How Optimality Structures Sparse Dictionaries: A Theory for Understanding SAE Representations
Pith reviewed 2026-06-28 11:34 UTC · model grok-4.3
The pith
Local optimality under L1 nonnegativity imposes distribution-dependent constraints on SAE features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
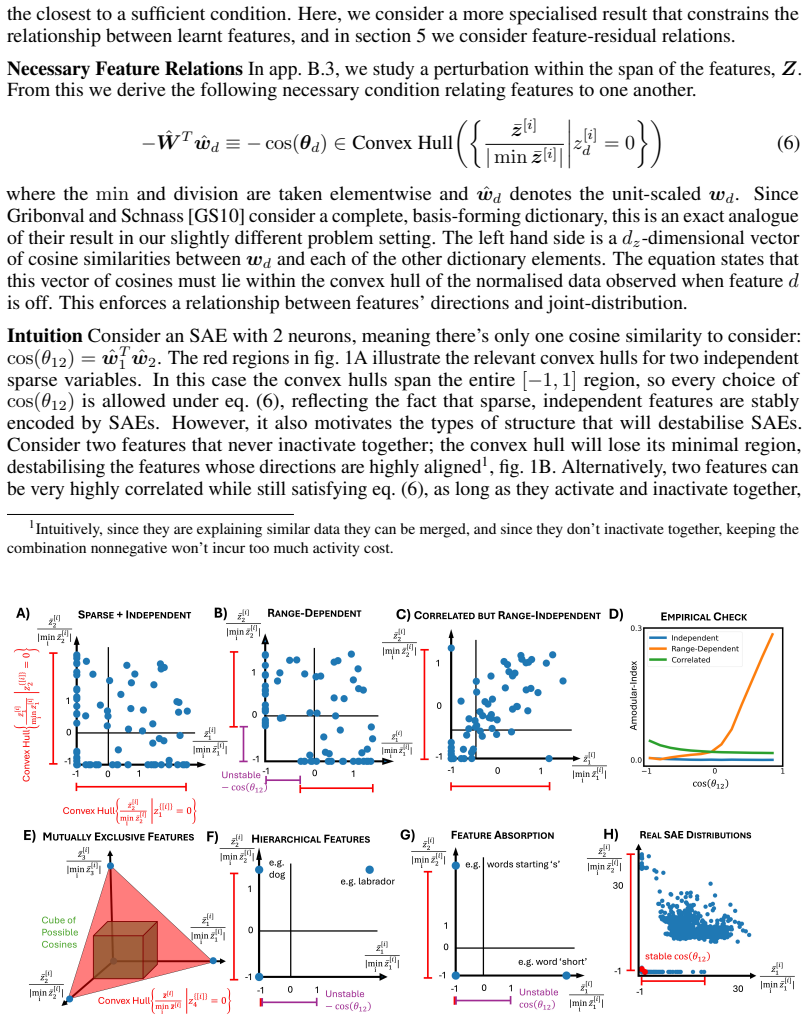
Extending local optimality analysis to the nonnegative joint-optimization problem that vanilla SAEs approximate yields explicit constraints relating each optimal atom to the distribution of points it represents. These constraints explain a range of observed SAE behaviors—hierarchical splitting and absorption, the structure of residuals, and dense antipodal features—as direct consequences of how L1 plus nonnegativity interact with data at stationarity.
What carries the argument
The stationarity constraints obtained by setting the gradient of the L1-nonnegative reconstruction objective to zero, which enforce that each optimal atom aligns with a weighted sum of the data points it activates on.
If this is right
- Hierarchical splitting occurs when a single atom can be replaced by two or more atoms whose activation distributions better satisfy the stationarity conditions.
- Residual vectors must lie in directions that cannot improve the objective by adding a new atom under the current nonnegativity and L1 penalty.
