SWE-INTERACT: Reimagining SWE Benchmarks as User-Driven Long-Horizon Coding Sessions
Pith reviewed 2026-06-30 06:53 UTC · model grok-4.3
The pith
Top coding models solve roughly 50 percent of single-turn tasks but only 25 percent when requirements evolve through repeated user feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
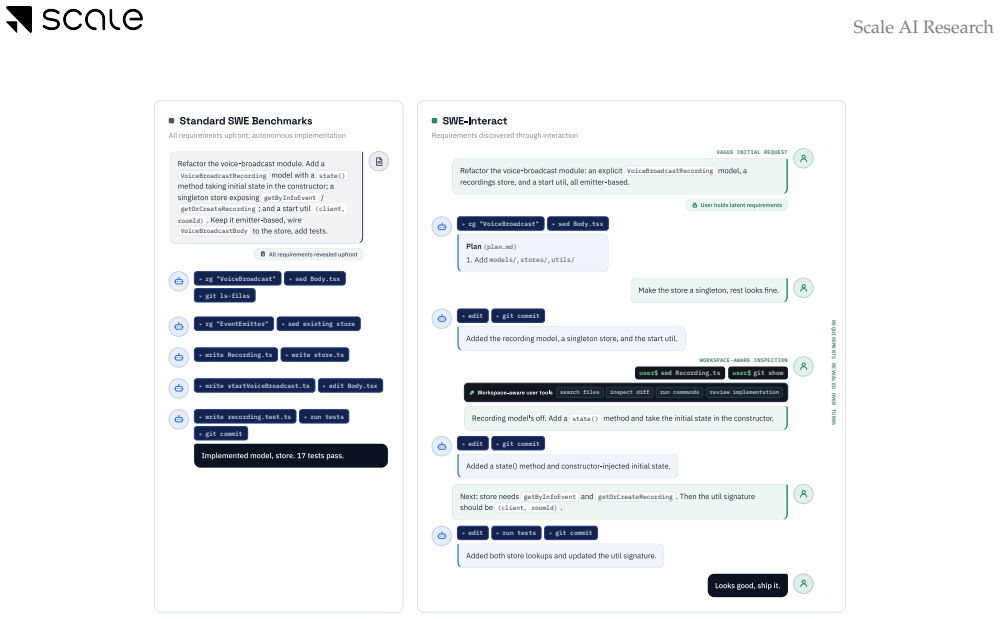
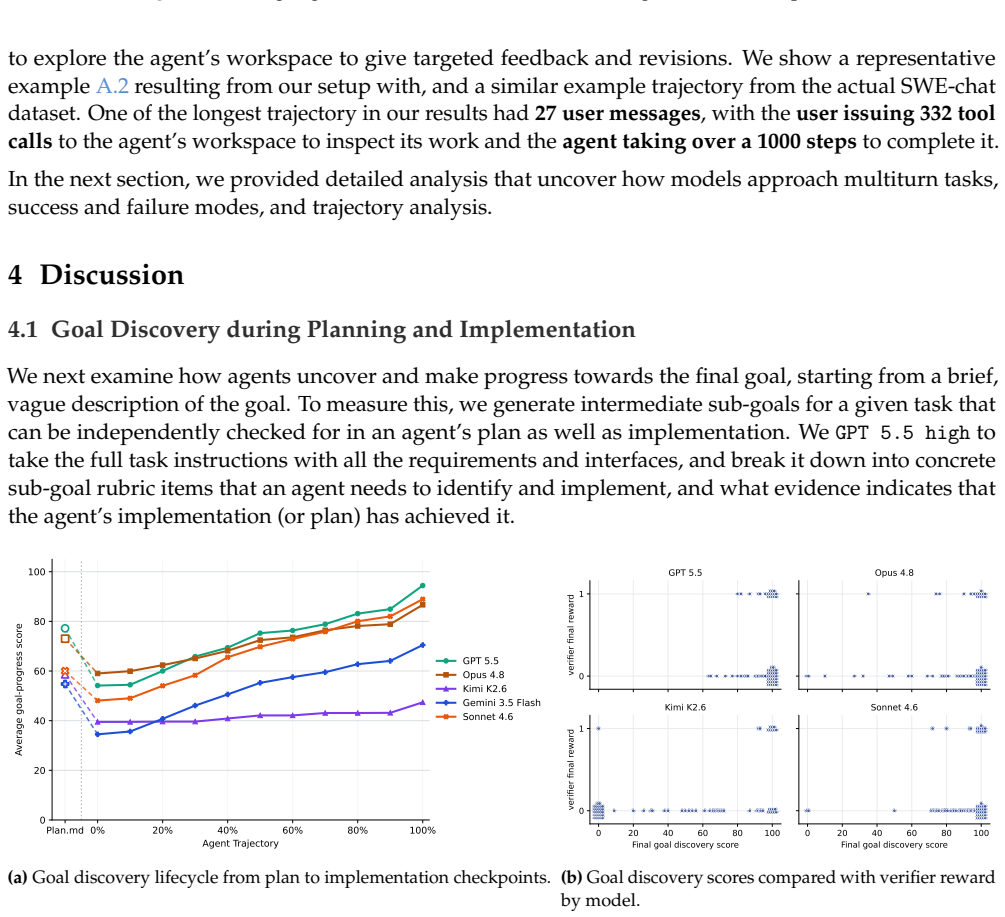
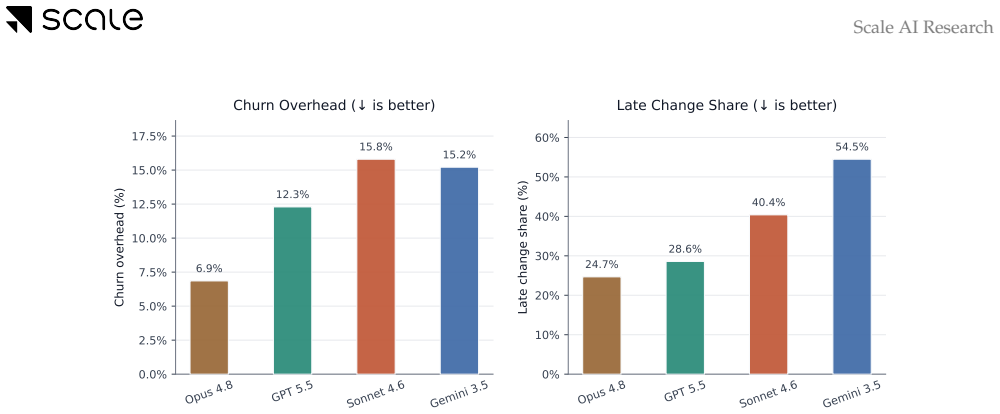
SWE-Interact places agents inside long-horizon sessions where a simulator grounded in real interaction studies starts with incomplete instructions, inspects the