Inference-Time Robot Behavior Steering through Physically-Aware Reconfiguration of Task-Structure
Pith reviewed 2026-06-26 05:30 UTC · model grok-4.3
The pith
ReStruct steers a trained robot policy at inference time by synchronously composing a preference automaton into its neural state-machine skeleton while freezing the low-level controller.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
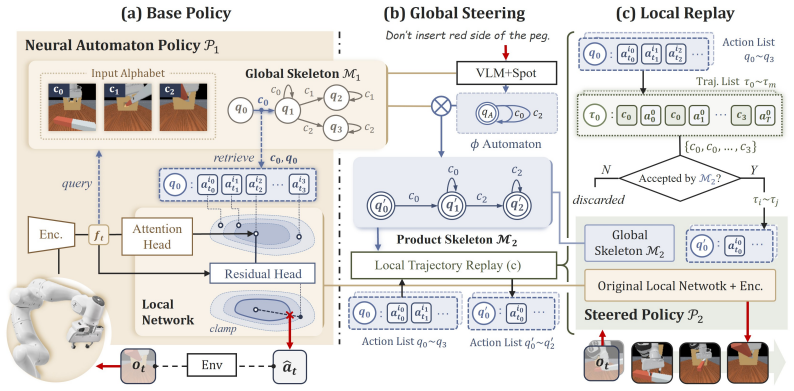
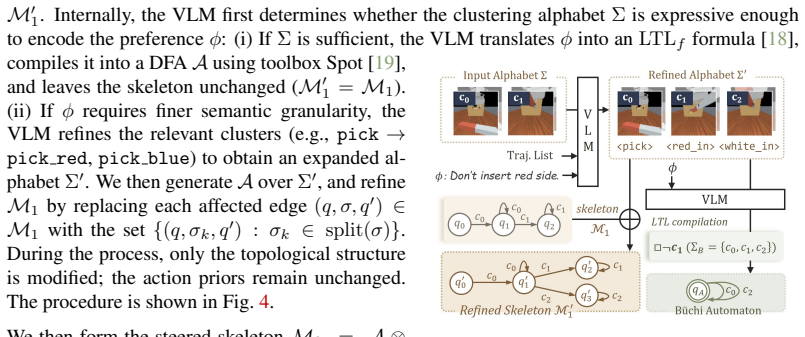
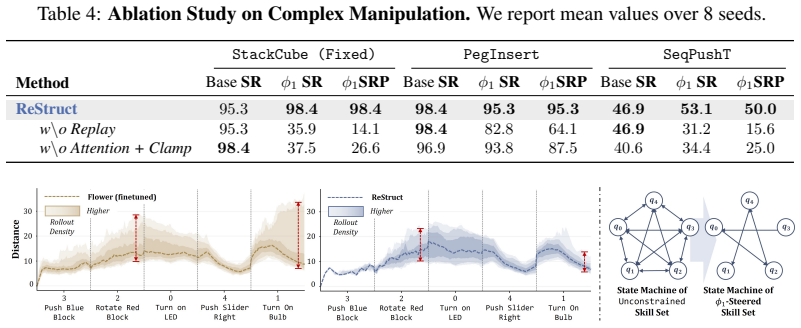
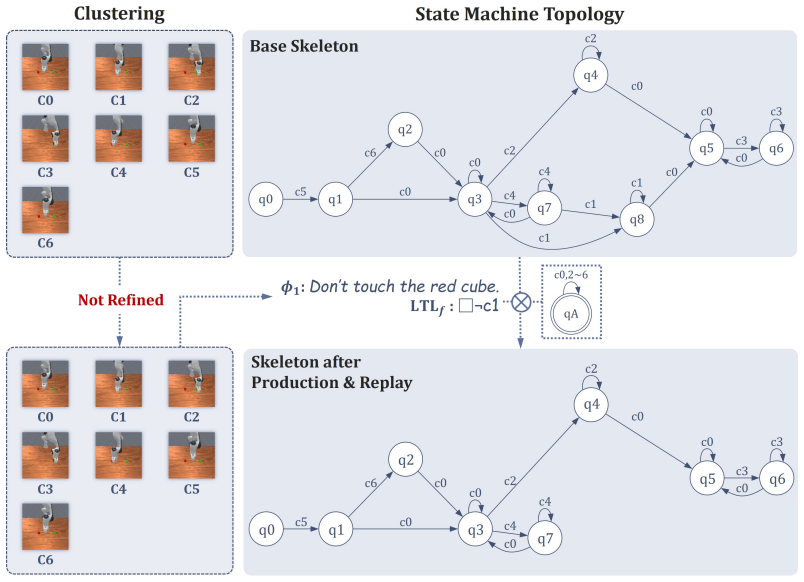
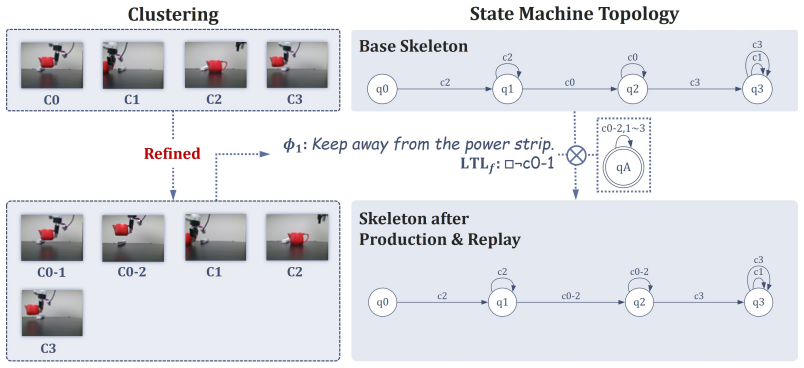
ReStruct adopts the automaton to represent the preference and incorporates it into the skeleton through a synchronous product, thereby reconfiguring the task structure. With the controller kept frozen, the action priors provided by the skeleton are updated accordingly to enable physically-aware control under a modified task structure. Experiments in simulation and the real world show that the method steers object-centric specifications as well as temporal-logic constraints and exceeds both prior steering techniques and VLA models by up to 25 percent in combined task success and preference adherence.
What carries the argument
The neural automaton that decomposes the visuomotor policy into a high-level state-machine skeleton capturing task structure and a low-level residual controller; the synchronous product of this skeleton with a preference automaton reconfigures the supplied action priors.
If this is right
- ReStruct handles both object-centric specifications and temporal-logic constraints without retraining.
- The method improves task success and preference-following over prior steering approaches and over VLA models by up to 25 percent.
- Only the high-level skeleton is edited; the low-level controller remains frozen throughout.
- The approach works in both simulated environments and real-world robot deployments.
Where Pith is reading between the lines
- The same decomposition might allow runtime insertion of safety constraints expressed as automata without touching the policy weights.
- If the skeleton can be extracted from any visuomotor network, the technique could apply to policies trained by imitation or reinforcement learning alike.
- Natural-language preferences could be compiled into automata upstream, turning the method into a language-to-behavior interface that still respects physics.
Load-bearing premise
The learned automaton skeleton accurately captures the original task structure so that its synchronous product with any new preference automaton still yields physically feasible action priors for the unchanged residual controller.
What would settle it
A trial in which the reconfigured skeleton produces action priors that cause the robot to violate physical constraints or collide, even though the combined automaton satisfies the stated preference.