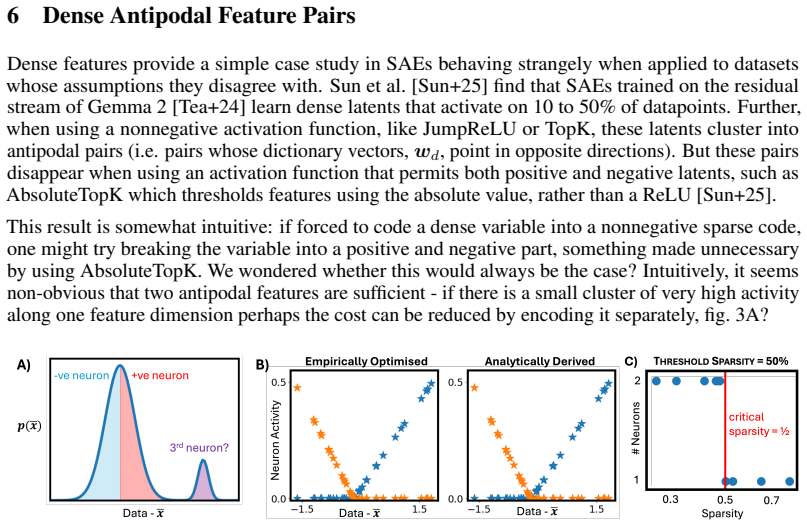
- Dense antipodal features appear when positive and negative directions both achieve stationarity for opposing subsets of the data distribution.
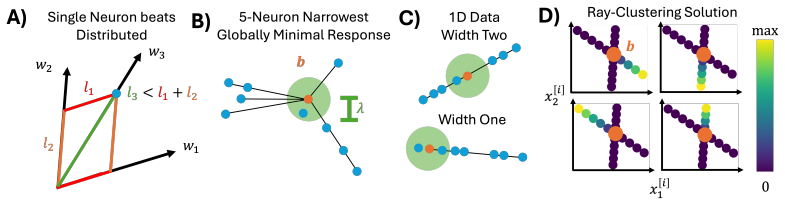
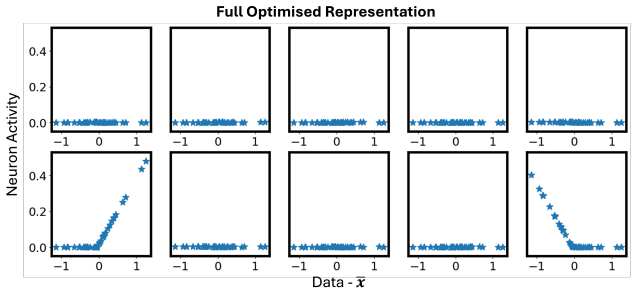
- The wide atom-per-datapoint limit yields a convex problem whose solutions are fully characterized by the same stationarity relations.
Where Pith is reading between the lines
- The same stationarity analysis could be applied to other sparse coding objectives to predict which features will be recovered under different regularizers.
- Training trajectories that remain far from these stationarity conditions may produce less interpretable dictionaries even at convergence.
- Design choices such as the choice of activation function or additional penalties can be evaluated by whether they preserve or relax the derived constraints.
Load-bearing premise
Observed SAE patterns arise from the local optimality conditions of the objective rather than from optimization dynamics, initialization, or finite-sample effects.
What would settle it
An SAE trained to a local minimum whose learned features systematically violate the derived stationarity constraints on a controlled dataset would falsify the claim.
Figures

read the original abstract
Sparse Autoencoders (SAEs) have found success parsing neural representations into interpretable concepts, providing a basis for understanding and control. However, what exactly SAEs extract, and, correspondingly, the scientific conclusions we can draw from them, are not obvious. Empirically, the proof is in the pudding: SAEs learn interpretable features. Theoretically, we lack a clear account of what properties a 'concept' must satisfy for an SAE to extract it. There has been extensive identifiability work studying the conditions under which sparse coding recovers ground-truth features; however, these approaches tends to focus on simple data-generating models (e.g. sparse independent features) which poorly approximate the internet-swallowing language-model representations on which SAEs are trained. Here, avoiding data-generating models, we ask simply what properties any dictionary learning optimum must satisfy. Concretely, we extend local optimality analyses (Gribonval & Schnass, 2010) to the nonnegative joint-optimisation problem that vanilla SAEs approximate, and derive constraints relating optimal SAE features to their distributions. We use these constraints to explain a range of observed SAE behaviours - hierarchical splitting & absorption, the structure of residuals, and dense antipodal features - each reflecting how L1+nonnegativity interact with data to structure optimal dictionaries. Finally, we construct a novel large-dictionary convex problem and explore the wide atom-per-datapoint limit. In sum, we hope to tease model assumptions from unexpected observations, letting us learn more from SAEs' successes and provide principles for designing their successors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends local optimality analyses from Gribonval & Schnass (2010) to the nonnegative joint-optimization problem approximated by vanilla sparse autoencoders (SAEs). It derives stationarity constraints relating optimal SAE features (norms, supports) to data distributions, then applies these to explain empirical behaviors including hierarchical splitting/absorption, residual structure, and dense antipodal features. The work avoids data-generating models, introduces a novel large-dictionary convex relaxation, and examines the wide atom-per-datapoint limit.
