From Latent Space to Training Data: Explainable Specialization in Minimal MLPs
Pith reviewed 2026-06-29 22:22 UTC · model grok-4.3
The pith
Coverage regularization yields the lowest reconstruction error and raises prototype specialization in minimal one-hidden-layer MLPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
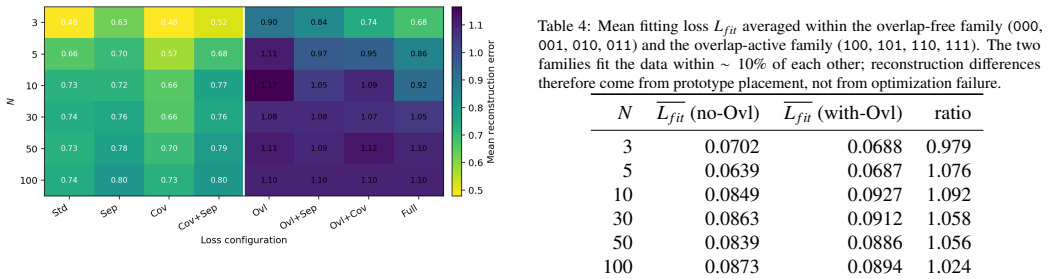
In Gaussian-activation MLPs of width N on N-point uniform one-dimensional datasets, coverage regularization minimizes reconstruction error at all tested N and elevates the prototype-usage specialization ratio relative to the standard baseline; overlap penalties are systematically harmful because they drive the optimizer to equilibria in which prototype centers lie outside the convex hull of the inputs, separation shows inconsistent effects, and coverage acts as the necessary attractor that prevents such expulsion.
What carries the argument
Coverage regularization loss, which attracts hidden-neuron prototypes toward the training samples and thereby counters the expulsion produced by repulsive losses.
If this is right
- Coverage regularization can be added to training to improve both reconstruction accuracy and neuron specialization in minimal MLPs.
- Repulsive losses such as overlap or separation without a compensating attractor lead to degenerate equilibria that increase reconstruction error.
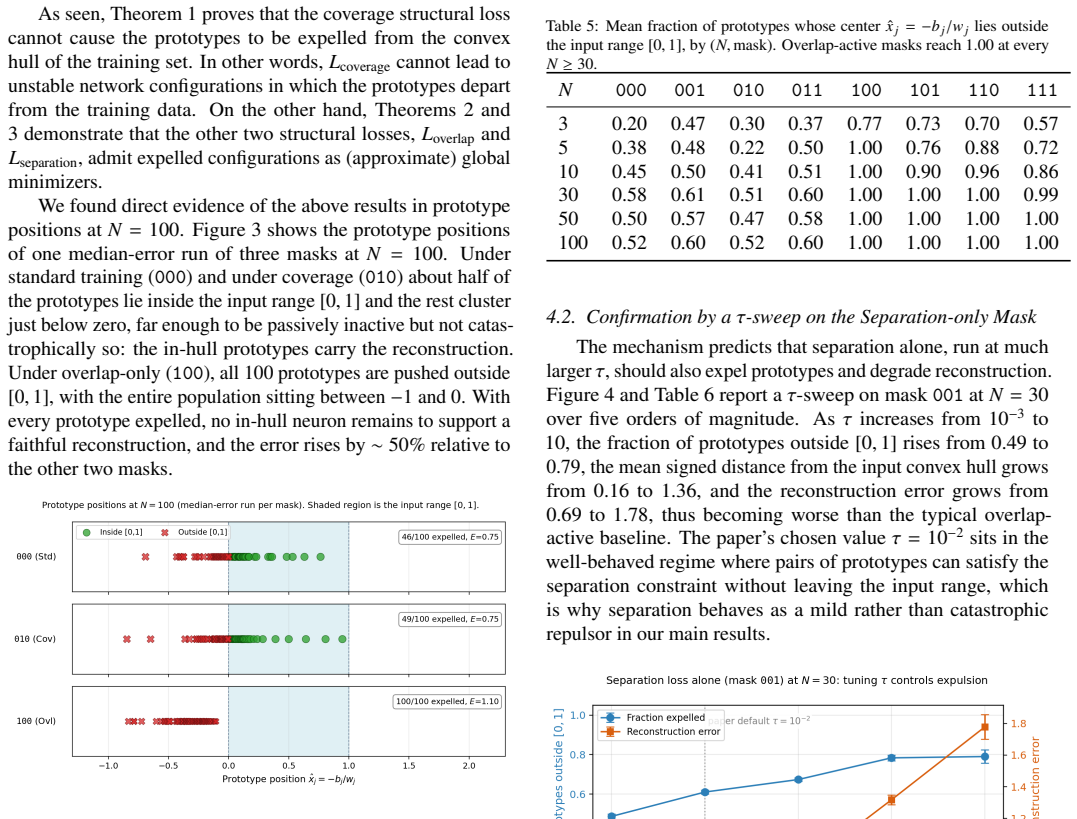
- Separation penalties produce only mixed gains and become harmful at large temperature or without an attractor term.