workspace, and supplies targeted feedback plus new constraints until the full goal is conveyed. The evaluation finds that the best models reach about 50 percent on matched single-turn baselines yet only 25 percent on the interactive versions, with even the strongest models exhibiting over-agentic coding, requirement forgetting, and technical errors while weaker models give up early or ignore instructions.
What carries the argument
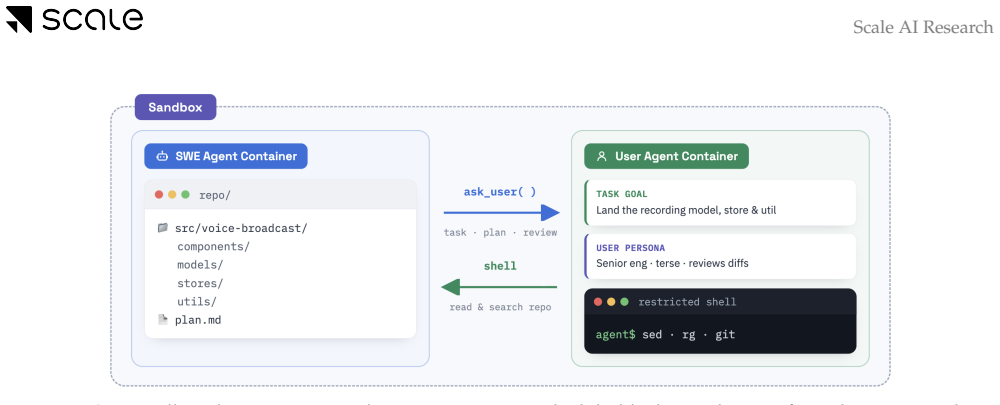
The user simulator that progressively reveals requirements, inspects the agent's workspace, and issues revisions until the complete task is handed off.
