Do VLMs Reason Like Engineers? A Benchmark and a Stage-wise Evaluation
Pith reviewed 2026-06-27 13:09 UTC · model grok-4.3
The pith
Vision-language models exhibit substantial limitations in engineering reasoning on the EngVQA benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
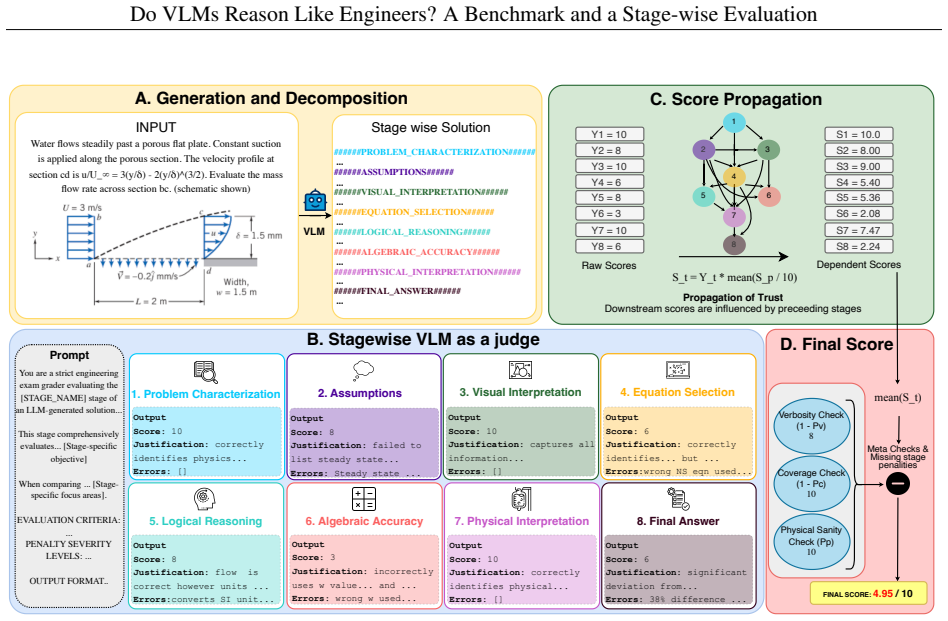
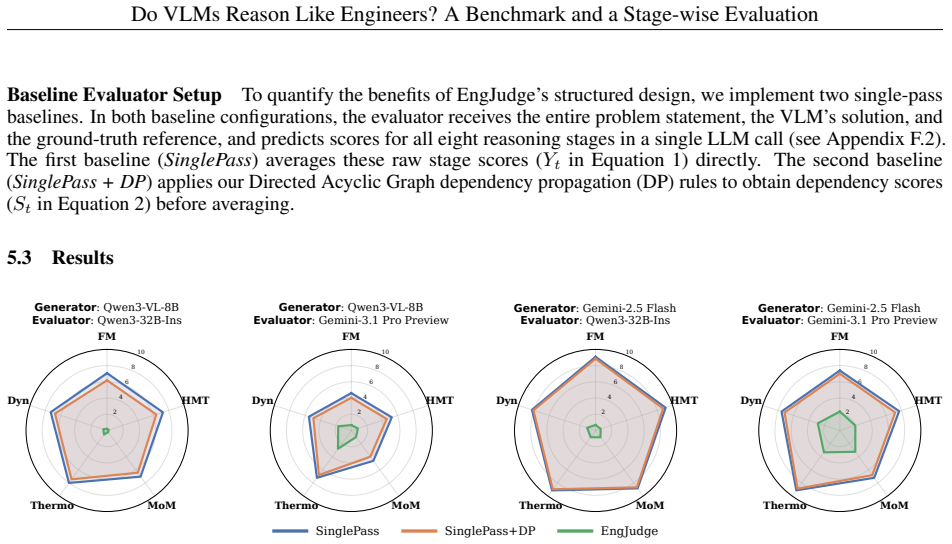
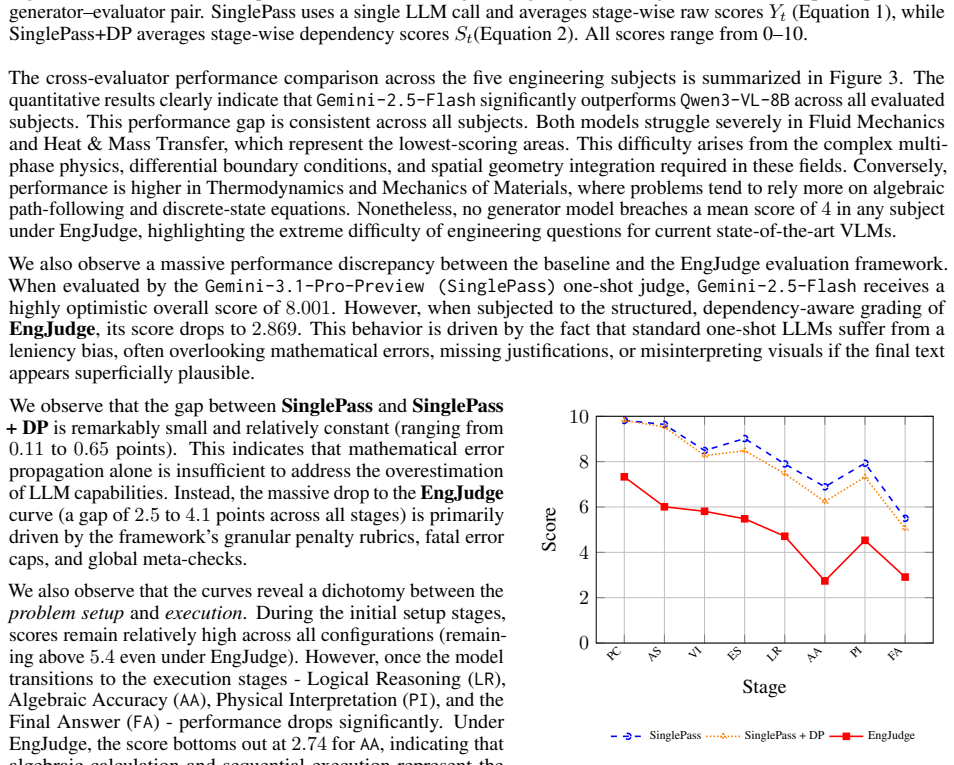
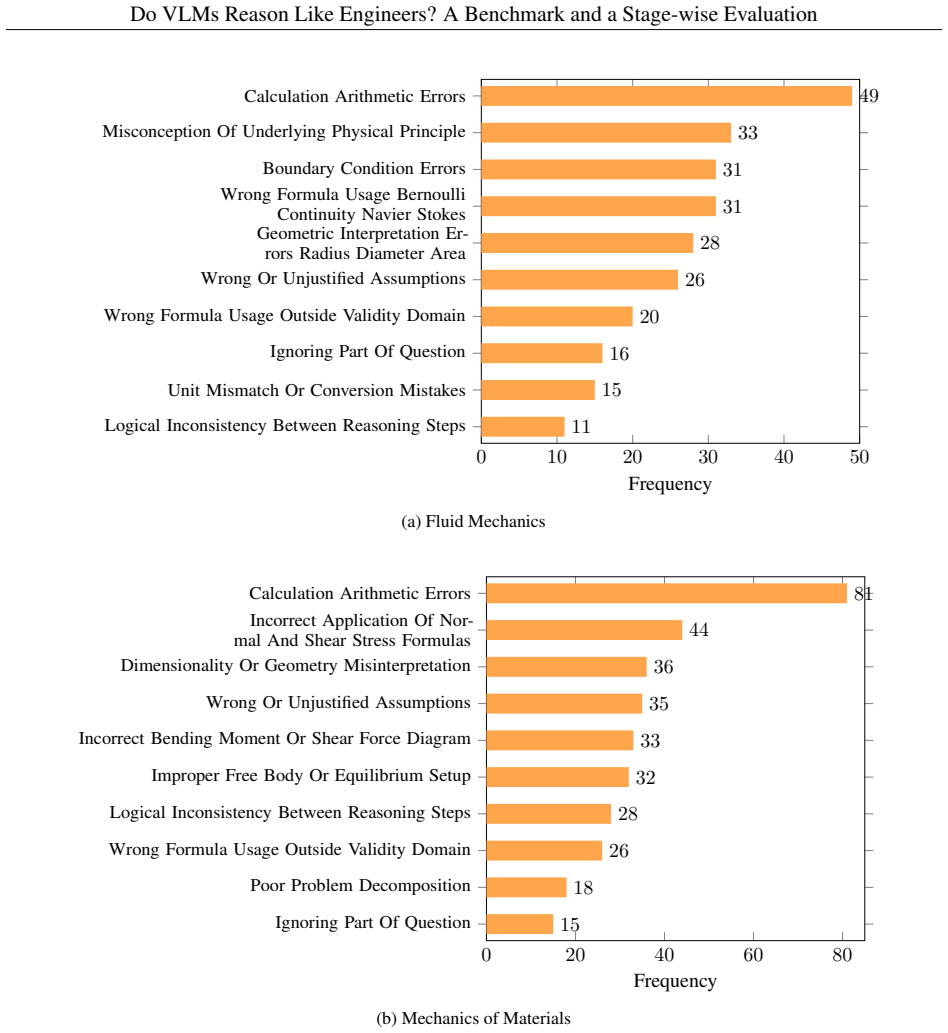
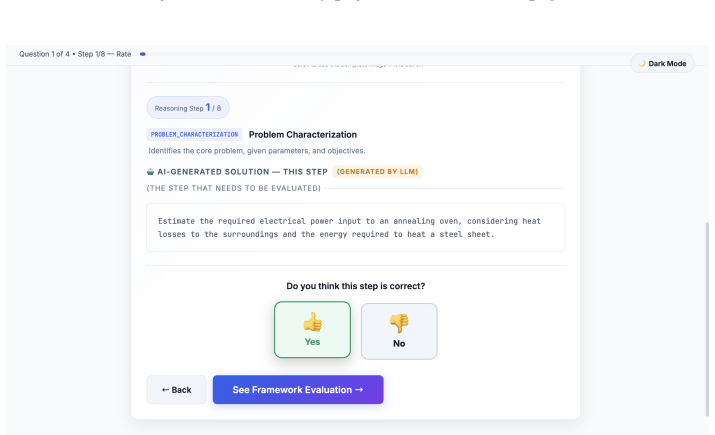
