Robust Koopman Control Barrier Filters for Safe Actor-Critic Reinforcement Learning
Pith reviewed 2026-06-29 17:39 UTC · model grok-4.3
The pith
Robust Koopman-CBF filters let actor-critic RL achieve zero constraint violations on CartPole while matching SAC returns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
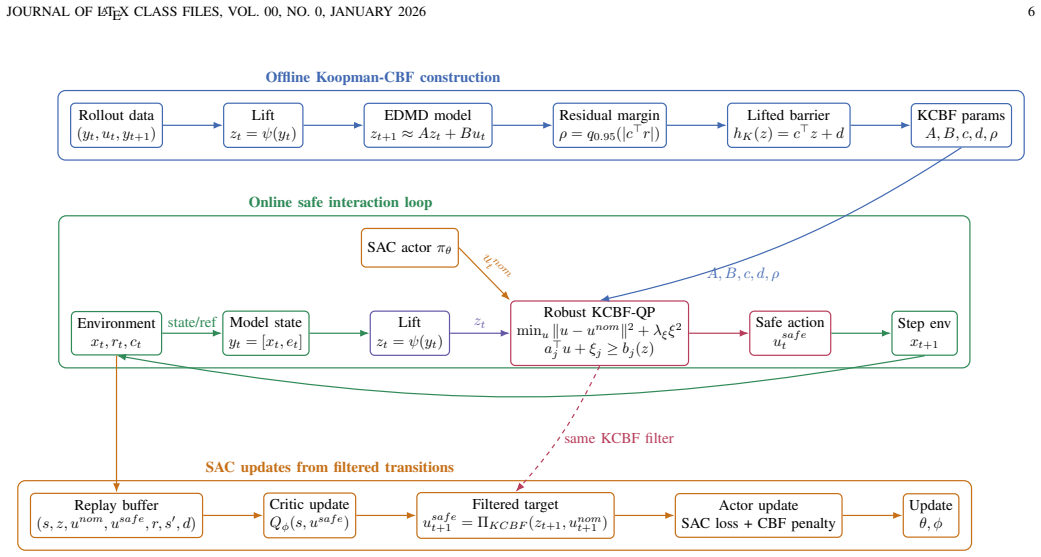
Robust Koopman-CBF SAC learns a finite-dimensional Koopman predictor from data, constructs affine CBF constraints in the lifted space, and enforces them through a quadratic-program safety layer whose condition is tightened by a projected residual margin estimated from held-out rollouts; the critic trains on executed safe actions and the actor is regularized toward the feasible set.
