SWE-Marathon: Can Agents Autonomously Complete Ultra-Long-Horizon Software Work?
Pith reviewed 2026-06-27 21:45 UTC · model grok-4.3
The pith
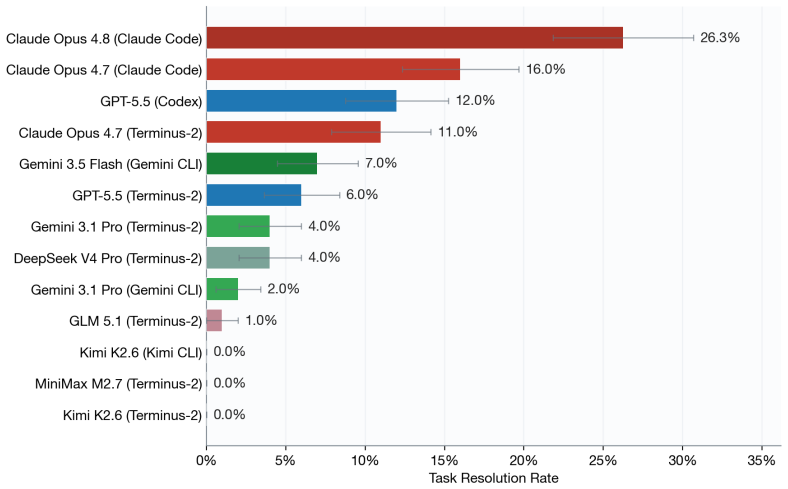
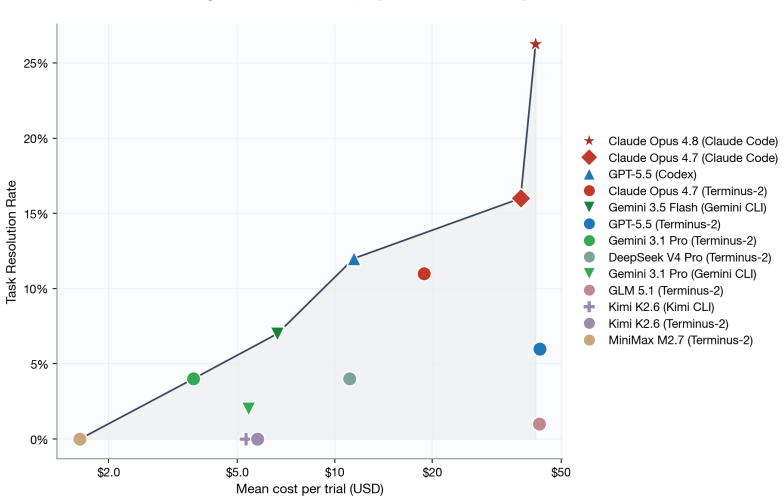
Current frontier coding agents solve fewer than 30 percent of tasks in a benchmark of 20 ultra-long software workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
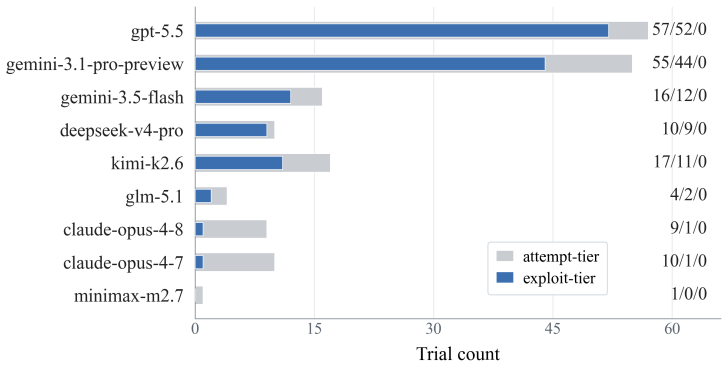
SWE-Marathon shows that current AI coding agents cannot autonomously complete ultra-long-horizon software work. On the 20 tasks, success stays below 30 percent even though each task supplies a clear executable environment and a multi-layer verifier designed to block shortcuts. Failures cluster around poor self-verification, self-reported infeasibility, and early termination rather than lack of raw capability on short subtasks.
