JacobianAvatar: Temporally Consistent Semi-rigid Avatar Reconstruction from a Monocular Video
Pith reviewed 2026-07-01 05:59 UTC · model grok-4.3
The pith
Neural Jacobian fields solved via constrained Poisson equations reconstruct temporally consistent semi-rigid human avatars from monocular video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
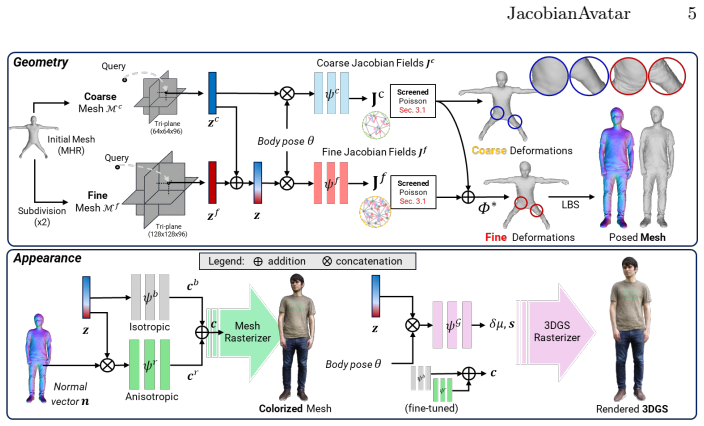
Neural Jacobian fields represent semi-rigid deformations by predicting Jacobian matrices whose integration is obtained by solving a Poisson equation; three added components—a constrained Poisson solver, signed distance-based Jacobian regularization, and deformation-guided residual flow loss—suppress boundary artifacts, recover frequently occluded regions such as armpits and thighs, and enforce temporal consistency during motion.
What carries the argument
Neural Jacobian fields (NJFs): self-supervised networks that predict pose-dependent Jacobian matrices, integrated through Poisson solving and regularized by the constrained solver, signed-distance term, and residual flow loss to handle monocular occlusions and motion.
If this is right
- The reconstructed avatars exhibit temporal stability and geometric coherence across frames.
- Occluded and invisible surfaces are recovered without additional views or sensors.
- Boundary artifacts that appear in earlier monocular methods are reduced.
- Performance exceeds state-of-the-art approaches on both benchmark datasets and unconstrained videos.
Where Pith is reading between the lines
- The same Jacobian representation and Poisson solving could be tested on non-human articulated objects if the deformation patterns are comparably semi-rigid.
- The residual flow loss term might transfer to other neural-field deformation models that already use flow supervision.
- If the method remains stable on longer sequences, it could support avatar creation pipelines that ingest casual phone footage without manual cleanup.
Load-bearing premise
The three introduced components are sufficient to suppress boundary artifacts and recover occluded regions such as armpits and thighs from monocular input alone.
What would settle it
Persistent boundary artifacts or visible failure to reconstruct occluded regions like armpits and thighs on benchmark or in-the-wild test sequences would show the components are not sufficient.
Figures


read the original abstract
Generating realistic human avatars in complex motions--such as clothing dynamics--requires modeling of global and local deformations which remains challenging in monocular settings. We address this problem by leveraging neural Jacobian fields (NJFs) for representing semi-rigid deformations. We train self-supervised neural networks for predicting Jacobian matrices that give the pose-dependent deformations, by solving a Poisson equation. However, monocular input presents several difficulties such as self-occluded regions and invisible surfaces. To address these issues, we introduce three key components: a constrained Poisson solver, signed distance-based Jacobian regularization, and a deformation-guided residual flow loss, which together suppress boundary artifacts, recover frequently occluded regions such as armpits and thighs, and enforce temporal consistency during motion. Experiments on benchmark and in-the-wild videos demonstrate that our method generates temporally stable and geometrically coherent avatars, outperforming state-of-the-art approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes JacobianAvatar, a method for reconstructing semi-rigid avatars from monocular video using neural Jacobian fields (NJFs). It trains self-supervised networks to predict Jacobian matrices for pose-dependent deformations by solving a Poisson equation. Three key components are introduced: a constrained Poisson solver, signed distance-based Jacobian regularization, and a deformation-guided residual flow loss to handle self-occlusions, boundary artifacts, and temporal consistency. The method is evaluated on benchmark and in-the-wild videos, claiming to outperform state-of-the-art approaches in generating temporally stable and geometrically coherent avatars.
