Online TT-ALS for Streaming Tensor Decomposition with Incremental Orthogonalization
Pith reviewed 2026-07-01 05:09 UTC · model grok-4.3
The pith
Online TT-ALS updates tensor train cores one at a time with exact orthogonal constraints to achieve monotonic objective decrease and linear-rank complexity for streaming data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Online TT-ALS algorithm sequentially enforces orthogonality constraints during alternating least squares updates for tensor train decomposition. This guarantees that the local objective function decreases monotonically and maintains temporal smoothness in streaming data. The deterministic single-sweep update reduces computational complexity from quadratic to linear dependence on the TT-rank, resulting in overall complexity O(I^{n-1} r).
What carries the argument
Sequential enforcement of orthogonality constraints on core tensors inside a single-sweep alternating least squares iteration for streaming tensor train decomposition.
If this is right
- The local objective function decreases monotonically at each streaming update.
- Temporal smoothness across consecutive time steps is preserved by construction.
- Rank dependence drops from quadratic to linear, producing overall complexity O(I^{n-1} r).
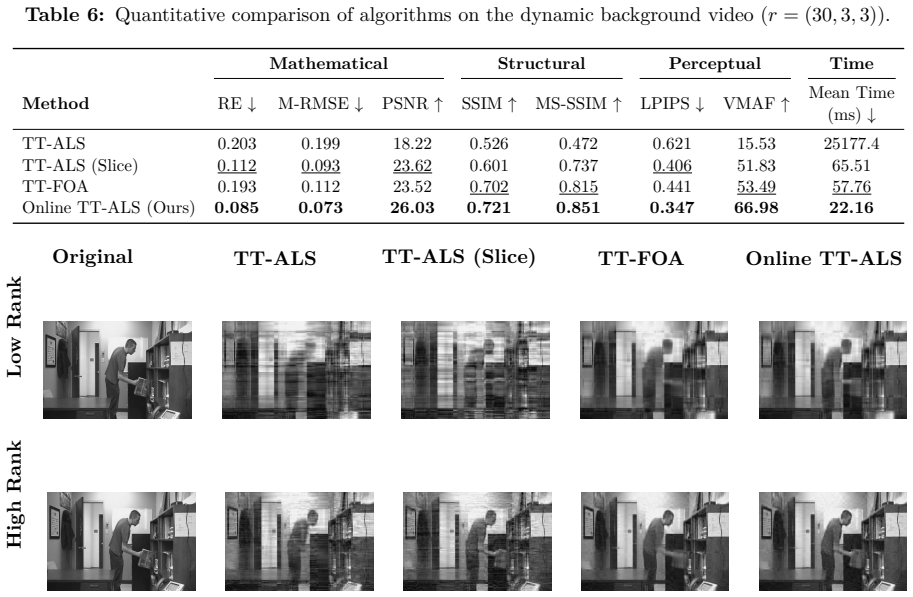
- Reconstruction accuracy exceeds that of existing online tensor methods on video data.
- Algebraic speedups of several orders of magnitude are obtained relative to deep-learning baselines.
Where Pith is reading between the lines
- The same incremental orthogonalization idea could be ported to other tensor formats such as Tucker or CP if analogous gauge constraints are identified.
- Low-latency applications like real-time sensor fusion could store only the current TT cores instead of the full history.
- Performance on non-video streams such as financial time series or scientific simulation outputs remains an open test of generality.
- The deterministic algebraic updates suggest straightforward mapping to fixed-point or FPGA hardware for edge deployment.
Load-bearing premise
Exact sequential enforcement of orthogonality constraints remains possible in a streaming setting while still preserving the reconstruction accuracy required by the theoretical guarantees.
What would settle it
Run the online algorithm on a long video stream, recompute a full batch TT decomposition on the accumulated data at several checkpoints, and check whether the online reconstruction error stays within a small factor of the batch error; divergence beyond that factor falsifies the accuracy claim.