If this is right
- Agents must maintain running records of changing constraints rather than treating early code as fixed.
- Evaluation protocols need to include multi-turn sessions with partial information to capture real deployment conditions.
- Stronger models still require improved mechanisms to avoid over-committing to initial implementations.
- Weaker models require better handling of ambiguity before they can participate in iterative refinement.
Where Pith is reading between the lines
- Training pipelines that expose models only to complete specifications may systematically under-prepare them for live development workflows.
- Adding user-simulator loops to existing benchmarks could surface capability gaps that single-turn tests miss.
- Deployment of coding agents in practice may require separate calibration for the interactive-discovery phase before autonomous coding begins.
Load-bearing premise
The simulator produces interactions that match how real developers reveal intent and give feedback over time.
What would settle it
Direct comparison of model success rates on SWE-Interact against their success rates when the same tasks are completed with actual human developers providing the evolving requirements.
Figures

read the original abstract
We introduce SWE-Interact, a new testbed for evaluating coding agents on multi-turn, interactive, user-driven software engineering tasks. Existing frontier SWE benchmarks typically provide complete requirements upfront and evaluate agents on autonomous implementation. In contrast, SWE-Interact places agents in a realistic developer workflow: a carefully designed user simulator starts with vague or incomplete instructions, progressively reveals requirements, inspects the agent's workspace, and provides targeted feedback, revisions, and new constraints until the full task goal has been handed off. Grounded in large-scale studies of real coding-agent interactions, this setup tests whether agents can discover user intent, adapt to evolving requirements, and build on their own prior work. Across a suite of frontier and open-weight models, we find that strong performance on single-turn SWE tasks does not reliably transfer to multi-turn, user-driven workflows: the best-performing models solve roughly 50% of single-turn baseline tasks but only 25% of the corresponding SWE-Interact tasks. The strongest models in our evaluation, including Opus 4.8 and GPT 5.5, start strong even in the face of vague initial instructions, persevere until all the requirements are surfaced by the user, integrate them better and write clean code. However, they still suffer from over-agentic coding, forgetting requirements and technical mistakes. Weaker models start poorly under ambiguity, give up early, forget or ignore instructions and rework their code more. Overall, SWE-Interact measures an orthogonal, real-world capability axis for frontier model development: interactive goal discovery and iterative refinement with a user in the loop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-Interact, a benchmark that replaces single-turn SWE tasks (complete requirements given upfront) with multi-turn sessions driven by a user simulator. The simulator begins with vague instructions, progressively reveals requirements, inspects workspaces, and supplies feedback until the goal is met. Across frontier models the headline result is that ~50% success on single-turn baselines drops to ~25% on the corresponding SWE-Interact tasks; the authors interpret this gap as evidence that single-turn capability does not transfer to interactive, requirement-evolving workflows.
Significance. If the simulator faithfully reproduces the statistical properties of real developer–agent interactions, the work identifies an orthogonal evaluation axis—interactive goal discovery and iterative refinement—that current autonomous SWE benchmarks miss. The empirical comparison across multiple models supplies concrete evidence that existing leaderboards may overstate readiness for realistic coding sessions.
major comments (2)
- [Abstract and §3] Abstract and §3 (Evaluation Setup): the central transfer claim rests on the reported 50% vs. 25% gap, yet the manuscript supplies no information on task selection criteria, number of tasks per condition, statistical significance testing, or error analysis. Without these details the numerical comparison cannot be assessed for robustness.