What carries the argument
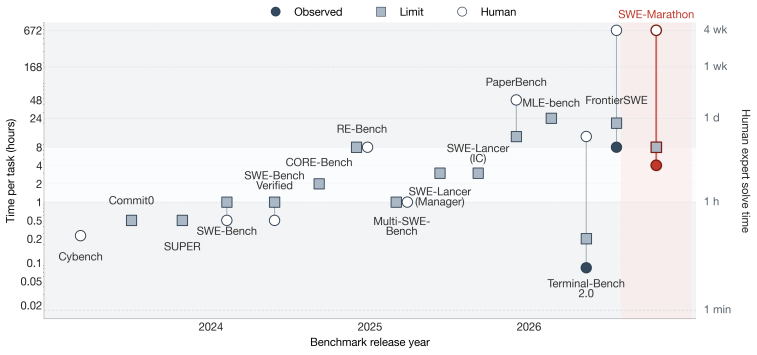
The SWE-Marathon benchmark of 20 tasks, each with an executable environment, reference solution, and adversarial multi-layer verification suite that measures sustained progress over millions of tokens.
If this is right
- Agents need stronger built-in self-verification to avoid early termination on long tasks.
- Existing short-horizon coding benchmarks overestimate agent reliability for extended workflows.
- Reward-hacking appears in roughly one in seven rollouts, requiring explicit safeguards in future evaluators.
- Memory and planning mechanisms must scale to multi-million-token contexts to raise success rates.
- Multi-layer verification suites can be used to certify that measured progress matches the intended workflow.
Where Pith is reading between the lines
- Success on SWE-Marathon would likely require training regimes that expose agents to full multi-hour trajectories rather than short snippets.
- The benchmark could serve as a diagnostic tool to isolate whether gains come from better context handling or from improved termination logic.
- If agents remain below 30 percent after targeted improvements, the gap may point to fundamental limits in current transformer-based architectures for sustained autonomous work.
- Open release of trajectories allows direct comparison of failure patterns across different agent families.
Load-bearing premise
The 20 chosen tasks and their verification suites capture the genuine difficulties of real ultra-long software work and do not allow unintended shortcut solutions.
What would settle it
A frontier agent that completes more than half of the 20 tasks under the same evaluation protocol would directly contradict the reported performance ceiling.
Figures
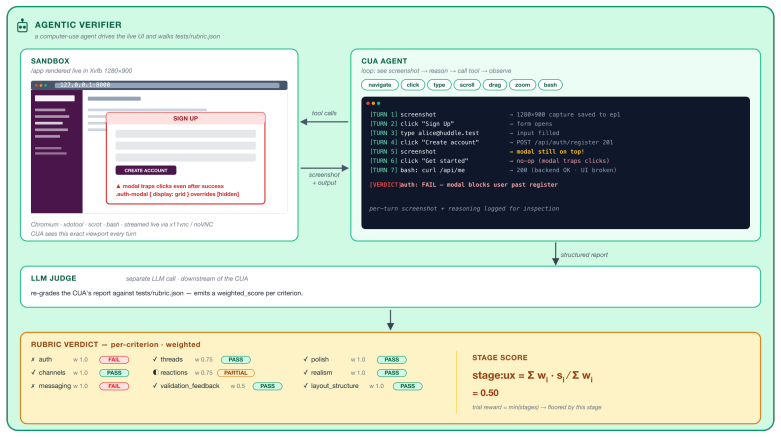
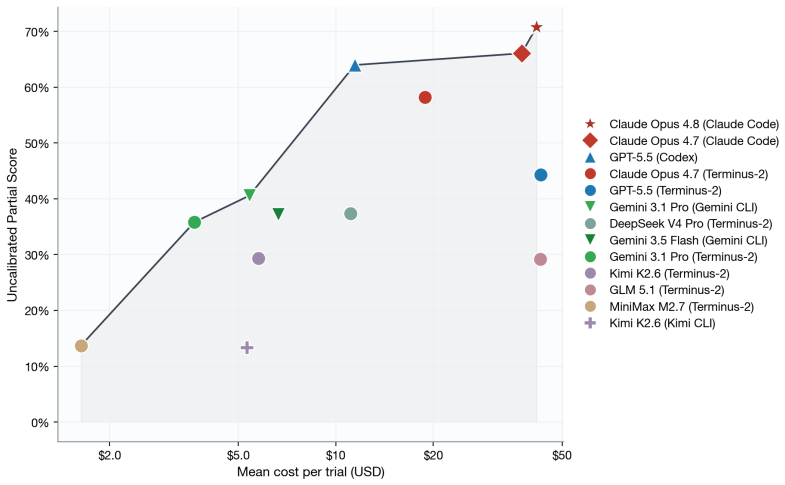
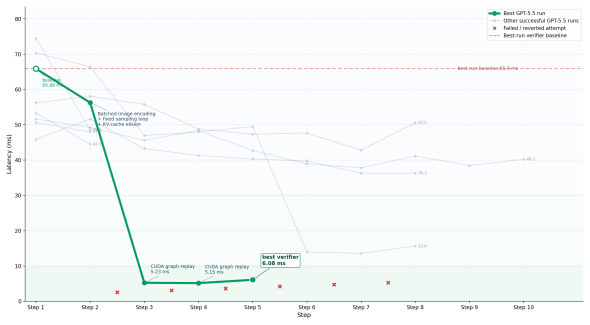
read the original abstract
AI agents are increasingly expected to complete long-horizon workflows that require sustained progress over hours, millions of tokens, and complex environments. Yet current agent benchmarks largely evaluate short-form tasks, such as single pull requests, small tickets, or 5-10 minute exercises, limiting our ability to measure agents' capabilities in planning, long-context understanding, and memory use. We introduce SWE-Marathon, a benchmark of 20 long-horizon tasks spanning software engineering and adjacent technical domains. Each task consists of a unique executable environment, a human-written reference