Exploration and Online Transfer with Behavioral Foundation Models
Pith reviewed 2026-07-01 06:48 UTC · model grok-4.3
The pith
Behavioral foundation models enable online zero-shot RL transfer by generating exploration policies in a bandit formulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When rewards are observed only through environment interactions, the behavioral foundation model can itself supply the policies needed for exploration; in the linear-reward setting this exploration is realized by repeatedly selecting the policy that minimizes the eigenvalues of the uncertainty matrix inside an upper-confidence-bound bandit loop.
What carries the argument
Eigenvalue minimization of the uncertainty matrix, which quantifies remaining uncertainty over linear reward functions and drives policy selection inside the bandit loop.
If this is right
- The agent reaches the optimal policy for any linear reward without ever receiving an offline state-reward dataset.
- Exploration reduces to a concrete matrix-eigenvalue computation at each bandit step rather than heuristic search.
- The same BFM used for zero-shot policy generation also supplies the exploration policies, eliminating the need for a separate exploration mechanism.
Where Pith is reading between the lines
- The same eigenvalue-reduction idea could be tested on non-linear reward approximations if an analogous uncertainty measure can be defined.
- The bandit framing opens a direct link between zero-shot transfer and classical online RL regret bounds that the paper leaves unexplored.
- Scaling the method to high-dimensional state spaces would require checking whether the uncertainty matrix remains tractable to diagonalize.
Load-bearing premise
The behavioral foundation model can generate a useful set of exploration policies whose execution in the environment is sufficient to identify the optimal policy for an unknown reward function.
What would settle it
Run the proposed eigenvalue-minimization loop on a linear-reward task whose optimal policy is known in advance; if the method converges to a clearly suboptimal policy after a number of interactions that should be sufficient according to the derived bounds, the claim is falsified.
Figures

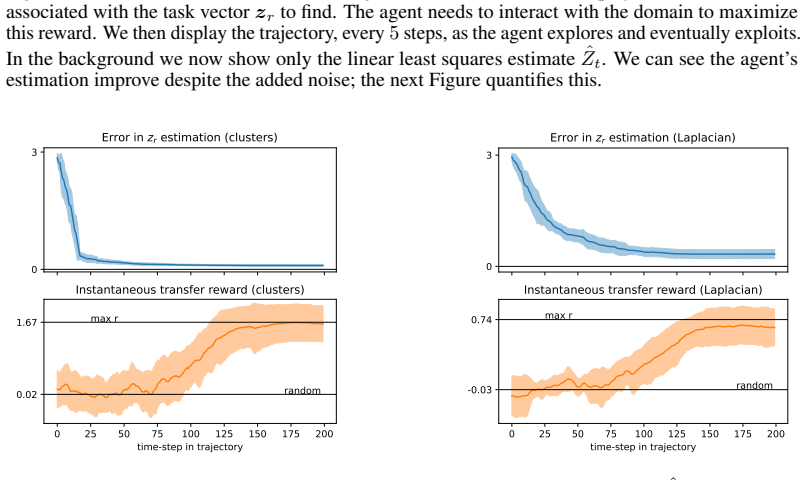
read the original abstract
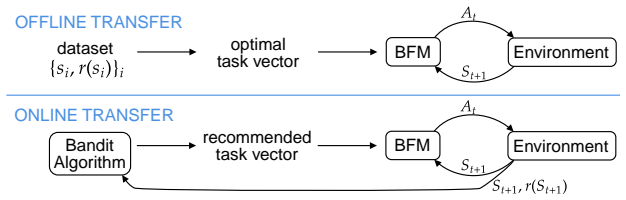
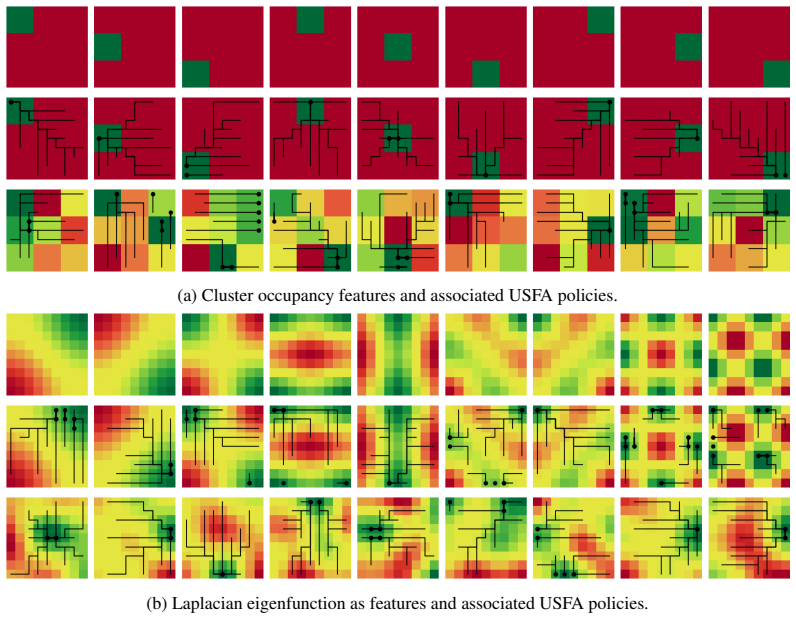
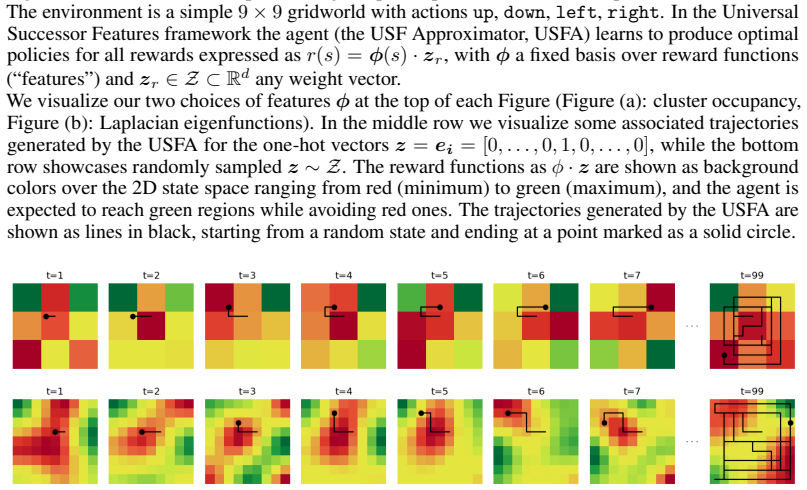
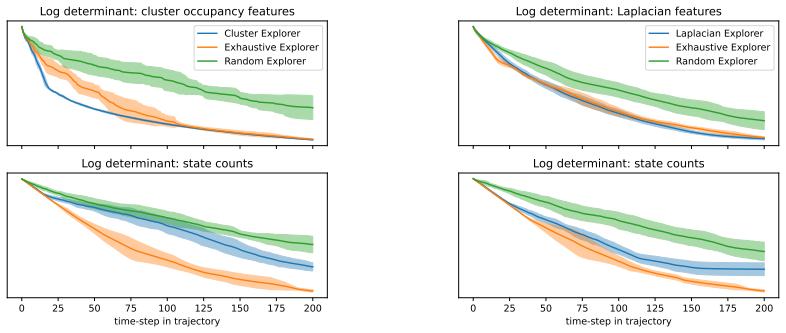