Figures




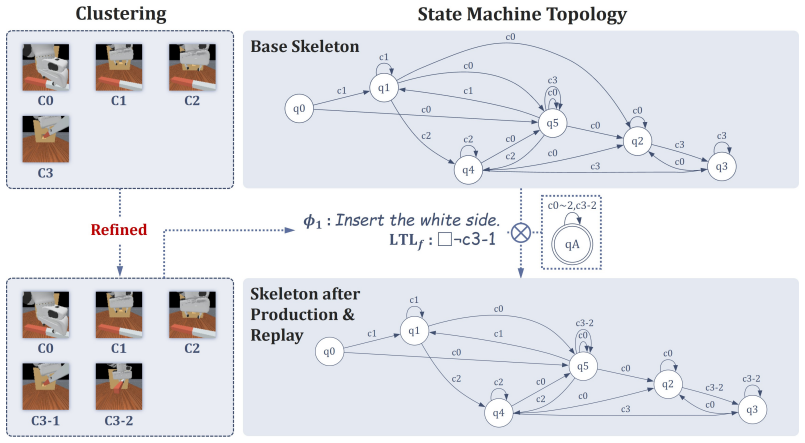
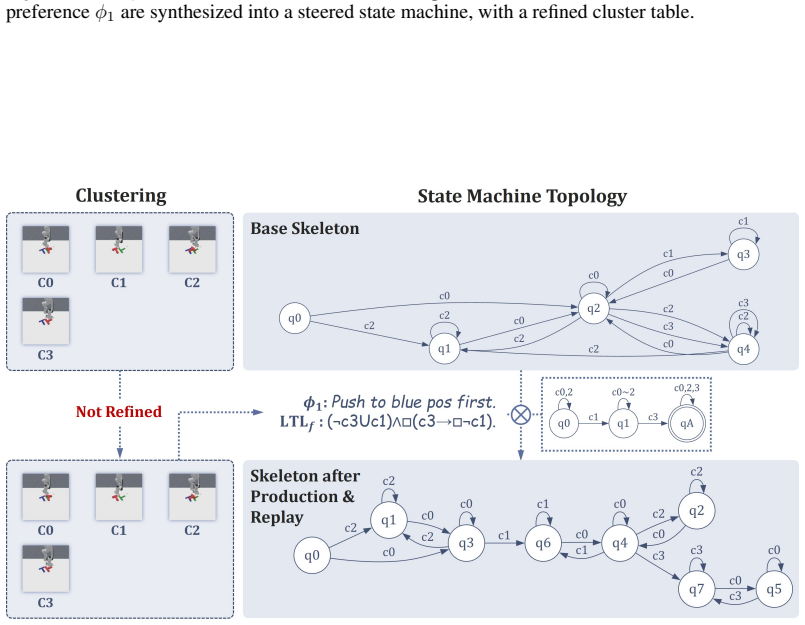
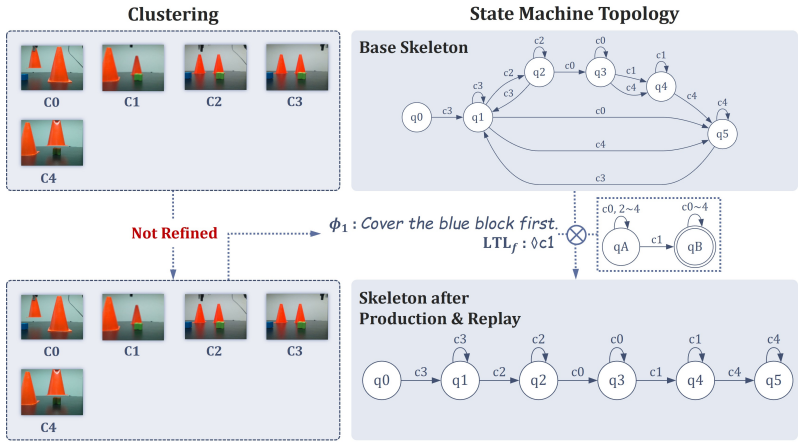
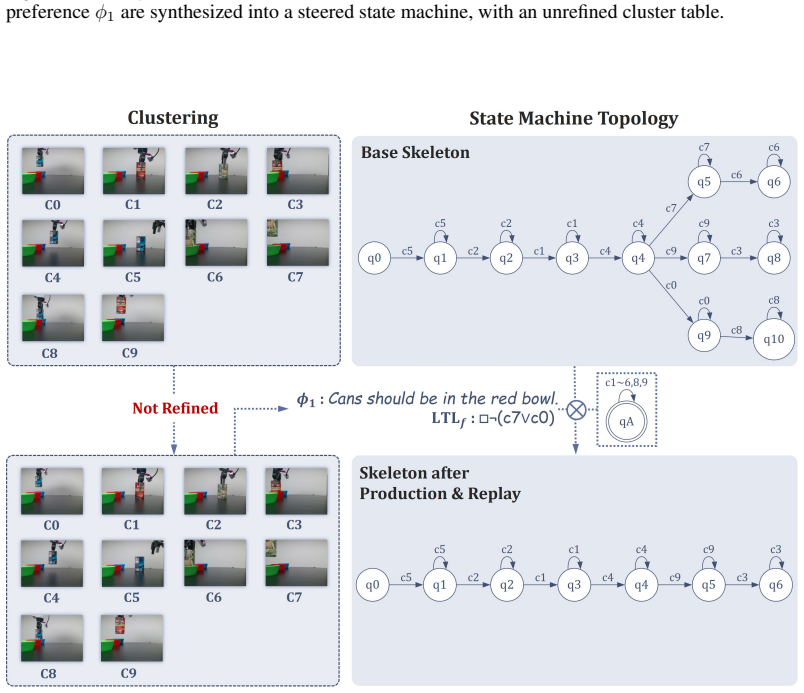
read the original abstract
A central challenge in deploying learned robot policies is inference-time behavior steering: redirecting a policy at test time to satisfy user preferences not anticipated during training, without retraining. Existing methods fail in two modes: end-to-end methods require fine-tuning or expert-level guidance, while neuro-symbolic methods rely on predefined symbols whose edits can result in logically reasonable but physically infeasible plans. To address this challenge, we propose ReStruct, which builds upon a neural automaton policy that decomposes a visuomotor policy into a high-level state-machine skeleton capturing task structure and a low-level continuous controller represented as a residual policy. Specifically, ReStruct adopts the automaton to represent the preference and incorporates it into the skeleton through a synchronous product, thereby reconfiguring the task structure. With the controller kept frozen, the action priors provided by the skeleton are updated accordingly to enable physically-aware control under a modified task structure. Extensive experiments from simulation and real-world show that ReStruct steers a wide range of preferences, from object-centric specifications to temporal-logic constraints, and after steering surpasses existing methods, exceeding VLA models in both task success and preference-following by up to 25%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReStruct, a neuro-symbolic approach for inference-time steering of learned robot policies. It decomposes a visuomotor policy into a neural automaton representing a high-level state-machine skeleton and a low-level residual controller. User preferences (object-centric or temporal-logic) are encoded as automata and incorporated via synchronous