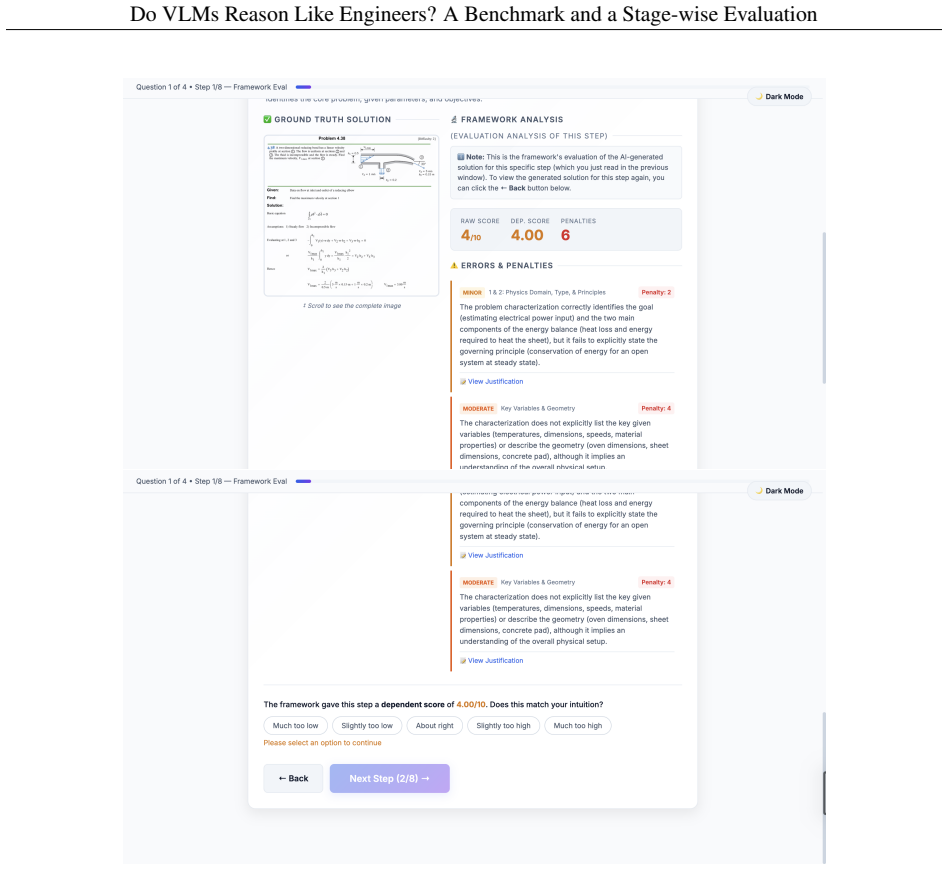
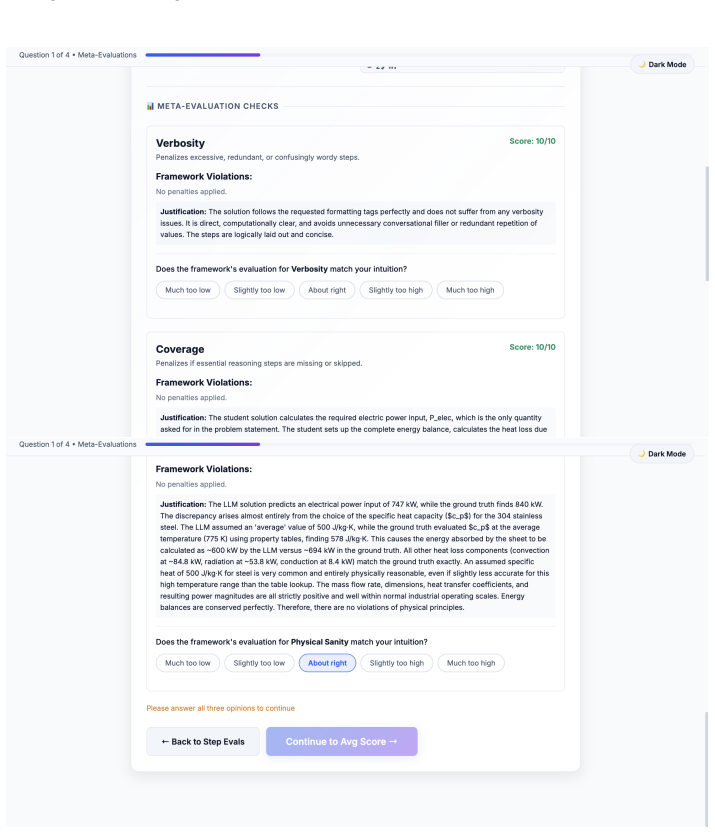
The paper claims that state-of-the-art VLMs exhibit substantial limitations in engineering reasoning capabilities, as shown by their performance on the EngVQA benchmark using the 8-stage evaluation framework. The benchmark covers five engineering subjects and 696 problems, and the framework enables fine-grained analysis by evaluating each stage of the solution process separately.
