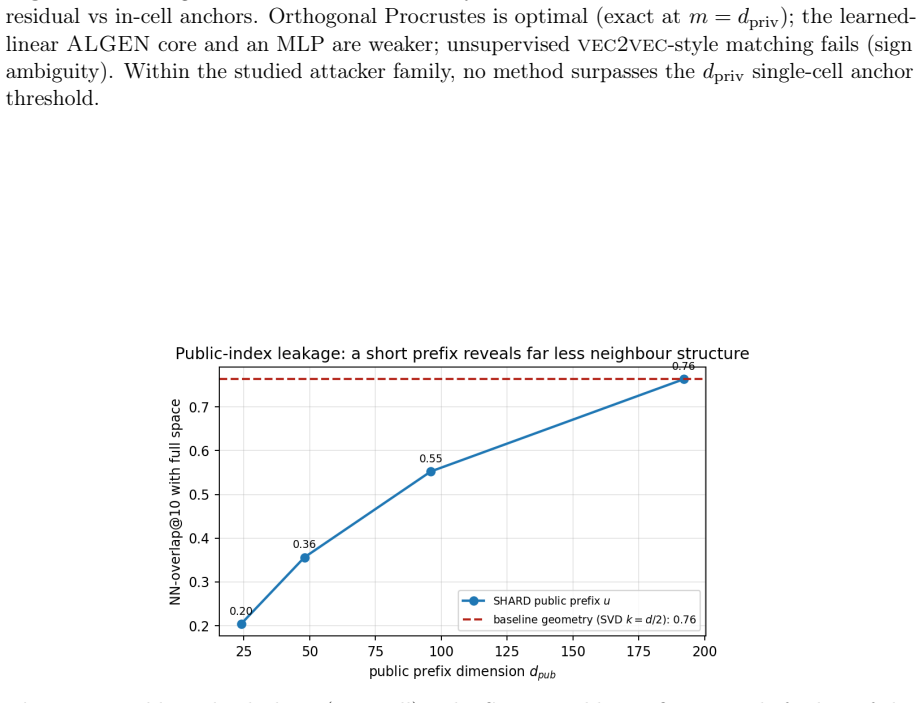
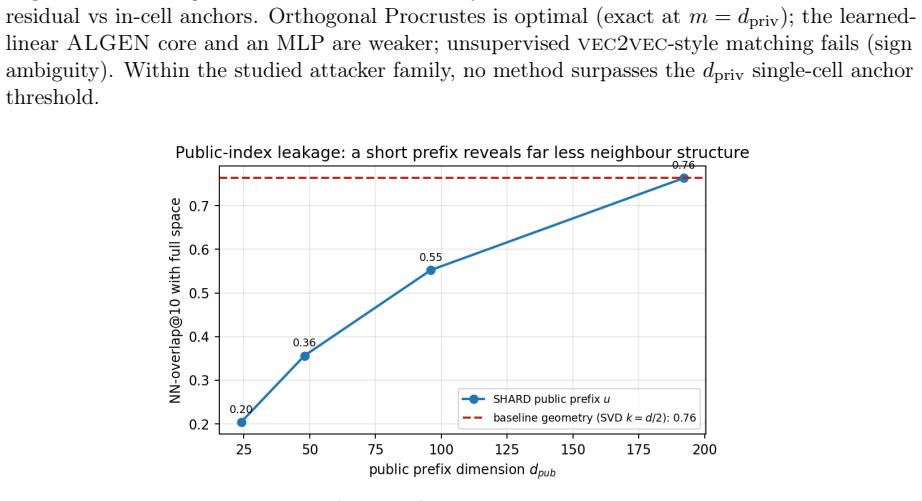
- The short public prefix leaks far less neighbour structure.