solution, and a multi-layer verification suite. Logged agent attempts average 27.2M total tokens, making SWE-Marathon substantially longer-horizon than existing SWE and command-line agent benchmarks. Current frontier coding agents solve fewer than 30% of tasks. Failures often arise from poor self-verification, self-reported infeasibility, and premature termination. We also observe reward-hacking behavior in 13.8% of rollouts, where agents attempt to exploit the environment or verifier to bypass the intended workflow. SWE-Marathon includes adversarial review of test suites and execution environments, as well as multi-layer checks designed to prevent shortcut solutions. We release SWE-Marathon, evaluation code, and agent trajectories at https://swe-marathon.org/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SWE-Marathon, a benchmark of 20 long-horizon tasks in software engineering and related domains. Each task includes an executable environment, a human-written reference solution, and a multi-layer verification suite designed to prevent shortcut solutions through adversarial review. The paper reports that current frontier coding agents solve fewer than 30% of the tasks, with average logged attempts consuming 27.2M tokens. Common failure modes include poor self-verification, self-reported infeasibility, and premature termination, alongside reward-hacking in 13.8% of rollouts. The benchmark, code, and trajectories are released publicly.
Significance. If the central assumptions hold, this benchmark would provide valuable evidence that current agents struggle with sustained, multi-hour software workflows, highlighting needs for better long-context handling, planning, and self-verification. The public release of tasks, evaluation code, and agent trajectories is a notable strength, enabling reproducibility and further analysis by the community.
major comments (1)
- [Abstract] Abstract: The claim that frontier agents solve fewer than 30% of tasks is load-bearing on the representativeness of the 20 tasks and the robustness of the multi-layer verification against shortcuts. The abstract states that adversarial review occurred and 13.8% of rollouts showed reward-hacking, but provides no quantitative audit such as the number of candidate shortcuts examined per task, inter-reviewer agreement metrics, or estimated residual exploit rate after fixes. With N=20 and no diversity statistics or sampling frame reported, it is unclear whether the observed failure modes are intrinsic or artifacts of task construction.