What carries the argument
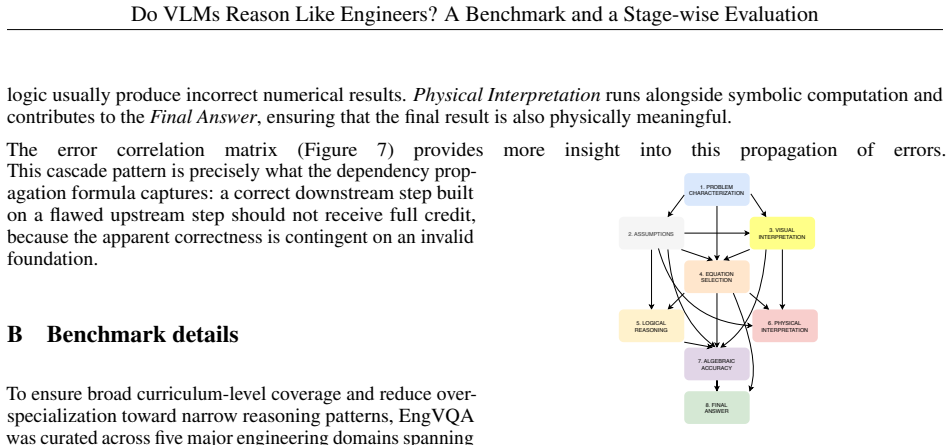
The 8-stage automatic evaluation framework that independently scores each phase of an engineering solution, from diagram interpretation through physical principle selection to final verification.
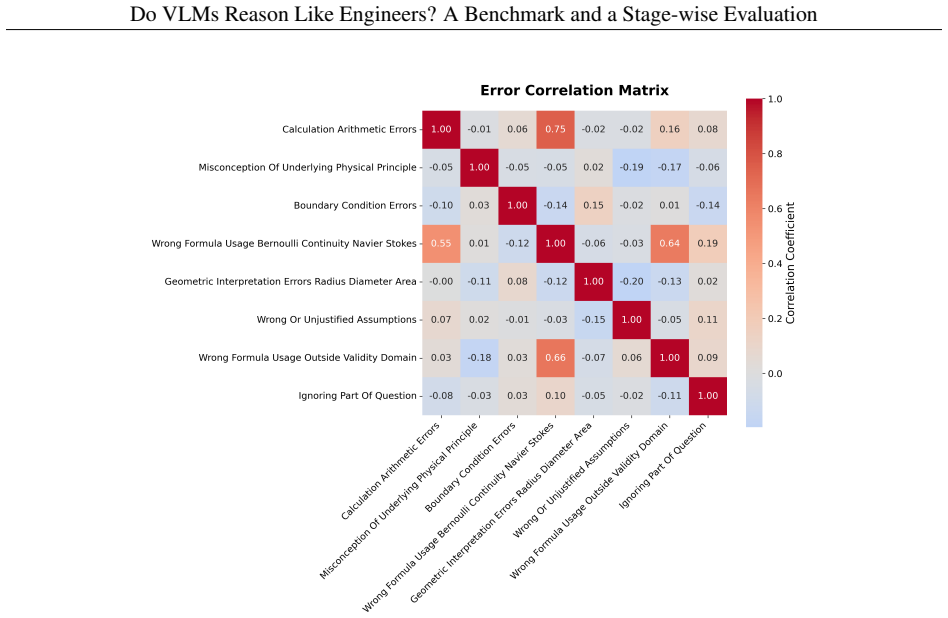
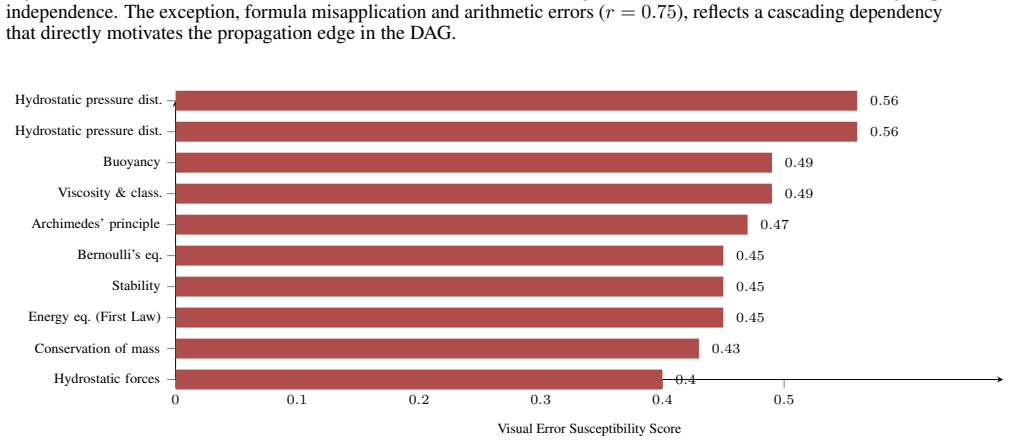
If this is right
- Benchmarks that score only final answers miss the specific stages where VLMs break down in engineering tasks.