What carries the argument
The robust Koopman control barrier filter: a data-learned linear model in lifted coordinates whose approximation error is bounded by a projected residual margin to produce a conservative affine CBF constraint enforced by quadratic programming.
If this is right
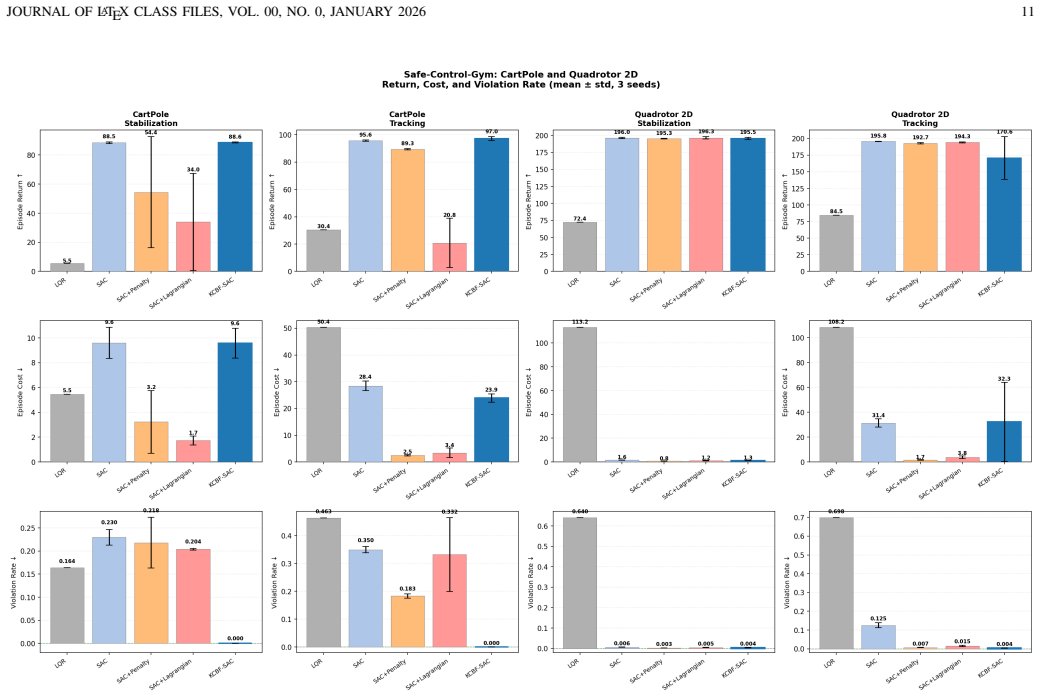
- Zero constraint violations occur on CartPole stabilization and tracking while matching or exceeding unconstrained SAC returns.
- The critic trains on the executed safe action and the actor is regularized toward the Koopman-CBF feasible set, reducing dependence on the filter over training.
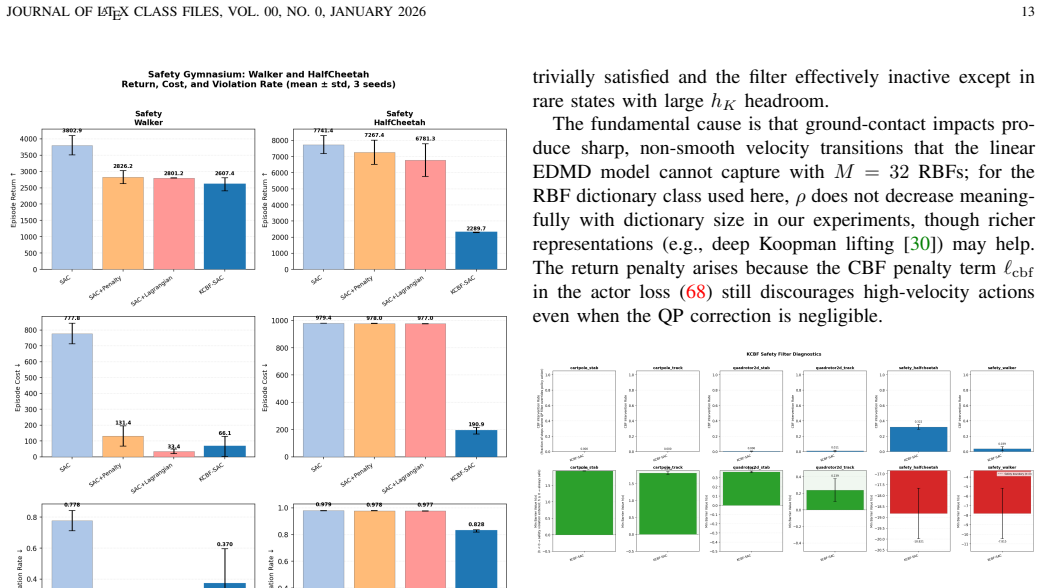
- Violations are reduced in some high-dimensional Safety Gymnasium locomotion tasks.