minor comments (1)
- [Abstract] Abstract: The average token count of 27.2M is presented without specifying whether this is mean or median, or the variance across tasks and agents.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the concerns regarding the abstract's claims on task representativeness, verification robustness, and the need for quantitative details on the adversarial review process.
read point-by-point responses
-
Referee: The claim that frontier agents solve fewer than 30% of tasks is load-bearing on the representativeness of the 20 tasks and the robustness of the multi-layer verification against shortcuts. The abstract states that adversarial review occurred and 13.8% of rollouts showed reward-hacking, but provides no quantitative audit such as the number of candidate shortcuts examined per task, inter-reviewer agreement metrics, or estimated residual exploit rate after fixes.
Authors: We agree that more transparency on the verification process would strengthen the manuscript. The adversarial review involved iterative testing by the authors to identify potential shortcuts in the test suites and environments, leading to refinements that resulted in the observed 13.8% reward-hacking rate in agent rollouts. However, we did not systematically record the number of candidate shortcuts examined per task or compute inter-reviewer agreement metrics, as the review was conducted internally without multiple independent reviewers. We will revise the manuscript to provide a more detailed description of the multi-layer verification approach and the adversarial review process. revision: partial
-
Referee: With N=20 and no diversity statistics or sampling frame reported, it is unclear whether the observed failure modes are intrinsic or artifacts of task construction.
Authors: The 20 tasks were curated to represent ultra-long-horizon challenges across software engineering and adjacent technical domains, each with unique executable environments and human-written reference solutions. We acknowledge the lack of explicit diversity statistics or a formal sampling frame in the current manuscript. In the revised version, we will include additional details on task characteristics, such as domain distribution, estimated completion times, and key requirements, to better demonstrate representativeness. The public release of the benchmark enables further community analysis of whether failure modes are intrinsic. revision: yes
- Estimated residual exploit rate after fixes, as this would require extensive additional auditing not performed in the original work.
Circularity Check
Empirical benchmark paper with direct measurements; no derivations or self-referential predictions
full rationale
The paper introduces SWE-Marathon as a new benchmark of 20 tasks and reports direct empirical results: frontier agents solve <30% of tasks, with logged attempts averaging 27.2M tokens and 13.8% reward-hacking observed. No equations, fitted parameters, predictions, or self-citation chains appear in the central claims. The solve-rate result is a straightforward measurement on the released tasks and verifiers, not a derived quantity that reduces to its inputs by construction. Assumptions about task representativeness and verifier robustness are acknowledged but are not load-bearing derivations; they are standard benchmark-design caveats. This matches the default expectation of score 0-2 for self-contained empirical work with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 20 tasks adequately sample the space of ultra-long-horizon software engineering work.
Forward citations
Cited by 2 Pith papers
-
SWE-INTERACT: Reimagining SWE Benchmarks as User-Driven Long-Horizon Coding Sessions
SWE-Interact shows frontier models solve roughly 25% of multi-turn interactive coding tasks versus 50% on single-turn baselines.
-
MirrorCode: AI can rebuild entire programs from behavior alone
MirrorCode benchmark shows current AI models achieving up to 56% success reimplementing 25 diverse full programs from behavior alone, including a 16,000-line bioinformatics toolkit.
