Sample Where You Struggle: Sharpening Base Model Reasoning via Entropy-Guided Power Sampling
Pith reviewed 2026-06-27 18:47 UTC · model grok-4.3
The pith
Entropy-guided sampling focuses MCMC moves on high-entropy tokens to extract RL-level reasoning from base models at 12x lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
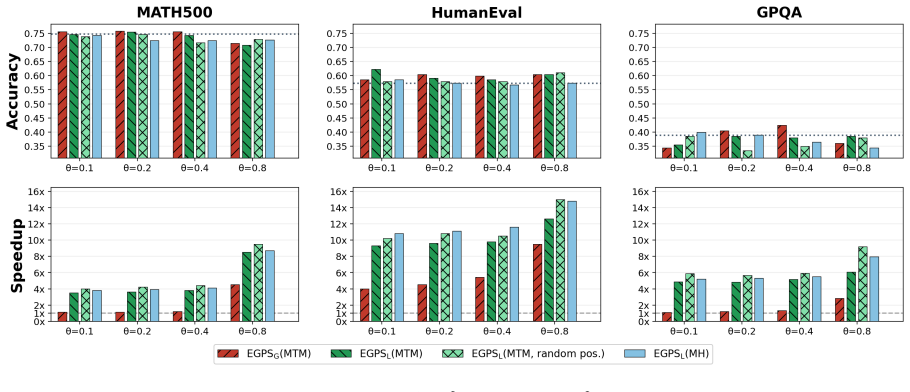
By localizing proposals to high-entropy neighborhoods already visible in the forward pass, EGPS makes power sampling practical: it reaches 75.8 percent on MATH500, 62.2 percent on HumanEval and 42.4 percent on GPQA at up to 12.6 times the speed of standard Metropolis-Hastings without any parameter updates or external verifiers.
What carries the argument
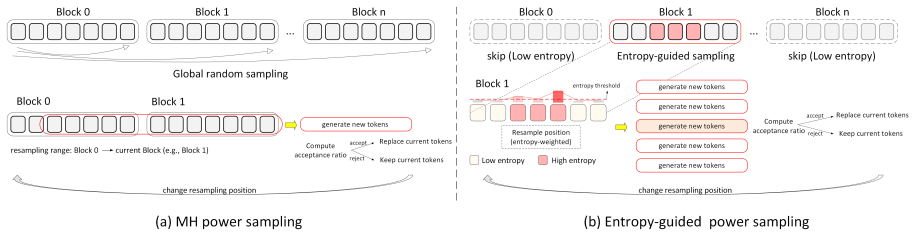
Entropy-Guided Power Sampling (EGPS), which skips deterministic blocks and re-derives each MCMC proposal from token-level entropy to localize moves at high-entropy decision points.
If this is right
- Accuracy on MATH500, HumanEval and GPQA reaches or ties the best reported figures for the base model.
- Wall-clock cost of power sampling drops by up to a factor of 12.6 relative to uniform Metropolis-Hastings.
- The approach requires no gradient updates and no external verifier.
- Sampling expense becomes proportional to entropy mass rather than total sequence length.
Where Pith is reading between the lines
- Reasoning traces may be dominated by a small number of uncertain tokens, so targeted resampling could be combined with other inference-time methods.
- The same entropy-localization idea might apply to any sequence model where the target distribution differs from the base model mainly at sparse decision points.
- If high-entropy clusters are stable across domains, the method could reduce the need for task-specific fine-tuning in favor of inference-only adjustments.
Load-bearing premise
The differences between p^α and p are concentrated in a sparse, spatially clustered set of high-entropy tokens so that localizing proposals there is sufficient.
What would settle it
A benchmark run in which EGPS accuracy falls more than two points below the MH baseline or wall-clock speedup drops below 3x after accounting for entropy computation overhead.