Significance. If the stationarity constraints hold and trained SAEs are near the derived local optima, the results supply a model-free account of what properties SAE features must satisfy, moving beyond identifiability results that rely on simple sparse independent feature models. The nonnegative joint-optimization extension and convex large-dictionary construction are concrete strengths that could inform SAE design and interpretation.
major comments (2)
- [§4] §4 (mapping of constraints to behaviors): The explanatory claims for hierarchical splitting, residual structure, and antipodal features rest on the premise that trained SAEs lie at or near points satisfying the exact stationarity conditions derived from the L1-nonnegative objective. The manuscript provides no auxiliary analysis or bounds showing that SGD/Adam trajectories on the non-convex SAE loss reliably reach such points, nor does it quantify the contribution of initialization or finite-sample effects; this assumption is load-bearing for the central claim that optimality structures the observed representations.
- [§3] §3 (stationarity derivation): The extension of Gribonval & Schnass (2010) to the joint nonnegative setting is presented as yielding constraints that survive nonnegativity, but the text does not explicitly verify that the derived conditions remain valid under the joint optimization of dictionary and codes (as opposed to alternating minimization) or under the specific L1 penalty and nonnegativity constraints used in vanilla SAEs.
minor comments (2)
- [§3] Notation for the stationarity conditions (e.g., the precise form of the subdifferential or support constraints) should be cross-referenced to the original Gribonval & Schnass equations for easier comparison.
- [final section] The convex large-dictionary problem in the final section would benefit from an explicit statement of its relationship to the non-convex SAE objective (e.g., whether it is a relaxation or an approximation in a specific limit).
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help clarify the scope and assumptions of our theoretical analysis. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§4] §4 (mapping of constraints to behaviors): The explanatory claims for hierarchical splitting, residual structure, and antipodal features rest on the premise that trained SAEs lie at or near points satisfying the exact stationarity conditions derived from the L1-nonnegative objective. The manuscript provides no auxiliary analysis or bounds showing that SGD/Adam trajectories on the non-convex SAE loss reliably reach such points, nor does it quantify the contribution of initialization or finite-sample effects; this assumption is load-bearing for the central claim that optimality structures the observed representations.
Authors: We acknowledge that the manuscript does not include convergence analysis or bounds demonstrating that SGD/Adam trajectories reach the derived stationarity points, nor does it quantify effects from initialization or finite samples. The paper's primary contribution is the derivation of necessary optimality conditions for the nonnegative joint objective, which explain observed behaviors under the assumption that trained SAEs are near such points. We will add an explicit discussion section in the revision acknowledging this assumption, its load-bearing role, and outlining it as an important direction for future work on optimization dynamics. The constraints themselves remain valid characterizations of the optima independent of the path taken. revision: partial
-
Referee: [§3] §3 (stationarity derivation): The extension of Gribonval & Schnass (2010) to the joint nonnegative setting is presented as yielding constraints that survive nonnegativity, but the text does not explicitly verify that the derived conditions remain valid under the joint optimization of dictionary and codes (as opposed to alternating minimization) or under the specific L1 penalty and nonnegativity constraints used in vanilla SAEs.