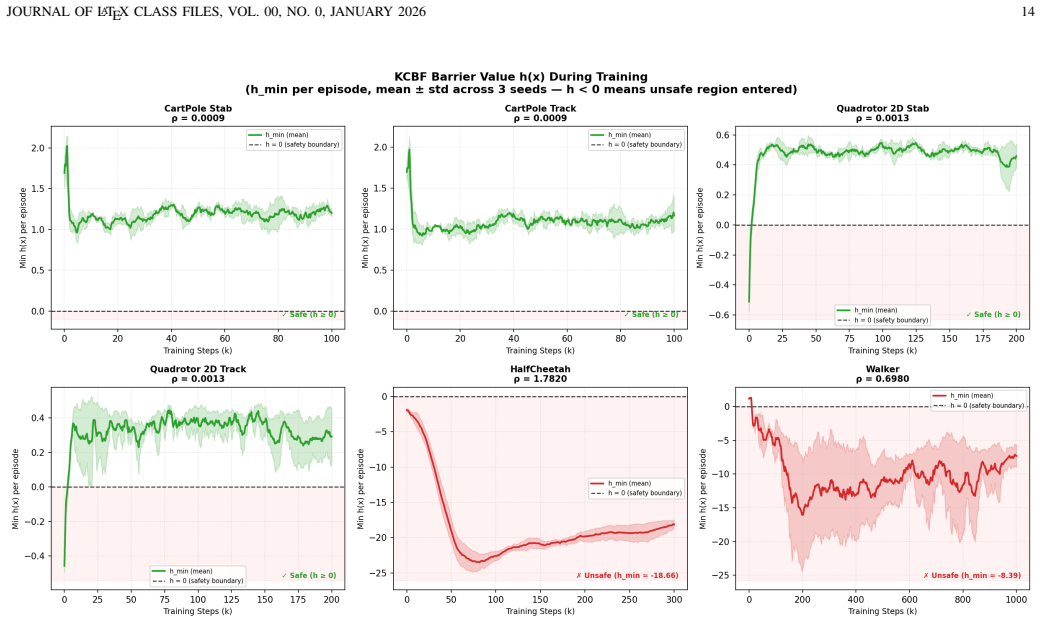
- The results identify limits of first-order velocity barriers and linear EDMD models, motivating high-order and multi-step extensions.
Where Pith is reading between the lines
- The same residual-margin tightening could be applied to other learned dynamics models if comparable held-out error statistics can be collected.
- Physical-robot tests would show whether the margin computed from simulation rollouts remains valid under sensor noise and unmodeled effects.
- Regularizing the actor toward the safe set may improve sample efficiency in other constrained RL problems beyond the benchmarks shown.
Load-bearing premise
The finite-dimensional Koopman approximation error can be adequately bounded by a projected residual margin estimated from held-out rollout data, allowing the tightened CBF condition to guarantee forward invariance.
What would settle it
Trajectories on which the actual one-step prediction error exceeds the estimated residual margin and constraint violations occur despite the quadratic-program filter.
Figures
read the original abstract
Safe reinforcement learning (RL) for robotic systems requires policies that improve task performance while satisfying state and input constraints during both training and deployment. Control barrier functions (CBFs) provide a principled mechanism for enforcing forward invariance through minimally invasive safety filters, but their use in model-free RL is limited by the need for accurate dynamics and hand-designed barrier certificates. We propose Robust Koopman-CBF SAC, a safety-filtered actor--critic framework that learns a finite-dimensional Koopman predictor from data, constructs affine CBF constraints in the lifted space, and enforces them through a quadratic-program safety layer. To account for finite-dimensional Koopman approximation error, the CBF condition is tightened using a projected residual margin estimated from held-out rollout data. The critic is trained on the executed safe action, while the actor is regularized toward the Koopman-CBF feasible set, reducing dependence on the filter over training. Across safe-control benchmarks, the method achieves zero constraint violations on CartPole stabilization and tracking while matching or exceeding unconstrained SAC returns. On high-dimensional Safety Gymnasium locomotion tasks, the method reduces violations in some settings but also exposes important limitations of first-order velocity barriers and linear EDMD models, motivating high-order and multi-step Koopman-CBF extensions. These results suggest that robust Koopman-CBF filters are a promising bridge between model-free RL and certifiable safety, while clarifying the structural conditions under which such filters remain effective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Robust Koopman-CBF SAC, a safe actor-critic RL framework that learns a finite-dimensional Koopman predictor from data, constructs affine CBF constraints in the lifted space, and enforces them via a QP safety filter. To handle finite-dimensional approximation error, the CBF condition is tightened by a projected residual margin estimated from held-out rollout data. The critic trains on executed safe actions while the actor is regularized toward the Koopman-CBF feasible set. Empirical results claim zero constraint violations on CartPole stabilization and tracking (matching or exceeding SAC returns) and reduced violations on some Safety Gymnasium locomotion tasks, while noting limitations of linear EDMD models and first-order velocity barriers.