Significance. If the experimental validation holds, the work could advance monocular 3D human reconstruction by offering a self-supervised NJF-based approach that targets occlusions and temporal stability without multi-view input. The three proposed components represent targeted technical contributions to deformation modeling.
major comments (1)
- [Abstract] Abstract: the claim that the three components (constrained Poisson solver, signed distance-based Jacobian regularization, and deformation-guided residual flow loss) are sufficient to suppress boundary artifacts and recover occluded regions such as armpits and thighs from monocular input alone is presented without any quantitative results, error analysis, or derivation details, making it impossible to verify whether the math and data support the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to clarify our presentation. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the three components (constrained Poisson solver, signed distance-based Jacobian regularization, and deformation-guided residual flow loss) are sufficient to suppress boundary artifacts and recover occluded regions such as armpits and thighs from monocular input alone is presented without any quantitative results, error analysis, or derivation details, making it impossible to verify whether the math and data support the outperformance claim.
Authors: The abstract is a concise high-level summary, as is conventional. Quantitative results (including metrics on temporal consistency, geometric error, and ablation studies isolating each of the three components), error analyses, and mathematical derivations for the constrained Poisson solver and regularizers are provided in Sections 3 and 4 of the manuscript. These experiments on benchmark and in-the-wild data support the claims regarding artifact suppression and occluded-region recovery from monocular video. The outperformance statements are grounded in those results. revision: no
Circularity Check
No significant circularity detected
full rationale
The derivation proceeds from neural prediction of Jacobian matrices, followed by integration via a constrained Poisson solver plus explicit regularization terms (signed-distance Jacobian and deformation-guided flow losses) to handle monocular ambiguities. These steps are additive design choices rather than reductions of outputs back to inputs by definition; the self-supervised objective is constructed from geometric consistency constraints that remain independent of the final avatar geometry. No self-citation chain, fitted-parameter renaming, or ansatz smuggling is required for the core pipeline, and the empirical claims rest on external benchmark comparisons rather than internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: SIGGRAPH Asia 2023 Technical Communications
Abdrashitov, R., Raichstat, K., Monsen, J., Hill, D.: Robust skin weights transfer via weight inpainting. In: SIGGRAPH Asia 2023 Technical Communications. SA ’23, Association for Computing Machinery, New York, NY, USA (2023).https: //doi.org/10.1145/3610543.3626180,https://doi.org/10.1145/3610543. 3626180
-
[2]
ACM TOG41(4) (2022)
Aigerman, N., Gupta, K., Kim, V.G., Chaudhuri, S., Saito, J., Groueix, T.: Neural jacobian fields: learning intrinsic mappings of arbitrary meshes. ACM TOG41(4) (2022)
2022
-
[3]
In: 2018 International Conference on 3D Vision (3DV)
Alldieck, T., Magnor, M., Xu, W., Theobalt, C., Pons-Moll, G.: Detailed human avatars from monocular video. In: 2018 International Conference on 3D Vision (3DV). pp. 98–109. IEEE (2018) 16 C. Won et al
2018
-
[4]
In: CVPR (2025)
Chen, H., Peng, B., Tao, Y., Zhang, J.: Dˆ 3-human: Dynamic disentangled digital human from monocular video. In: CVPR (2025)
2025
-
[5]
In: ICCV (2021)
Chen, X., Zheng, Y., Black, M.J., Hilliges, O., Geiger, A.: SNARF: Differentiable forward skinning for animating non-rigid neural implicit shapes. In: ICCV (2021)
2021
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cheng, W., Chen, R., Fan, S., Yin, W., Chen, K., Cai, Z., Wang, J., Gao, Y., Yu, Z., Lin, Z., et al.: Dna-rendering: A diverse neural actor repository for high- fidelity human-centric rendering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19982–19993 (2023)
2023
-
[7]
In: SIGGRAPH Asia 2022 Conference Papers
Feng,Y.,Yang,J.,Pollefeys,M.,Black,M.J.,Bolkart,T.:Capturingandanimation of body and clothing from monocular video. In: SIGGRAPH Asia 2022 Conference Papers. pp. 1–9 (2022)
2022
-
[8]
Ferguson, A., Osman, A.A.A., Bescos, B., Stoll, C., Twigg, C., Lassner, C., Otte, D., Vignola, E., Prada, F., Bogo, F., Santesteban, I., Romero, J., Zarate, J., Lee, J., Park, J., Yang, J., Doublestein, J., Venkateshan, K., Kitani, K., Kavan, L., Farra, M.D., Hu, M., Cioffi, M., Fabris, M., Ranieri, M., Modarres, M., Kadlecek, P., Khirodkar, R., Abdrashit...
