Feature-Optimized Vision for Adaptive 3D Scene Reconstruction
Pith reviewed 2026-06-28 22:50 UTC · model grok-4.3
The pith
Adaptive feature scoring and budget allocation improves 3D reconstruction quality over fixed baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
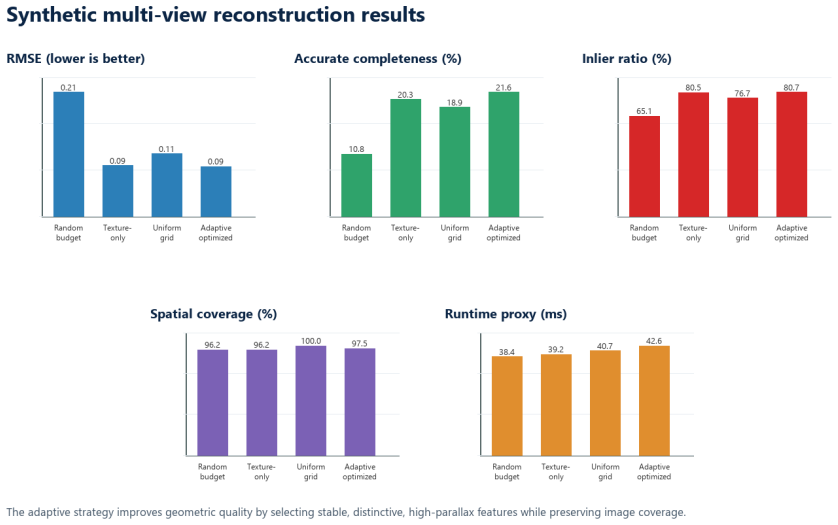
The paper establishes that scoring candidate features by five criteria and allocating per-view budgets adaptively produces the best quality-aware completeness and lowest aggregate reconstruction RMSE across corridor, facade, object-table, and cluttered scenes when compared to random, texture-only, and uniform-grid baselines.
What carries the argument
A scoring and per-view budget allocation policy that selects features to maximize useful tracks under a fixed reconstruction pipeline.
If this is right
- Quality-aware completeness is highest with the adaptive policy.
- Aggregate reconstruction RMSE is lowest with the adaptive policy.
- Broad image coverage is preserved.
- The policy works as a modular front-end for classical and learned pipelines.
Where Pith is reading between the lines
- Such adaptive selection could reduce wasted computation on unhelpful features in practical applications.
- Combining this with modern learned matchers might yield even stronger results by prioritizing geometrically useful matches.
- Validation on real-world captured data would be needed to confirm the benefits hold outside synthetic prototypes.
Load-bearing premise
That scoring features on the five given criteria and allocating budgets per view will lead to better tracks in a fixed pipeline on the four synthetic scenes.
What would settle it
If experiments on the four scenes with the fixed pipeline show no improvement in RMSE or completeness for the adaptive policy over the uniform-grid baseline, the claim would fail.
Figures

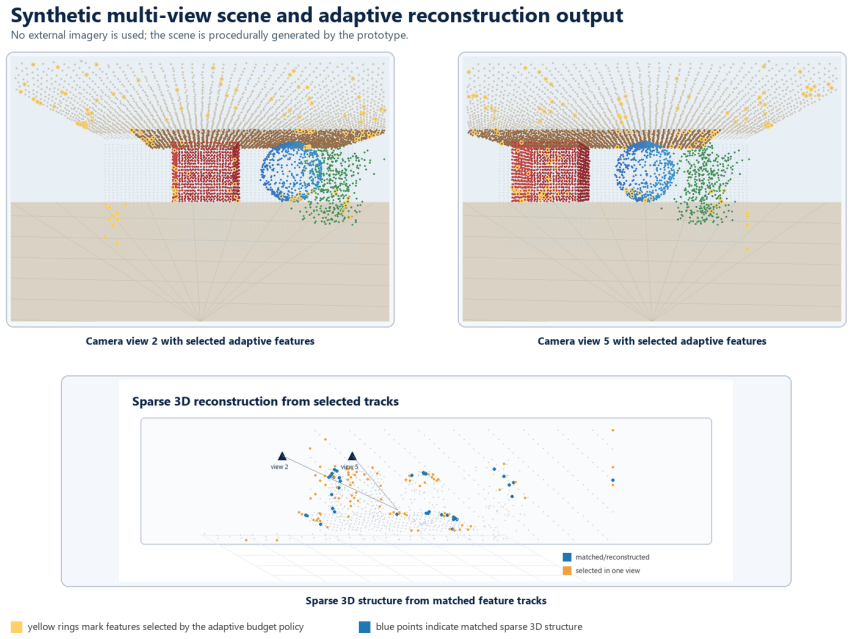
read the original abstract
Three-dimensional scene reconstruction depends on local image evidence that is both visually discriminative and geometrically useful. Fixed feature thresholds and uniform feature budgets are easy to deploy, but they can waste computation on repeated texture, low-parallax regions, or unstable points. This paper proposes an adaptive feature-optimized vision front end for 3D reconstruction. The method scores candidate features by texture, repeatability, distinctiveness, expected triangulation angle, and spatial coverage, then allocates a per-view feature budget to maximize useful tracks under a fixed reconstruction pipeline. A small synthetic multi-view prototype evaluates four selection policies across corridor, facade, object-table, and cluttered scenes. Compared with random, texture-only, and uniform-grid baselines, the adaptive policy obtains the best quality-aware completeness and the lowest aggregate reconstruction RMSE while preserving broad image coverage. The result is not a replacement for modern learned matching or neural reconstruction systems; it is a modular front-end policy that can make classical and learned 3D pipelines more deliberate about which visual evidence they spend compute on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an adaptive feature-optimized vision front-end for 3D scene reconstruction. Candidate features are scored by five criteria (texture, repeatability, distinctiveness, expected triangulation angle, spatial coverage) and a per-view feature budget is allocated to maximize useful tracks under a fixed reconstruction pipeline. A small synthetic multi-view prototype evaluates four selection policies on corridor, facade, object-table, and cluttered scenes; the adaptive policy is reported to achieve the best quality-aware completeness and lowest aggregate reconstruction RMSE while preserving broad image coverage. The method is positioned as a modular front-end compatible with classical or learned pipelines rather than a replacement.
