Video2Code: Generating Interactive Webpages from UI Videos via Action-Aware Revisit
Pith reviewed 2026-06-27 00:59 UTC · model grok-4.3
The pith
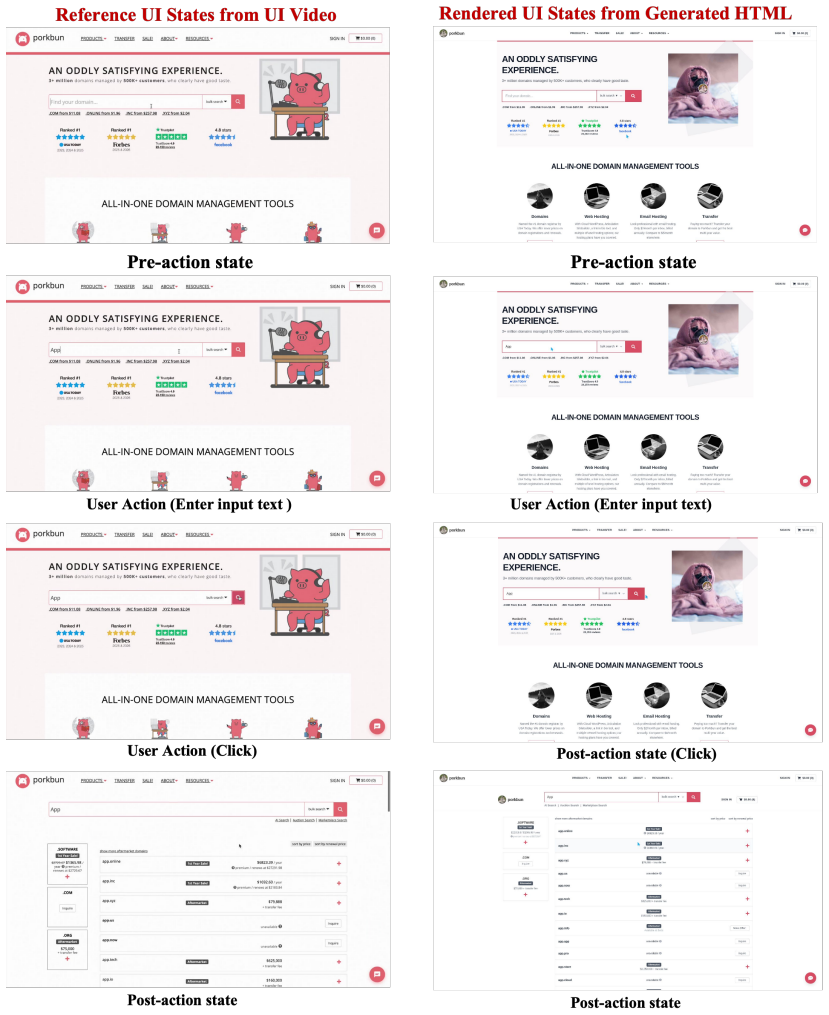
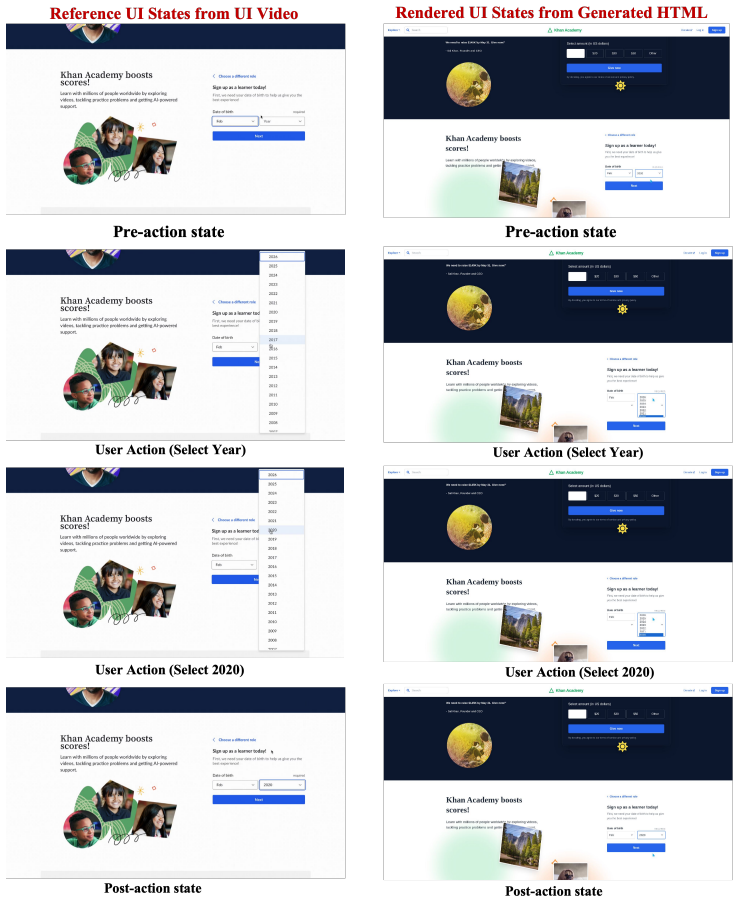
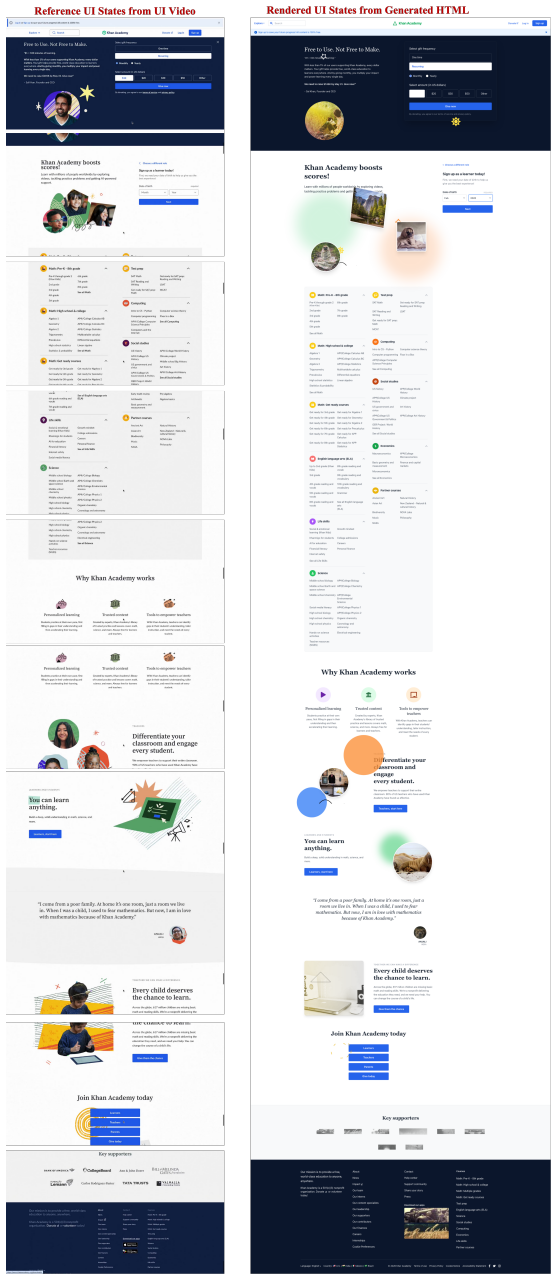
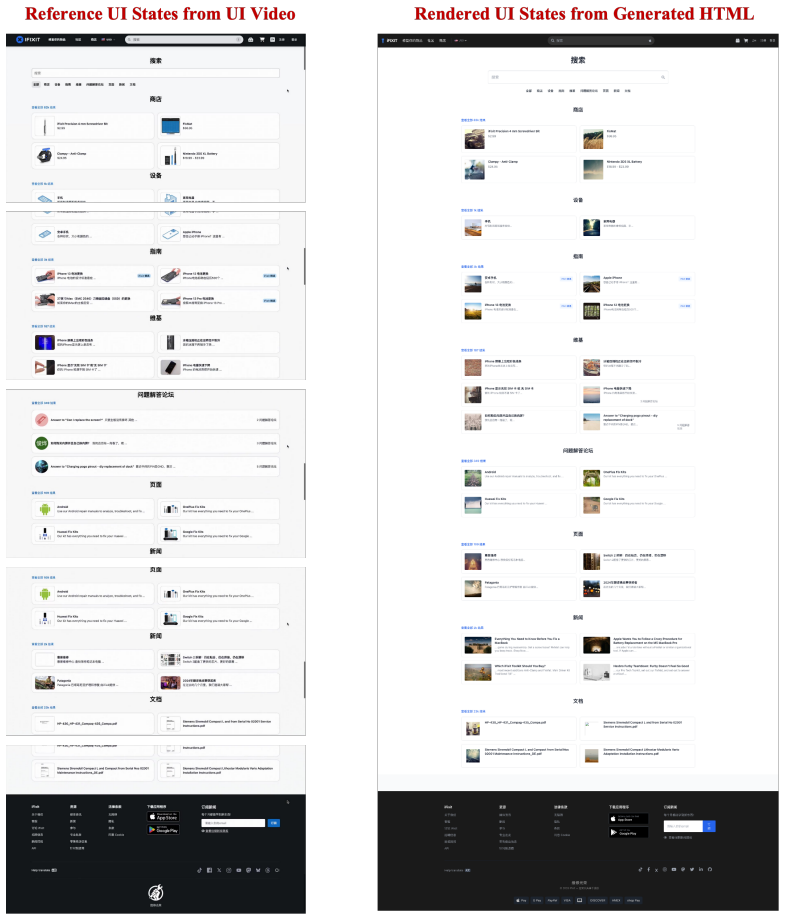