- [§4] §4 (User Simulator): the simulator is stated to be 'grounded in large-scale studies of real coding-agent interactions,' but no quantitative validation is presented (e.g., KL divergence or distributional match on turn counts, requirement granularity, feedback type frequencies, or abandonment rates). Because simulator fidelity is the load-bearing assumption for interpreting the performance drop as a genuine capability gap rather than a benchmark artifact, this omission directly affects the main conclusion.
minor comments (2)
- [Abstract] Model names 'Opus 4.8' and 'GPT 5.5' appear without version or release dates; clarify exact checkpoints used.
- [Abstract] The abstract states that weaker models 'give up early' and 'rework their code more,' but no quantitative metrics (e.g., average turns before abandonment, edit counts) are referenced; add these to the results tables if present in the full evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify areas where additional detail will improve the clarity and credibility of our claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Evaluation Setup): the central transfer claim rests on the reported 50% vs. 25% gap, yet the manuscript supplies no information on task selection criteria, number of tasks per condition, statistical significance testing, or error analysis. Without these details the numerical comparison cannot be assessed for robustness.
Authors: We agree that the current description of the evaluation setup is insufficient for assessing robustness. In the revised manuscript we will expand §3 with: explicit task selection criteria (random stratified sample from SWE-Bench verified tasks meeting complexity and domain filters), the precise number of tasks per condition, statistical significance testing (McNemar’s test with bootstrap confidence intervals on the 50 % vs. 25 % gap), and a dedicated error-analysis subsection that quantifies the frequency of the failure modes already mentioned in the abstract (over-agentic coding, requirement forgetting, technical mistakes). revision: yes
-
Referee: [§4] §4 (User Simulator): the simulator is stated to be 'grounded in large-scale studies of real coding-agent interactions,' but no quantitative validation is presented (e.g., KL divergence or distributional match on turn counts, requirement granularity, feedback type frequencies, or abandonment rates). Because simulator fidelity is the load-bearing assumption for interpreting the performance drop as a genuine capability gap rather than a benchmark artifact, this omission directly affects the main conclusion.
Authors: We concur that quantitative validation of the simulator is necessary to support the central interpretation. Although the design is derived from the cited large-scale studies, the original submission does not report distributional matches. We will add a new subsection (or appendix) to §4 that presents KL-divergence and frequency comparisons on turn counts, requirement granularity, feedback-type distributions, and abandonment rates, computed against the statistics reported in the grounding studies. This addition will directly address the concern that the observed gap might be an artifact of simulator mismatch. revision: yes
Circularity Check
No circularity: direct empirical measurements on a new benchmark
full rationale
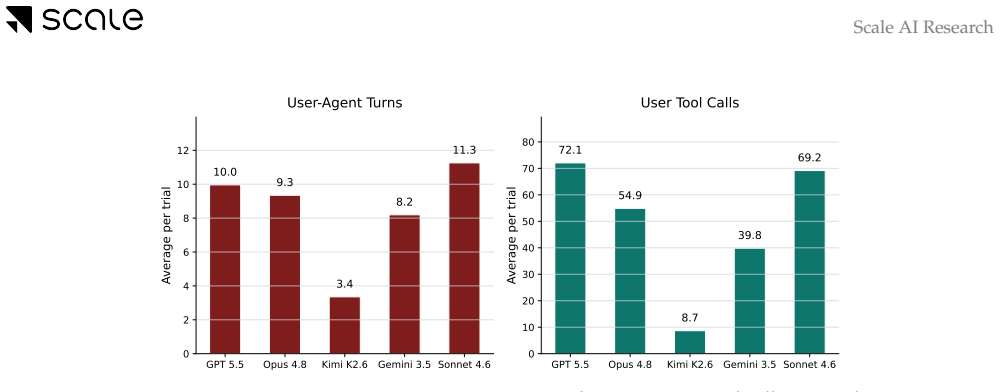
The paper introduces SWE-Interact as a new testbed and reports raw performance percentages (50% single-turn vs 25% interactive) as direct empirical results from running models on the benchmark. No equations, fitted parameters, or derived quantities are presented as predictions. The simulator is described as grounded in external large-scale studies without any self-citation chain or uniqueness theorem invoked to justify the central transfer claim. The reported gap is a straightforward measurement rather than a reduction to prior inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The user simulator accurately models real developer interactions and requirement evolution.