product with the skeleton; the resulting reconfigured action priors are fed to the frozen controller to produce physically-aware behavior without retraining. Experiments in simulation and real-world settings claim that ReStruct handles diverse preferences and outperforms baselines including VLA models by up to 25% in task success and preference adherence.
Significance. If the physical realizability of the reconfigured priors holds, the approach would meaningfully advance inference-time adaptation by combining the editability of automata with the performance of end-to-end policies, reducing reliance on retraining or expert guidance. The reported real-world experiments and breadth of preference types (object-centric to temporal logic) would strengthen its practical relevance if the feasibility guarantee is substantiated.
major comments (2)
- [Method (neural automaton decomposition and synchronous product)] The central claim that the synchronous product yields physically feasible action priors for the frozen residual controller (without retraining) is load-bearing, yet the manuscript provides no explicit loss term, training objective, or safeguard that enforces correspondence between automaton states and the controller's training distribution. This leaves open the possibility that product-generated transitions fall outside the controller's support.
- [Experiments section] Experimental results claim up to 25% gains over VLA models in both task success and preference following, but the abstract and method description omit details on experimental design, number of trials, baselines, statistical tests, or how physical feasibility was verified post-reconfiguration (e.g., via constraint violation rates or failure mode analysis).
minor comments (2)
- [Method] Notation for the automaton states, transitions, and the synchronous product operation should be formalized with explicit definitions or equations to improve reproducibility.