Video2Code recovers executable state transitions from UI videos by first locating action-critical regions coarsely then revisiting them at higher temporal resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
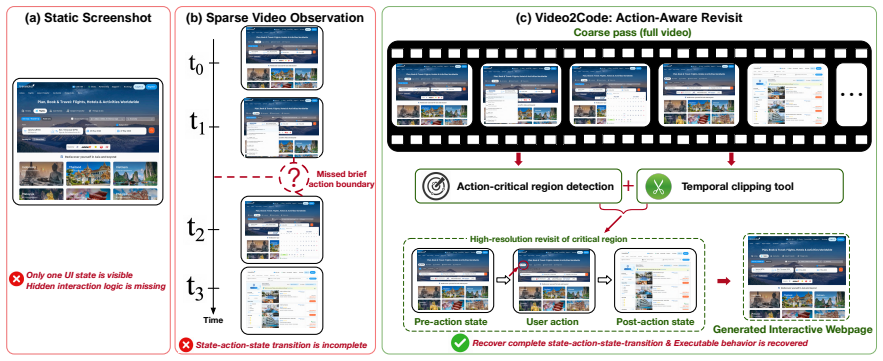
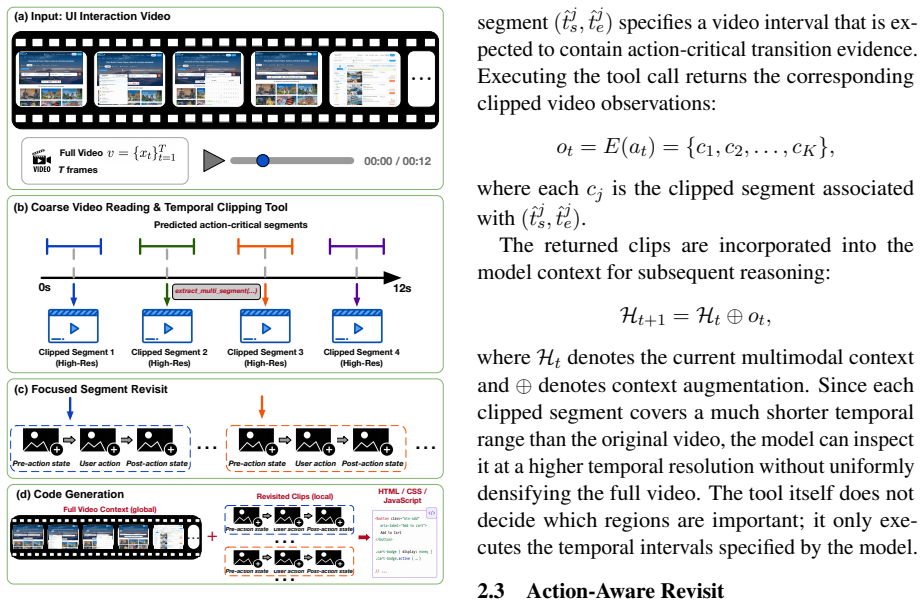
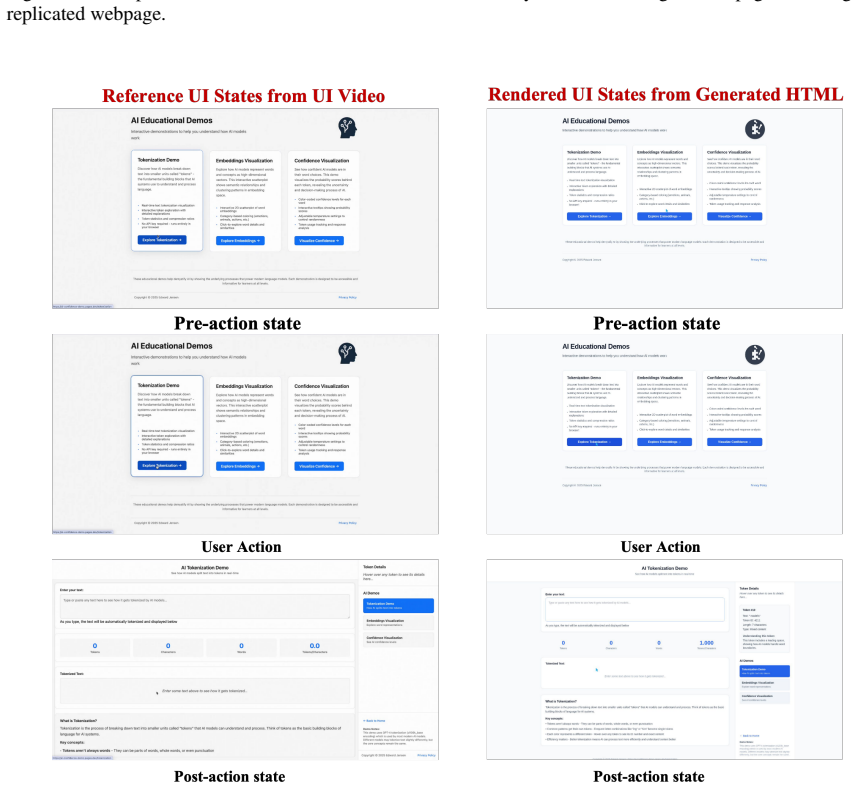
Video2Code addresses state-transition misalignment by performing