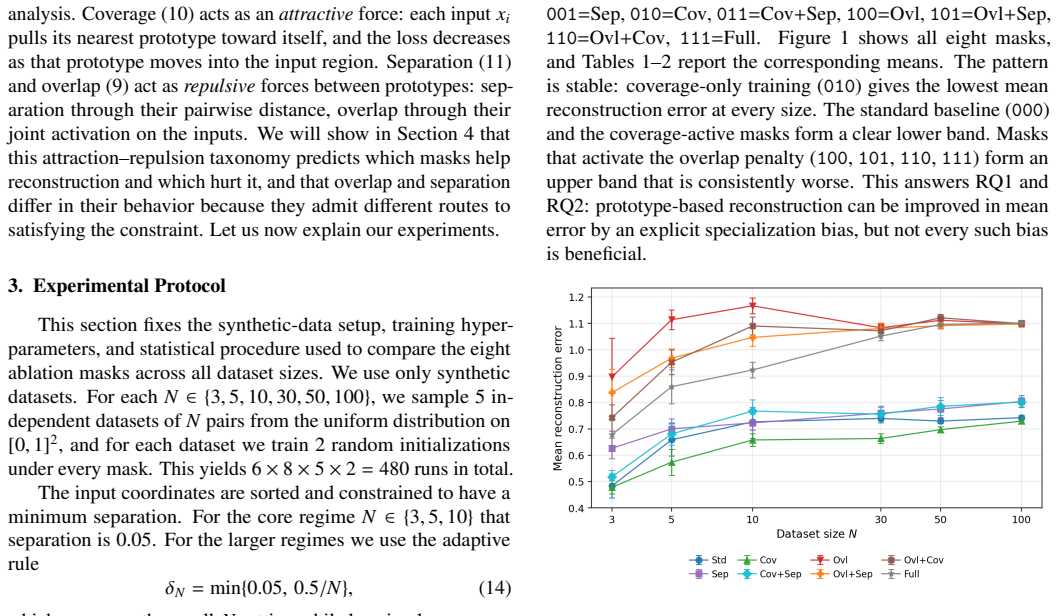
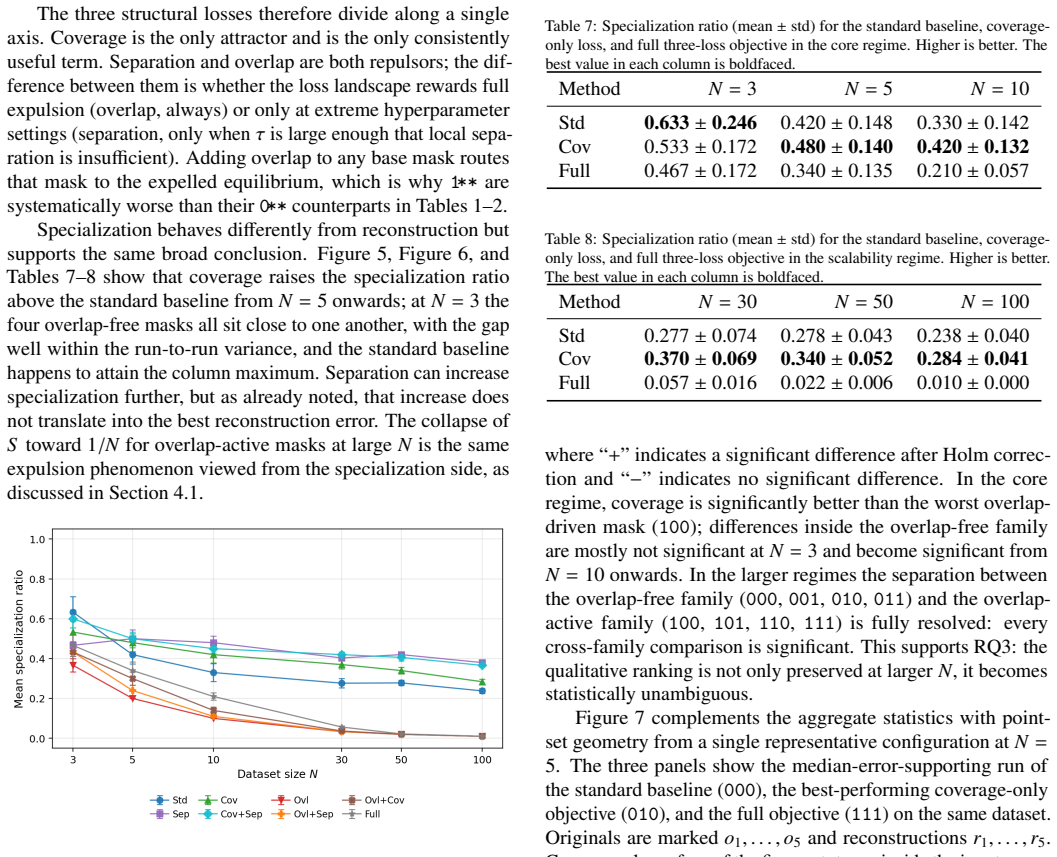
- The stable pattern across N from 3 to 100 in 480 runs indicates that the coverage-attractor principle applies across a wide range of minimal network sizes on this data regime.