Significance. If the projected residual margin rigorously upper-bounds the Koopman error for all states visited by the learned policy, the method would provide a practical, data-driven bridge between model-free RL and certifiable safety without requiring hand-designed barriers or accurate analytic dynamics. The explicit acknowledgment of limitations on high-dimensional tasks and the call for high-order/multi-step extensions are strengths. The empirical zero-violation results on CartPole constitute a concrete, falsifiable outcome that can be directly reproduced.
major comments (2)
- [Abstract] Abstract: the claim that the tightened CBF condition guarantees forward invariance (and thus zero violations on CartPole) rests on the projected residual margin dominating the true approximation error ||f(x,u) - K Φ(x,u)|| for every state-action pair visited by the policy, yet the manuscript supplies neither a concentration inequality, worst-case bound, nor coverage argument justifying that the single held-out estimate suffices under distribution shift between the held-out set and the actor's evolving distribution.
- [Abstract] Abstract: the robustness margin is estimated from held-out rollout data and then inserted into the CBF condition while the actor is simultaneously regularized toward the same learned feasible set; this creates a circular dependence in which safety performance is evaluated with respect to quantities fitted inside the training loop, without an independent verification that the margin remains valid for the final policy.
minor comments (1)
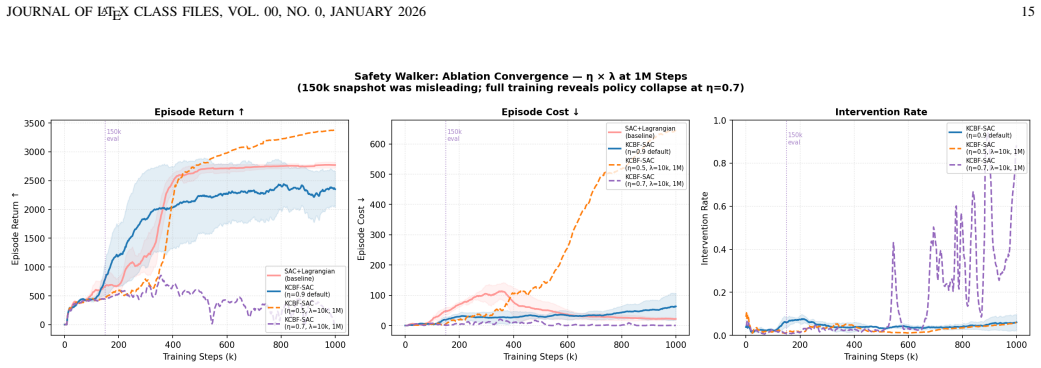
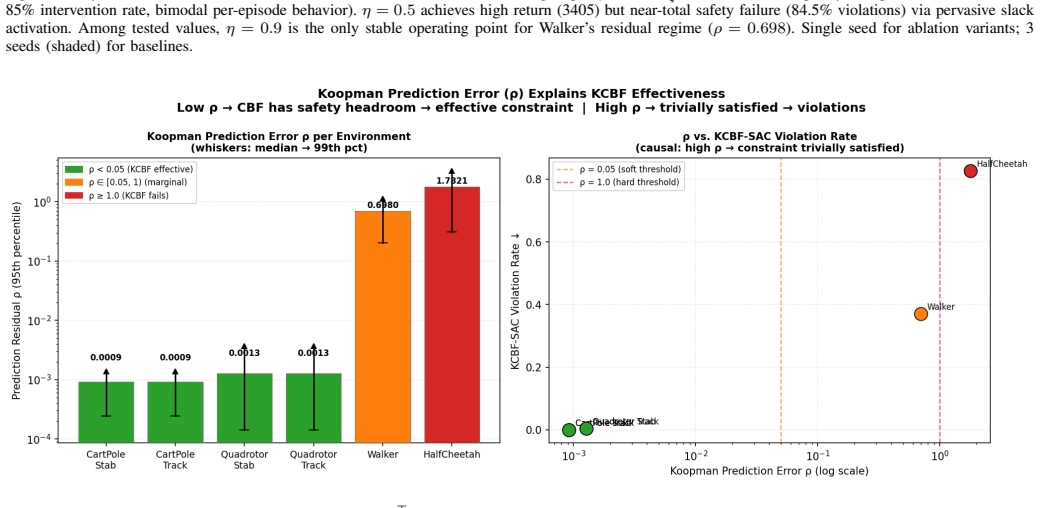
- [Abstract] The abstract states that the method 'exposes important limitations of first-order velocity barriers and linear EDMD models' but does not quantify how these limitations manifest in the reported Safety Gymnasium results (e.g., which tasks still exhibit violations and by how much).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, proposing targeted revisions to the abstract to ensure claims are precisely aligned with the empirical nature of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the tightened CBF condition guarantees forward invariance (and thus zero violations on CartPole) rests on the projected residual margin dominating the true approximation error ||f(x,u) - K Φ(x,u)|| for every state-action pair visited by the policy, yet the manuscript supplies neither a concentration inequality, worst-case bound, nor coverage argument justifying that the single held-out estimate suffices under distribution shift between the held-out set and the actor's evolving distribution.
Authors: The abstract reports observed empirical results of zero constraint violations on CartPole; it does not assert a formal guarantee of forward invariance. The manuscript explicitly notes limitations of linear EDMD models and first-order barriers, and the results are presented as empirical evidence rather than a certified bound. We will revise the abstract to state explicitly that zero violations are empirical observations on the evaluated tasks and that the margin provides practical robustness without a concentration inequality or coverage argument for all distribution shifts. revision: yes