Figures
read the original abstract
Sampling from the sequence-level power distribution $p^\alpha$ elicits RL-level reasoning from base language models without any parameter updates, but the standard Metropolis--Hastings (MH), a Markov Chain Monte Carlo (MCMC) sampler, is both expensive and slow-mixing. We trace both to a structural mismatch: $p^\alpha$ mainly departs from $p$ at a sparse, spatially clustered set of high-entropy decision points, yet MH proposes resampling positions uniformly along the prefix -- wasting compute on near-degenerate conditionals while under-mixing precisely where modes diverge. We propose Entropy-Guided Power Sampling (EGPS), a training-free and verifier-free sampler that re-derives its proposal from token-level entropy already in the forward pass. EGPS skips deterministic blocks, localizes each MCMC move to a high-entropy neighborhood, and applies Multiple-Try Metropolis at decision points -- making sampling cost scale with \emph{entropy mass rather than sequence length}. On Qwen2.5-Math-7B, EGPS reaches best or tied-best accuracy on all three benchmarks (MATH500 $75.8\%$, HumanEval $62.2\%$, GPQA $42.4\%$) at up to a $12.6\times$ wall-clock speedup over the MH baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard Metropolis-Hastings sampling from the sequence-level power distribution p^α is inefficient due to a structural mismatch with the base model p, which occurs mainly at sparse, clustered high-entropy tokens. It introduces Entropy-Guided Power Sampling (EGPS), a training-free sampler that uses token-level entropy to skip deterministic blocks, localize MCMC moves, and apply Multiple-Try Metropolis, achieving best or tied-best accuracies (MATH500 75.8%, HumanEval 62.2%, GPQA 42.4%) on Qwen2.5-Math-7B with up to 12.6× wall-clock speedup over MH.
Significance. If the empirical claims hold and the localization assumption is validated, EGPS would provide a practical, parameter-light inference-time method to sharpen base-model reasoning without RL or verifiers, with efficiency scaling tied to entropy mass rather than length. The training-free and verifier-free design is a clear strength relative to other inference scaling approaches.
major comments (2)
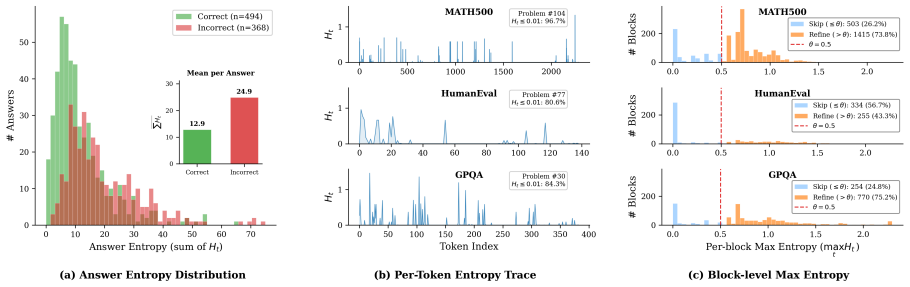
- [Abstract, §1] Abstract and §1 (motivation): The premise that p^α departs from p 'mainly' at a 'sparse, spatially clustered set of high-entropy decision points' is load-bearing for both the claimed 12.6× speedup and the correctness of skipping blocks/localizing moves, yet the manuscript supplies no quantitative support such as the measured fraction of positions where |log p^α − log p| exceeds a threshold, spatial clustering statistics, or counter-example sequences where divergence is diffuse.
- [§4] §4 (experiments): The reported accuracies and speedups on MATH500, HumanEval, and GPQA are presented without error bars, ablation controls on the entropy-guidance components, or implementation details on evaluation protocol (e.g., number of chains, burn-in, proposal parameters, or how wall-clock time was measured), preventing assessment of whether the gains are robust or reproducible.
minor comments (2)
- [§2] Notation for the power distribution p^α and the entropy-guided proposal should be introduced with explicit equations early in §2 to avoid ambiguity when describing Multiple-Try Metropolis.
- [§4] Figure captions and axis labels in the experimental section would benefit from explicit mention of the base model (Qwen2.5-Math-7B) and the exact α value used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for stronger validation and reproducibility.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1 (motivation): The premise that p^α departs from p 'mainly' at a 'sparse, spatially clustered set of high-entropy decision points' is load-bearing for both the claimed 12.6× speedup and the correctness of skipping blocks/localizing moves, yet the manuscript supplies no quantitative support such as the measured fraction of positions where |log p^α − log p| exceeds a threshold, spatial clustering statistics, or counter-example sequences where divergence is diffuse.