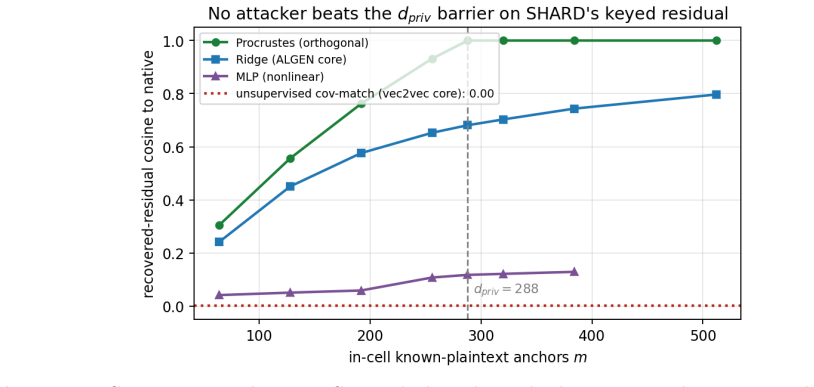
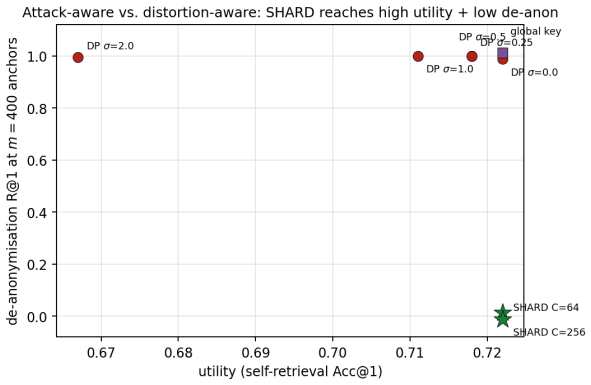
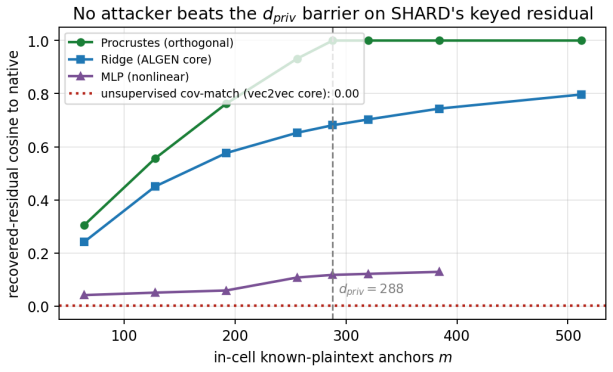
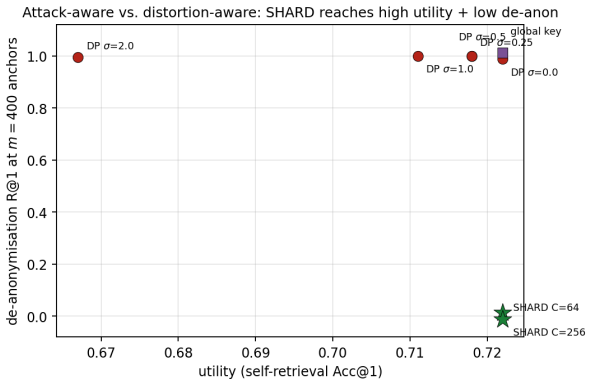
- The barrier holds against learned-linear, non-linear and unsupervised aligners.
- Where a matched-utility noise defence de-anonymises almost every probe, SHARD de-anonymises none.
Where Pith is reading between the lines
- If the public prefix length is reduced further, neighbour leakage could be lowered at the expense of stage-1 recall.
- The cancellable template property enables key revocation without re-embedding the corpus, useful for long-term deployment.
- Targeted attacks on a single cell still require only d_priv anchors, suggesting that cell size selection is a key security parameter.