-
Referee: [Abstract] Abstract: the robustness margin is estimated from held-out rollout data and then inserted into the CBF condition while the actor is simultaneously regularized toward the same learned feasible set; this creates a circular dependence in which safety performance is evaluated with respect to quantities fitted inside the training loop, without an independent verification that the margin remains valid for the final policy.
Authors: The margin is computed once from a fixed held-out dataset collected separately from the final policy training. The actor regularization encourages feasible actions but does not alter the fixed margin used in the safety filter. We acknowledge that distribution shift between the held-out set and the converged policy could affect validity, consistent with the paper's discussion of limitations on high-dimensional tasks. We will add a clarifying sentence in the abstract noting that the margin is precomputed from held-out data and that its effectiveness for the final policy is supported by the reported empirical outcomes. revision: partial
Circularity Check
Safety guarantee reduces to fitted residual margin inserted into CBF; zero-violation claim is data-dependent by construction.
specific steps
-
fitted input called prediction
[Abstract]
"To account for finite-dimensional Koopman approximation error, the CBF condition is tightened using a projected residual margin estimated from held-out rollout data."
The margin is obtained by fitting to held-out trajectories; this same scalar is then inserted into the CBF inequality that the safety filter enforces. Consequently the claim of zero constraint violations is produced by construction once the margin value is chosen from the data, rather than being an independent prediction of the method.
-
fitted input called prediction
[Abstract]
"The critic is trained on the executed safe action, while the actor is regularized toward the Koopman-CBF feasible set, reducing dependence on the filter over training."
The feasible set used for actor regularization is defined by the identical tightened CBF that incorporates the data-estimated margin; the regularization target is therefore not an external reference but a quantity derived inside the training loop from the same held-out residuals.
full rationale
The central safety mechanism tightens the CBF constraint with a margin computed from held-out rollouts; the reported zero violations on CartPole and reduced violations on Safety Gym are therefore produced by applying a filter whose tightening parameter was itself derived from the same data distribution. No independent bound or coverage argument is supplied, so the performance metric is statistically forced by the fitted input rather than derived from first principles. This matches the fitted-input-called-prediction pattern and justifies a moderate circularity score; the remainder of the Koopman lifting and QP filter construction is independent.