coarse video understanding to locate action-critical regions, then invoking a temporal clipping tool to revisit these regions at higher temporal resolution before generating HTML/CSS/JavaScript code. The method is instantiated with action-aligned video-code supervision and evaluated under both visual and functional criteria on open-source models.
What carries the argument
Action-aware revisit: coarse video understanding locates action-critical regions, followed by temporal clipping for higher-resolution revisit before code generation.
If this is right
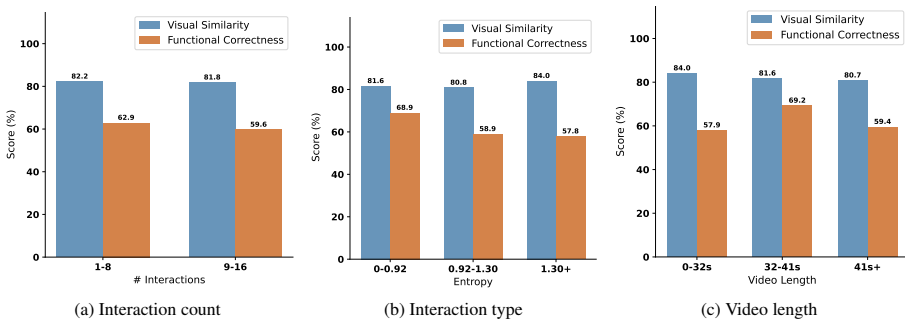
- Functional correctness rises over direct video observation, particularly on dense multi-step interactions.