-
[9]
In: CVPR (2023)
Guo, C., Jiang, T., Chen, X., Song, J., Hilliges, O.: Vid2avatar: 3d avatar re- construction from videos in the wild via self-supervised scene decomposition. In: CVPR (2023)
2023
-
[10]
In: CVPR (June 2025)
Guo, C., Li, J., Kant, Y., Sheikh, Y., Saito, S., Cao, C.: Vid2avatar-pro: Authentic avatar from videos in the wild via universal prior. In: CVPR (June 2025)
2025
-
[11]
In: CVPR (2024)
Ho, I., Song, J., Hilliges, O.: Sith: Single-view textured human reconstruction with image-conditioned diffusion. In: CVPR (2024)
2024
-
[12]
In: CVPR (2024)
Hu, L., Zhang, H., Zhang, Y., Zhou, B., Liu, B., Zhang, S., Nie, L.: GaussianAvatar: Towards realistic human avatar modeling from a single video via animatable 3D gaussians. In: CVPR (2024)
2024
-
[13]
In: NeurIPS (2023)
Huang, Y., Wang, J., Zeng, A., Cao, H., Qi, X., Shi, Y., Zha, Z.J., Zhang, L.: DreamWaltz: Make a scene with complex 3D animatable avatars. In: NeurIPS (2023)
2023
-
[14]
In: CVPR (2021)
Jafarian, Y., Park, H.S.: Learning high fidelity depths of dressed humans by watch- ing social media dance videos. In: CVPR (2021)
2021
-
[15]
In: CVPR (2022)
Jiang, B., Hong, Y., Bao, H., Zhang, J.: SelfRecon: Self reconstruction your digital avatar from monocular video. In: CVPR (2022)
2022
-
[16]
In: CVPR (2023)
Jiang, T., Chen, X., Song, J., Hilliges, O.: Instantavatar: Learning avatars from monocular video in 60 seconds. In: CVPR (2023)
2023
-
[17]
In: ECCV (2022)
Jiang, W., Yi, K.M., Samei, G., Tuzel, O., Ranjan, A.: NeuMan: Neural human radiance field from a single video. In: ECCV (2022)
2022
-
[18]
ACM Transac- tions on Graphics (ToG)32(3), 1–13 (2013)
Kazhdan, M., Hoppe, H.: Screened poisson surface reconstruction. ACM Transac- tions on Graphics (ToG)32(3), 1–13 (2013)
2013
-
[19]
ACM TOG42(4) (2023)
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM TOG42(4) (2023)
2023
-
[20]
In: ECCV (2024)
Khirodkar, R., Bagautdinov, T., Martinez, J., Zhaoen, S., James, A., Selednik, P., Anderson, S., Saito, S.: Sapiens: Foundation for human vision models. In: ECCV (2024)
2024
-
[21]
In: ECCV (2024)
Kratimenos, A., Lei, J., Daniilidis, K.: Dynmf: Neural motion factorization for real-time dynamic view synthesis with 3d gaussian splatting. In: ECCV (2024)
2024
-
[22]
ACM TOG39(6) (2020) JacobianAvatar 17
Laine, S., Hellsten, J., Karras, T., Seol, Y., Lehtinen, J., Aila, T.: Modular primi- tives for high-performance differentiable rendering. ACM TOG39(6) (2020) JacobianAvatar 17
2020
-
[23]
In: CVPR (2025)
Lei, J., Weng, Y., Harley, A.W., Guibas, L., Daniilidis, K.: Mosca: Dynamic gaus- sian fusion from casual videos via 4d motion scaffolds. In: CVPR (2025)
2025
-
[24]
In: CVPR (2025)
Li, P., Zheng, W., Liu, Y., Yu, T., Li, Y., Qi, X., Chi, X., Xia, S., Cao, Y.P., Xue, W., Luo, W., Guo, Y.: Pshuman: Photorealistic single-image 3d human recon- struction using cross-scale multiview diffusion and explicit remeshing. In: CVPR (2025)
2025
-
[25]
In: Proceedings of the IEEE/CVF international conference on computer vision