Axiom & Free-Parameter Ledger
free parameters (1)
- projected residual margin
axioms (1)
- domain assumption Finite-dimensional Koopman approximation error can be bounded by a data-estimated margin sufficient to preserve forward invariance
Reference graph
Works this paper leans on
-
[1]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, no. 1, pp. 411–444, 2022
2022
-
[2]
A Review On Safe Reinforcement Learning Using Lyapunov and Barrier Functions
D. S. Kushwaha and Z. A. Biron, “A review on safe reinforce- ment learning using lyapunov and barrier functions,”arXiv preprint arXiv:2508.09128, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inInternational conference on machine learning. Pmlr, 2017, pp. 22–31
2017
-
[4]
Control barrier function based quadratic programs for safety critical systems,
A. D. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,”IEEE Transactions on Automatic Control, vol. 62, no. 8, pp. 3861–3876, 2016
2016
-
[5]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” in2019 18th European control conference (ECC). Ieee, 2019, pp. 3420–3431
2019
-
[6]
A data–driven approximation of the koopman operator: Extending dynamic mode decomposition,
M. O. Williams, I. G. Kevrekidis, and C. W. Rowley, “A data–driven approximation of the koopman operator: Extending dynamic mode decomposition,”Journal of Nonlinear Science, vol. 25, no. 6, pp. 1307– 1346, 2015
2015
-
[7]
Linear predictors for nonlinear dynamical sys- tems: Koopman operator meets model predictive control,
M. Korda and I. Mezi ´c, “Linear predictors for nonlinear dynamical sys- tems: Koopman operator meets model predictive control,”Automatica, vol. 93, pp. 149–160, 2018
2018
-
[8]
Data-driven safety-critical control: Synthesizing control barrier functions with koop- man operators,
C. Folkestad, Y . Chen, A. D. Ames, and J. W. Burdick, “Data-driven safety-critical control: Synthesizing control barrier functions with koop- man operators,”IEEE Control Systems Letters, vol. 5, no. 6, pp. 2012– 2017, 2020
2012
-
[9]
Neural koopman control barrier functions for safety-critical control of unknown nonlinear systems,
V . Zinage and E. Bakolas, “Neural koopman control barrier functions for safety-critical control of unknown nonlinear systems,” in2023 American Control Conference (ACC). IEEE, 2023, pp. 3442–3447
2023
-
[10]
Safe-control-gym: A unified benchmark suite for safe learning-based control and reinforcement learning in robotics,
Z. Yuan, A. W. Hall, S. Zhou, L. Brunke, M. Greeff, J. Panerati, and A. P. Schoellig, “Safe-control-gym: A unified benchmark suite for safe learning-based control and reinforcement learning in robotics,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 11 142–11 149, 2022
2022
-
[11]
Safety gymnasium: A unified safe reinforcement learning benchmark,
J. Ji, B. Zhang, J. Zhou, X. Pan, W. Huang, R. Sun, Y . Geng, Y . Zhong, J. Dai, and Y . Yang, “Safety gymnasium: A unified safe reinforcement learning benchmark,”Advances in Neural Information Processing Systems, vol. 36, pp. 18 964–18 993, 2023
2023
-
[12]
Recovery rl: Safe reinforcement learning with learned recovery zones,
B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, and K. Goldberg, “Recovery rl: Safe reinforcement learning with learned recovery zones,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4915–4922, 2021
2021
-
[13]
Robustness of control barrier functions for safety critical control,
X. Xu, P. Tabuada, J. W. Grizzle, and A. D. Ames, “Robustness of control barrier functions for safety critical control,”IFAC-PapersOnLine, vol. 48, no. 27, pp. 54–61, 2015
2015
-
[14]
End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,
R. Cheng, G. Orosz, R. M. Murray, and J. W. Burdick, “End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 3387–3395