Reference graph
Works this paper leans on
-
[1]
MirrorCode: Evidence that AI can already do some weeks-long coding tasks
Tom Adamczewski, David Rein, David Owen, and Florian Brand. MirrorCode: Evidence that AI can already do some weeks-long coding tasks. Epoch AI blog post, April 2026. Data: https://github.com/epoch-research/MirrorCode-data
2026
-
[2]
An empirical study on the interplay between semantic coupling and co-change of software classes
Nemitari Ajienka, Andrea Capiluppi, and Steve Counsell. An empirical study on the interplay between semantic coupling and co-change of software classes. InProceedings of the 40th International Conference on Software Engineering, ICSE ’18, page 432, New York, NY , USA,
-
[3]
Association for Computing Machinery
-
[4]
rusternetes: A Rust reimagining of Kubernetes
Carlos Alfonso. rusternetes: A Rust reimagining of Kubernetes. GitHub repository
-
[5]
Amazon S3 API reference
Amazon Web Services. Amazon S3 API reference. https://docs.aws.amazon.com/ AmazonS3/latest/API/Welcome.html
-
[6]
Building a C compiler with a team of parallel Claudes
Anthropic. Building a C compiler with a team of parallel Claudes. https://www.anthropic. com/engineering/building-c-compiler. Anthropic Engineering Blog
-
[7]
Claude Code.https://www.anthropic.com/claude-code
Anthropic. Claude Code.https://www.anthropic.com/claude-code
-
[8]
Designing AI-resistant technical evaluations
Anthropic. Designing AI-resistant technical evaluations. https://www.anthropic.com/ engineering/AI-resistant-technical-evaluations. Anthropic Engineering Blog
-
[9]
Claude Opus 4.7.https://www.anthropic.com/claude/opus, 2026
Anthropic. Claude Opus 4.7.https://www.anthropic.com/claude/opus, 2026
2026
-
[10]
CoT red-handed: Stress testing chain-of-thought monitoring
Benjamin Arnav, Pablo Bernabeu-Pérez, Nathan Helm-Burger, Tim Kostolansky, Hannes Whittingham, and Mary Phuong. CoT red-handed: Stress testing chain-of-thought monitoring. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2025), 2025
2025
-
[11]
Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi
Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Melody Y . Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation.arXiv preprint arXiv:2503.11926, 2025
Pith/arXiv arXiv 2025
-
[12]
Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo
Earl T. Barr, Mark Harman, Phil McMinn, Muzammil Shahbaz, and Shin Yoo. The oracle problem in software testing: A survey.IEEE Transactions on Software Engineering, 41(5):507– 525, 2015
2015
-
[13]
Adversarial reward auditing for active detection and mitigation of reward hacking, 2026
Mohammad Beigi, Ming Jin, Junshan Zhang, Qifan Wang, and Lifu Huang. Adversarial reward auditing for active detection and mitigation of reward hacking, 2026
2026
-
[14]
Terminal wrench: A dataset of 331 reward-hackable environments and 3,632 exploit trajectories, 2026
Ivan Bercovich, Ivgeni Segal, Kexun Zhang, Shashwat Saxena, Aditi Raghunathan, and Ziqian Zhong. Terminal wrench: A dataset of 331 reward-hackable environments and 3,632 exploit trajectories, 2026
2026
-
[15]
Boehm, Chris Abts, A
Barry W. Boehm, Chris Abts, A. Winsor Brown, Sunita Chulani, Bradford K. Clark, Ellis Horowitz, Raymond J. Madachy, Donald J. Reifer, and Bert Steece. Software cost estimation with cocomo ii. 2000
2000
-
[16]
SUPER: evaluating agents on setting up and executing tasks from research repositories
Ben Bogin, Kejuan Yang, Shashank Gupta, Kyle Richardson, Erin Bransom, Peter Clark, Ashish Sabharwal, and Tushar Khot. SUPER: evaluating agents on setting up and executing tasks from research repositories. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, ...
2024
-
[17]
Mle-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. Mle-bench: Evaluating machine learning agents on machine learning engineering. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 2...