- [Abstract] The abstract states 'extensive experiments from simulation and real-world' but does not reference specific figures or tables showing quantitative metrics; cross-references would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Method (neural automaton decomposition and synchronous product)] The central claim that the synchronous product yields physically feasible action priors for the frozen residual controller (without retraining) is load-bearing, yet the manuscript provides no explicit loss term, training objective, or safeguard that enforces correspondence between automaton states and the controller's training distribution. This leaves open the possibility that product-generated transitions fall outside the controller's support.
Authors: The neural automaton is obtained by decomposing the original visuomotor policy, so its states are by construction aligned with regions where the residual controller was trained. The synchronous product modifies only the high-level state machine while the controller remains frozen and receives action priors from the reconfigured skeleton; physical feasibility is therefore inherited from the original policy rather than enforced by an additional loss. We acknowledge that the manuscript does not spell out an explicit safeguard term. We will add a clarifying paragraph in the method section describing the decomposition procedure and the resulting distribution alignment. revision: partial
-
Referee: [Experiments section] Experimental results claim up to 25% gains over VLA models in both task success and preference following, but the abstract and method description omit details on experimental design, number of trials, baselines, statistical tests, or how physical feasibility was verified post-reconfiguration (e.g., via constraint violation rates or failure mode analysis).
Authors: The full manuscript reports simulation and real-robot trials, comparisons against VLA and other baselines, and success/preference metrics, with physical feasibility assessed via task completion and observed failure modes. However, the abstract and method sections are indeed terse on trial counts, statistical tests, and explicit feasibility verification. We will revise both sections to include the number of trials per condition, the statistical tests performed, and a short failure-mode analysis that reports constraint-violation rates. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, or load-bearing steps that reduce the claimed performance (e.g., 25% gains) to fitted parameters, self-definitions, or self-citation chains by construction. ReStruct is presented as an application of existing automata concepts (neural automaton decomposition into skeleton + residual controller, followed by synchronous product) to inference-time steering, with the controller kept frozen. No self-referential reductions or ansatzes smuggled via citation are evident in the text. This is the expected honest non-finding for a methods paper whose central claim rests on empirical validation rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[2]
H. Zhou, M. Ding, W. Peng, M. Tomizuka, L. Shao, and C. Gan. Generalizable long-horizon manipulations with large language models.arXiv preprint arXiv:2310.02264, 2023
arXiv 2023
-
[3]
Y . Wang, L. Wang, Y . Du, B. Sundaralingam, X. Yang, Y .-W. Chao, C. P ´erez-D’Arpino, D. Fox, and J. Shah. Inference-time policy steering through human interactions. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15626–15633. IEEE, 2025
2025
-
[4]
R. Singhal, Z. Horvitz, R. Teehan, M. Ren, Z. Yu, K. McKeown, and R. Ranganath. A gen- eral framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025
arXiv 2025
-
[5]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, et al.π0.5: a vision-language-action model with open-world general- ization. In9th Annual Conference on Robot Learning, 2025
2025
-
[6]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[7]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[8]
B. P. Bhuyan, A. Ramdane-Cherif, R. Tomar, and T. Singh. Neuro-symbolic artificial intelli- gence: a survey.Neural Computing and Applications, 36(21):12809–12844, 2024