Figures




read the original abstract
Tensor Train (TT) decomposition is a powerful technique for analyzing high-dimensional data. Existing algorithms for computing TT decompositions can be categorized into two main types: conventional batch-based approaches and recursive online methods. In the context of streaming data, batch methods typically achieve higher reconstruction accuracy but often suffer from memory exhaustion, while online methods provide greater computational efficiency. In this work, we introduce Online TT-ALS (Alternating Least Squares), an algorithm that sequentially enforces orthogonality constraints. This approach allows for efficient and exact updates of the core tensor while maintaining high reconstruction accuracy. Theoretically, we prove that enforcing these orthogonal gauge constraints guarantees monotonic decrease of the local objective function and temporal smoothness. Computationally, our deterministic single-sweep update reduces the rank dependence from quadratic to linear, achieving an overall complexity of $\mathcal{O}(I^{n-1} r)$. Experimental results demonstrate that the proposed method outperforms existing online techniques not only in terms of mathematical approximation accuracy but also in human perception-based video quality metrics. Furthermore, compared to recent deep learning-based paradigms, our algebraic approach achieves speedups of several orders of magnitude. Consequently, our method exhibits high computational efficiency and is suitable for low-latency real-time processing applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Online TT-ALS, a streaming algorithm for tensor-train decomposition that sequentially enforces orthogonality constraints on the cores. It claims a proof that this gauge enforcement yields monotonic decrease of the local objective function together with temporal smoothness, a deterministic single-sweep update whose complexity is O(I^{n-1} r), and experimental superiority over prior online methods and deep-learning baselines on reconstruction accuracy and video-quality metrics.
Significance. If the claimed guarantees hold, the work supplies an algebraic, low-latency method for streaming high-order tensor decomposition with explicit descent and complexity properties, offering a non-learned alternative that can be orders of magnitude faster than neural approaches for real-time applications.
major comments (2)
- [Theoretical analysis] Theoretical analysis section (proof of monotonicity): the descent argument is stated to follow from exact maintenance of the orthogonal gauge after each incremental update, yet the manuscript does not supply a rigorous argument that the streaming QR/Gram-Schmidt step on the updated core preserves exact orthogonality without access to the full history or buffer truncation; any accumulation of floating-point or truncation error would invalidate the standard ALS monotonicity argument.
- [Complexity analysis] Complexity derivation (single-sweep update): the reduction from quadratic to linear rank dependence is asserted to yield overall O(I^{n-1} r) cost, but the derivation assumes the incremental orthogonalization remains exactly linear-rank; the streaming buffer size and any truncation therein must be shown not to re-introduce quadratic terms or approximate the claimed bound.
minor comments (2)
- [Algorithm description] Notation for the streaming buffer and its truncation threshold is introduced without an explicit symbol or pseudocode line; adding a dedicated definition would clarify the exactness claim.
- [Experiments] The experimental section reports speedups versus deep-learning methods but does not list the precise tensor orders, ranks, and streaming rates used in each comparison; a table summarizing these parameters would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive major comments. We address each point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section (proof of monotonicity): the descent argument is stated to follow from exact maintenance of the orthogonal gauge after each incremental update, yet the manuscript does not supply a rigorous argument that the streaming QR/Gram-Schmidt step on the updated core preserves exact orthogonality without access to the full history or buffer truncation; any accumulation of floating-point or truncation error would invalidate the standard ALS monotonicity argument.
Authors: We appreciate the referee highlighting the need for greater rigor here. The proof of monotonicity (Theorem 3) proceeds from the assumption that the orthogonal gauge is exactly preserved after each core update. Algorithm 2 implements this via a streaming QR factorization that operates solely on the current core slice and the already-orthogonalized preceding factors; because prior cores remain untouched and the update is rank-r, no full history is required and exact orthogonality holds in exact arithmetic. We agree that an explicit supporting lemma is missing from the current text. In the revision we will insert a short lemma proving gauge preservation under the streaming QR step together with a brief remark on floating-point considerations. This constitutes a partial revision. revision: partial
-
Referee: [Complexity analysis] Complexity derivation (single-sweep update): the reduction from quadratic to linear rank dependence is asserted to yield overall O(I^{n-1} r) cost, but the derivation assumes the incremental orthogonalization remains exactly linear-rank; the streaming buffer size and any truncation therein must be shown not to re-introduce quadratic terms or approximate the claimed bound.
