LWDrive: Layer-Wise World-Model-Guided Vision-Language Model Planning for Autonomous Driving
Pith reviewed 2026-06-30 06:32 UTC · model grok-4.3
The pith
Layer-wise world-model guidance refines coarse VLM trajectories into accurate driving plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
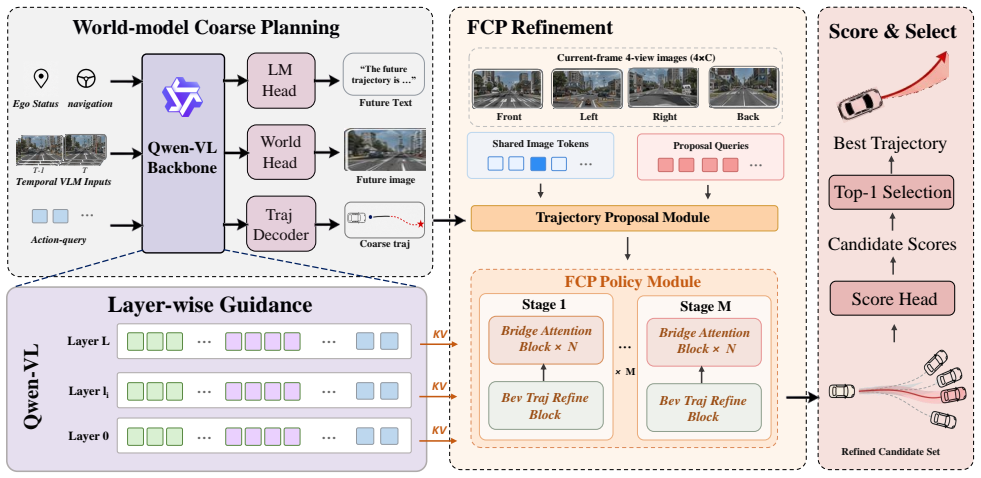
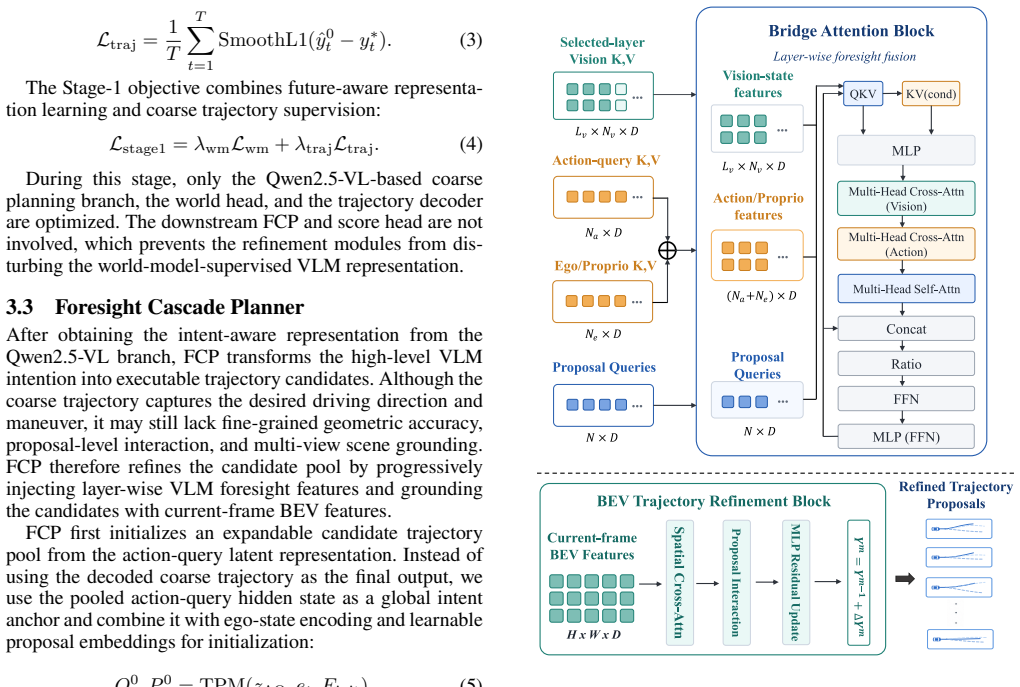
LWDrive treats the VLM output only as an intent-aware coarse plan, expands a diverse candidate space around it, and progressively refines the candidates through a Foresight Cascade Planner. Future-frame generation supervision injects planning-relevant predictive dynamics into the VLM's internal hidden states. The planner exploits VLM features across multiple layers, integrates historical temporal states, Action-Query representations, and current-frame multi-view BEV features to refine trajectories in a coarse-to-fine manner, enabling correction of spatial positions and motion trends while preserving the high-level driving intention. A score head then selects the best refined trajectory as th
What carries the argument
Foresight Cascade Planner (FCP), which exploits multi-layer VLM features under world-model supervision to refine trajectory candidates in a coarse-to-fine sequence.
If this is right
- Refined trajectories correct spatial positions and motion trends while preserving high-level driving intention from the VLM.
- Trajectory refinement is grounded with multi-view scene cues from BEV features.
- A score head evaluates refined candidates and selects the final planning output.
- The framework achieves 92.0 on the NAVSIM benchmark and 89.6 on NAVSIM-v2.
Where Pith is reading between the lines
- The same supervision-plus-cascade pattern could be tested on VLM planners for other robotic tasks such as manipulation or navigation.
- If the layer-wise refinement proves stable, it may reduce the need for separate geometric post-processors in VLM-based systems.
- Success would suggest that predictive world-model signals can be injected into existing VLMs without changing their core architecture.