Significance. If the reported gains on the four synthetic prototypes hold under the stated conditions, the work provides a concrete, criterion-driven policy for deliberate feature selection that could reduce wasted computation on low-utility regions in existing reconstruction systems. The modular framing is a strength, as it does not require changes to downstream matching or optimization. However, confinement to synthetic data and a single fixed pipeline means the result, even if internally consistent, offers limited evidence for broader impact or robustness.
major comments (2)
- [Evaluation (synthetic prototype)] The central empirical claim (adaptive policy superiority in completeness and RMSE) rests on evaluation across only four small synthetic prototypes with one fixed reconstruction pipeline and no reported variation in the matcher, optimizer, or scene statistics. This setup leaves open the possibility that observed differences are artifacts of the prototype set rather than intrinsic to the five-criterion scoring and budget allocation; the manuscript should either expand the test regime or explicitly bound the claim to the reported synthetic conditions.
- No equations, implementation details for the five scoring functions, per-view budget allocation procedure, or quantitative results (including error bars or per-scene breakdowns) appear in the abstract or summary description, preventing verification that the reported RMSE and completeness improvements are statistically meaningful or free of implementation-specific biases.
minor comments (2)
- Clarify whether the five criteria are combined via a fixed weighted sum or learned weights, and state the exact form of the budget allocation objective.
- The abstract states that the adaptive policy 'preserves broad image coverage'; a supporting figure or table quantifying coverage (e.g., fraction of image area with selected features) would strengthen this assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Evaluation (synthetic prototype)] The central empirical claim (adaptive policy superiority in completeness and RMSE) rests on evaluation across only four small synthetic prototypes with one fixed reconstruction pipeline and no reported variation in the matcher, optimizer, or scene statistics. This setup leaves open the possibility that observed differences are artifacts of the prototype set rather than intrinsic to the five-criterion scoring and budget allocation; the manuscript should either expand the test regime or explicitly bound the claim to the reported synthetic conditions.
Authors: The manuscript already frames the work explicitly as a 'small synthetic multi-view prototype' and scopes all empirical claims to the four reported scenes under a single fixed pipeline. We have revised the abstract, introduction, and conclusion to state this bounding more prominently and to avoid any implication of broader generality. Expanding the evaluation to additional pipelines, real-world data, or scene statistics is outside the intended scope of this prototype study. revision: partial
-
Referee: [—] No equations, implementation details for the five scoring functions, per-view budget allocation procedure, or quantitative results (including error bars or per-scene breakdowns) appear in the abstract or summary description, preventing verification that the reported RMSE and completeness improvements are statistically meaningful or free of implementation-specific biases.