Zero-shot Transfer in Reinforcement Learning (RL) aims to train an agent that can generate optimal policies for any reward function, without additional learning at transfer time, while training only on reward-free trajectories. For their generality over tasks, such models are sometimes called ``Behavioral Foundation Models'' (BFMs). While they have shown strong performances and improvements in recent years, the current framework and algorithms still assume that, during the transfer phase, the agent is informed offline about the reward (the task to solve) through a dataset of state-reward pairs, which it uses to pick the best policy to deploy. However, in practice if the reward is a black-box (e.g. direct user feedback), it is not possible to generate such a dataset: it is necessary to observe the reward through interactions with the environment. In other words, the current framework of offline transfer is not aligned with the traditional RL setting of online learning through trial-and-error, which requires exploration in order to find rewards. This paper proposes to tackle this new online transfer in zero-shot RL, with the key insight that the BFM itself can be used to generate exploration policies. We show that it is possible to frame this online learning problem in terms of a bandit-like exploration-exploitation problem. More precisely, at each step the bandit algorithm recommends a policy, the BFM executes it in the environment, which yields a reward and a new state; we repeat the process until we converge to the optimal policy. In the popular context of linear reward approximation, we derive a formulation inspired by Upper Confidence Bound and show that exploration can be achieved through the minimization of the eigenvalues of an uncertainty matrix. We evaluate qualitatively and quantitatively our framework on a simple environment to validate the concept of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces online transfer for zero-shot RL with Behavioral Foundation Models (BFMs), where rewards must be observed via environment interactions rather than offline state-reward datasets. It frames the problem as a bandit-like exploration-exploitation task in which the BFM generates policies; for linear reward approximation, it derives a UCB-inspired formulation in which exploration is achieved by minimizing the eigenvalues of an uncertainty matrix. The approach is evaluated qualitatively and quantitatively on a simple environment.