- Process-oriented evaluation becomes necessary for any VLM system used in engineering education or technical decision support.
- The 696-problem EngVQA set provides a concrete testbed for measuring progress on diagram interpretation and multi-step physical consistency.
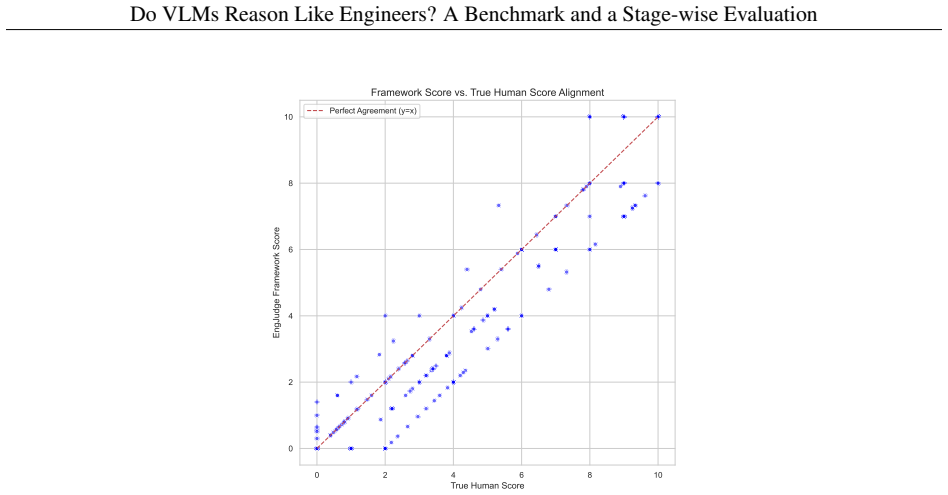
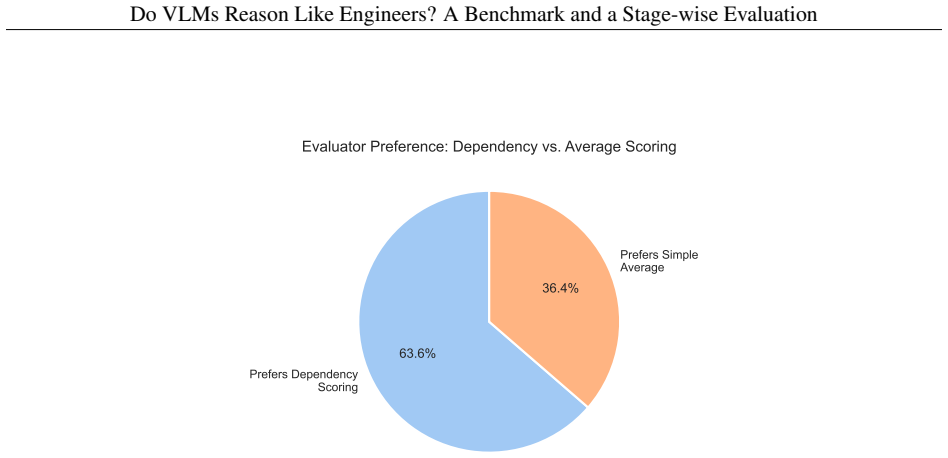
- High agreement between the automated framework and human graders supports scaling this evaluation method to larger model assessments.
Where Pith is reading between the lines
- The same stage-wise approach could be adapted to evaluate reasoning in related technical fields such as physics problem solving or circuit design.
- Models that fail early stages like diagram reading may require targeted training on technical visuals before attempting full solutions.
- General multimodal benchmarks may systematically overestimate VLM readiness for domains that demand physically valid intermediate steps.
Load-bearing premise
The 8-stage decomposition of engineering problem solving is both exhaustive and independently scorable by an automated system without requiring human judgment for each stage.
What would settle it
A large collection of VLM-generated solutions where the automated stage scores differ substantially from scores assigned by expert human graders would show the framework does not reliably capture engineering reasoning quality.
Figures



read the original abstract
Vision-Language Models (VLMs) demonstrate strong performance on general multimodal reasoning benchmarks, yet their ability to perform engineering reasoning remains largely unexplored. Unlike general visual question answering, engineering problem solving requires interpreting technical diagrams, selecting governing physical principles, and maintaining physically consistent multi-step reasoning. These capabilities are increasingly important for AI systems used in engineering education, scientific assistance, and technical decision-making, where reasoning failures may produce physically invalid yet superficially plausible solutions. Existing benchmarks primarily evaluate final answers and provide limited assessment of intermediate reasoning processes. We introduce EngVQA, a multimodal benchmark for evaluating engineering reasoning across 5 engineering subjects containing 696 problems. We introduce an 8-stage automatic evaluation framework for assessing VLM-generated solutions. The framework independently evaluates each stage of the solution, enabling fine-grained analysis of reasoning failures. We benchmark multiple state-of-the-art open and closed source VLMs on our evaluation framework and demonstrate substantial limitations in current engineering reasoning capabilities. Human evaluation shows strong agreement with our automated framework, achieving a Pearson correlation of 0.975 and a mean absolute error of 0.67 on a 10-point grading scale. Our results highlight the importance of process-oriented evaluation for reliable assessment of multimodal engineering reasoning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EngVQA, a multimodal benchmark with 696 engineering problems across 5 subjects, paired with a novel 8-stage automatic evaluation framework that scores VLM solutions stage-by-stage rather than solely on final answers. It benchmarks multiple open- and closed-source VLMs, reports substantial limitations in their engineering reasoning, and validates the automated framework via strong human agreement (Pearson 0.975, MAE 0.67 on a 10-point scale).