- The underlying open-source vision-language model is strengthened for the UI video-to-code task.
- State-action-state transitions become recoverable when visual budget is allocated non-uniformly rather than uniformly across frames.
- Executable webpage code can be produced directly from interaction videos once misalignment is reduced.
Where Pith is reading between the lines
- The same coarse-then-revisit pattern could be tested on other video-to-program tasks such as robot instruction following where timing of actions is critical.
- If the coarse stage is replaced by a stronger video model, the revisit step might become even more accurate on long videos.
- The approach implicitly suggests that uniform frame sampling is a bottleneck for any task requiring precise temporal causality.
Load-bearing premise
The coarse video understanding step can reliably locate action-critical regions without missing short boundaries or creating misalignment that the later high-resolution revisit cannot fix.
What would settle it
A test set of UI videos where the coarse stage misses at least one short action boundary and the final generated code still produces the wrong state transition even after the revisit stage.
Figures












read the original abstract
UI videos provide a natural input for generating interactive webpages, as they capture both webpage appearance and action-triggered state transitions. However, directly applying video-capable vision-language models to this task remains insufficient. Existing models typically rely on sparse sampling or compressed temporal representations, which may miss short action boundaries and break the state-action-state transitions needed to implement webpage behavior. We formulate UI video-to-code generation as executable state-transition recovery from interaction videos, and identify this failure mode as state-transition misalignment. We introduce Video2Code, an action-aware video-to-code approach for recovering executable UI state transitions. Rather than allocating the visual budget uniformly across the video, Video2Code first performs coarse video understanding to locate action-critical regions, then invokes a temporal clipping tool to revisit these regions at higher temporal resolution before generating HTML/CSS/JavaScript code. We instantiate Video2Code with action-aligned video-code supervision and evaluate it under both visual and functional criteria. Experiments show that Video2Code substantially strengthens the underlying open-source model for UI video-to-code generation, improving functional correctness over direct video observation, especially on dense multi-step interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Video2Code, a two-stage action-aware pipeline for UI video-to-code generation. It first performs coarse video understanding to locate action-critical regions, then applies a temporal clipping tool to revisit those regions at higher temporal resolution before generating executable HTML/CSS/JavaScript. The approach is motivated by the diagnosis that direct VLM sampling suffers from state-transition misalignment due to sparse or compressed temporal representations, and the paper claims that this targeted revisit substantially improves functional correctness over direct observation, especially on dense multi-step interactions, when instantiated with action-aligned supervision.
Significance. If the empirical gains hold under rigorous evaluation, the work provides a practical engineering augmentation for strengthening open-source VLMs on executable UI state-transition recovery without uniform visual-budget allocation. The explicit framing as state-transition recovery and the use of action-aligned video-code supervision are concrete strengths that could inform follow-on work in video-conditioned code generation.
major comments (2)
- [Abstract] Abstract (paragraph on state-transition misalignment and the two-stage pipeline): the central claim that the coarse localization step reliably identifies short action boundaries (thereby enabling the high-resolution revisit to recover transitions that direct sampling misses) is load-bearing for the reported gains on dense multi-step interactions, yet the manuscript supplies no independent quantitative verification of localization precision or boundary accuracy; if the coarse stage inherits the same sparse-representation limitations, the subsequent clip cannot correct the misalignment.
- [Abstract] Abstract (experiments paragraph): the claim of 'substantially strengthens the underlying open-source model' and 'improving functional correctness' is stated without any reported numbers, error bars, dataset sizes, ablation results, or comparison tables, making it impossible to assess whether the improvement is statistically meaningful or concentrated exactly where the misalignment diagnosis predicts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript to incorporate additional quantitative support where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on state-transition misalignment and the two-stage pipeline): the central claim that the coarse localization step reliably identifies short action boundaries (thereby enabling the high-resolution revisit to recover transitions that direct sampling misses) is load-bearing for the reported gains on dense multi-step interactions, yet the manuscript supplies no independent quantitative verification of localization precision or boundary accuracy; if the coarse stage inherits the same sparse-representation limitations, the subsequent clip cannot correct the misalignment.