Significance. If the derivation holds and BFM policies span feature space sufficiently, the work could extend offline zero-shot transfer to practical online settings with black-box rewards. The eigenvalue-minimization approach to uncertainty reduction is a potentially useful connection between BFMs and bandit methods. The manuscript supplies no equations, proof steps, or quantitative results in the abstract, and evaluation is limited to a simple environment, so the strength of the contribution cannot yet be assessed.
major comments (2)
- [Derivation of UCB-inspired method (abstract and method section)] The derivation of the UCB-inspired method (linear rewards, exploration via eigenvalue minimization of uncertainty matrix) requires that repeated execution of BFM policies yields state-reward pairs whose feature vectors allow the uncertainty matrix to be updated and its eigenvalues driven down in a way that distinguishes the optimal policy. No mechanism or analysis is supplied to ensure the generated behaviors are rich enough to make the Gram matrix full rank or to guarantee that eigenvalue minimization corresponds to regret bounds; if the behaviors are correlated or miss key directions, the bandit reduction fails to identify the optimum.
- [Evaluation section] The evaluation is described only as qualitative and quantitative on a simple environment. This scope is insufficient to verify the central claim, especially the load-bearing assumption that BFM policies span feature space adequately.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Derivation of UCB-inspired method (abstract and method section)] The derivation of the UCB-inspired method (linear rewards, exploration via eigenvalue minimization of uncertainty matrix) requires that repeated execution of BFM policies yields state-reward pairs whose feature vectors allow the uncertainty matrix to be updated and its eigenvalues driven down in a way that distinguishes the optimal policy. No mechanism or analysis is supplied to ensure the generated behaviors are rich enough to make the Gram matrix full rank or to guarantee that eigenvalue minimization corresponds to regret bounds; if the behaviors are correlated or miss key directions, the bandit reduction fails to identify the optimum.
Authors: The manuscript derives the eigenvalue-minimization strategy by extending standard linear bandit UCB ideas to BFM policy selection, but we agree it lacks explicit analysis of conditions for full-rank Gram matrices or regret bounds. The derivation assumes BFM policies produce sufficiently diverse feature vectors, consistent with zero-shot transfer literature. In revision we will add a dedicated subsection discussing these assumptions, the update process for the uncertainty matrix, and connections to linear bandit regret analysis, while noting failure modes if policies lack diversity. revision: yes
-
Referee: [Evaluation section] The evaluation is described only as qualitative and quantitative on a simple environment. This scope is insufficient to verify the central claim, especially the load-bearing assumption that BFM policies span feature space adequately.