Significance. If the 8-stage framework proves both exhaustive and independently scorable, the work supplies a process-oriented diagnostic tool that could meaningfully advance evaluation of VLMs for technical domains where physically consistent multi-step reasoning matters. The emphasis on intermediate stages over final-answer accuracy is a clear methodological strength.
major comments (2)
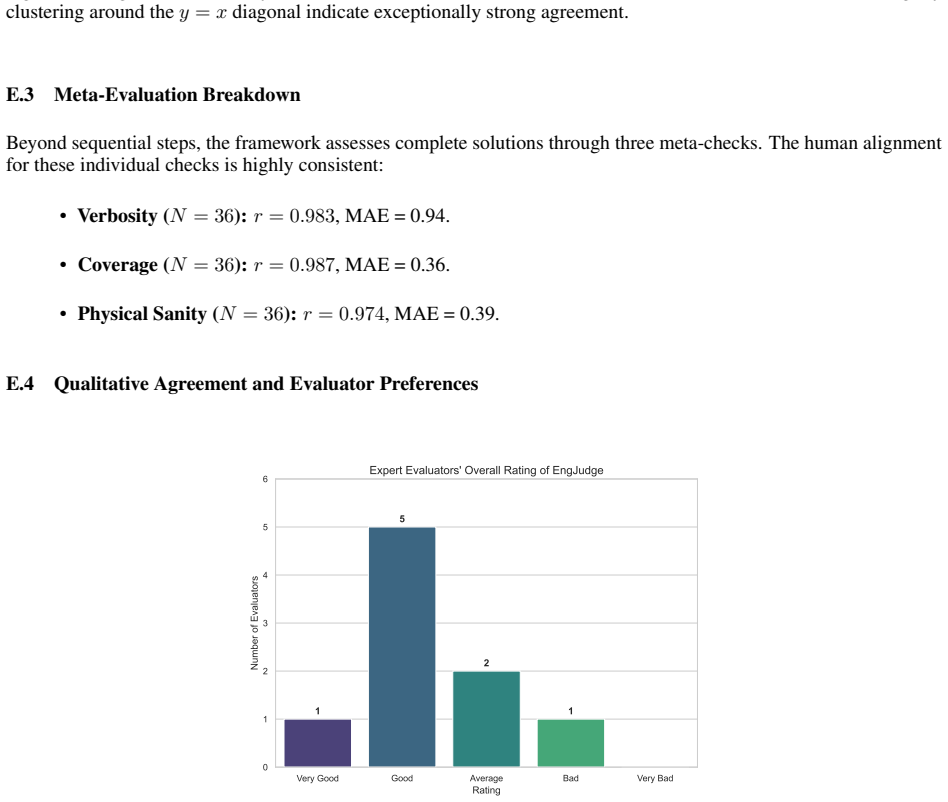
- [§4] §4 (8-stage framework description): the central claim of 'substantial limitations' and the fine-grained failure analysis rest on the assumption that the chosen 8 stages are exhaustive and independently machine-scorable; the reported Pearson/MAE agreement is only with overall human grades and does not test coverage of omitted elements such as assumption checking, unit consistency, or iterative refinement, nor does it demonstrate that inter-stage dependencies permit truly independent scoring.
- [§3] §3 (benchmark construction): no details are supplied on how the 696 problems were generated or validated, nor on inter-rater reliability specifically for the stage labels themselves; without this, the soundness of the per-stage scores used to support the headline conclusion remains under-specified.
minor comments (2)
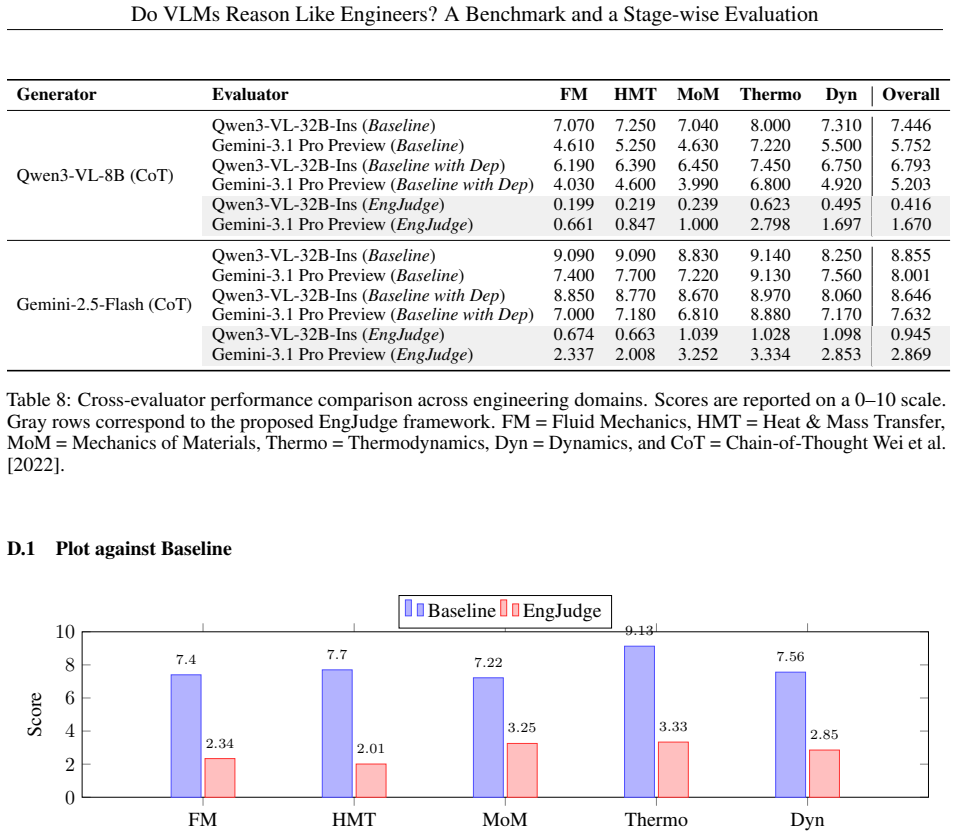
- [§5] The abstract and §5 report aggregate VLM scores but do not include per-stage breakdown tables or error bars; adding these would improve interpretability of the failure-mode claims.
- [§4] Notation for the automated scoring function (presumably defined in §4) should be made fully explicit so that the independence assumption can be directly inspected.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We provide point-by-point responses to the major comments and indicate the revisions we will make to address them.
read point-by-point responses
-
Referee: [§4] §4 (8-stage framework description): the central claim of 'substantial limitations' and the fine-grained failure analysis rest on the assumption that the chosen 8 stages are exhaustive and independently machine-scorable; the reported Pearson/MAE agreement is only with overall human grades and does not test coverage of omitted elements such as assumption checking, unit consistency, or iterative refinement, nor does it demonstrate that inter-stage dependencies permit truly independent scoring.
Authors: We appreciate the referee pointing out the need for stronger validation of the 8-stage framework. The stages were selected to represent a canonical engineering reasoning pipeline based on established problem-solving literature. The human evaluation agreement supports the reliability of the overall scores, but we acknowledge that it does not directly validate stage exhaustiveness or independence. In the revised manuscript, we will expand §4 to include: (1) a detailed rationale for the 8 stages with references to engineering education standards, (2) an analysis of inter-stage score correlations to assess independence, and (3) a discussion of potential omitted elements (e.g., assumption checking) with examples of how they might be incorporated in future extensions. We believe this will address the concern while maintaining the framework's utility as a diagnostic tool. revision: yes
-
Referee: [§3] §3 (benchmark construction): no details are supplied on how the 696 problems were generated or validated, nor on inter-rater reliability specifically for the stage labels themselves; without this, the soundness of the per-stage scores used to support the headline conclusion remains under-specified.