Load-bearing premise
Future-frame generation supervision successfully injects planning-relevant predictive dynamics into the VLM hidden states and the cascade planner can refine candidates without introducing new spatial or motion errors.
What would settle it
If ablation experiments that remove future-frame supervision or the multi-layer cascade refinement produce equal or lower NAVSIM scores than the full model, the claim that layer-wise world-model guidance improves planning accuracy would be falsified.
Figures


read the original abstract
Vision-Language Models (VLMs) provide powerful semantic understanding and commonsense reasoning for End-to-End Autonomous Driving (E2E-AD) planning. However, trajectories directly generated by VLMs often encode only coarse driving intentions and remain insufficient for geometrically accurate, future-aware, and multi-view-grounded planning. To address these limitations, we develop the Layer-Wise World-Model-Guided Driving framework (LWDrive). LWDrive is a VLM planning framework that refines coarse trajectories through layer-wise world-model guidance. Instead of treating the VLM output as the final trajectory, LWDrive uses it as an intent-aware coarse plan, expands a diverse candidate space around it, and progressively refines the candidates through a Foresight Cascade Planner (FCP). Specifically, we introduce future-frame generation supervision to encourage the VLM to learn forward-looking scene representations, thereby injecting planning-relevant predictive dynamics into its internal hidden states. Built upon these world-model-supervised representations, FCP exploits VLM features across multiple layers and integrates historical temporal states, Action-Query representations, and current-frame multi-view Bird's-Eye-View (BEV) features to refine candidate trajectories in a coarse-to-fine manner. This design enables progressive correction of spatial positions and motion trends while grounding trajectory refinement with multi-view scene cues and preserving the high-level driving intention produced by the large model. Finally, a score head evaluates the refined candidates and selects the best trajectory as the final planning output. Experiments show that LWDrive achieves a score of 92.0 on the NAVSIM benchmark and 89.6 on NAVSIM-v2. Code and models will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LWDrive, a VLM-based framework for end-to-end autonomous driving planning. It treats VLM outputs as coarse intent-aware trajectories, applies future-frame generation supervision to inject predictive dynamics into hidden states, and uses a Foresight Cascade Planner (FCP) to progressively refine candidate trajectories in a coarse-to-fine manner by combining multi-layer VLM features with historical states, Action-Query representations, and multi-view BEV features. A score head then selects the final trajectory. Experiments report scores of 92.0 on NAVSIM and 89.6 on NAVSIM-v2.
Significance. If the central mechanism is validated, the work could meaningfully advance E2E-AD by showing how to retain VLM commonsense reasoning while achieving geometric and motion accuracy through world-model-guided refinement. The layer-wise cascade design and future-frame supervision are potentially generalizable ideas, but the absence of supporting analyses for representation quality limits the assessed impact.
major comments (2)
- [Abstract] Abstract: The reported scores of 92.0 (NAVSIM) and 89.6 (NAVSIM-v2) are presented without any baseline comparisons, ablation results, error bars, dataset statistics, or statistical significance tests, making it impossible to determine whether the gains are attributable to the proposed layer-wise world-model guidance or to other factors.
- [Abstract] Abstract (and method overview): No evidence is supplied that future-frame generation supervision causes VLM hidden states to encode planning-relevant predictive dynamics rather than purely semantic features. Without probing, representation similarity metrics, or controlled ablations isolating this supervision effect, the claim that FCP can reliably refine trajectories without introducing new spatial or motion errors rests on an unverified assumption.
minor comments (2)
- The description of candidate expansion around the coarse plan and the exact architecture of the score head should be expanded with pseudocode or a diagram for reproducibility.
- Clarify the precise integration of Action-Query representations within the FCP cascade and whether any additional learned parameters are introduced beyond the VLM backbone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas where the abstract and supporting analyses can be strengthened to better substantiate the claims. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported scores of 92.0 (NAVSIM) and 89.6 (NAVSIM-v2) are presented without any baseline comparisons, ablation results, error bars, dataset statistics, or statistical significance tests, making it impossible to determine whether the gains are attributable to the proposed layer-wise world-model guidance or to other factors.
Authors: We agree that the abstract would benefit from additional context. The full manuscript includes baseline comparisons in the experiments section showing improvements over prior methods, along with ablations. In the revision, we will update the abstract to reference key baseline scores and the magnitude of gains, and ensure the main text explicitly includes error bars, dataset statistics, and significance tests to demonstrate attribution to the proposed components. revision: yes
-
Referee: [Abstract] Abstract (and method overview): No evidence is supplied that future-frame generation supervision causes VLM hidden states to encode planning-relevant predictive dynamics rather than purely semantic features. Without probing, representation similarity metrics, or controlled ablations isolating this supervision effect, the claim that FCP can reliably refine trajectories without introducing new spatial or motion errors rests on an unverified assumption.
Authors: We acknowledge that the current version lacks direct empirical validation such as probing or isolated ablations for the supervision effect. In the revised manuscript, we will add controlled ablations that isolate the future-frame generation supervision, along with representation similarity metrics or probing results where feasible, to confirm that the hidden states encode planning-relevant predictive dynamics and support the FCP refinement claims. revision: yes
Circularity Check
No circularity: additive pipeline with external supervision and refinement steps
full rationale
The paper proposes an architectural pipeline (VLM coarse plan + future-frame supervision + FCP refinement using multi-layer features) whose final output is not shown by any equation or self-citation to be definitionally equivalent to its training inputs. The future-frame loss is an external supervision signal whose effect on hidden-state geometry is an empirical claim, not a tautology. No fitted parameter is renamed as a prediction, no uniqueness theorem is imported from the authors' prior work, and the reported NAVSIM scores are benchmark measurements rather than quantities forced by internal definitions. The derivation chain therefore remains self-contained against external evaluation.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.