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Ai choreographer: Music conditioned 3d dance generation with aist++. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13401–13412 (2021)
2021
-
[26]
In: CVPR (2024)
Li, Z., Zheng, Z., Wang, L., Liu, Y.: Animatable gaussians: Learning pose- dependent gaussian maps for high-fidelity human avatar modeling. In: CVPR (2024)
2024
-
[27]
In: CVPR (2024)
Liu, X., Zhan, X., Tang, J., Shan, Y., Zeng, G., Lin, D., Liu, X., Liu, Z.: Human- Gaussian: Text-driven 3D human generation with gaussian splatting. In: CVPR (2024)
2024
-
[28]
ACM TOG34(6) (Oct 2015)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM TOG34(6) (Oct 2015)
2015
-
[29]
In: CVPR (2021)
Ma, Q., Saito, S., Yang, J., Tang, S., Black, M.J.: SCALE: Modeling clothed hu- mans with a surface codec of articulated local elements. In: CVPR (2021)
2021
-
[30]
In: ECCV (2024)
Moon, G., Shiratori, T., Saito, S.: Expressive whole-body 3d gaussian avatar. In: ECCV (2024)
2024
-
[31]
In: CVPR (June 2015)
Newcombe,R.A.,Fox,D.,Seitz,S.M.:Dynamicfusion:Reconstructionandtracking of non-rigid scenes in real-time. In: CVPR (June 2015)
2015
-
[32]
ACM Transactions on Graphics (TOG)40(6), 1–13 (2021)
Nicolet, B., Jacobson, A., Jakob, W.: Large steps in inverse rendering of geometry. ACM Transactions on Graphics (TOG)40(6), 1–13 (2021)
2021
-
[33]
In: CVPR (2019)
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: CVPR (2019)
2019
-
[34]
In: CVPR (2019)
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single image. In: CVPR (2019)
2019
-
[35]
In: CVPR (2024)
Qian, Z., Wang, S., Mihajlovic, M., Geiger, A., Tang, S.: 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. In: CVPR (2024)
2024
-
[36]
Advances in Neural Infor- mation Processing Systems33, 22468–22478 (2020)
Remelli, E., Lukoianov, A., Richter, S., Guillard, B., Bagautdinov, T., Baque, P., Fua, P.: Meshsdf: Differentiable iso-surface extraction. Advances in Neural Infor- mation Processing Systems33, 22468–22478 (2020)
2020
-
[37]
In: CVPR (2021)
Saito, S., Yang, J., Ma, Q., Black, M.J.: SCANimate: Weakly supervised learning of skinned clothed avatar networks. In: CVPR (2021)
2021
-
[38]
In: ICCV (2025)
Saleh, F., Aliakbarian, S., Hewitt, C., Petikam, L., Xiao, X., Criminisi, A., Cash- man, T.J., Baltrusaitis, T.: David: Data-efficient and accurate vision models from synthetic data. In: ICCV (2025)
2025
-
[39]
In: CVPR (2024)
Shao, Z., Wang, Z., Li, Z., Wang, D., Lin, X., Zhang, Y., Fan, M., Wang, Z.: Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting. In: CVPR (2024)
2024
-
[40]
In: ECCV (2024)
Shin, J., Lee, J., Lee, S., Park, M.G., Kang, J.M., Yoon, J.H., Jeon, H.G.: Canoni- calFusion: Generating drivable 3D human avatars from multiple images. In: ECCV (2024)
2024
-
[41]
In: ICCV (2025)
Sim, G., Moon, G.: PERSONA: Personalized whole-body 3D avatar with pose- driven deformations from a single image. In: ICCV (2025)
2025
-
[42]
arXiv preprint arXiv:2308.11951 (2023) 18 C
Song, C., Wandt, B., Rhodin, H.: Pose modulated avatars from video. arXiv preprint arXiv:2308.11951 (2023) 18 C. Won et al