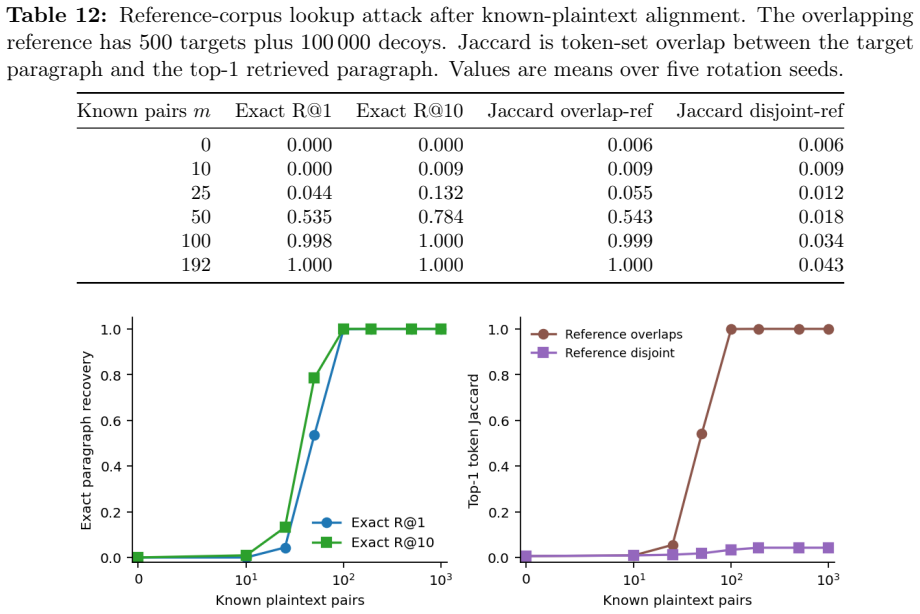
- The scheme could be combined with other defenses to handle overlapping reference corpora that leak through the prefix.
Load-bearing premise
The short public prefix leaks far less neighbour structure and the cell-keyed residual forces any alignment attack to scale with C.
What would settle it
Showing that an alignment attack succeeds on the sharded residuals using no more anchors than on the un-sharded case, independent of C.
Figures

read the original abstract
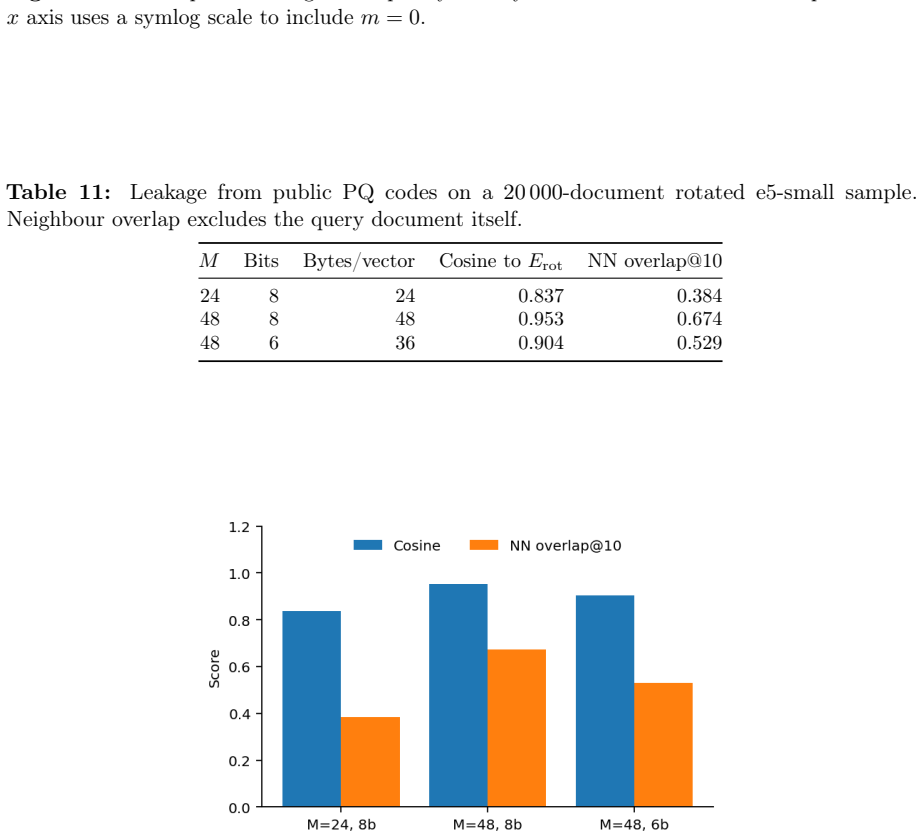
Dense embeddings underpin semantic search and retrieval-augmented generation, yet a leaked vector store hands much of the underlying text back. Modern inversion and alignment attacks share one weakness: the protected store is a single global geometry, and any single geometry can be aligned to a known one - a secret global rotation included, since orthogonal Procrustes recovers it from about subspace-dimension known-plaintext pairs. We introduce SHARD, a retrieval-preserving embedding transform that removes that weak axis. The centred embedding is rotated and split into a short public prefix (driving stage-1 retrieval) and a private residual sharded into C cells, each rotated under a separate secret key; the residual is reranked under CKKS, where the keys cancel and the inner product stays exact. One parameter C spans the global-linear baseline (C=1) to per-document micro-keys (C=N), making the keyed residual a cancellable template - revocable, renewable, unlinkable - for text embeddings, the first such scheme for dense retrieval. On five encoders: full-dimensional reranking returns the raw-space nDCG@10 that half-SVD truncation gives up; recovering the cell-keyed residual under a diffuse known-plaintext leak costs about C times more anchors (median 200 to 102,400 at C=256) for a few encrypted residual queries and the short public prefix leaks far less neighbour structure, with a micro-key limit driving residual leakage to zero. The barrier holds against learned-linear, non-linear and unsupervised aligners, and where a matched-utility noise defence de-anonymises almost every probe, SHARD de-anonymises none. Limits: within a cell similarities survive, a targeted attacker on one victim's cell needs only about d_priv anchors, and an overlapping reference corpus still leaks through the public prefix. SHARD is an attack-aware geometric defence, not a cryptographic guarantee.