Dual Dimensionality for Local and Global Attention
Pith reviewed 2026-06-26 21:19 UTC · model grok-4.3
The pith
Distance-adaptive representations match full-dimensional attention performance by giving richer keys and values to local tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
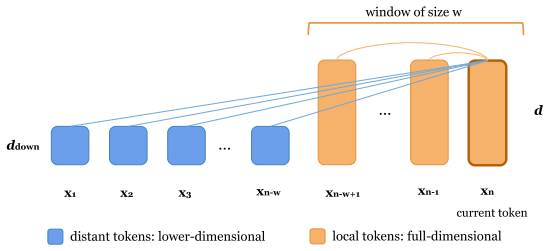
Decoder-only Transformers compute attention over the KV cache of preceding tokens with the same dimensionality for every position. The authors hypothesize that local tokens impose greater demands on representational capacity because they most strongly influence immediate next-token predictions, whereas distant tokens mainly provide long-range memory that tolerates lower dimensionality. Distance-Adaptive Representation implements this by preserving full-dimensional KV vectors inside a fixed local window and assigning reduced-dimensional vectors beyond the window. Across multiple pretraining scales and continued supervised fine-tuning, the approach matches the performance of full-dimensional m
What carries the argument
Distance-Adaptive Representation (DAR), which keeps full-dimensional KV representations inside a local context window and assigns reduced-dimensional representations to tokens beyond that window.
If this is right
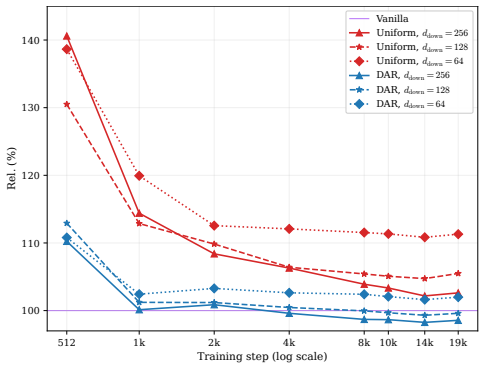
- Performance remains comparable to full-dimensional baselines across pretraining scales from 70M to 410M parameters.
- Continued supervised fine-tuning on a 1B-scale model also reaches matching performance.
- Uniform reduction of dimensionality at every token position produces worse results than the distance-adaptive approach.
- KV cache memory footprint can be reduced during inference while preserving accuracy.
Where Pith is reading between the lines
- The same local-versus-distant split could be applied to attention layers in non-decoder architectures.
- Fixed local windows might be replaced by learned or task-dependent window sizes to further optimize capacity allocation.
- Longer maximum sequence lengths could become practical under a fixed memory budget for the KV cache.
Load-bearing premise
Local tokens require richer representations than distant tokens because they matter more for predicting the immediate next output.
What would settle it
At the 410-million-parameter scale, run the same pretraining data and show that the distance-adaptive model produces more than a 0.5-point rise in validation perplexity relative to the matched full-dimensional baseline.
Figures
read the original abstract
Decoder-only Transformers compute attention over the KV cache of preceding tokens. Keys (and Values) are typically represented with the same dimensionality, regardless of its distance from the prediction target. In natural language, however, the next word is most strongly influenced by the immediately preceding tokens. We hypothesize that local and distant tokens impose asymmetric demands on representational capacity: local tokens are more critical for predicting immediate outputs and thus require richer representations, whereas distant tokens primarily serve as long-range memory, for which lower-dimensional representations may suffice. We formalize this idea as Distance-Adaptive Representation (DAR), implemented in a controlled setting that preserves full-dimensional representations within a local context window while assigning reduced-dimensional representations (e.g. 1/4 of the original dimensionality) to tokens beyond that window. Across multiple pretraining scales (70M to 410M parameters), as well as continued supervised fine-tuning on a 1B-scale model, this approach closely matches the performance of full-dimensional baselines. In contrast, uniformly reducing dimensionality across all token positions leads to worse performance. These results challenge the common assumption that key and value dimensionality should be uniform across token positions. Our findings suggest a new direction for designing attention architectures that adaptively allocate representational capacity across sequences, enabling further reductions in KV cache during inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Distance-Adaptive Representation (DAR) for decoder-only Transformers, hypothesizing asymmetric representational demands: local tokens (within a context window) require full-dimensional keys/values while distant tokens can use reduced dimensionality (e.g., 1/4). Implemented in a controlled setting, DAR is evaluated on pretraining runs from 70M to 410M parameters and continued supervised fine-tuning on a 1B-scale model. Results indicate DAR matches full-dimensional baseline performance, whereas uniform dimensionality reduction across all positions degrades results. The work challenges the uniform KV dimensionality assumption and suggests potential KV cache reductions at inference.
Significance. If the central empirical claim holds under fully controlled conditions, the result would be significant for efficient Transformer design: it provides evidence that representational capacity can be allocated non-uniformly by token distance without performance loss, opening a direction for adaptive attention mechanisms that reduce memory usage during inference while preserving modeling quality.
major comments (2)
- [§3] The skeptic concern is load-bearing: the central claim requires that DAR and the uniform-reduction baseline differ only in the hypothesized local-vs-distant asymmetry. §3 (Method) and the experimental setup do not provide sufficient detail on the projection mechanism for reduced-dimensional KV (separate matrices? shared weights? padding/concatenation?), leaving open the possibility that performance parity arises from uncontrolled differences in parameter count or attention computation rather than the distance-adaptive hypothesis.
- [Table 2] Table 2 (or equivalent results table): the reported matching performance across pretraining scales lacks explicit controls for total parameter count or effective head capacity between DAR and the full-dimensional baseline; without these, the contrast to uniform reduction cannot be attributed solely to the local-window design.
minor comments (2)
- The exact local window size and reduction factor used in each scale experiment should be stated explicitly (they are listed as free parameters in the design) rather than described only as 'e.g. 1/4'.