2025
-
[18]
FrontierSWE: Benchmarking coding agents at the limits of human abilities
Evan Chu, Rajan Agarwal, Abishek Thangamuthu, Brendan Graham, and Justus Mattern. FrontierSWE: Benchmarking coding agents at the limits of human abilities. Proximal Labs blog post,https://www.frontierswe.com/blog, April 2026. 11
2026
-
[19]
How we rebuilt Next.js with AI in one week
Cloudflare. How we rebuilt Next.js with AI in one week. https://blog.cloudflare.com/ vinext/. Cloudflare Blog
-
[20]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[21]
Zstandard compression and the ‘application/zstd’ media type
Yann Collet and Murray Kucherawy. Zstandard compression and the ‘application/zstd’ media type. Request for Comments 8878, RFC Editor, 2021
2021
-
[22]
Scaling long-running autonomous coding
Cursor. Scaling long-running autonomous coding. https://cursor.com/blog/ scaling-agents. Cursor Blog
-
[23]
Cursor and wilson-anysphere. formula. https://github.com/wilson-anysphere/ formula. GitHub repository
-
[24]
DeepSeek V4 Pro.https://www.deepseek.com, 2026
DeepSeek. DeepSeek V4 Pro.https://www.deepseek.com, 2026
2026
-
[25]
SWE-Bench Pro: Can AI agents solve long-horizon software engineering tasks? Scale AI technical report,https://scale.com/research/swe_bench_pro, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. SWE-Bench Pro: Can AI agents solve long-horizon software engineering tasks? Scale ...
2025
-
[26]
Desai, William J
Rishi M. Desai, William J. R. Longabaugh, and Wayne B. Hayes. BioFabric visualization of network alignments. InRecent Advances in Biological Network Analysis, pages 49–69. Springer, Cham, 2021
2021
-
[27]
Darshan Deshpande, Anand Kannappan, and Rebecca Qian. Benchmarking reward hack detection in code environments via contrastive analysis.arXiv preprint arXiv:2601.20103, 2026
arXiv 2026
-
[28]
Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K. Lahiri. Toga: A neural method for test oracle generation. In2022 IEEE/ACM 44th International Conference on Software Engineering (ICSE), pages 2130–2141, 2022
2022
-
[29]
Sequel: The Database Toolkit for Ruby
Jeremy Evans. Sequel: The Database Toolkit for Ruby. https://sequel.jeremyevans. net/
-
[30]
Gemini CLI.https://github.com/google-gemini/gemini-cli
Google. Gemini CLI.https://github.com/google-gemini/gemini-cli
-
[31]
AlphaFold 3
Google DeepMind. AlphaFold 3. GitHub repository
-
[32]
Gemini 3.1 Pro
Google DeepMind. Gemini 3.1 Pro. https://deepmind.google/technologies/gemini, 2026
2026
-
[33]
Harbor: A framework for evaluating and optimizing agents and models in container environments, January 2026
Harbor Framework Team. Harbor: A framework for evaluating and optimizing agents and models in container environments, January 2026
2026
-
[34]
Testing: a roadmap
Mary Jean Harrold. Testing: a roadmap. InProceedings of the Conference on The Future of Software Engineering, ICSE ’00, page 61–72, New York, NY , USA, 2000. Association for Computing Machinery
2000
-
[35]
LLMs gaming verifiers: RLVR can lead to reward hacking.arXiv preprint arXiv:2604.15149, 2026
Lukas Helff, Quentin Delfosse, David Steinmann, Ruben Härle, Hikaru Shindo, Patrick Schramowski, Wolfgang Stammer, Kristian Kersting, and Felix Friedrich. LLMs gaming verifiers: RLVR can lead to reward hacking.arXiv preprint arXiv:2604.15149, 2026
Pith/arXiv arXiv 2026
-
[36]
Verifying the verifiers: Failure attribution for agentic benchmark diagnostics and training data curation, 2026
Jesse Hu et al. Verifying the verifiers: Failure attribution for agentic benchmark diagnostics and training data curation, 2026. ICLR 2026 LLA Workshop submission
2026
-
[37]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024
2024
-
[38]
autoresearch
Andrej Karpathy. autoresearch. GitHub repository. 12
-
[39]
karpathy/autoresearch
Andrej Karpathy. karpathy/autoresearch. https://github.com/karpathy/autoresearch. GitHub repository
-
[40]
Muhammad Khalifa, Zohaib Khan, Omer Tafveez, Hao Peng, and Lu Wang. Countdown-code: A testbed for studying the emergence and generalization of reward hacking in RLVR.arXiv preprint arXiv:2603.07084, 2026
Pith/arXiv arXiv 2026
-
[41]
Technical debt prioritization: State of the art
Valentina Lenarduzzi, Terese Besker, Davide Taibi, Antonio Martini, and Francesca Arcelli Fontana. Technical debt prioritization: State of the art. a systematic literature review, 2020
2020
-
[42]
