SAD-GS: Learning Reliable 3D Semantic Gaussian Fields via Dynamic Geo-Semantic Anchoring
Pith reviewed 2026-06-30 07:06 UTC · model grok-4.3
The pith
SAD-GS resolves multi-view contradictions in 3D semantic Gaussian fields through dynamic geo-semantic anchoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
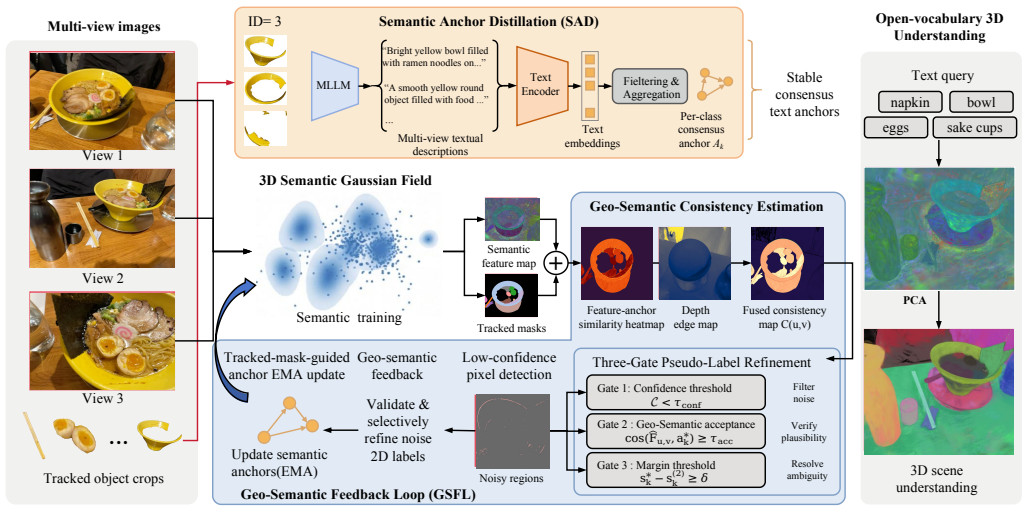
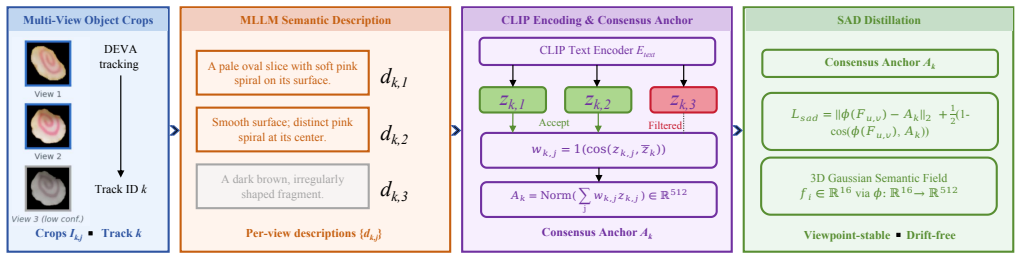
The central claim is that dynamic geo-semantic anchoring, implemented as Semantic Anchor Distillation that converts per-view visual embeddings into consensus text anchors for viewpoint-invariant identity plus a Geo-Semantic Feedback Loop that actively corrects tracker anomalies and spatial assignments via a three-gate update rule, enables reliable 3D semantic Gaussian field learning from unreliable multi-view 2D supervision, demonstrated by consistent top performance on LERF-OVS, 3D-OVS, and Mip-NeRF360.
What carries the argument
Dynamic geo-semantic anchoring via Semantic Anchor Distillation (SAD) that produces consensus text anchors and the Geo-Semantic Feedback Loop (GSFL) that filters anomalies with a conservative three-gate rule.
If this is right
- The 3D field can serve as an active supervisor that improves the quality of its own 2D training targets over time.
- Multi-view contradictions no longer force the Gaussian representation to average conflicting signals.
- Open-vocabulary localization and segmentation both improve when semantic identity is grounded in text consensus rather than raw per-view features.
- Conservative gating limits error propagation from any single faulty 2D mask.
Where Pith is reading between the lines
- The same anchoring-plus-feedback pattern could be applied to other 3D representations such as NeRFs or voxel grids when 2D labels are noisy.
- Iterative 2D-to-3D refinement loops may generalize beyond semantics to geometry or appearance consistency tasks.
- The approach suggests that explicit separation of consensus identity from view-dependent features is a reusable design choice for any multi-view learning setting.
Load-bearing premise
Distilling per-view visual embeddings into consensus text anchors produces a truly viewpoint-invariant semantic identity and the 3D field can identify and correct tracker anomalies without introducing new errors.
What would settle it
A controlled test in which extreme viewpoint changes still produce semantic identity drift in the distilled anchors, or in which the three-gate feedback loop measurably increases boundary leakage or identity switches on held-out scenes.