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHARD, a geometric transform for private dense retrieval. Centred embeddings are rotated and split into a short public prefix (for stage-1 retrieval) and a private residual sharded into C cells, each rotated under a distinct secret key. The residual supports exact inner-product reranking under CKKS (keys cancel), while C provides a tunable continuum from global linear (C=1) to per-document micro-keys (C=N). This yields revocable, renewable, unlinkable templates. Empirical results on five encoders claim that full-dimensional reranking recovers raw-space nDCG@10, that alignment attacks require ~C times more anchors (median 200–102400 at C=256), that the public prefix leaks less neighbour structure, and that SHARD resists learned-linear, non-linear and unsupervised aligners better than matched-utility noise baselines. Limits (intra-cell similarity survival, targeted-cell anchor cost ~d_priv, public-prefix leakage under overlapping corpora) are explicitly stated.
Significance. If the utility and scaling claims hold under the stated limits, the work is significant: it supplies the first explicit cancellable-template construction for dense retrieval embeddings, combining an attack-aware geometric split with CKKS to achieve exact reranking while forcing alignment cost to scale with C. The single-parameter continuum and the empirical demonstration that a matched-utility noise defence de-anonymises probes while SHARD does not are concrete contributions to the privacy-preserving retrieval literature.
major comments (2)
- [Abstract / Empirical Evaluation] Abstract and empirical evaluation: the central claim that 'full-dimensional reranking returns the raw-space nDCG@10' is presented without error bars, dataset identities, encoder dimensions, or statistical tests. Because nDCG recovery is the primary evidence that utility is preserved, the absence of these details makes the utility claim impossible to evaluate from the given text.
- [Construction / CKKS Reranking] CKKS reranking paragraph: the statement that 'the keys cancel and the inner product stays exact' is asserted without an explicit equation, proof sketch, or reference to the precise CKKS operations used. This cancellation is load-bearing for the claim of lossless reranking utility and must be shown for the result to be verifiable.
minor comments (2)
- [Notation] Notation for the public prefix length and cell dimension d_priv should be introduced once with a clear definition before first use.