Authors: We agree that an independent quantitative verification of the coarse localization step's precision and boundary accuracy would strengthen the load-bearing claim. The current evaluation centers on end-to-end functional correctness of the generated code under visual and functional criteria, which provides indirect evidence that the action-critical regions are identified effectively enough to improve state-transition recovery. To directly address the concern, we will add a dedicated analysis section with metrics such as boundary precision/recall against ground-truth action annotations from the dataset. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the claim of 'substantially strengthens the underlying open-source model' and 'improving functional correctness' is stated without any reported numbers, error bars, dataset sizes, ablation results, or comparison tables, making it impossible to assess whether the improvement is statistically meaningful or concentrated exactly where the misalignment diagnosis predicts.
Authors: Abstracts conventionally summarize high-level outcomes without full numerical detail. The full manuscript reports dataset sizes, ablation studies, comparison tables, and functional correctness metrics (including breakdowns on dense multi-step interactions) with the underlying open-source model. We will revise the abstract's experiments paragraph to include the key quantitative improvements in functional correctness to make the claims more self-contained. revision: yes
Circularity Check
No significant circularity; method is an empirical engineering augmentation
full rationale
The paper describes a two-stage pipeline (coarse video understanding to locate regions, followed by temporal clipping and high-resolution revisit) instantiated with action-aligned supervision and evaluated empirically on functional correctness. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations are present that would reduce the claimed improvements to inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vision2ui: A real-world dataset with layout for code generation from ui designs.arXiv preprint arXiv:2404.06369, 5. Yi Gui, Yao Wan, Zhen Li, Zhongyi Zhang, Dongping Chen, Hongyu Zhang, Yi Su, Bohua Chen, Xing Zhou, Wenbin Jiang, and 1 others. 2025b. Uicopilot: 9 Automating ui synthesis via hierarchical code gener- ation from webpage designs. InProceeding...
-
[2]
Ryan Li, Yanzhe Zhang, and Diyi Yang
Screencoder: Advancing visual-to-code gen- eration for front-end automation via modular multi- modal agents.arXiv preprint arXiv:2507.22827. Hugo Laurençon, Léo Tronchon, and Victor Sanh. 2024. Unlocking the conversion of web screenshots into html code with the websight dataset.arXiv preprint arXiv:2403.09029. Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang,...
-
[3]
UI2Code^N: UI-to-Code Generation as Interactive Visual Optimization
Ui2codeˆ n: A visual language model for test- time scalable interactive ui-to-code generation.arXiv preprint arXiv:2511.08195. Sukmin Yun, Haokun Lin, Rusiru Thushara, and 1 oth- ers. 2024. Web2code: A large-scale webpage-to- code dataset and evaluation framework for multi- modal llms.arXiv preprint arXiv:2406.20098. Boqiang Zhang, Kehan Li, Zesen Cheng, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106. Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2024. Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713. Zheyu Zhang, Ziqi Pang, Shixing Chen, Xiang Hao, Vimal Bhat, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
The webpage content should revolve around the speci- fied theme and include a wide variety of theme-related modules
-
[6]
Each interactive component should cause corresponding and reasonable changes on the webpage
The webpage must contain multiple interactive el- ements, limited to buttons, input fields , and dropdown selectors. Each interactive component should cause corresponding and reasonable changes on the webpage
-
[7]
The webpage content should be rich, detailed, and contextually diverse
-
[8]
Figure 5: Template used to construct webpage de- sign prompts for generating interactive webpage HTML code
The output should only contain the final prompt for the AI to generate the webpage—without explana- tions, metadata, or additional commentary. Figure 5: Template used to construct webpage de- sign prompts for generating interactive webpage HTML code. Table 5: Error distribution on manually inspected failed cases fromWebVideo2Code-Real. Error Type Ratio Ev...
-
[9]
Generate a complete interactive single-page website rendered usingReact (v18)andTailwind CSS (v3+)
-
[10]
Return only the full source code wrapped within<html>...</html> tags.Do notinclude markdown wrappers, explanations, or code comments
-
[11]
https://cdn.jsdelivr.net/npm/react@18.0.0/umd/react. development.js
Must include the following dependencies: <script src="https://cdn.jsdelivr.net/npm/react@18.0.0/umd/react. development.js"></script> <script src="https://cdn.jsdelivr.net/npm/react-dom@18.0.0/umd/react-dom. development.js"></script> <script src="https://cdn.jsdelivr.net/npm/@babel/standalone/babel.js"></ script> <script src="https://cdn.tailwindcss.com"><...