Authors: We agree that this premise is central and that direct quantitative evidence would strengthen the motivation. The current manuscript relies on qualitative tracing of the mismatch and the resulting empirical speedups, but does not include explicit measurements of divergence fractions, clustering statistics, or diffuse counterexamples. In the revised version we will add an analysis (main text or appendix) reporting these quantities on the evaluated benchmarks, including the fraction of positions exceeding chosen divergence thresholds, average spatial cluster sizes, and selected sequence examples. revision: yes
-
Referee: [§4] §4 (experiments): The reported accuracies and speedups on MATH500, HumanEval, and GPQA are presented without error bars, ablation controls on the entropy-guidance components, or implementation details on evaluation protocol (e.g., number of chains, burn-in, proposal parameters, or how wall-clock time was measured), preventing assessment of whether the gains are robust or reproducible.
Authors: We agree that the experimental reporting is insufficient for full reproducibility and robustness assessment. The revision will add error bars computed over multiple independent runs, ablations that isolate the entropy-guidance components (e.g., uniform vs. entropy-localized proposals), and complete protocol details including chain counts, burn-in lengths, proposal parameters, and the exact procedure used for wall-clock timing. revision: yes
Circularity Check
No circularity: algorithmic proposal is self-contained
full rationale
The paper presents EGPS as a direct algorithmic re-derivation of the MCMC proposal distribution from token-level entropy already computed in the forward pass, with no fitted parameters, no predictions that reduce to internal fits by construction, and no load-bearing self-citations or uniqueness theorems invoked. The central claims rest on the stated structural mismatch between p and p^α as motivation for the design, but this mismatch is asserted rather than mathematically derived within the paper, and the efficiency/accuracy results are reported as empirical outcomes of the modified sampler rather than forced by any internal definition or renaming. The derivation chain therefore contains no self-referential reductions of the enumerated kinds.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (1)
- domain assumption Token-level entropy computed in the forward pass is a reliable proxy for locations where p^α differs most from p.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:2510.14901 , year=
Reasoning with sampling: Your base model is smarter than you think , author=. arXiv preprint arXiv:2510.14901 , year=
-
[9]
arXiv preprint arXiv:2601.21590 , year=
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening , author=. arXiv preprint arXiv:2601.21590 , year=
-
[10]
arXiv preprint arXiv:2602.10273 , year=
Power-SMC: Low-Latency Sequence-Level Power Sampling for Training-Free LLM Reasoning , author=. arXiv preprint arXiv:2602.10273 , year=
-
[11]
Authorea Preprints , year=
Uncertainty-Driven Adaptive Sampling for Resource-Efficient Language Model Inference , author=. Authorea Preprints , year=
-
[12]
arXiv preprint arXiv:2411.19943 , year=
Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability , author=. arXiv preprint arXiv:2411.19943 , year=
-
[13]
arXiv preprint arXiv:2510.13940 , year=
Less is More: Improving LLM Reasoning with Minimal Test-Time Intervention , author=. arXiv preprint arXiv:2510.13940 , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2508.15260 , year=
Deep think with confidence , author=. arXiv preprint arXiv:2508.15260 , year=
-
[16]
arXiv preprint arXiv:2601.12269 , year=
Simulated Annealing Enhances Theory-of-Mind Reasoning in Autoregressive Language Models , author=. arXiv preprint arXiv:2601.12269 , year=
-
[17]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Rewarding the unlikely: Lifting grpo beyond distribution sharpening , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[18]
arXiv preprint arXiv:2504.13837 , year=
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. arXiv preprint arXiv:2504.13837 , year=
-
[19]
arXiv preprint arXiv:2604.16453 , year=
Sampling for Quality: Training-Free Reward-Guided LLM Decoding via Sequential Monte Carlo , author=. arXiv preprint arXiv:2604.16453 , year=
-
[20]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[21]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[22]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[23]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[24]
2024 , eprint=
Qwen2 Technical Report , author=. 2024 , eprint=
2024
-
[25]
arXiv preprint arXiv:2306.17806 , year=
Stay on topic with classifier-free guidance , author=. arXiv preprint arXiv:2306.17806 , year=
-
[26]
arXiv preprint arXiv:2509.06941 , year=
Outcome-based exploration for llm reasoning , author=. arXiv preprint arXiv:2509.06941 , year=
-
[27]
arXiv preprint arXiv:2605.02427 , year=
The Model Knows, the Decoder Finds: Future Value Guided Particle Power Sampling , author=. arXiv preprint arXiv:2605.02427 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.