- [Attack Evaluation] The manuscript would be strengthened by an explicit statement of the exact attack implementations (learned-linear, non-linear, unsupervised) and the anchor-selection procedure used to produce the reported median anchor counts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of our utility results and the CKKS reranking construction. Both points identify areas where additional detail will improve verifiability, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Empirical Evaluation] Abstract and empirical evaluation: the central claim that 'full-dimensional reranking returns the raw-space nDCG@10' is presented without error bars, dataset identities, encoder dimensions, or statistical tests. Because nDCG recovery is the primary evidence that utility is preserved, the absence of these details makes the utility claim impossible to evaluate from the given text.
Authors: We agree that the abstract and the summary of empirical results would be strengthened by these details. In the revised manuscript we will (i) report error bars on all nDCG@10 recovery figures, (ii) explicitly name the five encoders and their embedding dimensions, (iii) identify the evaluation datasets, and (iv) include the results of paired statistical tests comparing SHARD reranking to the raw-space baseline. These elements already exist in the full experimental tables; we will surface them in the abstract and evaluation summary as well. revision: yes
-
Referee: [Construction / CKKS Reranking] CKKS reranking paragraph: the statement that 'the keys cancel and the inner product stays exact' is asserted without an explicit equation, proof sketch, or reference to the precise CKKS operations used. This cancellation is load-bearing for the claim of lossless reranking utility and must be shown for the result to be verifiable.
Authors: We accept that an explicit derivation is required. In the revised construction section we will insert (a) the precise CKKS inner-product expression under per-cell rotations, (b) the algebraic cancellation of the cell keys, and (c) a short proof sketch confirming that the result equals the plaintext inner product. A reference to the relevant CKKS multiplication and rotation primitives will also be added. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript defines an explicit geometric transform (centred embedding rotated and split into public prefix plus C-cell keyed residual) whose inner-product cancellation under CKKS is stated directly from the construction. Security scaling with C is presented as a measured empirical outcome against external aligners rather than a fitted prediction or self-referential definition. No load-bearing step reduces by the paper's own equations to its inputs, and no self-citation chain or ansatz smuggling is invoked for the central claims. The work is self-contained once the stated limits (intra-cell similarity survival, public-prefix leakage) are accepted.
Axiom & Free-Parameter Ledger
free parameters (1)
- C
axioms (1)
- domain assumption CKKS homomorphic encryption permits exact inner-product computation once cell keys cancel
invented entities (1)
-
cell-keyed residual split (SHARD transform)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” inProc. EMNLP, 2019, pp. 3982–3992
2019
-
[2]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
L. Wang, N. Yang, X. Huang, et al., “Text Embeddings by Weakly-Supervised Contrastive Pre- training,”arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Large Dual Encoders Are Generalizable Retrievers,
J. Ni et al., “Large Dual Encoders Are Generalizable Retrievers,” inProc. EMNLP, 2022, pp. 9844–9855
2022
-
[4]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation,” arXiv:2402.03216, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Dense Passage Retrieval for Open-Domain Question Answering,