2024
-
[10]
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foundation models via value guidance.arXiv preprint arXiv:2410.13816, 2024
arXiv 2024
- [11]
-
[12]
J. Mao, J. B. Tenenbaum, and J. Wu. Neuro-symbolic concepts.arXiv preprint arXiv:2505.06191, 2025
arXiv 2025
-
[13]
Y . Pan, X. Luo, H. Hu, P. Yu, and C. Liu. Emergent neural automaton policies: Learning symbolic structure from visuomotor trajectories.arXiv preprint arXiv:2603.25903, 2026
Pith/arXiv arXiv 2026
-
[14]
M. Y . Vardi. An automata-theoretic approach to linear temporal logic. InLogics for concur- rency: structure versus automata, pages 238–266. Springer, 2005
2005
-
[15]
De Giacomo and M
G. De Giacomo and M. Y . Vardi. Linear temporal logic and linear dynamic logic on finite traces. 2013
2013
-
[16]
M. T. Spaan. Partially observable markov decision processes. InReinforcement learning: State-of-the-art, pages 387–414. Springer, 2012
2012
-
[17]
Kurniawati
H. Kurniawati. Partially observable markov decision processes and robotics.Annual review of control, robotics, and autonomous systems, 5(1):253–277, 2022. 18
2022
-
[18]
S. Xu, X. Luo, Y . Huang, L. Leng, R. Liu, and C. Liu. Nl2hltl2plan: Scaling up natural lan- guage understanding for multi-robots through hierarchical temporal logic task specifications. IEEE Robotics and Automation Letters, 2025
2025
-
[19]
Duret-Lutz, A
A. Duret-Lutz, A. Lewkowicz, A. Fauchille, T. Michaud, E. Renault, and L. Xu. Spot 2.0—a framework for ltl and-automata manipulation. InInternational Symposium on Automated Tech- nology for Verification and Analysis, pages 122–129. Springer, 2016
2016
-
[20]
R. Wang, J. Mao, J. Hsu, H. Zhao, J. Wu, and Y . Gao. Programmatically grounded, composi- tionally generalizable robotic manipulation.arXiv preprint arXiv:2304.13826, 2023
arXiv 2023
-
[21]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[22]
D. A. Reynolds et al. Gaussian mixture models.Encyclopedia of biometrics, 741(659-663):3, 2009
2009
-
[23]
T. Mu, Z. Ling, F. Xiang, D. Yang, X. Li, S. Tao, Z. Huang, Z. Jia, and H. Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations.arXiv preprint arXiv:2107.14483, 2021
arXiv 2021
-
[24]
O. Mees, L. Hermann, and W. Burgard. What matters in language conditioned robotic imitation learning over unstructured data.IEEE Robotics and Automation Letters, 7(4):11205–11212, 2022
2022
- [25]
- [26]
- [27]
-
[28]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[29]
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, J. Fan, et al. Eureka: Human-level reward design via coding large language models. InInternational con- ference on learning Representations, volume 2024, pages 26516–26560, 2024
2024
-
[30]
Y . Pan, Z. Liu, and H. Wang. Wonder wins ways: Curiosity-driven exploration through multi- agent contextual calibration.Advances in Neural Information Processing Systems, 38:116109– 116137, 2026
2026
-
[31]
Y . Chen, D. K. Jha, M. Tomizuka, and D. Romeres. Fdpp: Fine-tune diffusion policy with hu- man preference. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12010–12016. IEEE, 2025
2025
- [32]
- [33]
-
[34]
S. Holk, D. Marta, and I. Leite. Predilect: Preferences delineated with zero-shot language- based reasoning in reinforcement learning. InProceedings of the 2024 ACM/IEEE Interna- tional Conference on Human-Robot Interaction, pages 259–268, 2024
2024
- [35]
-
[36]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
-
[37]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[38]
V . Liu, A. Adeniji, H. Zhan, S. Haldar, R. Bhirangi, P. Abbeel, and L. Pinto. Egozero: Robot learning from smart glasses.arXiv preprint arXiv:2505.20290, 2025
arXiv 2025
-
[39]
Black, M
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero- shot robotic manipulation with pre-trained image-editing diffusion models. InInternational Conference on Learning Representations, volume 2024, pages 33431–33452, 2024
2024
-
[40]
Sundaresan, Q
P. Sundaresan, Q. Vuong, J. Gu, P. Xu, T. Xiao, S. Kirmani, T. Yu, M. Stark, A. Jain, K. Haus- man, et al. Rt-sketch: Goal-conditioned imitation learning from hand-drawn sketches. In8th Annual Conference on Robot Learning, 2024