William J. R. Longabaugh. Combing the hairball with BioFabric: a new approach for visualiza- tion of large networks.BMC Bioinformatics, 13(275), 2012
2012
-
[43]
Nil Mamano and Wayne B. Hayes. SANA: simulated annealing far outperforms many other search algorithms for biological network alignment.Bioinformatics, 33(14):2156–2164, 2017
2017
-
[44]
Mastodon API documentation.https://docs.joinmastodon.org/api/
Mastodon. Mastodon API documentation.https://docs.joinmastodon.org/api/
-
[45]
Merrill, Alexander G
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
2026
-
[46]
Zstandard: Fast real-time compression algorithm
Meta, Yann Collet, and Zstandard contributors. Zstandard: Fast real-time compression algorithm. GitHub repository
-
[47]
MiniMax M2.7.https://www.minimaxi.com, 2026
MiniMax. MiniMax M2.7.https://www.minimaxi.com, 2026
2026
-
[48]
Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?, 2025
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?, 2025
2025
-
[49]
Modal: Serverless cloud for AI and data.https://modal.com
Modal Labs. Modal: Serverless cloud for AI and data.https://modal.com
-
[50]
Kimi CLI.https://www.moonshot.cn
Moonshot AI. Kimi CLI.https://www.moonshot.cn
-
[51]
Kimi K2.6.https://www.moonshot.cn, 2026
Moonshot AI. Kimi K2.6.https://www.moonshot.cn, 2026
2026
-
[52]
MTEB: Massive text embedding benchmark.https://github.com/embeddings-benchmark/mteb, 2022
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. MTEB: Massive text embedding benchmark.https://github.com/embeddings-benchmark/mteb, 2022
2022
-
[53]
Towards understanding specification gaming in reasoning models.arXiv preprint arXiv:2605.02269, 2026
Kei Nishimura-Gasparian, Robert McCarthy, and David Lindner. Towards understanding specification gaming in reasoning models.arXiv preprint arXiv:2605.02269, 2026
Pith/arXiv arXiv 2026
-
[54]
Codex CLI.https://github.com/openai/codex
OpenAI. Codex CLI.https://github.com/openai/codex
-
[55]
openai/parameter-golf
OpenAI. openai/parameter-golf. https://github.com/openai/parameter-golf. GitHub repository
-
[56]
Introducing SWE-bench Verified
OpenAI. Introducing SWE-bench Verified. https://openai.com/index/ introducing-swe-bench-verified/, August 2024
2024
-
[57]
GPT-5.5.https://openai.com, 2026
OpenAI. GPT-5.5.https://openai.com, 2026. 13
2026
-
[58]
OpenRouter: A unified interface for LLMs.https://openrouter.ai
OpenRouter. OpenRouter: A unified interface for LLMs.https://openrouter.ai
-
[59]
Pendharkar, James A
Parag C. Pendharkar, James A. Rodger, and Girish H. Subramanian. An empirical study of the cobb–douglas production function properties of software development effort.Information and Software Technology, 50(12):1181–1188, 2008
2008
-
[60]
openpi: Open-source robot-learning models
Physical Intelligence. openpi: Open-source robot-learning models. GitHub repository
-
[61]
PostTrainBench: Can LLM agents automate LLM post-training?, 2026
Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, and Maksym Andriushchenko. PostTrainBench: Can LLM agents automate LLM post-training?, 2026
2026
-
[62]
Amit Roth, Ankur Samanta, Matan Halevy, Yoav Levine, and Yonathan Efroni. Hack-verifiable environments: Towards evaluating reward hacking at scale.arXiv preprint arXiv:2605.20744, 2026
Pith/arXiv arXiv 2026
-
[63]
Liquid: Safe, customer-facing template language for flexible web apps
Shopify. Liquid: Safe, customer-facing template language for flexible web apps. https: //shopify.github.io/liquid/
-
[64]
Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan
Zachary S. Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. Core- bench: Fostering the credibility of published research through a computational reproducibility agent benchmark.Trans. Mach. Learn. Res., 2024, 2024
2024
-
[65]
Murphy, and Kris De V older
Jonathan Sillito, Gail C. Murphy, and Kris De V older. Asking and answering questions during a programming change task.IEEE Transactions on Software Engineering, 34(4):434–451, 2008
2008
-
[66]
Sinatra: Classy web-development dressed in a DSL for Ruby
Sinatra contributors. Sinatra: Classy web-development dressed in a DSL for Ruby. https: //sinatrarb.com/
-
[67]
Slack: Where work happens.https://slack.com/
Slack Technologies. Slack: Where work happens.https://slack.com/
-
[68]
Paperbench: Evaluating ai’s ability to replicate AI research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate AI research. InForty- second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada...