2019
-
[15]
Learning control barrier functions and their application in reinforcement learning: A survey,
M. Guerrier, H. Fouad, and G. Beltrame, “Learning control barrier functions and their application in reinforcement learning: A survey,” arXiv preprint arXiv:2404.16879, 2024
-
[16]
Extended dynamic mode decomposition with dictionary learning: A data-driven adaptive spectral decomposition of the koopman operator,
Q. Li, F. Dietrich, E. M. Bollt, and I. G. Kevrekidis, “Extended dynamic mode decomposition with dictionary learning: A data-driven adaptive spectral decomposition of the koopman operator,”Chaos: An Interdisciplinary Journal of Nonlinear Science, vol. 27, no. 10, 2017
2017
-
[17]
Dynamic mode decom- position with control,
J. L. Proctor, S. L. Brunton, and J. N. Kutz, “Dynamic mode decom- position with control,”SIAM Journal on Applied Dynamical Systems, vol. 15, no. 1, pp. 142–161, 2016
2016
-
[18]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational conference on machine learning. Pmlr, 2018, pp. 1861–1870
2018
-
[19]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
V ovk, A
V . V ovk, A. Gammerman, and G. Shafer,Algorithmic learning in a random world. Springer, 2005
2005
-
[21]
Conformal prediction: A gentle introduction,
A. N. Angelopoulos and S. Bates, “Conformal prediction: A gentle introduction,”Foundations and Trends in Machine Learning, vol. 16, no. 4, pp. 494–591, 2023
2023
-
[22]
Boyd and L
S. Boyd and L. Vandenberghe,Convex optimization. Cambridge university press, 2004
2004
-
[23]
Safe reinforcement learning using robust control barrier functions,
Y . Emam, G. Notomista, P. Glotfelter, Z. Kira, and M. Egerstedt, “Safe reinforcement learning using robust control barrier functions,”IEEE Robotics and Automation Letters, vol. 10, no. 3, pp. 2886–2893, 2022
2022
-
[24]
Discrete control barrier functions for safety-critical control of discrete systems with application to bipedal robot navigation
A. Agrawal and K. Sreenath, “Discrete control barrier functions for safety-critical control of discrete systems with application to bipedal robot navigation.” inRobotics: Science and Systems, vol. 13. Cam- bridge, MA, USA, 2017, pp. 1–10. JOURNAL OF LATEX CLASS FILES, VOL. 00, NO. 0, JANUARY 2026 17
2017
-
[25]
Con- formal prediction under covariate shift,
R. J. Tibshirani, R. Foygel Barber, E. Candes, and A. Ramdas, “Con- formal prediction under covariate shift,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[26]
Adaptive conformal inference under distribu- tion shift,
I. Gibbs and E. Candes, “Adaptive conformal inference under distribu- tion shift,”Advances in Neural Information Processing Systems, vol. 34, pp. 1660–1672, 2021
2021
-
[27]
Reward shaping-based actor–critic deep reinforcement learning for residential energy management,
R. Lu, Z. Jiang, H. Wu, Y . Ding, D. Wang, and H.-T. Zhang, “Reward shaping-based actor–critic deep reinforcement learning for residential energy management,”IEEE Transactions on Industrial Informatics, vol. 19, no. 3, pp. 2662–2673, 2022
2022
-
[28]
D. S. Kushwaha and Z. A. Biron, “Lyapunov constrained soft actor- critic (lc-sac) using koopman operator theory for quadrotor trajectory tracking,”arXiv preprint arXiv:2602.04132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
High-order control barrier functions,
W. Xiao and C. Belta, “High-order control barrier functions,”IEEE Transactions on Automatic Control, vol. 67, no. 7, pp. 3655–3662, 2021
2021
-
[30]
Deep koopman operator with control for nonlinear systems,
H. Shi and M. Q.-H. Meng, “Deep koopman operator with control for nonlinear systems,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 7700–7707, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.