- [§4] Clarify in the abstract and §4 whether the 1B-scale fine-tuning results use the same DAR configuration as the pretraining runs or a modified one.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on implementation details and experimental controls. We agree these clarifications will strengthen the paper and will revise accordingly.
read point-by-point responses
-
Referee: [§3] The skeptic concern is load-bearing: the central claim requires that DAR and the uniform-reduction baseline differ only in the hypothesized local-vs-distant asymmetry. §3 (Method) and the experimental setup do not provide sufficient detail on the projection mechanism for reduced-dimensional KV (separate matrices? shared weights? padding/concatenation?), leaving open the possibility that performance parity arises from uncontrolled differences in parameter count or attention computation rather than the distance-adaptive hypothesis.
Authors: We agree that §3 requires additional detail to rule out alternative explanations. In the revision we will expand the method description to specify the projection mechanism for reduced-dimensional KV (including matrix sharing or separation and any padding/concatenation steps) and confirm that attention computation remains identical across conditions. This will make explicit that the sole controlled difference is the distance-based dimensionality allocation. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table): the reported matching performance across pretraining scales lacks explicit controls for total parameter count or effective head capacity between DAR and the full-dimensional baseline; without these, the contrast to uniform reduction cannot be attributed solely to the local-window design.
Authors: We will add explicit parameter-count and head-capacity comparisons (for DAR, full baseline, and uniform-reduction models) to the results section and Table 2. This will allow direct verification that performance differences are attributable to the local-vs-distant asymmetry rather than capacity mismatches. revision: yes
Circularity Check
No circularity; empirical comparisons are independent of any fitted result or self-citation chain
full rationale
The paper advances a hypothesis about local vs. distant token representational needs, formalizes it as the DAR method (local full-dimensional KV, distant reduced-dimensional KV), and reports direct empirical performance comparisons against full-dimensional and uniform-reduction baselines across multiple model scales. No equations, predictions, or uniqueness claims are shown to reduce by construction to fitted parameters, self-citations, or ansatzes imported from prior work by the same authors. The central claim rests on controlled experiments whose outcomes are not forced by the method definition itself. This is the expected non-finding for an architecture proposal validated by ablation-style scaling experiments.
Axiom & Free-Parameter Ledger
free parameters (2)
- local context window size
- dimensionality reduction factor
axioms (1)
- standard math Decoder-only transformer attention computes over a KV cache of preceding tokens with uniform dimensionality by default.
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023
2023
-
[2]
GPT-NeoX: Large scale autoregressive language modeling in pytorch, 9 2023
Alex Andonian, Quentin Anthony, Stella Biderman, Sid Black, Preetham Gali, Leo Gao, Eric Hallahan, Josh Levy-Kramer, Connor Leahy, Lucas Nestler, Kip Parker, Michael Pieler, Jason Phang, Shivanshu Purohit, Hailey Schoelkopf, Dashiell Stander, Tri Songz, Curt Tigges, Benjamin Thérien, Phil Wang, and Samuel Weinbach. GPT-NeoX: Large scale autoregressive lan...
2023
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages...
2024
-
[5]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[6]
Datasheet for the pile.arXiv preprint arXiv:2201.07311, 2022
Stella Biderman, Kieran Bicheno, and Leo Gao. Datasheet for the pile.arXiv preprint arXiv:2201.07311, 2022
-
[7]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023
2023
-
[8]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christo- pher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[9]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
2022
-
[10]
DeepSeek-V4: Towards highly efficient million-token context intelligence
DeepSeek-AI. DeepSeek-V4: Towards highly efficient million-token context intelligence. Technical Report, April 2026
2026
-
[11]
Haojie Duanmu, Zhihang Yuan, Xiuhong Li, Jiangfei Duan, Xingcheng Zhang, and Dahua Lin. SKVQ: Sliding-window key and value cache quantization for large language models.arXiv preprint arXiv:2405.06219, 2024
-
[12]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The Pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
A framework for few-shot language model evaluation, September 2021
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework...
2021
-
[14]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[15]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse attention. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[17]
Matryoshka representation learning.Advances in Neural Information Processing Systems, 35:30233–30249, 2022
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ra- manujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Matryoshka representation learning.Advances in Neural Information Processing Systems, 35:30233–30249, 2022. 10
2022
-
[18]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[19]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
SnapKV: LLM knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[21]
MatryoshkaKV: Adaptive kv compression via trainable orthogonal projection
Bokai Lin, Zihao Zeng, Zipeng Xiao, Siqi Kou, Tianqi Hou, Xiaofeng Gao, Hao Zhang, and Zhijie Deng. MatryoshkaKV: Adaptive kv compression via trainable orthogonal projection. arXiv preprint arXiv:2410.14731, 2024
-
[22]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-V2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
FineWeb-Edu: the finest collection of educational content, 2024
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. FineWeb-Edu: the finest collection of educational content, 2024
2024
-
[24]
Pointer sentinel mixture models, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016
2016
-
[25]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Ma- lik, Willia...
2024
-
[26]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[27]
Fast Transformer Decoding: One Write-Head is All You Need
Noam Shazeer. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[28]
CommonsenseQA: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, V olume 1 (Long and Short Papers), pages 4149–4158, Minneapoli...
2019
-
[29]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[30]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
XAttention: Block sparse attention with antidiagonal scoring
Ruyi Xu, Guangxuan Xiao, Haofeng Huang, Junxian Guo, and Song Han. XAttention: Block sparse attention with antidiagonal scoring. InF orty-second International Conference on Machine Learning, 2025
2025
-
[32]
HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019. 11
2019
-
[33]
H2O: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023. 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.