Authors: We agree that additional details on benchmark construction are necessary for reproducibility and to support the validity of the stage labels. The 696 problems were collected from publicly available engineering textbooks, homework sets, and exam questions across the five subjects, then filtered and adapted for multimodal format by the authors with input from engineering faculty. For stage labels, a subset of 100 problems was independently labeled by two domain experts, with disagreements resolved through discussion. We will add a new subsection in §3 describing the problem curation process, inclusion criteria, and inter-rater reliability (e.g., percentage agreement and Cohen's kappa for stage assignments). This information was omitted due to space constraints but will be included in the revision. revision: yes
Circularity Check
No circularity: new benchmark and framework are self-contained contributions
full rationale
The paper introduces EngVQA (696 problems across 5 subjects) and an 8-stage automatic evaluation framework as original contributions. Reported VLM limitations follow directly from applying this framework, with independent validation via human agreement (Pearson 0.975, MAE 0.67 on 10-point scale). No equations, fitted parameters, self-citations, or derivations reduce any result to prior inputs by construction. The framework is presented as a novel process-oriented method rather than derived from or equivalent to existing self-referential elements. The exhaustiveness concern raised in the skeptic note pertains to validity/coverage rather than circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Engineering problem solving decomposes into eight independent stages that can be evaluated separately by an automated system.
Reference graph
Works this paper leans on
-
[1]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
URLhttps://arxiv.org/abs/2310.02255. Xiyuan Zhou, Xinlei Wang, Yirui He, Yang Wu, Ruixi Zou, Yuheng Cheng, Yulu Xie, Wenxuan Liu, Huan Zhao, Yan Xu, Jinjin Gu, and Junhua Zhao. Engibench: A benchmark for evaluating large language models on engineering problem solving, 2026. URLhttps://arxiv.org/abs/2509.17677. Ming Li, Jike Zhong, Tianle Chen, Yuxiang Lai...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr52734.2025.01245 2026
-
[2]
PROBLEM CHARACTERIZATION
-
[3]
VISUAL INTERPRETATION
ASSUMPTIONS 3. VISUAL INTERPRETATION
-
[4]
PHYSICAL INTERPRETATION
-
[5]
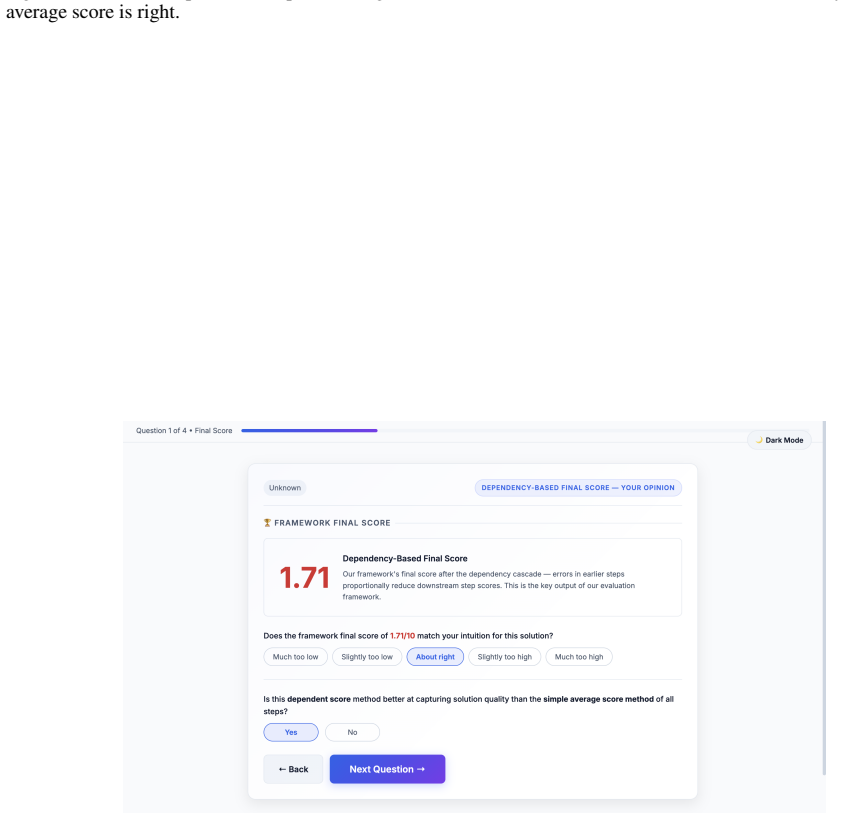
LOGICAL REASONING Figure 9: Dependency DAG structure used for trust prop- agation across reasoning steps. This cascade pattern is precisely what the dependency prop- agation formula captures: a correct downstream step built on a flawed upstream step should not receive full credit, because the apparent correctness is contingent on an invalid foundation. B ...
-
[6]
The model was provided with the question statement, its master topic list, and the corresponding question diagram
-
[7]
The model selected all topics necessary to formulate or solve the problem
-
[8]
large surroundings
To ensure data integrity and prevent hallucinated labels, the model’s output was processed by an automated validation script. The validator matched each output string against the master topic list using case-insensitive transformations and fuzzy string matching (with a similarity cutoff threshold of 0.85). Topics failing this validation check were discard...
2023
-
[9]
Correlation:The DAG is designed to enforce direct, physical causal prerequisites
Causality vs. Correlation:The DAG is designed to enforce direct, physical causal prerequisites. For example, a student can mathematically compute a correct final numerical answer (FA) via correct algebraic manipulation (AA) without necessarily understanding or explaining its physical meaning ( PI). Because PI is not a strict mathematical prerequisite for ...
-
[10]
This shared dependency on common ancestors creates high statistical correlation (confounding) in the empirical data
Confounding by Downstream Position:Later steps in the reasoning chain (such as AA, PI, and FA) are strongly correlated because they are co-dependent on the cumulative errors of early steps (likeAS and ES). This shared dependency on common ancestors creates high statistical correlation (confounding) in the empirical data. Adding redundant edges between the...
-
[11]
Much too low
Conceptual Independence in Rubrics:Conceptual reasoning (such as qualitative physical interpretation) and algebraic computation are graded as independent dimensions in standard engineering pedagogy. A model may fail the algebra but perform a correct physical limit check, or vice versa. The high empirical correlation (r= 0.52 between AA and PI) is a reflec...