Reference graph
Works this paper leans on
-
[1]
E. Bao, A. Perez, X. Wang, and J. Parapar. Eval4sim: An evaluation framework for persona simulation, 2026
2026
-
[2]
Barres, H
V . Barres, H. Dong, X. Si, S. Ray, and K. Narasimhan.τ2-bench: Evaluating conversational agents in a dual-control environment, 2025
2025
-
[3]
Baumann, V
J. Baumann, V . Padmakumar, X. Li, J. Yang, D. Yang, and S. Koyejo. Swe-chat: Coding agent interactions from real users in the wild, 2026
2026
-
[4]
X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. Hendryx, Z. Wang, V . Bharadwaj, J. Holm, R. Aluri, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?, 2025. URLhttps://arxiv.org/abs/2509.16941
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
SWE-Marathon: Can Agents Autonomously Complete Ultra-Long-Horizon Software Work?
R. Desai, J. Hu, J. Cabezas, N. Harsola, P . Shukla, R. B. Chaim, A. E. Assadi, O. M. Kamath, F. Faldu, P . Hebbar, J. Sun, Y. Li, P . Srinivasan, I. Gupta, C. Settles, D. Wang, D. Chen, P . Raja, A. Liu, M. Šuppa, N. Sasikumar, L. Kong, E. Quintanilla, X. Li, I. Bercovich, and S. Dillmann. Swe-marathon: Can agents autonomously complete ultra-long-horizon...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Y. Dou, M. Galley, B. Peng, C. Kedzie, W. Cai, A. Ritter, C. Quirk, W. Xu, and J. Gao. Simulatorarena: Are user simulators reliable proxies for multi-turn evaluation of ai assistants?, 2025
2025
-
[7]
Huang, C
W. Huang, C. Lee, L. Tng, and S. Ge. Deepswe: Measuring frontier coding agents on original, long-horizon engineering tasks, 2026. URLhttps://github.com/datacurve-ai/deep-swe
2026
-
[8]
Mehri, X
S. Mehri, X. Yang, T. Kim, G. Tur, D. Hakkani-Tur, and S. Mehri. Goal alignment in llm-based user simulators for conversational ai, 2026. 10 Scale AI Research
2026
-
[9]
Naous, P
T. Naous, P . Laban, W. Xu, and J. Neville. Flipping the dialogue: Training and evaluating user language models, 2026
2026
-
[10]
Orlanski, D
G. Orlanski, D. Roy, A. Yun, C. Shin, A. Gu, A. Ge, D. Adila, F. Sala, and A. Albarghouthi. Slop- codebench: Benchmarking how coding agents degrade over long-horizon iterative tasks, 2026
2026
- [11]
-
[12]
SWE Atlas: Benchmarking Coding Agents Beyond Issue Resolution
M. Raghavendra, S. Dan, M. R. Calvo, Y. Y. He, J. B. Mols, G. Anand, C. McCollum, E. Arakelyan, V . Bharadwaj, A. Park, J. Da, M. Rezaei, B. Liu, B. Kenstler, and Y. He. Swe atlas: Benchmarking coding agents beyond issue resolution, 2026. URLhttps://arxiv.org/abs/2605.08366
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Raghavendra, A
M. Raghavendra, A. Gunjal, B. Liu, and Y. He. Agentic rubrics as contextual verifiers for swe agents,
- [14]
-
[15]
S. Ray, K. Dhandhania, V . Barres, and K. Narasimhan.τ-voice: Benchmarking full-duplex voice agents on real-world domains, 2026
2026
-
[16]
Seshadri, S
P . Seshadri, S. Cahyawijaya, A. Odumakinde, S. Singh, and S. Goldfarb-Tarrant. Lost in simulation: Llm-simulated users are unreliable proxies for human users in agentic evaluations, 2026