-
[12]
All interactive components (input,button,select) must trigger meaningful updates to the rendered page
-
[13]
For editable content, use modals, dropdowns, or input forms with complete validation
-
[14]
Each image must have a fixed URL and remain constant across reloads
Use real pictures fromhttps://picsum.photos/. Each image must have a fixed URL and remain constant across reloads. Page Structure and Layout:
-
[15]
Include logical partitions (navigation, sidebar, main content, etc.) referencing modern app layouts
-
[16]
Ensure all sections are populated; empty placeholders are not allowed
-
[17]
pretending to independently discover and observe
The visual style must match the assigned theme (e.g., business, minimalism, tech, lifestyle). Notes: • Do not output explanations or text outside the code. • Ensure all theme-related UI logic is complete and intuitive. Webpage Description:<INSERT DETAILED PROMPT FROM STAGE 1> Figure 6: Code Generation Prompt used for large-scale HTML synthesis. For exampl...
-
[18]
reference operation list,
Pretend to discover independently: Do not mention words such as “reference operation list,” “user-provided list,” or “which image” in the thinking process. Your tone must sound like you are watching the complete video frame by frame and then independently discovering these operations. Incorrect example: “According to reference operation 1, I see...” Corre...
-
[19]
At 4.5 seconds, I see an initial page layout, then the mouse moves and clicks, and at 5.0 seconds the page finishes loading
Describe the operation and visual feedback in detail: For each time segment you mention, you may slightly modify the times based on the times in the followinguser timeline and operation reference descriptionto make it look more like an independent discovery. You must precisely describe what happens on the screen during that period. This includes: • What s...
-
[20]
video_url
Special treatment: For operations marked asscroll browsing, there is no need to describe the specific operation details; you only need to describe that scrolling shows the overall structure of the entire page. Output Requirement 2: Tool Call Statement and Tool Call<tool></tool> After completing the thinking, briefly state in natural language that you have...
-
[21]
scrolling after the operation
First observe the overall webpage layout: Before watching the first interaction short video, first inspect the webpage layout in the first video. This is the initial layout of the webpage, and you should describe it in detail. 2.Observe each operation: • Observe the mouse position: For each interaction short video, please observe thechanges in the mouse p...
-
[22]
pretending to watch videos
Summarize and pretend that you are about to write code: At the end, summarize what functions you have observed that this webpage needs to have, and state that you are starting to write the code. You do not actually need to write it. Important Constraints • At this stage, do not mention any code terms, such asdiv,state,onclick, etc.; only describe the visu...
-
[23]
Build the initial page according to the first webpage screenshot provided by the user, and it must be completely consistent with the content of the first screenshot given to you
-
[24]
Do not omit any details, including background colors, fonts, font sizes, spacing, borders, icons, text, etc., all of which must strictly match the screenshots
-
[25]
Every sentence of text in the screenshots must be presented exactly as it is
-
[26]
microscope
For image content, please use real images from thehttps://picsum.photos/ library, with URLs similar tohttps: //picsum.photos/id/.../.../.... Each image must explicitly list its URL; do not use reusable image components. The image URL of each webpage component must be fixed, and do not use random numbers to regenerate it each time. Core Task Requirements P...
-
[27]
Observe the overall page changes: Carefully observe the timeline screenshot sequence provided below. Focus on comparing theinitial screen before the operationand thefinal state/instant-change state, and do not omit any details on the page, such as a popup notification appearing in the upper-right corner, a newly added list item, etc. For screenshot sequen...
-
[28]
Make its functionality and visual feedback exactly the same as in the screenshots
Precisely locate the source of interaction: In theinitial screen before the operationscreenshot, find the mouse position, infer which component was clicked or typed into, and ensure that these components exist in the reproduced webpage and possess the same capabilities as the original. Make its functionality and visual feedback exactly the same as in the ...