Authors: The abstract is a high-level summary and is not intended to contain equations or detailed results; these appear in the methods and results sections of the full manuscript. We have revised the results section to include error bars on all reported metrics, explicit per-scene numerical breakdowns, and a brief statement on the statistical comparison between policies. revision: yes
Circularity Check
No circularity: empirical policy evaluation on held-out scenes
full rationale
The paper defines an explicit five-criterion scoring function and a per-view budget allocator, then reports direct empirical comparisons against random, texture-only, and uniform-grid baselines on four synthetic prototype scenes. No equations, fitted parameters, or predictions are shown that reduce by construction to the inputs; the evaluation uses held-out scenes and a fixed downstream pipeline. No self-citations appear as load-bearing uniqueness theorems or ansatzes. The derivation chain is therefore self-contained as a modular heuristic evaluated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, "Distinctive image features from scale-invariant keypoints," International Journal of Computer Vision, vol. 60, no. 2, pp. 91-110, 2004. doi:10.1023/B:VISI.0000029664.99615.94
-
[2]
M. A. Fischler and R. C. Bolles, "Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography," Communications of the ACM, vol. 24, no. 6, pp. 381-395, 1981. doi:10.1145/358669.358692
-
[3]
Machine learning for high-speed corner detection,
E. Rosten and T. Drummond, "Machine learning for high-speed corner detection," in ECCV 2006, LNCS 3951, pp. 430-443, 2006. doi:10.1007/11744023_34
-
[4]
ORB: An efficient alternative to SIFT or SURF,
E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, "ORB: An efficient alternative to SIFT or SURF," in ICCV 2011, pp. 2564-2571. doi:10.1109/ICCV.2011.6126544
-
[5]
Hartley and A
R. Hartley and A. Zisserman, Multiple View Geometry in Computer Vision, 2nd ed. Cambridge University Press, 2004
2004
-
[6]
Structure-from-Motion Revisited,
J. L. Schonberger and J.-M. Frahm, "Structure-from-motion revisited," in CVPR 2016, pp. 4104-4113. doi:10.1109/CVPR.2016.445
-
[7]
Multi-view stereo: A tutorial,
Y. Furukawa and C. Hernandez, "Multi-view stereo: A tutorial," Foundations and Trends in Computer Graphics and Vision, vol. 9, no. 1-2, pp. 1-148, 2015. doi:10.1561/0600000052
-
[8]
SuperPoint: Self-supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, "SuperPoint: Self-supervised interest point detection and description," in CVPR Workshops, 2018
2018
-
[9]
R2D2: Repeatable and reliable detector and descriptor,
J. Revaud, P. Weinzaepfel, C. De Souza, N. Pion, G. Csurka, Y. Cabon, and M. Humenberger, "R2D2: Repeatable and reliable detector and descriptor," in NeurIPS, 2019. 8
2019
-
[10]
Tailornet: Predict- ing clothing in 3d as a function of human pose, shape and garment style
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, "SuperGlue: Learning feature matching with graph neural networks," in CVPR 2020, pp. 4938-4947. doi:10.1109/CVPR42600.2020.00499
-
[11]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
J. Sun, Z. Shen, Y. Wang, H. Bao, and X. Zhou, "LoFTR: Detector-free local feature matching with transformers," in CVPR 2021, pp. 8922-8931. doi:10.1109/CVPR46437.2021.00881
-
[12]
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, "LightGlue: Local feature matching at light speed," in ICCV 2023, pp. 17581-17592. doi:10.1109/ICCV51070.2023.01616
-
[13]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, "NeRF: Representing scenes as neural radiance fields for view synthesis," in ECCV 2020, LNCS 12346, pp. 405-421. doi:10.1007/978-3-030-58452-8_24
-
[14]
3D Gaussian Splatting for Real -Time Radiance Field Rendering,
B. Kerbl, G. Kopanas, T. Leimkuhler, and G. Drettakis, "3D Gaussian Splatting for real-time radiance field rendering," ACM Transactions on Graphics, vol. 42, no. 4, 2023. doi:10.1145/3592433
-
[15]
DUSt3R: Geometric 3D vision made easy,
S. Wang et al., "DUSt3R: Geometric 3D vision made easy," in CVPR 2024, pp. 20697-20709
2024
-
[16]
Grounding image matching in 3d with mast3r
V. Leroy et al., "Grounding image matching in 3D with MASt3R," arXiv:2406.09756, 2024
-
[17]
Efficient representations for high-cardinality categorical variables in machine learning,
Z. Liang, "Efficient representations for high-cardinality categorical variables in machine learning," in 2025 International Conference on Advanced Machine Learning and Data Science (AMLDS), pp. 1-11. IEEE, 2025
2025
-
[18]
Harmonizing metadata of language resources for enhanced querying and accessibility,
Z. Liang, "Harmonizing metadata of language resources for enhanced querying and accessibility," in 2024 5th International Conference on Computers and Artificial Intelligence Technology (CAIT), pp. 642-650. IEEE, 2024
2024
-
[19]
Enhanced estimation techniques for certified radii in randomized smoothing,
Z. Liang, "Enhanced estimation techniques for certified radii in randomized smoothing," in 2025 8th International Conference on Artificial Intelligence and Big Data (ICAIBD), pp. 375-384. IEEE, 2025
2025
-
[20]
Automating date format detection for data visualization,
Z. Liang, "Automating date format detection for data visualization," in 2025 International Conference on Advanced Machine Learning and Data Science (AMLDS), pp. 756-764. IEEE, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.