2026
-
[17]
R. Shea, Y. Lu, L. Qiu, and Z. Yu. Sage: A top-down bottom-up knowledge-grounded user simulator for multi-turn agent evaluation, 2026
2026
-
[18]
H. Shen, X. Chen, W. Xu, Y. Ma, L. Chen, and K. Li. Evocode-bench: Evaluating coding agents in multi-turn iterative interactions, 2026
2026
-
[19]
Q. Shi, A. Zytek, P . Razavi, K. Narasimhan, and V . Barres.τ-knowledge: Evaluating conversational agents over unstructured knowledge, 2026
2026
-
[20]
J. Shim, W. Song, C. Jin, S. Kook, and Y. Jo. Non-collaborative user simulators for tool agents, 2026
2026
-
[21]
M. V . T. Thai, T. Le, D. Nguyen Manh, H. Phan Nhat, and N. D. Q. Bui. Swe-evo: Benchmarking coding agents in long-horizon software evolution scenarios, 2025
2025
-
[22]
HiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
T. Trinh, M. Elfeki, G. Luo, K. Luu, N. Hunt, E. Hernandez, N. Marwaha, Y. Y. He, C. Wang, F. Carabedo, A. Castillo, and B. Liu. Hil-bench (human-in-loop benchmark): Do agents know when to ask for help?, 2026. URLhttps://arxiv.org/abs/2604.09408
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Vijayvargiya, X
S. Vijayvargiya, X. Zhou, A. Yerukola, M. Sap, and G. Neubig. Ambig-swe: Interactive agents to overcome underspecificity in software engineering, 2026
2026
-
[24]
X. Wang, L. Sun, Y. Zhu, S. Zhou, J. Liu, F. Chen, L. Qiu, X. Cao, X. Cai, L. Zhang, and Z. Mao. Asuka-bench: Benchmarking code agents on underspecified user intent and multi-round refinement, 2026
2026
-
[25]
S. Wu, E. Choi, A. Khatua, Z. Wang, J. He-Yueya, T. C. Weerasooriya, W. Wei, D. Yang, J. Leskovec, and J. Zou. Humanlm: Simulating users with state alignment beats response imitation, 2026
2026
-
[26]
J. Yang, K. Lieret, J. Yang, C. E. Jimenez, O. Press, L. Schmidt, and D. Yang. Codeclash: Benchmarking goal-oriented software engineering, 2025. 11 Scale AI Research
2025
-
[27]
J. Yang, K. Lieret, J. Ma, P . Thakkar, D. Pedchenko, S. Sootla, E. McMilin, P . Yin, R. Hou, G. Synnaeve, D. Yang, and O. Press. Programbench: Can language models rebuild programs from scratch?, 2026
2026
-
[28]
S. Yao, N. Shinn, P . Razavi, and K. Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
2024
-
[29]
Z. Zhan, S. Gao, R. Hu, and C. Gao. Sr-eval: Evaluating llms on code generation under stepwise requirement refinement, 2026
2026
-
[30]
X. Zhou, V . Chen, Z. Z. Wang, G. Neubig, M. Sap, and X. Wang. Tom-swe: User mental modeling for software engineering agents, 2026
2026
-
[31]
60")returns60000. minutes_seconds_sum7 Correctly sum distinct minute and second components. parse_duration(
X. Zhou, W. Sun, Q. Ma, Y. Xie, J. Liu, W. Du, S. Welleck, Y. Yang, G. Neubig, S. T. Wu, and M. Sap. Mind the sim2real gap in user simulation for agentic tasks, 2026. 12 Scale AI Research A Appendix I A.1 Multi-turn Resolve-Rate Confidence Intervals Model Pass / N Resolve Rate GPT 5.5 37/150 24.7% [18.5, 32.1] Opus 4.8 40/150 26.7% [20.2, 34.3] Kimi K2.6 ...