Where Pith is reading between the lines
- The same balancing of repulsive and attractive losses could be tested in autoencoders or other models that recover prototypes from latent weights.
- If the expulsion mechanism persists in higher dimensions, coverage-style terms would become essential when designers add separation losses to encourage distinct prototypes.
- Direct visualization of prototype positions at larger N confirms the geometric mechanism and could be extended to monitor training dynamics in real time.
Load-bearing premise
The observed expulsion of prototypes outside the convex hull under overlap and separation losses is a general mechanism rather than an artifact of one-dimensional uniform sampling combined with Gaussian activations.
What would settle it
Repeating the full set of controlled runs on two-dimensional or non-uniformly sampled data and checking whether overlap and separation losses still produce prototype centers outside the convex hull.
Figures

read the original abstract
We here study whether training biases can make hidden neurons specialize in minimal one-hidden-layer MLPs, and whether such specialization improves prototype-based reconstruction of the training dataset from the learned weights. We consider Gaussianactivation MLPs of width equal to dataset size and compare three structural losses that respectively encourage coverage of the training samples, separation between neuron-induced prototypes, and low overlap of hidden responses, against the standard fitting baseline. Experiments on uniformly sampled one-dimensional datasets show a stable pattern from N = 3 to N = 100 across 480 controlled runs. Coverage regularization gives the lowest mean reconstruction error at every tested size and raises the prototype-usage specialization ratio relative to the standard baseline, while separation has mixed effects and overlap penalties are systematically harmful. We show that the harm is not an optimization failure: overlap-active approaches fit the data as well as overlap-free ones but route the optimizer to a degenerate equilibrium in which prototype centers are pushed outside the convex hull of the training inputs. Coverage cannot reward this expulsion and acts as an attractor: separation admits it only at large temperature and overlap admits it at the nominal hyperparameter choice. A direct {\tau}-sweep on the separation-only mask and a prototype-position visualization at N = 100 confirm the mechanism. The findings yield a simple design principle for prototype-recoverability-aware training: every repulsive structural loss must be compensated by a compatible attractor, or it will collapse the latent geometry it was meant to refine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies specialization in minimal one-hidden-layer MLPs (Gaussian activations, width = N) on 1D uniform data. It compares coverage, separation, and overlap structural losses to a standard baseline across N=3 to 100 (480 runs). Coverage yields lowest reconstruction error and higher prototype-usage ratios; separation is mixed; overlap is harmful by expelling prototypes outside the convex hull. Tau-sweeps and N=100 visualizations show the mechanism, yielding the design principle that every repulsive structural loss requires a compensating attractor.
Significance. If the empirical patterns hold, the work supplies a concrete mechanistic account of how structural losses interact with latent geometry in small networks, including a falsifiable design rule for prototype-recoverability. The scale (480 controlled runs), direct visualization of prototype positions, and identification of a non-optimization failure mode are strengths that make the observations reproducible and interpretable.
major comments (1)
- [Abstract] Abstract and experimental sections: the design principle ('every repulsive structural loss must be compensated by a compatible attractor') is stated without qualification, yet all supporting evidence (reconstruction errors, specialization ratios, expulsion mechanism) is obtained exclusively on 1D uniform sampling with Gaussian activations and width=N. The stress-test correctly flags that the expulsion equilibrium and coverage advantage may be artifacts of this regime; without tests on d>1 or non-uniform distributions the principle does not follow from the reported data.