Authors: The stationarity conditions in §3 are derived directly from the subdifferential of the joint objective (dictionary and codes optimized simultaneously) under the exact L1 penalty and nonnegativity constraints of vanilla SAEs. This differs from alternating minimization by construction. We will revise the manuscript to include an explicit verification step and additional text clarifying that the extension applies to the joint (end-to-end) optimization setting, confirming the conditions hold for the specific SAE objective rather than an alternating procedure. revision: yes
Circularity Check
No circularity: derivation extends external stationarity conditions without reduction to inputs
full rationale
The paper extends the local optimality analysis of Gribonval & Schnass (2010) to derive stationarity constraints for the nonnegative joint L1-penalized dictionary learning problem, then applies those constraints to interpret SAE behaviors. This is a forward mathematical derivation from cited external conditions rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equation or claim reduces the result to its own inputs by construction, and the central explanatory step rests on the independent extension rather than on the observations it interprets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the National Academy of Sciences , volume=
Understanding the computation of time using neural network models , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[2]
Nature neuroscience , volume=
Task representations in neural networks trained to perform many cognitive tasks , author=. Nature neuroscience , volume=. 2019 , publisher=
2019
-
[3]
Nature Neuroscience , volume=
Schema formation in a neural population subspace underlies learning-to-learn in flexible sensorimotor problem-solving , author=. Nature Neuroscience , volume=. 2023 , publisher=
2023
-
[4]
Science , volume=
Geometry of sequence working memory in macaque prefrontal cortex , author=. Science , volume=. 2022 , publisher=
2022
-
[5]
International Conference on Machine Learning , pages=
The neural race reduction: Dynamics of abstraction in gated networks , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[6]
The Twelfth International Conference on Learning Representations , year=
Discovering modular solutions that generalize compositionally , author=. The Twelfth International Conference on Learning Representations , year=
-
[7]
Nature neuroscience , volume=
Independent generation of sequence elements by motor cortex , author=. Nature neuroscience , volume=. 2021 , publisher=
2021
-
[8]
Elife , volume=
Motor cortex signals for each arm are mixed across hemispheres and neurons yet partitioned within the population response , author=. Elife , volume=. 2019 , publisher=
2019
-
[9]
eneuro , volume=
The largest response component in the motor cortex reflects movement timing but not movement type , author=. eneuro , volume=. 2016 , publisher=
2016
-
[10]
Advances in Neural Information Processing Systems , volume=
The clock and the pizza: Two stories in mechanistic explanation of neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
bioRxiv , pages=
Building compositional tasks with shared neural subspaces , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[12]
The Eleventh International Conference on Learning Representations , year=
Disentanglement with biological constraints: A theory of functional cell types , author=. The Eleventh International Conference on Learning Representations , year=
-
[13]
2023 , booktitle=
On the specialization of neural modules , author=. 2023 , booktitle=
2023
-
[14]
Neuron , volume=
A multiplexed, heterogeneous, and adaptive code for navigation in medial entorhinal cortex , author=. Neuron , volume=. 2017 , publisher=
2017
-
[15]
Nature , volume=
The importance of mixed selectivity in complex cognitive tasks , author=. Nature , volume=. 2013 , publisher=
2013
-
[16]
Current opinion in neurobiology , volume=
Why neurons mix: high dimensionality for higher cognition , author=. Current opinion in neurobiology , volume=. 2016 , publisher=
2016
-
[17]
nature , volume=
Context-dependent computation by recurrent dynamics in prefrontal cortex , author=. nature , volume=. 2013 , publisher=
2013
-
[18]
International Conference on Machine Learning , year=
Tripod: Three Complementary Inductive Biases for Disentangled Representation Learning , author=. International Conference on Machine Learning , year=
-
[19]
Advances in Neural Information Processing Systems , volume=
Disentanglement via latent quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Advances in Neural Information Processing Systems , volume=
Conditional Mutual Information for Disentangled Representations in Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
The Eleventh International Conference on Learning Representations , year=
Disentanglement of Correlated Factors via Hausdorff Factorized Support , author=. The Eleventh International Conference on Learning Representations , year=