2026
-
[32]
Incoming Open Library author key
-
[33]
Incoming ‘remote_ids‘
-
[34]
When an existing author is matched, merge in any new remote IDs
Existing name/date fallback logic. When an existing author is matched, merge in any new remote IDs. Report an error on conflicts and avoid partial saves. ## Implementation Steps
-
[35]
remote_ids
Add remote-id helper logic in ‘openlibrary/catalog/add_book/load_book.py‘. - Accept incoming ‘author["remote_ids"]‘ as a dictionary of provider names to non-empty string values. - Query authors by nested fields like ‘remote_ids.viaf‘. - Reuse redirect resolution behavior so redirected author matches resolve to final author records
-
[36]
- If an import author has an OL ‘key‘, fetch and use that author first
Update author matching order. - If an import author has an OL ‘key‘, fetch and use that author first. - Otherwise, try matching by ‘remote_ids‘. - If no remote-id match exists, use the existing name, alternate-name, and surname/date matching
-
[37]
- Error if an incoming OL key is missing or does not point to an author
Add conflict handling. - Error if an incoming OL key is missing or does not point to an author. - Error if incoming remote IDs match multiple different authors. - Error if the matched author already has the same remote-id provider with a different value. - Error if an incoming OL key matches one author but any incoming remote ID belongs to a different author
-
[38]
- Preserve existing author fields
Merge and persist matched author updates. - Preserve existing author fields. - Merge any new incoming ‘remote_ids‘ into the matched author. - Keep the existing behavior that fills ‘death_date‘ when the import provides it and the matched author lacks it. - Ensure modified matched authors are included in the add-book ‘save_many‘ batch, because the current ‘...
-
[39]
- When no existing author matches, copy valid ‘remote_ids‘ into the new author dict alongside the existing name/date fields
Preserve remote IDs on newly created author candidates. - When no existing author matches, copy valid ‘remote_ids‘ into the new author dict alongside the existing name/date fields
-
[40]
- Remote-id match prevents duplicate author creation when names/dates do not match
Add focused tests. - Remote-id match prevents duplicate author creation when names/dates do not match. - OL key takes priority over remote-id/name matching. - New remote IDs are merged and persisted on matched authors. - Conflicting remote IDs return an error and do not save partial changes. - New authors keep imported ‘remote_ids‘. ## Expected Files - ‘o...
-
[41]
- Extract ‘remote_ids‘ or ‘identifiers‘ from the incoming ‘author‘ dictionary: ‘‘‘python remote_ids = author.get(’remote_ids’) or author.get(’identifiers’) or {} ‘‘‘
**Identifier Extraction** - Locate ‘find_entity(author)‘ in ‘openlibrary/catalog/add_book/load_book.py‘. - Extract ‘remote_ids‘ or ‘identifiers‘ from the incoming ‘author‘ dictionary: ‘‘‘python remote_ids = author.get(’remote_ids’) or author.get(’identifiers’) or {} ‘‘‘
-
[42]
type": "/type/author
**Authoritative Database Query** - Iterate through supported identifier keys: - ‘viaf‘ - ‘goodreads‘ - ‘amazon‘ - ‘librivox‘ - ‘wikidata‘ - ‘isni‘ - ‘lc_naf‘ - ‘gnd‘ - ‘librarything‘ - ‘project_gutenberg‘ - If an identifier value is present, execute a query on the Infogami DB to find existing matching authors: ‘‘‘python web.ctx.site.things({"type": "/type...
-
[43]
**Redirect Resolution** - If match keys are found, resolve any redirects using ‘walk_redirects‘ to ensure we retrieve the canonical author records
-
[44]
This bypasses name/date matching checks that would otherwise reject matches if birth/death dates are missing or slightly mismatch
**Immediate Match Overrides** - If a unique canonical match is found via authoritative identifiers, return it directly. This bypasses name/date matching checks that would otherwise reject matches if birth/death dates are missing or slightly mismatch
-
[45]
not sure, your call
**Self-Verification & Testing** - Write comprehensive unit tests in ‘openlibrary/catalog/add_book/tests/test_load_book.py‘ to cover matches by Goodreads, VIAF, etc., including cases where dates mismatch or are missing. 17 Scale AI Research A.5 User-Simulator Prompt The following shows the modules concatenated into the user-simulator prompt used in the pap...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.