minor comments (1)
- [Abstract] Abstract contains unreplaced LaTeX ('{\tau}-sweep'); ensure all math renders correctly in the final version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the design principle is stated too generally given the scope of the experiments and will revise the manuscript to qualify the claims as observations from the 1D uniform regime while noting the need for further validation.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental sections: the design principle ('every repulsive structural loss must be compensated by a compatible attractor') is stated without qualification, yet all supporting evidence (reconstruction errors, specialization ratios, expulsion mechanism) is obtained exclusively on 1D uniform sampling with Gaussian activations and width=N. The stress-test correctly flags that the expulsion equilibrium and coverage advantage may be artifacts of this regime; without tests on d>1 or non-uniform distributions the principle does not follow from the reported data.
Authors: We acknowledge that all reported results, including reconstruction errors, specialization ratios, and the expulsion mechanism, are obtained exclusively on 1D uniform data with Gaussian activations and width=N. The design principle is an extrapolation from these controlled experiments. We will revise the abstract and experimental sections to present the principle as an empirical observation and falsifiable hypothesis specific to this regime, rather than a general claim. We will also expand the discussion of the stress-test to more explicitly flag the potential for regime-specific artifacts and the need for future tests in d>1 and non-uniform settings. revision: yes
Circularity Check
No circularity; purely empirical measurements of error and specialization ratios.
full rationale
The paper reports controlled experiments measuring reconstruction error and prototype-usage ratios on held-out data across N=3 to 100. The design principle is presented as an interpretation of observed optimizer behavior under different losses, not as a mathematical derivation or fitted quantity that reduces to its own inputs by construction. No equations, self-citations, or ansatzes are invoked in a load-bearing way that would create circularity. The central claims rest on direct experimental outcomes rather than re-deriving inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss coefficients for coverage, separation, overlap
Reference graph
Works this paper leans on
-
[1]
Y . Bengio, A. Courville, P. Vincent, Representation learn- ing: A review and new perspectives, IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8) (2013) 1798–1828. doi:10.1109/TPAMI.2013.50
-
[2]
Alain, Y
G. Alain, Y . Bengio, Understanding intermediate layers using linear classifier probes, in: International Conference on Learning Representations Workshop Track, 2017
2017
-
[3]
C. Rudin, Stop explaining black box machine learning mod- els for high stakes decisions and use interpretable models instead, Nature Machine Intelligence 1 (5) (2019) 206–215. doi:10.1038/s42256-019-0048-x
-
[4]
Carlini, F
N. Carlini, F. Tramèr, E. Wallace, M. Jagielski, A. Herbert- V oss, K. Lee, A. Roberts, T. Brown, D. Song, Ú. Erlings- son, A. Oprea, C. Raffel, Extracting training data from large language models, in: 30th USENIX Security Sympo- sium (USENIX Security 21), 2021, pp. 2633–2650
2021
-
[5]
N. Haim, G. Vardi, G. Yehudai, O. Shamir, M. Irani, Re- constructing training data from trained neural networks, in: Advances in Neural Information Processing Systems 35, 2022, pp. 22911–22924
2022
-
[6]
Cogswell, F
M. Cogswell, F. Ahmed, R. Girshick, L. Zitnick, D. Batra, Reducing overfitting in deep networks by decorrelating representations, in: International Conference on Learning Representations, 2016
2016
-
[7]
E. Oostwal, M. Straat, M. Biehl, Hidden unit specialization in layered neural networks: ReLU vs. sigmoidal activation, Physica A: Statistical Mechanics and its Applications 564 (2021) 125517. doi:10.1016/j.physa.2020.125517
-
[8]
L. Xie, Y . Yang, D. Cai, X. He, Neural collapse inspired attraction-repulsion-balanced loss for imbal- anced learning, Neurocomputing 527 (2023) 60–70. doi:10.1016/j.neucom.2023.01.023
-
[9]
D. S. Broomhead, D. Lowe, Multivariable functional inter- polation and adaptive networks, Complex Systems 2 (3) (1988) 321–355
1988
-
[10]
J. Moody, C. J. Darken, Fast learning in networks of locally- tuned processing units, Neural Computation 1 (2) (1989) 281–294. doi:10.1162/neco.1989.1.2.281
-
[11]
J. Park, I. W. Sandberg, Universal approximation using radial-basis-function networks, Neural Computation 3 (2) (1991) 246–257. doi:10.1162/neco.1991.3.2.246. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.