V. Karpukhin et al., “Dense Passage Retrieval for Open-Domain Question Answering,” inProc. EMNLP, 2020, pp. 6769–6781
2020
-
[6]
ColBERT: Efficient and Effective Passage Search via Contextualised Late Interaction over BERT,
O. Khattab and M. Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualised Late Interaction over BERT,” inProc. ACM SIGIR, 2020, pp. 39–48
2020
-
[7]
Text Embeddings Reveal (Almost) As Much As Text,
J. X. Morris, V. Kuleshov, V. Shmatikov, and A. M. Rush, “Text Embeddings Reveal (Almost) As Much As Text,” inProc. EMNLP, 2023
2023
-
[8]
Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence,
H. Li, M. Xu, and Y. Song, “Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence,” inFindings of ACL, 2023, pp. 14022–14040
2023
-
[9]
Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries,
Y.-H. Huang, Y. Tsai, H. Hsiao, H.-Y. Lin, and S.-D. Lin, “Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries,” inProc. ACL (Long), 2024, pp. 4193–4205
2024
-
[10]
ALGEN: Few-shot Inversion Attacks on Textual Embeddings via Cross-Model Alignment and Generation,
Y. Chen, Q. Xu, and J. Bjerva, “ALGEN: Few-shot Inversion Attacks on Textual Embeddings via Cross-Model Alignment and Generation,” inProc. ACL, 2025
2025
-
[11]
Universal Zero-shot Embedding Inversion,
C. Zhang, J. X. Morris, and V. Shmatikov, “Universal Zero-shot Embedding Inversion,” arXiv:2504.00147, 2025
-
[12]
W. Yu, Y. Chen, J. Bjerva, S. Kosta, and Q. Li, “LAGO: Few-shot Crosslingual Embedding Inversion Attacks via Language Similarity-Aware Graph Optimization,”arXiv:2505.16008, 2025
-
[13]
EGuard: Defending LLM Embeddings Against Inversion Attacks via Text Mutual Information Optimization,
T. Liu et al., “EGuard: Defending LLM Embeddings Against Inversion Attacks via Text Mutual Information Optimization,” inProc. AAAI, 2026. 30
2026
-
[14]
Concept-Aware Privacy Mechanisms for Defending Embedding Inversion Attacks,
Y.-C. Tsai, H. Hsiao, K.-Y. Chen, and S.-D. Lin, “Concept-Aware Privacy Mechanisms for Defending Embedding Inversion Attacks,”arXiv:2602.07090, 2026
-
[15]
Nonparametric Variational Differential Privacy via Embedding Parameter Clipping,
D. El Zein, S. Kumar, and J. Henderson, “Nonparametric Variational Differential Privacy via Embedding Parameter Clipping,”arXiv:2603.09583, 2026
-
[16]
Matryoshka Representation Learning,
A. Kusupati et al., “Matryoshka Representation Learning,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[17]
Harnessing the Universal Geometry of Embed- dings,
R. Jha, C. Zhang, V. Shmatikov, and J. X. Morris, “Harnessing the Universal Geometry of Embed- dings,”arXiv:2505.12540, 2025
-
[18]
The Good and the Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG),
S. Zeng et al., “The Good and the Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG),” inFindings of ACL, 2024, pp. 4505–4524
2024
-
[19]
Information Leakage in Embedding Models,
C. Song and A. Raghunathan, “Information Leakage in Embedding Models,” inProc. ACM CCS, 2020, pp. 377–390
2020
-
[20]
Membership Inference Attacks Against Machine Learning Models,
R. Shokri et al., “Membership Inference Attacks Against Machine Learning Models,” inProc. IEEE S&P, 2017, pp. 3–18
2017
-
[21]
Extracting Training Data from Large Language Models,
N. Carlini et al., “Extracting Training Data from Large Language Models,” inProc. USENIX Security, 2021, pp. 2633–2650
2021
-
[22]
Differential Privacy,
C. Dwork, “Differential Privacy,” inProc. ICALP, 2006, pp. 1–12
2006
-
[23]
Deep Learning with Differential Privacy,
M. Abadi et al., “Deep Learning with Differential Privacy,” inProc. ACM CCS, 2016, pp. 308–318
2016
-
[24]
Differentially Private Representation for NLP,