-
[22]
International Conference on Learning Representations , year=
A Theory of Usable Information under Computational Constraints , author=. International Conference on Learning Representations , year=
-
[23]
PloS one , volume=
Mutual information between discrete and continuous data sets , author=. PloS one , volume=. 2014 , publisher=
2014
-
[24]
High resolution disentanglement datasets , author =
-
[25]
Sensory communication , volume=
Possible principles underlying the transformation of sensory messages , author=. Sensory communication , volume=
-
[26]
, author=
Some informational aspects of visual perception. , author=. Psychological review , volume=. 1954 , publisher=
1954
-
[27]
Neuron , volume=
Synaptic energy use and supply , author=. Neuron , volume=. 2012 , publisher=
2012
-
[28]
Advances in neural information processing systems , volume=
A simple weight decay can improve generalization , author=. Advances in neural information processing systems , volume=
-
[29]
Current opinion in neurobiology , volume=
Energy as a constraint on the coding and processing of sensory information , author=. Current opinion in neurobiology , volume=. 2001 , publisher=
2001
-
[30]
Current opinion in neurobiology , volume=
Efficient information coding and degeneracy in the nervous system , author=. Current opinion in neurobiology , volume=. 2022 , publisher=
2022
-
[31]
IEEE Transactions on Automatic Control , volume=
Inequalities for the trace of matrix product , author=. IEEE Transactions on Automatic Control , volume=. 1994 , publisher=
1994
-
[32]
BIT Numerical Mathematics , volume=
Perturbation bounds for means of eigenvalues and invariant subspaces , author=. BIT Numerical Mathematics , volume=. 1970 , publisher=
1970
-
[33]
Soudry, Daniel and Speiser, Dror , title =. 2015
2015
-
[34]
Ravsky, Alex , title =. 2025
2025
-
[35]
Statistics & Probability Letters , volume=
Sharp lower and upper bounds for the covariance of bounded random variables , author=. Statistics & Probability Letters , volume=. 2022 , publisher=
2022
-
[36]
Advances in neural information processing systems , volume=
Learning dynamics of deep linear networks with multiple pathways , author=. Advances in neural information processing systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Organizing recurrent network dynamics by task-computation to enable continual learning , author=. Advances in neural information processing systems , volume=
-
[38]
arXiv preprint arXiv:2402.18361 , year=
Why Do Animals Need Shaping? A Theory of Task Composition and Curriculum Learning , author=. arXiv preprint arXiv:2402.18361 , year=
-
[39]
Nature , volume=
Microstructure of a spatial map in the entorhinal cortex , author=. Nature , volume=. 2005 , publisher=
2005
-
[40]
The Journal of physiology , volume=
Receptive fields, binocular interaction and functional architecture in the cat's visual cortex , author=. The Journal of physiology , volume=. 1962 , publisher=
1962
-
[41]
A framework for the quantitative evaluation of disentangled representations , author =
-
[42]
Neuron , year=
Mixed selectivity: Cellular computations for complexity , author=. Neuron , year=
-
[43]
Cell , volume=
The geometry of abstraction in the hippocampus and prefrontal cortex , author=. Cell , volume=. 2020 , publisher=
2020
-
[44]
Advances in Neural Information Processing Systems , volume=
Explaining heterogeneity in medial entorhinal cortex with task-driven neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Nature , volume=
Shared mechanisms underlie the control of working memory and attention , author=. Nature , volume=. 2021 , publisher=
2021
-
[46]
Nature Reviews Neuroscience , volume=
Two views on the cognitive brain , author=. Nature Reviews Neuroscience , volume=. 2021 , publisher=
2021
-
[47]
Nature neuroscience , volume=
Cerebellar granule cell axons support high-dimensional representations , author=. Nature neuroscience , volume=. 2021 , publisher=
2021
-
[48]
Neuron , year=
Tuned geometries of hippocampal representations meet the computational demands of social memory , author=. Neuron , year=
-
[49]
Cell , volume=
The Tolman-Eichenbaum machine: unifying space and relational memory through generalization in the hippocampal formation , author=. Cell , volume=. 2020 , publisher=
2020
-
[50]
Nature , pages=
A cellular basis for mapping behavioural structure , author=. Nature , pages=. 2024 , publisher=
2024
-
[51]
, author=
Short-term memory for serial order: a recurrent neural network model. , author=. Psychological review , volume=. 2006 , publisher=
2006
-
[52]
Nature , volume=
The orbitofrontal cortex maps future navigational goals , author=. Nature , volume=. 2021 , publisher=
2021
-
[53]
Adam: A Method for Stochastic Optimization
Kingma, Diederik P. and Ba, Jimmy , keywords =. Adam: A Method for Stochastic Optimization , publisher =. 2014 , copyright =. doi:10.48550/ARXIV.1412.6980 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2014