2024
-
[41]
R. T. Icarte, T. Klassen, R. Valenzano, and S. McIlraith. Using reward machines for high-level task specification and decomposition in reinforcement learning. InInternational Conference on Machine Learning, pages 2107–2116. PMLR, 2018
2018
-
[42]
Y . Chen, J. Arkin, C. Dawson, Y . Zhang, N. Roy, and C. Fan. Autotamp: Autoregressive task and motion planning with llms as translators and checkers. In2024 IEEE International conference on robotics and automation (ICRA), pages 6695–6702. IEEE, 2024
2024
-
[43]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[44]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
2023
-
[45]
C. R. Garrett, T. Lozano-P´erez, and L. P. Kaelbling. Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. InProceedings of the international conference on automated planning and scheduling, volume 30, pages 440–448, 2020
2020
-
[46]
Konidaris and A
G. Konidaris and A. Barto. Skill discovery in continuous reinforcement learning domains using skill chaining.Advances in neural information processing systems, 22, 2009
2009
-
[47]
Pertsch, Y
K. Pertsch, Y . Lee, and J. Lim. Accelerating reinforcement learning with learned skill priors. InConference on robot learning, pages 188–204. PMLR, 2021
2021
-
[48]
B. Da Silva, G. Konidaris, and A. Barto. Learning parameterized skills.arXiv preprint arXiv:1206.6398, 2012
Pith/arXiv arXiv 2012
-
[49]
Konidaris, L
G. Konidaris, L. P. Kaelbling, and T. Lozano-Perez. From skills to symbols: Learning symbolic representations for abstract high-level planning.Journal of Artificial Intelligence Research, 61: 215–289, 2018. 20
2018
- [50]
-
[51]
J. Mao, C. Gan, P. Kohli, J. B. Tenenbaum, and J. Wu. The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision.arXiv preprint arXiv:1904.12584, 2019
Pith/arXiv arXiv 1904
-
[52]
H. M. Pasula, L. S. Zettlemoyer, and L. P. Kaelbling. Learning symbolic models of stochastic domains.Journal of Artificial Intelligence Research, 29:309–352, 2007
2007
-
[53]
Chitnis, T
R. Chitnis, T. Silver, J. B. Tenenbaum, T. Lozano-Perez, and L. P. Kaelbling. Learning neuro- symbolic relational transition models for bilevel planning. In2022 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 4166–4173. IEEE, 2022
2022
-
[54]
M. Poli, S. Massaroli, L. Scimeca, S. Chun, S. J. Oh, A. Yamashita, H. Asama, J. Park, and A. Garg. Neural hybrid automata: Learning dynamics with multiple modes and stochastic transitions.Advances in Neural Information Processing Systems, 34:9977–9989, 2021
2021
-
[55]
Y . Pan, Y . Xu, Z. Liu, and H. Wang. Planning from imagination: Episodic simulation and episodic memory for vision-and-language navigation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6345–6353, 2025
2025
-
[56]
Y . Xu, Y . Pan, and Z. Liu. Dream to recall: Imagination-guided experience retrieval for memory-persistent vision-and-language navigation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[57]
Du and S
M. Du and S. Song. Dynaguide: Steering diffusion polices with active dynamic guidance. Advances in Neural Information Processing Systems, 38:44192–44221, 2026
2026
-
[58]
Y . Liu, J. I. Hamid, A. Xie, Y . Lee, M. Du, and C. Finn. Bidirectional decoding: Improving action chunking via guided test-time sampling.International Conference on Learning Repre- sentations (ICLR), 2025. URLhttps://arxiv.org/abs/2408.17355
arXiv 2025
-
[59]
S. Wu, X. Luo, J. Zhang, J. Xie, J. Song, H. T. Shen, and L. Gao. Policy contrastive decoding for robotic foundation models.arXiv preprint arXiv:2505.13255, 2025
Pith/arXiv arXiv 2025
-
[60]
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning.arXiv preprint arXiv:2506.15799, 2025
Pith/arXiv arXiv 2025
-
[61]
Y . Wu, R. Tian, G. Swamy, and A. Bajcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment.arXiv preprint arXiv:2502.01828, 2025
arXiv 2025
-
[62]
Z. Li, J. Liu, Z. Dong, T. Teng, Q. Rouxel, D. Caldwell, and F. Chen. Towards deploying vla without fine-tuning: Plug-and-play inference-time vla policy steering via embodied evolution- ary diffusion.IEEE Robotics and Automation Letters, 11(5):6234–6241, 2026. 21
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.