Authors: We concur that evaluation on a single simple environment provides only preliminary support and does not rigorously verify feature-space spanning. The revised manuscript will expand the evaluation to additional environments and include quantitative diagnostics such as the evolution of matrix rank and eigenvalue spectra during online interactions to directly test the spanning assumption. revision: yes
Circularity Check
No circularity: derivation presented as independent from inputs
full rationale
The abstract and provided text frame the UCB-inspired formulation and eigenvalue-minimization exploration as a new derivation in the linear-reward setting. No equations or steps are shown reducing by construction to a fitted parameter, self-defined quantity, or load-bearing self-citation chain. The BFM policy-generation assumption is stated as an external premise rather than derived from the result itself. This meets the default expectation of a self-contained derivation with no exhibited reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear reward approximation holds for the tasks considered
Reference graph
Works this paper leans on
-
[1]
Abbasi-Yadkori, Y., P \'a l, D., and Szepesv \'a ri, C. (2011). Improved algorithms for linear stochastic bandits. Advances in neural information processing systems , 24
2011
-
[2]
Agarwal, S., Sikchi, H., Stone, P., and Zhang, A. (2025). Proto successor measure: Representing the behavior space of an rl agent
2025
-
[3]
P., Piot, B., Kapturowski, S., Sprechmann, P., Vitvitskyi, A., Guo, Z
Badia, A. P., Piot, B., Kapturowski, S., Sprechmann, P., Vitvitskyi, A., Guo, Z. D., and Blundell, C. (2020). Agent57: Outperforming the atari human benchmark. In International conference on machine learning , pages 507--517. PMLR
2020
-
[4]
N., Latre, S., Mets, K., and da Silva, B
Bagot, L., Alegre, L. N., Latre, S., Mets, K., and da Silva, B. C. (2025). Successor clusters: A behavior basis for unsupervised zero-shot reinforcement learning. Transactions on Machine Learning Research
2025
-
[5]
Bai, C., Wang, L., Han, L., Hao, J., Garg, A., Liu, P., and Wang, Z. (2021). Principled exploration via optimistic bootstrapping and backward induction. In International Conference on Machine Learning , pages 577--587. PMLR
2021
-
[6]
Barreto, A., Borsa, D., Hou, S., Comanici, G., Ayg \"u n, E., Hamel, P., Toyama, D., Mourad, S., Silver, D., Precup, D., et al. (2019). The option keyboard: Combining skills in reinforcement learning. Advances in Neural Information Processing Systems , 32
2019
-
[7]
Barreto, A., Borsa, D., Quan, J., Schaul, T., Silver, D., Hessel, M., Mankowitz, D., Zidek, A., and Munos, R. (2018). Transfer in deep reinforcement learning using successor features and generalised policy improvement. In International Conference on Machine Learning , pages 501--510. PMLR
2018
-
[8]
J., Schaul, T., van Hasselt, H
Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., van Hasselt, H. P., and Silver, D. (2017). Successor features for transfer in reinforcement learning. In Advances in Neural Information Processing Systems , volume 30
2017
-
[9]
Bellemare, M., Srinivasan, S., Ostrovski, G., Schaul, T., Saxton, D., and Munos, R. (2016). Unifying count-based exploration and intrinsic motivation. Advances in neural information processing systems , 29
2016
-
[11]
J., van Hasselt, H., Munos, R., Silver, D., and Schaul, T
Borsa, D., Barreto, A., Quan, J., Mankowitz, D. J., van Hasselt, H., Munos, R., Silver, D., and Schaul, T. (2019). Universal successor features approximators. In International Conference on Learning Representations
2019
-
[13]
Frans, K., Park, S., Abbeel, P., and Levine, S. (2024). Unsupervised zero-shot reinforcement learning via functional reward encodings. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F., editors, Proceedings of the 41st International Conference on Machine Learning , volume 235 of Proceedings of Machine L...