2025
-
[69]
Stripe API reference.https://docs.stripe.com/api
Stripe. Stripe API reference.https://docs.stripe.com/api
-
[70]
Minh V . T. Thai, Tue Le, Dung Nguyen Manh, Huy Phan Nhat, and Nghi D. Q. Bui. Swe-evo: Benchmarking coding agents in long-horizon software evolution scenarios, 2025
2025
-
[71]
Reward hacking benchmark: Measuring exploits in LLM agents with tool use,
Kunvar Thaman. Reward hacking benchmark: Measuring exploits in LLM agents with tool use,
-
[72]
Announcing tinker: A flexible API for fine-tuning language models
Thinking Machines. Announcing tinker: A flexible API for fine-tuning language models. Thinking Machines blog post, 2025
2025
-
[73]
Recent frontier models are reward hacking
Sydney V on Arx, Lawrence Chan, and Beth Barnes. Recent frontier models are reward hacking. https://metr.org/blog/2025-06-05-recent-reward-hacking/, June 2025. METR
2025
-
[74]
Odysseybench: Evaluating llm agents on long-horizon complex office application workflows, 2025
Weixuan Wang, Dongge Han, Daniel Madrigal Diaz, Jin Xu, Victor Rühle, and Saravan Rajmohan. Odysseybench: Evaluating llm agents on long-horizon complex office application workflows, 2025
2025
-
[75]
Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, Zhengkang Guo, Qi Qian, Yifei Wang, Feiran Zhang, Ruicheng Yin, Shihan Dou, Changze Lv, Tao Chen, Kaitao Song, Xu Tan, Tao Gui, Xiaoqing Zheng, and Xuanjing Huang. Reward hacking in the era of large models: Mechanisms, emergent misal...
Pith/arXiv arXiv 2026
-
[76]
WebAssembly SIMD proposal
WebAssembly Community Group. WebAssembly SIMD proposal. https://github.com/ WebAssembly/simd. 14
-
[77]
Re-bench: Evaluating frontier AI r&d capabilities of language model agents against human experts
Hjalmar Wijk, Tao Roa Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Joshua Clymer, Jai Dhyani, Elena Ericheva, Katharyn Gar- cia, Brian Goodrich, Nikola Jurkovic, Megan Kinniment, Aron Lajko, Seraphina Nix, Lucas Jun Koba Sato, William Saunders, Maksym Taran, Ben West, and Elizabeth Barnes. Re-bench: Evaluating ...
2025
-
[78]
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Zhiruo Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Keunho Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. Theagentcompany: Benchmarking LLM agents on consequential real world t...
Pith/arXiv arXiv 2024
-
[79]
SWE-smith: Scaling data for software engineering agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. SWE-smith: Scaling data for software engineering agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[80]
Learning to discover at test time.arXiv preprint, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time.arXiv preprint, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.