-
[43]
In: The Thirteenth International Conference on Learning Rep- resentations (2025)
Song, C., Wu, Z., Su, S.Y., Wandt, B., Sigal, L., Rhodin, H.: Locality sensitive avatars from video. In: The Thirteenth International Conference on Learning Rep- resentations (2025)
2025
-
[44]
In: Computer Graphics Forum
Song, C., Wu, Z., Wandt, B., Sigal, L., Rhodin, H.: Representing animatable avatar via factorized neural fields. In: Computer Graphics Forum. vol. 44, p. e70192. Wiley Online Library (2025)
2025
-
[45]
In: ECCV
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: ECCV. Springer (2020)
2020
-
[46]
In: ICCV (2025)
Wang, Q., Ye, V., Gao, H., Zeng, W., Austin, J., Li, Z., Kanazawa, A.: Shape of motion: 4d reconstruction from a single video. In: ICCV (2025)
2025
-
[47]
Wang, S., Simon, T., Santesteban, I., Bagautdinov, T., Li, J., Agrawal, V., Prada, F., Yu, S.I., Nalbone, P., Gramlich, M., Lubachersky, R., Wu, C., Romero, J., Saragih, J., Zollhoefer, M., Geiger, A., Tang, S., Saito, S.: Relightable full-body gaussian codec avatars. ACM TOG2501.14726(2025)
-
[48]
arXiv preprint arXiv:2506.21526 (2025)
Wang, Y., Deng, J.: Waft: Warping-alone field transforms for optical flow. arXiv preprint arXiv:2506.21526 (2025)
-
[49]
In: ECCV
Wang, Y., Lipson, L., Deng, J.: Sea-raft: Simple, efficient, accurate raft for optical flow. In: ECCV. Springer (2024)
2024
-
[50]
In: CVPR (2024)
Wen, J., Zhao, X., Ren, Z., Schwing, A.G., Wang, S.: Gomavatar: Efficient animat- able human modeling from monocular video using gaussians-on-mesh. In: CVPR (2024)
2024
-
[51]
In: CVPR (2022)
Weng, C.Y., Curless, B., Srinivasan, P.P., Barron, J.T., Kemelmacher-Shlizerman, I.: HumanNeRF: Free-viewpoint rendering of moving people from monocular video. In: CVPR (2022)
2022
-
[52]
In: CVPR (2024)
Wu,R.,Mildenhall,B.,Henzler,P.,Park,K.,Gao,R.,Watson,D.,Srinivasan,P.P., Verbin, D., Barron, J.T., Poole, B., Hoyński, A.: Reconfusion: 3d reconstruction with diffusion priors. In: CVPR (2024)
2024
-
[53]
Structured 3D Latents for Scalable and Versatile 3D Generation
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
ACM TOG37(2) (2018)
Xu, W., Chatterjee, A., Zollhöfer, M., Rhodin, H., Mehta, D., Seidel, H.P., Theobalt, C.: Monoperfcap: Human performance capture from monocular video. ACM TOG37(2) (2018)
2018
-
[55]
In: CVPR (2024)
Zhang, J., Li, X., Zhang, Q., Cao, Y., Shan, Y., Liao, J.: Humanref: Single image to 3d human generation via reference-guided diffusion. In: CVPR (2024)
2024
-
[56]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zhao, Z., Lai, Z., Lin, Q., Zhao, Y., Liu, H., Yang, S., Feng, Y., Yang, M., Zhang, S., Yang, X., et al.: Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation. arXiv preprint arXiv:2501.12202 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019) JacobianAvatar 19 Supplementary Material A Demonstration of A vatar Animation We provide a supplementary video showcasing the animati...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.