2024
-
[14]
Gomez, D., Bowling, M., and Machado, M. C. (2024). Proper laplacian representation learning. In The Twelfth International Conference on Learning Representations
2024
-
[15]
Hutsebaut-Buysse, M., Mets, K., and Latr \'e , S. (2022). Hierarchical reinforcement learning: A survey and open research challenges. Machine Learning and Knowledge Extraction , 4(1):172--221
2022
-
[16]
Jin, C., Yang, Z., Wang, Z., and Jordan, M. I. (2020). Provably efficient reinforcement learning with linear function approximation. In Conference on learning theory , pages 2137--2143. PMLR
2020
-
[17]
Khetarpal, K., Riemer, M., Rish, I., and Precup, D. (2022). Towards continual reinforcement learning: A review and perspectives. Journal of Artificial Intelligence Research , 75:1401--1476
2022
-
[18]
and Szepesv \'a ri, C
Lattimore, T. and Szepesv \'a ri, C. (2020). Bandit algorithms . Cambridge University Press
2020
-
[19]
Li, Y., Luo, Z., Zhang, T., Dai, C., Kanervisto, A., Tirinzoni, A., Weng, H., Kitani, K., Guzek, M., Touati, A., et al. (2025). Bfm-zero: A promptable behavioral foundation model for humanoid control using unsupervised reinforcement learning. arXiv e-prints , pages arXiv--2511
2025
-
[21]
C., Bellemare, M
Machado, M. C., Bellemare, M. G., and Bowling, M. (2017). A laplacian framework for option discovery in reinforcement learning. In International Conference on Machine Learning , pages 2295--2304. PMLR
2017
-
[22]
and Maggioni, M
Mahadevan, S. and Maggioni, M. (2007). Proto-value functions: A laplacian framework for learning representation and control in markov decision processes. Journal of Machine Learning Research , 8(10)
2007
-
[23]
Park, S., Kreiman, T., and Levine, S. (2024). Foundation policies with hilbert representations. In Forty-first International Conference on Machine Learning
2024
-
[24]
Strehl, A. L. and Littman, M. L. (2008). A n analysis of model-based I nterval E stimation for M arkov D ecision P rocesses. Journal of Computer and System Sciences , 74(8):1309--1331
2008
-
[25]
Sutton, R. S. and Barto, A. G. (2018). Reinforcement Learning: An Introduction . Second edition
2018
-
[26]
S., Precup, D., and Singh, S
Sutton, R. S., Precup, D., and Singh, S. (1999). Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial intelligence , 112(1-2):181--211
1999
-
[28]
and Ollivier, Y
Touati, A. and Ollivier, Y. (2021). Learning one representation to optimize all rewards. In Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W., editors, Advances in Neural Information Processing Systems , volume 34, pages 13--23. Curran Associates, Inc
2021
-
[29]
Touati, A., Rapin, J., and Ollivier, Y. (2023). Does zero-shot reinforcement learning exist? In The Eleventh International Conference on Learning Representations
2023
-
[30]
Wang, K., Zhou, K., Zhang, Q., Shao, J., Hooi, B., and Feng, J. (2021). Towards better laplacian representation in reinforcement learning with generalized graph drawing. In International Conference on Machine Learning , pages 11003--11012. PMLR
2021
-
[32]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , biburl =. Reinforcement Learning: An Introduction , year =
-
[33]
2020 , publisher=
Bandit algorithms , author=. 2020 , publisher=
2020
-
[34]
2008 , publisher=
Strehl, Alexander L and Littman, Michael L , journal=. 2008 , publisher=
2008
-
[35]
Advances in neural information processing systems , volume=
Unifying count-based exploration and intrinsic motivation , author=. Advances in neural information processing systems , volume=
-
[36]
Artificial intelligence , volume=
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning , author=. Artificial intelligence , volume=. 1999 , publisher=
1999
-
[37]
Machine Learning and Knowledge Extraction , volume=
Hierarchical Reinforcement Learning: A Survey and Open Research Challenges , author=. Machine Learning and Knowledge Extraction , volume=. 2022 , publisher=
2022
-
[38]
Journal of Artificial Intelligence Research , volume=
Towards continual reinforcement learning: A review and perspectives , author=. Journal of Artificial Intelligence Research , volume=
-
[39]
, author=
Proto-value Functions: A Laplacian Framework for Learning Representation and Control in Markov Decision Processes. , author=. Journal of Machine Learning Research , volume=
-
[40]
International Conference on Machine Learning , pages=
A laplacian framework for option discovery in reinforcement learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[41]
Advances in Neural Information Processing Systems , volume=
The option keyboard: Combining skills in reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
arXiv preprint arXiv:2110.05740 , year=
Temporal abstraction in reinforcement learning with the successor representation , author=. arXiv preprint arXiv:2110.05740 , year=