1974
-
[12]
Steady state -- no time-dependent terms given
-
[13]
Constant k -- temperature range is small
-
[14]
###### END_STEP ###### ###### VISUAL_INTERPRETATION ###### Extract from the diagram: dimensions, boundary conditions, material properties
1D radial -- long pipe, neglect end effects Do NOT over-complicate. ###### END_STEP ###### ###### VISUAL_INTERPRETATION ###### Extract from the diagram: dimensions, boundary conditions, material properties. Be brief and factual. If no diagram, state geometry from the problem text. ###### END_STEP ###### ###### EQUATION_SELECTION ###### Write the governing...
-
[15]
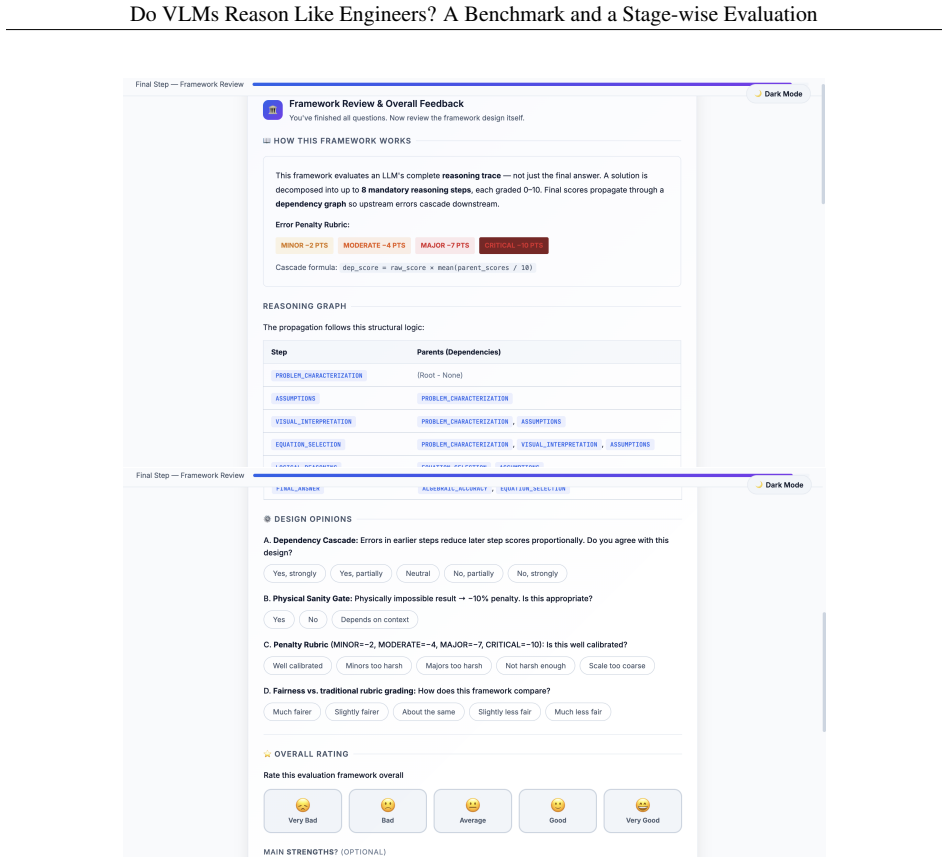
PROBLEM_CHARACTERIZATION: Identifies the underlying physics, problem type, and governing principles
-
[16]
ASSUMPTIONS: Makes valid assumptions based on problem information with physical justification
-
[17]
VISUAL_INTERPRETATION: Correctly interprets diagrams, FBDs, geometric information, and visual constraints
-
[18]
EQUATION_SELECTION: Verifies correct governing equation, justified simplifications, appropriate coordinate system, correct BCs
-
[19]
LOGICAL_REASONING: Ensures logical validity and meaningful contribution of each reasoning step
-
[20]
ALGEBRAIC_ACCURACY: Evaluates derivation, numerical substitutions, algebraic manipulations, and expressions
-
[21]
PHYSICAL_INTERPRETATION: Evaluates whether the model interprets the final result physically
-
[22]
step_evaluations
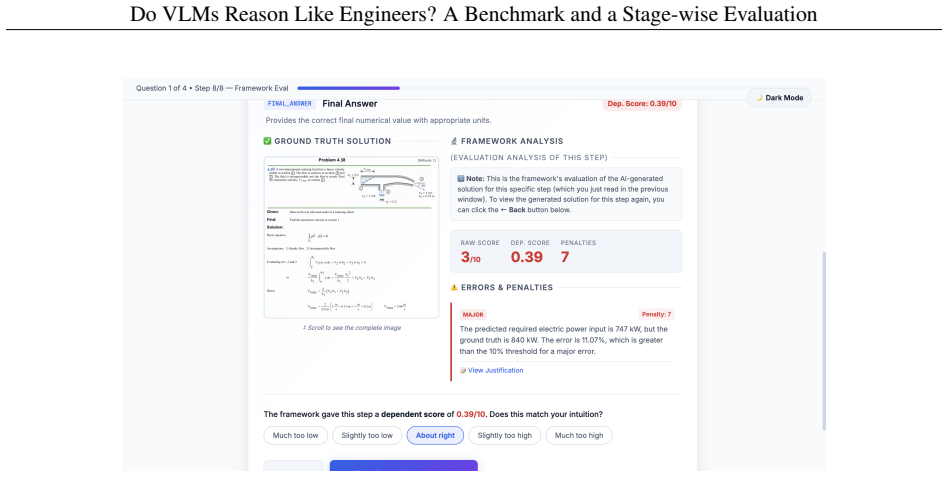
FINAL_ANSWER: Compares predicted answer with ground truth using strict numerical error thresholds. Compare the student's solution to the Ground Truth image provided. OUTPUT FORMAT: Your response MUST be a valid JSON object matching this exact structure: { "step_evaluations": [ { "step_name": "PROBLEM_CHARACTERIZATION", "score": <int between 0 and 10>, "re...
-
[23]
PHYSICS DOMAIN & PROBLEM TYPE - Is the correct branch of engineering/physics identified (e.g., heat transfer, fluid mechanics)? - Is the specific sub-topic correctly identified (e.g., forced vs natural convection)? - Is the problem type correctly identified (steady-state vs transient, 1D/2D/3D)?
-
[24]
GOVERNING PRINCIPLES - Are the relevant physical laws mentioned (conservation of mass/energy/momentum)? - Are the governing principles appropriate for this problem?
-
[25]
errors": [ {{
KEY VARIABLES & GEOMETRY - Are the important given quantities correctly identified? - Is it clear what quantity needs to be found? - Is the physical configuration and geometry correctly understood (pipe flow, cylinder, etc.)? --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1 & 2: Physics Domain, Type, & Principles | Criterion 3: Key...
-
[26]
VALIDITY & JUSTIFICATION - Is each assumption physically valid for this problem? - Is each assumption justified with a physical reason or standard practice? - Are any assumptions clearly wrong or too aggressive (e.g., removing essential physics)?