Authors: We thank the referee for this observation on the complexity claim. The O(I^{n-1} r) bound is obtained because the incremental orthogonalization (lines 8–12 of Algorithm 2) performs only matrix-vector operations and a thin QR on an I×r matrix, yielding linear dependence on r; the fixed-size streaming buffer stores only the current core and does not grow with rank or history. When rank truncation is applied it occurs after the linear-cost update and therefore does not alter the per-step complexity. We will add an explicit paragraph in Section 4.2 that isolates the buffer-size assumption and confirms the absence of quadratic terms. This is a partial revision. revision: partial
Circularity Check
No circularity: derivation relies on standard ALS monotonicity arguments adapted to streaming constraints
full rationale
The paper claims a proof that sequential enforcement of orthogonal gauge constraints guarantees monotonic decrease of the local objective and temporal smoothness, plus a deterministic single-sweep update yielding O(I^{n-1} r) complexity. No equations, self-citations, or fitted parameters are shown in the abstract that reduce these claims to inputs by construction. The central theoretical statements are presented as following from the gauge enforcement itself (a standard technique in batch TT-ALS), and the streaming adaptation is described as preserving exactness without reference to prior self-work that would make the result tautological. This is the normal case of an independent derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tensor train format is appropriate for the high-dimensional streaming data considered
- ad hoc to paper Orthogonality constraints can be enforced sequentially and exactly in an online streaming setting
Reference graph
Works this paper leans on
-
[1]
doi: 10.1137/07070111X. I. V. Oseledets. Tensor-Train Decomposition.SIAM Journal on Scientific Computing, 33(5): 2295–2317,
-
[2]
Alexander Novikov, Dmitry Podoprikhin, Anton Osokin, and Dmitry Vetrov
doi: 10.1137/090752286. Alexander Novikov, Dmitry Podoprikhin, Anton Osokin, and Dmitry Vetrov. Tensorizing Neural Networks. InProceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, page 442–450, Cambridge, MA, USA,
-
[3]
doi: 10.1007/s11263-007-0075-7
ISSN 1573-1405. doi: 10.1007/s11263-007-0075-7. Jimeng Sun, Dacheng Tao, and Christos Faloutsos. Beyond streams and graphs: dynamic tensor analysis. InProceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’06, page 374–383, New York, NY, USA,
-
[4]
Association for Computing Machinery. ISBN 1595933395. doi: 10.1145/1150402.1150445. MortezaMardani, GonzaloMateos, andGeorgiosB.Giannakis. Subspacelearningandimputation for streaming big data matrices and tensors.IEEE Transactions on Signal Processing, 63(10): 2663–2677,
-
[5]
Le Trung Thanh, Karim Abed-Meraim, Nguyen Linh Trung, and Adel Hafiane
doi: 10.1109/TSP.2015.2417491. Le Trung Thanh, Karim Abed-Meraim, Nguyen Linh Trung, and Adel Hafiane. A Contemporary and Comprehensive Survey on Streaming Tensor Decomposition.IEEE Transactions on Knowledge and Data Engineering, 35(11):10897–10921,
-
[6]
doi: 10.1109/TKDE.2022. 3230874. Sebastian Holtz, Thorsten Rohwedder, and Reinhold Schneider. The Alternating Linear Scheme for Tensor Optimization in the Tensor Train Format.SIAM Journal on Scientific Computing, 34(2):A683–A713,
-
[7]
doi: 10.1137/100818893. 18 Johann A. Bengua, Ho N. Phien, Hoang Duong Tuan, and Minh N. Do. Efficient tensor completion for color image and video recovery: Low-rank tensor train.IEEE Transactions on Image Processing, 26(5):2466–2479,
-
[8]
Le Trung Thanh, Karim Abed-Meraim, Nguyen Linh Trung, and Remy Boyer
doi: 10.1109/TIP.2017.2672439. Le Trung Thanh, Karim Abed-Meraim, Nguyen Linh Trung, and Remy Boyer. Adaptive Algorithms for Tracking Tensor-Train Decomposition of Streaming Tensors. In2020 28th European Signal Processing Conference (EUSIPCO), pages 995–999,
-
[9]
Xi Zhang, Yanyi Li, Yisi Luo, Qi Xie, and Deyu Meng
doi: 10.23919/ Eusipco47968.2020.9287780. Xi Zhang, Yanyi Li, Yisi Luo, Qi Xie, and Deyu Meng. Online functional tensor decomposition via continual learning for streaming data completion. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pages 41790–418...
arXiv 2020
-
[10]
Yi Wang, Pierre-Marc Jodoin, Fatih Porikli, Janusz Konrad, Yannick Benezeth, and Prakash Ishwar
doi: 10.1137/1.9781421407944. Yi Wang, Pierre-Marc Jodoin, Fatih Porikli, Janusz Konrad, Yannick Benezeth, and Prakash Ishwar. Cdnet 2014: An expanded change detection benchmark dataset. In2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 393–400,
-
[11]
doi: 10.1109/CVPRW.2014.126. R.C. Gonzalez and R.E. Woods.Digital Image Processing. Pearson, 4th edition,
-
[12]
doi: 10.1109/TIP.2003.819861. Z. Wang, E.P. Simoncelli, and A.C. Bovik. Multiscale structural similarity for image quality assessment. InThe Thirty-Seventh Asilomar Conference on Signals, Systems and Computers, 2003, volume 2, pages 1398–1402 Vol.2,
-
[13]
Richard Zhang, Phillip Isola, Alexei A
doi: 10.1109/ACSSC.2003.1292216. Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.