L. Lyu, X. He, and Y. Li, “Differentially Private Representation for NLP,” inFindings of EMNLP, 2020, pp. 2355–2365
2020
-
[25]
Privacy via the Johnson-Lindenstrauss Transform,
K. Kenthapadi, A. Korolova, I. Mironov, and N. Mishra, “Privacy via the Johnson-Lindenstrauss Transform,”J. Privacy and Confidentiality, vol. 5, no. 1, 2013
2013
-
[26]
Random Projection-Based Multiplicative Data Perturbation for Privacy Preserving Distributed Data Mining,
K. Liu, H. Kargupta, and J. Ryan, “Random Projection-Based Multiplicative Data Perturbation for Privacy Preserving Distributed Data Mining,”IEEE TKDE, vol. 18, no. 1, 2006, pp. 92–106
2006
-
[27]
Homomorphic Encryption for Arithmetic of Approximate Numbers,
J. H. Cheon, A. Kim, M. Kim, and Y. Song, “Homomorphic Encryption for Arithmetic of Approximate Numbers,” inAdvances in Cryptology—ASIACRYPT 2017, LNCS 10624, pp. 409–437
2017
-
[28]
Bootstrapping for Approximate Homomorphic Encryption,
J. H. Cheon, K. Han, A. Kim et al., “Bootstrapping for Approximate Homomorphic Encryption,” in Advances in Cryptology—EUROCRYPT 2018, LNCS 10820, pp. 360–384
2018
-
[29]
Homomorphic Encryption Security Standard,
M. Albrecht et al., “Homomorphic Encryption Security Standard,” HomomorphicEncryption.org, 2018
2018
-
[30]
On the Concrete Hardness of Learning with Errors,
M. R. Albrecht, R. Player, and S. Scott, “On the Concrete Hardness of Learning with Errors,”Journal of Mathematical Cryptology, vol. 9, no. 3, 2015, pp. 169–203 (lattice-estimator methodology)
2015
-
[31]
A Generalized Solution of the Orthogonal Procrustes Problem,
P. H. Schönemann, “A Generalized Solution of the Orthogonal Procrustes Problem,”Psychometrika, vol. 31, no. 1, 1966, pp. 1–10
1966
-
[32]
Cancelable Biometrics: A Review,
V. M. Patel, N. K. Ratha, and R. Chellappa, “Cancelable Biometrics: A Review,”IEEE Signal Processing Magazine, vol. 32, no. 5, 2015, pp. 54–65
2015
-
[33]
OpenFHE: Open-Source Fully Homomorphic Encryption Library,
A. Al Badawi et al., “OpenFHE: Open-Source Fully Homomorphic Encryption Library,” inProc. WAHC ’22, 2022, pp. 53–63
2022
-
[34]
EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation,
R. Dathathri et al., “EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation,” inProc. ACM PLDI, 2020, pp. 546–561
2020
-
[35]
CHET: An Optimizing Compiler for Fully-Homomorphic Neural-Network Inferencing,
R. Dathathri et al., “CHET: An Optimizing Compiler for Fully-Homomorphic Neural-Network Inferencing,” inProc. ACM PLDI, 2019, pp. 142–156. 31
2019
-
[36]
Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimisation with GPUs,
W. Jung, S. Kim, J. H. Ahn et al., “Over 100x Faster Bootstrapping in Fully Homomorphic Encryption through Memory-centric Optimisation with GPUs,”IACR TCHES, vol. 2021, no. 4, pp. 114–148
2021
-
[37]
Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52,
F. Boemer et al., “Intel HEXL: Accelerating Homomorphic Encryption with Intel AVX512-IFMA52,” inProc. WAHC ’21, 2021, pp. 57–62
2021
-
[38]
Private Web Search with Tiptoe,
A. Henzinger, E. Dauterman, H. Corrigan-Gibbs, and N. Zeldovich, “Private Web Search with Tiptoe,” inProc. ACM SOSP, 2023
2023
-
[39]
PIR with Compressed Queries and Amortised Query Processing,
S. Angel, H. Chen, K. Laine, and S. Setty, “PIR with Compressed Queries and Amortised Query Processing,” inProc. IEEE S&P, 2018, pp. 962–979
2018
-
[40]
One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval (SimplePIR),
A. Henzinger, M. M. Hong, H. Corrigan-Gibbs, S. Meiklejohn, and V. Vaikuntanathan, “One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval (SimplePIR),” in Proc. USENIX Security, 2023
2023
-
[41]
OnionPIR: Response Efficient Single-Server PIR,
M. H. Mughees, H. Chen, and L. Ren, “OnionPIR: Response Efficient Single-Server PIR,” inProc. ACM CCS, 2021, pp. 2292–2306