-
[27]
errors": [ {{
COMPLETENESS & CONSISTENCY - Are all necessary assumptions stated (steady-state, 1D, incompressible, etc.)? - Are assumptions consistent with information given in the problem and diagrams? - Are any assumptions contradicted by the problem statement? --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1: Validity & Justification | Criter...
-
[28]
DIMENSIONS & GEOMETRY - Are all dimensions correctly read from the diagram (lengths, radii, angles)? - Are geometric relationships (parallel, concentric) correctly identified?
-
[29]
BOUNDARY CONDITIONS & LOADING - Are applied forces, pressures, heat fluxes, or boundary temperatures correctly identified? - Are support conditions (fixed, pinned, free) correctly read? - Is flow direction or boundary layer type correctly noted from the visual?
-
[30]
errors": [ {{
MATERIALS & COORDINATES - Are different materials or regions properly recognized? - Is the spatial orientation correctly understood? - Is the coordinate system consistent with the diagram? --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1 & 3: Dimensions, Geometry & Coordinates | Criterion 2: Boundary Conditions & Loading | | :--- |...
-
[31]
GOVERNING EQUATION (Critical Axis) - Is the correct governing equation chosen for this physical system? - Is it the right form (differential vs integral, 1D vs 2D)? - If the governing equation is fundamentally wrong -> score = 0 immediately
-
[32]
BOUNDARY CONDITIONS & COORDINATES - Are the equations for boundary conditions correctly formulated? - Is the chosen coordinate system (Cartesian, cylindrical, spherical) appropriate? - Are vector quantities expressed correctly?
-
[33]
governing_equation_correct
JUSTIFICATION & SIMPLIFICATION - Are simplifying assumptions justified in the equation form (e.g., dropping transient term)? - Are there any invalid, applicability-exceeded, or dimensionally inconsistent equations? --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 2 & 3: BCs, Coordinates, & Simplifications | Criterion 1: Governing Equ...
-
[34]
LOGICAL VALIDITY & COMPLETENESS - Does each claim follow logically from the previous one? - Are there any non-sequiturs, circular arguments, or unjustified conclusions? - Are all necessary logical links present, or are there massive leaps? - Does the reasoning contribute meaningfully to solving the problem?
-
[35]
errors": [ {{
PHYSICS CAUSALITY & PROPORTIONALITY - Is the direction of physical causation correct (e.g., temperature gradient causes heat flow)? - Are proportional relationships stated correctly? - Do the logical claims align with physical reality? --- GRADING RUBRIC MATRIX (PENALTIES): 38 Do VLMs Reason Like Engineers? A Benchmark and a Stage-wise Evaluation | Severi...
-
[36]
RESULT & TREND INTERPRETATION - Does the model explain what the numerical result physically means? - Does the model correctly identify how the result depends on key parameters? - Are physical trends (increasing/decreasing with T, P, V) correct?
-
[37]
intense turbulent convection
BENCHMARKS & LIMITING CASES - Does the model check whether the answer magnitude is physically reasonable? - Is it compared against known limiting cases (e.g., as k->inf)? - Are engineering or practical implications discussed? --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1: Result & Trend | Criterion 2: Benchmarks & Limits | | :--...
-
[38]
- Calculate: error = |predicted - ground_truth| / |ground_truth| - Multiple values? Evaluate each
NUMERICAL CORRECTNESS (Primary) - Compare the predicted numerical value(s) with the ground truth. - Calculate: error = |predicted - ground_truth| / |ground_truth| - Multiple values? Evaluate each. The total penalty should reflect the overall accuracy. - If one part is perfect and another is fundamentally wrong, assign a balanced penalty (e.g., 5-7 points)...
-
[39]
UNITS & PRESENTATION - Are the correct SI or problem-specified units provided? - Is it clearly stated with reasonable significant figures?
-
[40]
predicted_values
COMPLETENESS & PHYSICAL POSSIBILITY - Are ALL parts/values asked for actually provided? - Is the result physically impossible? (Negative absolute temp, negative density, etc.) - Sign errors that reverse the physical meaning are MAJOR. --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1: Numerical Correctness | Criterion 2: Units & Pre...
-
[41]
boilerplate
REPETITION & RESTATEMENT - Does the solution unnecessarily restate the entire question before starting? - Does it repeat the same conclusion multiple times across different steps? - Are equations written out repeatedly without any new substitution or derivation? - CRITICAL: The solution is REQUIRED to follow a strict tagged format (e.g., ###### PROBLEM_CH...
-
[42]
As we can clearly see
FILLER TEXT & OVER-EXPLANATION - Is there excessive conversational filler ("As we can clearly see...", "It is important to note that...")? - Are trivial algebraic steps over-explained in paragraphs of text? - Could the solution be significantly shorter without losing any technical rigor? - Are there any extra assumptions, algebraic steps which are not act...
-
[43]
Find T and Q
ALL ASKED QUANTITIES - Does the solution compute every primary and secondary quantity requested? - If the question asks for multiple values (e.g., "Find T and Q"), are ALL of them computed?
-
[44]
SUB-QUESTIONS & SCOPE - If the question has parts (a), (b), (c), are ALL parts answered? - Does the solution address the full physically described scope (e.g., if there are two connected pipes, are both analyzed)?
-
[45]
comment on result
RELEVANT ANALYSIS & RESULTS - Are requested diagrams/plots mentioned or described? - Are final numerical answers clearly provided rather than just symbolic equations? --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1: Asked Quantities | Criterion 2 & 3: Scope & Analysis | | :--- | :---: | :--- | :--- | | MINOR | 2 | Missing units on...
-
[46]
- Efficiency of heat engines must be <= Carnot efficiency
SIGN CHECKS & LIMITS - Density, Mass, Absolute Temperature (> 0 K), Thermal conductivity, Viscosity must be positive. - Efficiency of heat engines must be <= Carnot efficiency. - Heat cannot spontaneously flow from cold to hot
-
[47]
- Stresses should not exceed ultimate strength of specified materials ridiculously
MAGNITUDE REASONABLENESS - Velocities should not exceed speed of light for non-relativistic problems. - Stresses should not exceed ultimate strength of specified materials ridiculously. - Pressures should be physically meaningful
-
[48]
violations
CONSERVATION LAWS - Mass, Energy, Momentum must be conserved. 47 Do VLMs Reason Like Engineers? A Benchmark and a Stage-wise Evaluation --- GRADING RUBRIC MATRIX (PENALTIES): | Severity | Points | Criterion 1: Signs & Limits | Criterion 2 & 3: Magnitudes & Conservation | | :--- | :---: | :--- | :--- | | MINOR | 2 | Small violation of an assumption boundar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.