-
[29]
All interactive operations given to you must be perfectly reproduced in the generated HTML, meaning they must have complete functionality, and after completion the page must be consistent with the corresponding screenshot. Please use the following libraries: •React 18:https://cdn.jsdelivr.net/npm/react@18.0.0/umd/react.development.js •ReactDOM 18:https://...
-
[30]
Only output the code inside the complete<html></html>tags
-
[31]
Ensure the code is complete HTML webpage code that can be rendered directly, and do not omit anything with ellipses
-
[32]
Video frames information <VIDEO FRAMES INFORMATION>
Do not add markdown,html, or any additional text before or after the code. Video frames information <VIDEO FRAMES INFORMATION>. Figure 9: Prompt used to reconstruct webpage HTML code from clipped webpage interaction video frames 21 Video-based Webpage Reconstruction Prompt for Baseline Inference You are highly skilled in building interactive web pages usi...
-
[33]
Background colors, fonts, font sizes, spacing, borders, icons, text, etc., must strictly match the video
Do not omit any details. Background colors, fonts, font sizes, spacing, borders, icons, text, etc., must strictly match the video
-
[34]
Every single line of text in the video must be pre- sented exactly as it is
-
[35]
microscopic
For image content, please use real images from the https://picsum.photos/ library, with URLs sim- ilar to https://picsum.photos/id/.../.../.... Each image must explicitly list its URL; do not use reusable image components. The image URL for each web component must be fixed and not randomly re- generated every time. Core Task Requirements Please apply a “m...
-
[36]
Observe overall page changes: Carefully watch the interactive web page video sent by the user, and do not miss any details on the page, such as pop-up no- tifications appearing in the top right corner, newly added list items, etc
-
[37]
This means it must be fully functional, and upon completion, the page must exactly match the content in the video
All interactive operations shown to you must be per- fectly replicated in the generated HTML. This means it must be fully functional, and upon completion, the page must exactly match the content in the video. Code Output Format
-
[40]
Figure 10: Prompt used to reconstruct interactive web- page HTML code directly from videos
Do not add markdown backticks,html, or any addi- tional text before or after the code. Figure 10: Prompt used to reconstruct interactive web- page HTML code directly from videos. Frame-based Webpage Reconstruction Prompt for Baseline Inference You are highly skilled in building interactive web pages using React and Tailwind, and you can precisely reconstr...
-
[41]
Background colors, fonts, font sizes, spacing, borders, icons, text, etc., must strictly match the extracted frames
Do not omit any details. Background colors, fonts, font sizes, spacing, borders, icons, text, etc., must strictly match the extracted frames
-
[42]
Every single line of text in the extracted frames must be presented exactly as it is
-
[43]
microscopic
For image content, please use real images from the https://picsum.photos/ library, with URLs similar to https://picsum.photos/id/.../.../. Each image must explicitly list its URL; do not use reusable image components. The image URL for each web component must be fixed and not randomly re- generated every time. Core Task Requirements Please apply a “micros...
-
[44]
Only output the complete code within the <html></html>tags
-
[45]
Do not omit anything using ellipses
Ensure the code is a complete, directly renderable HTML webpage. Do not omit anything using ellipses
-
[46]
zone–[x,y,w,h]
Do not add markdown backticks, html, or any text before or after the code. Figure 11: Prompt used to reconstruct interactive web- page HTML code directly from videos frames. 22 Interaction Selection Prompt for Evaluation You are a webpage interaction replay assistant. I will give you a set of video frame screenshots arranged in chronological order, captur...
-
[47]
Compare the frames to identify the interaction that occurred in the original webpage
-
[48]
The interaction is usually exactly one of:click,enter(typing),select(dropdown), orscroll
-
[49]
Locate the corresponding element in the DOM Tree by matching visible_text, address, tag, input_value, options, and surrounding context
-
[50]
Important Notes on Number of Actions • In almost all cases, the interaction can and should be reproduced withone single action
Output the action instruction needed to replay the interaction on the replicated webpage. Important Notes on Number of Actions • In almost all cases, the interaction can and should be reproduced withone single action. • Only outputtwo actionsin the special case where the video shows a dropdown/select-like interaction, but the replicated DOM Tree does not ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.