2021
-
[42]
Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions,
N. Halko, P.-G. Martinsson, and J. A. Tropp, “Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions,”SIAM Review, vol. 53, no. 2, 2011, pp. 217–288
2011
-
[43]
Product Quantisation for Nearest Neighbor Search,
H. Jegou, M. Douze, and C. Schmid, “Product Quantisation for Nearest Neighbor Search,”IEEE TPAMI, vol. 33, no. 1, 2011, pp. 117–128
2011
-
[44]
The Approximation of One Matrix by Another of Lower Rank,
C. Eckart and G. Young, “The Approximation of One Matrix by Another of Lower Rank,”Psychome- trika, vol. 1, no. 3, 1936, pp. 211–218
1936
-
[45]
Extensions of Lipschitz Mappings into a Hilbert Space,
W. B. Johnson and J. Lindenstrauss, “Extensions of Lipschitz Mappings into a Hilbert Space,” Contemporary Mathematics, vol. 26, 1984, pp. 189–206
1984
-
[46]
Greedy Function Approximation: A Gradient Boosting Machine,
J. H. Friedman, “Greedy Function Approximation: A Gradient Boosting Machine,”Annals of Statistics, vol. 29, no. 5, 2001, pp. 1189–1232
2001
-
[47]
BLEU: a Method for Automatic Evaluation of Machine Translation,
K. Papineni et al., “BLEU: a Method for Automatic Evaluation of Machine Translation,” inProc. ACL, 2002, pp. 311–318
2002
-
[48]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,
P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” inProc. NeurIPS, 2020
2020
-
[49]
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models,
N. Thakur, N. Reimers, A. Rücklé, A. Srivastava, and I. Gurevych, “BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models,” inProc. NeurIPS Datasets and Benchmarks, 2021
2021
-
[50]
Searchable Symmetric Encryption: Improved Definitions and Efficient Constructions,
R. Curtmola, J. Garay, S. Kamara, and R. Ostrovsky, “Searchable Symmetric Encryption: Improved Definitions and Efficient Constructions,” inProc. ACM CCS, 2006, pp. 79–88
2006
-
[51]
Structured Encryption and Controlled Disclosure,
M. Chase and S. Kamara, “Structured Encryption and Controlled Disclosure,” inAdvances in Cryptology—ASIACRYPT, 2010, pp. 577–594
2010
-
[52]
Leakage-Abuse Attacks Against Searchable Encryption,
D. Cash, P. Grubbs, J. Perry, and T. Ristenpart, “Leakage-Abuse Attacks Against Searchable Encryption,” inProc. ACM CCS, 2015, pp. 668–679
2015
-
[53]
Access Pattern Disclosure on Searchable Encryption: Ramification, Attack and Mitigation,
M. S. Islam, M. Kuzu, and M. Kantarcioglu, “Access Pattern Disclosure on Searchable Encryption: Ramification, Attack and Mitigation,” inProc. NDSS, 2012
2012
-
[54]
D. Seputis, Y. Li, K. Langerak, and S. Mihailov, “Rethinking the Privacy of Text Embeddings: A Reproducibility Study of ‘Text Embeddings Reveal (Almost) As Much As Text’,” inProc. ACM RecSys, 2025.arXiv:2507.07700
-
[55]
S. M. Kurilenko, “Hybrid Method for Privacy-Preserving Semantic Search Based on Homomorphic Encryption and Random Projections,”Vestnik Komp’yuternykh i Informatsionnykh Tekhnologiy, no. 3, 2026, pp. 44–49. doi:10.14489/vkit.2026.03.pp.044-049. 32
-
[56]
S. M. Kurilenko, “Hybrid privacy-aware semantic search: SVD-truncated document geometry and CKKS-encrypted query reranking under a restricted threat model,”arXiv:2606.26373, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Z. Wan et al., “Transform Before You Query: A Privacy-Preserving Approach for Vector Retrieval with Embedding Space Alignment (STEER),”arXiv:2507.18518, 2025
-
[58]
Safeguarding LLM Embeddings in End-Cloud Collaboration via Entropy-Driven Perturbation (EntroGuard),
S. Wang et al., “Safeguarding LLM Embeddings in End-Cloud Collaboration via Entropy-Driven Perturbation (EntroGuard),”arXiv:2503.12896, 2025. 33
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.