-
[54]
Cell reports , volume=
Thalamic control of cortical dynamics in a model of flexible motor sequencing , author=. Cell reports , volume=. 2021 , publisher=
2021
-
[55]
Journal of Neuroscience , volume=
Task-dependent changes in short-term memory in the prefrontal cortex , author=. Journal of Neuroscience , volume=. 2010 , publisher=
2010
-
[56]
bioRxiv , pages=
Coding of time with non-linear mixed selectivity in Prefrontal Cortex ensembles , author=. bioRxiv , pages=. 2023 , publisher=
2023
-
[57]
Object-vector coding in the medial entorhinal cortex , volume =
Høydal,. Object-vector coding in the medial entorhinal cortex , volume =. Nature , publisher =. 2019 , month = apr, pages =. doi:10.1038/s41586-019-1077-7 , number =
-
[58]
PLoS Computational Biology , volume=
A recurrent neural network model of prefrontal brain activity during a working memory task , author=. PLoS Computational Biology , volume=. 2023 , publisher=
2023
-
[59]
Nature neuroscience , volume=
Mixed selectivity morphs population codes in prefrontal cortex , author=. Nature neuroscience , volume=. 2017 , publisher=
2017
-
[60]
Eneuro , volume=
More prominent nonlinear mixed selectivity in the dorsolateral prefrontal than posterior parietal cortex , author=. Eneuro , volume=. 2022 , publisher=
2022
-
[61]
Journal of Neuroscience , volume=
Emergence of nonlinear mixed selectivity in prefrontal cortex after training , author=. Journal of Neuroscience , volume=. 2021 , publisher=
2021
-
[62]
arXiv preprint arXiv:2401.12181 , year=
Universal neurons in gpt2 language models , author=. arXiv preprint arXiv:2401.12181 , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Biologically-plausible determinant maximization neural networks for blind separation of correlated sources , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
IEEE Transactions on Neural Networks , volume=
Algorithms for nonnegative independent component analysis , author=. IEEE Transactions on Neural Networks , volume=. 2003 , publisher=
2003
-
[65]
Neural computation , volume=
A hebbian/anti-hebbian neural network for linear subspace learning: A derivation from multidimensional scaling of streaming data , author=. Neural computation , volume=. 2015 , publisher=
2015
-
[66]
Neural computation , volume=
An information-maximization approach to blind separation and blind deconvolution , author=. Neural computation , volume=. 1995 , publisher=
1995
-
[67]
IEEE Transactions on Signal Processing , volume=
Polytopic matrix factorization: Determinant maximization based criterion and identifiability , author=. IEEE Transactions on Signal Processing , volume=. 2021 , publisher=
2021
-
[68]
Neural computation , volume=
Blind nonnegative source separation using biological neural networks , author=. Neural computation , volume=. 2017 , publisher=
2017
-
[69]
2014 48th Asilomar Conference on Signals, Systems and Computers , pages=
An extended family of bounded component analysis algorithms , author=. 2014 48th Asilomar Conference on Signals, Systems and Computers , pages=. 2014 , organization=
2014
-
[70]
ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Generalized polytopic matrix factorization , author=. ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2021 , organization=
2021
-
[71]
The head direction signal: origins and sensory-motor integration , author=. Annu. Rev. Neurosci. , volume=. 2007 , publisher=
2007
-
[72]
Nature neuroscience , volume=
The role of population structure in computations through neural dynamics , author=. Nature neuroscience , volume=. 2022 , publisher=
2022
-
[73]
Nature , volume=
The entorhinal grid map is discretized , author=. Nature , volume=. 2012 , publisher=
2012
-
[74]
SIAM Journal on numerical analysis , volume=
The differentiation of pseudo-inverses and nonlinear least squares problems whose variables separate , author=. SIAM Journal on numerical analysis , volume=. 1973 , publisher=
1973
-
[75]
Siam journal on applied mathematics , volume=
Generalized inversion of modified matrices , author=. Siam journal on applied mathematics , volume=. 1973 , publisher=
1973
-
[76]
Cambridge UP , year=
Convex optimization , author=. Cambridge UP , year=
-
[77]
The Thirteenth International Conference on Learning Representations , year =
Range, not Independence, Drives Modularity in Biologically Inspired Representations , author=. The Thirteenth International Conference on Learning Representations , year =
-
[78]
Advances in Neural Information Processing Systems , volume=
Translation-equivariant representation in recurrent networks with a continuous manifold of attractors , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
Elife , volume=
Population codes enable learning from few examples by shaping inductive bias , author=. Elife , volume=. 2022 , publisher=
2022
-
[80]
arXiv preprint arXiv:2212.04180 , year=
evosax: JAX-based Evolution Strategies , author=. arXiv preprint arXiv:2212.04180 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.