-
[43]
The Laplacian in RL: Learning Representations with Efficient Approximations
The laplacian in rl: Learning representations with efficient approximations , author=. arXiv preprint arXiv:1810.04586 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
International Conference on Machine Learning , pages=
Towards better laplacian representation in reinforcement learning with generalized graph drawing , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[45]
The Twelfth International Conference on Learning Representations , year=
Proper Laplacian Representation Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[46]
Neural computation , volume=
Improving generalization for temporal difference learning: The successor representation , author=. Neural computation , volume=
-
[47]
Successor Features for Transfer in Reinforcement Learning , volume =
Barreto, Andre and Dabney, Will and Munos, Remi and Hunt, Jonathan J and Schaul, Tom and van Hasselt, Hado P and Silver, David , booktitle =. Successor Features for Transfer in Reinforcement Learning , volume =
-
[48]
International Conference on Machine Learning , pages=
Transfer in deep reinforcement learning using successor features and generalised policy improvement , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[49]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Universal Value Function Approximators , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
2015
-
[50]
International Conference on Learning Representations , year=
Universal Successor Features Approximators , author=. International Conference on Learning Representations , year=
-
[51]
arXiv preprint arXiv:2101.07123 , year=
Learning successor states and goal-dependent values: A mathematical viewpoint , author=. arXiv preprint arXiv:2101.07123 , year=
-
[52]
Learning One Representation to Optimize All Rewards , url =
Touati, Ahmed and Ollivier, Yann , booktitle =. Learning One Representation to Optimize All Rewards , url =
-
[53]
The Eleventh International Conference on Learning Representations , year=
Does Zero-Shot Reinforcement Learning Exist? , author=. The Eleventh International Conference on Learning Representations , year=
-
[54]
Forty-first International Conference on Machine Learning , year=
Foundation Policies with Hilbert Representations , author=. Forty-first International Conference on Machine Learning , year=
-
[55]
Proceedings of the 41st International Conference on Machine Learning , pages =
Unsupervised Zero-Shot Reinforcement Learning via Functional Reward Encodings , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[56]
Transactions on Machine Learning Research , issn=
Successor Clusters: A Behavior Basis for Unsupervised Zero-Shot Reinforcement Learning , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[57]
2025 , school=
Transfer and zero-shot reinforcement learning: learning behaviors without a reward function , author=. 2025 , school=
2025
-
[58]
2025 , eprint=
Proto Successor Measure: Representing the Behavior Space of an RL Agent , author=. 2025 , eprint=
2025
-
[59]
International conference on machine learning , pages=
Agent57: Outperforming the atari human benchmark , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[60]
Entropy , volume=
An information-theoretic perspective on intrinsic motivation in reinforcement learning: A survey , author=. Entropy , volume=. 2023 , publisher=
2023
-
[61]
Frontiers in neurorobotics , volume=
What is intrinsic motivation? A typology of computational approaches , author=. Frontiers in neurorobotics , volume=. 2007 , publisher=
2007
-
[62]
Conference on learning theory , pages=
Provably efficient reinforcement learning with linear function approximation , author=. Conference on learning theory , pages=. 2020 , organization=
2020
-
[63]
International Conference on Machine Learning , pages=
Principled exploration via optimistic bootstrapping and backward induction , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[64]
arXiv e-prints , pages=
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning , author=. arXiv e-prints , pages=
-
[65]
Zero-shot whole-body humanoid control via behavioral foundation models , author=. arXiv preprint arXiv:2504.11054 , year=
-
[66]
arXiv preprint arXiv:2010.10182 , year=
The elliptical potential lemma revisited , author=. arXiv preprint arXiv:2010.10182 , year=
-
[67]
Advances in neural information processing systems , volume=
Improved algorithms for linear stochastic bandits , author=. Advances in neural information processing systems , volume=
-
[68]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning with double q-learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.