Figures


read the original abstract
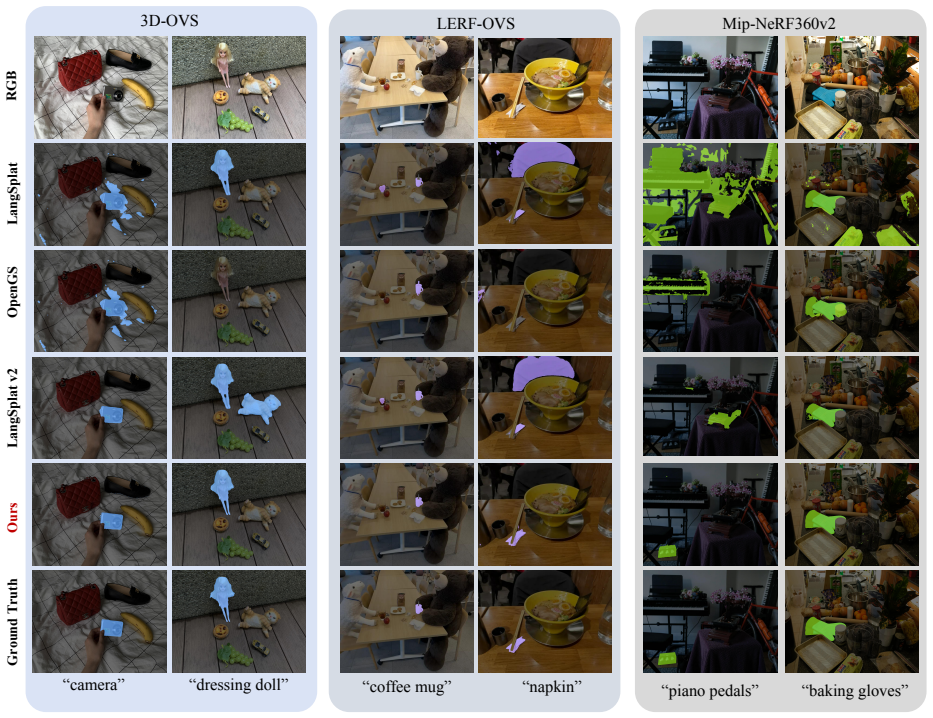
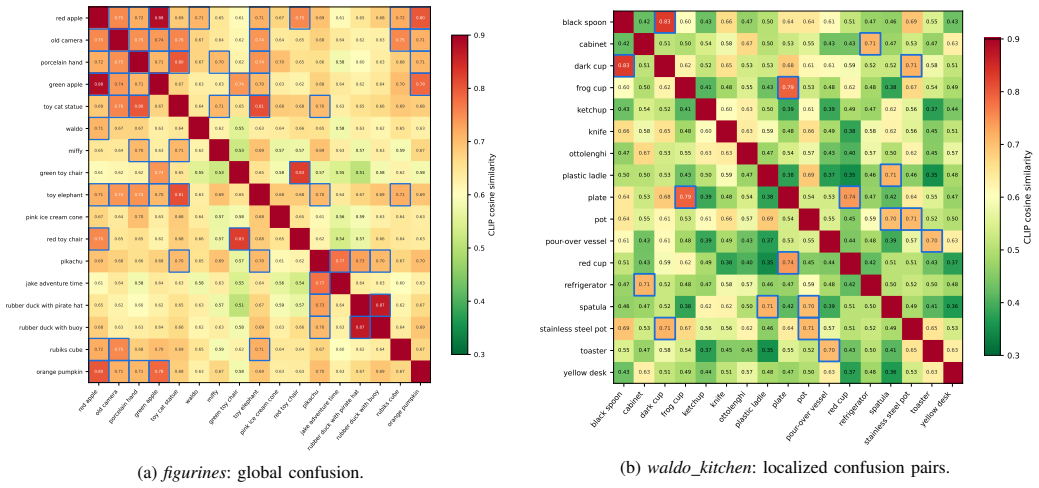
Open-vocabulary 3D semantic Gaussian field learning relies on multi-view 2D supervision, whose semantic targets and spatial assignments are often unreliable. Across varying viewpoints, view-dependent features cause semantic identity drift, while propagated tracker masks introduce boundary leakage and identity switches. Directly optimizing against these unreliable 2D targets forces the 3D representation to absorb multi-view contradictions, leading to severe error accumulation. To resolve this limitation, we propose SAD-GS, a framework for learning reliable 3D semantic Gaussian fields via dynamic geo-semantic anchoring. Specifically, Semantic Anchor Distillation (SAD) distills per-view visual embeddings into consensus text anchors to establish a viewpoint-invariant semantic identity. Concurrently, the Geo-Semantic Feedback Loop (GSFL) leverages the evolving 3D field to actively filter tracker anomalies and refine spatial mask assignments via a conservative three-gate update rule. Extensive evaluations on LERF-OVS, 3D-OVS, and Mip-NeRF360 show that SAD-GS consistently achieves the best overall performance in both open-vocabulary localization and semantic segmentation. These comprehensive improvements validate the effectiveness and robustness of dynamic geo-semantic anchoring for reliable 3D semantic Gaussian field learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SAD-GS for learning reliable 3D semantic Gaussian fields from multi-view 2D supervision. It introduces Semantic Anchor Distillation (SAD) to distill per-view visual embeddings into consensus text anchors for viewpoint-invariant semantic identities, and a Geo-Semantic Feedback Loop (GSFL) that uses the evolving 3D field with a conservative three-gate update rule to filter tracker anomalies and refine spatial mask assignments. Experiments on LERF-OVS, 3D-OVS, and Mip-NeRF360 are reported to show that SAD-GS achieves the best overall performance in open-vocabulary localization and semantic segmentation.
Significance. If the SAD consensus anchors and GSFL three-gate filtering deliver the claimed viewpoint-invariant identities and error-free corrections, the work would address a central practical limitation in distilling 2D open-vocabulary signals into consistent 3D fields. The dynamic geo-semantic anchoring idea is a targeted response to identity drift and boundary leakage; its adoption could improve robustness in downstream 3D scene understanding tasks.
major comments (2)
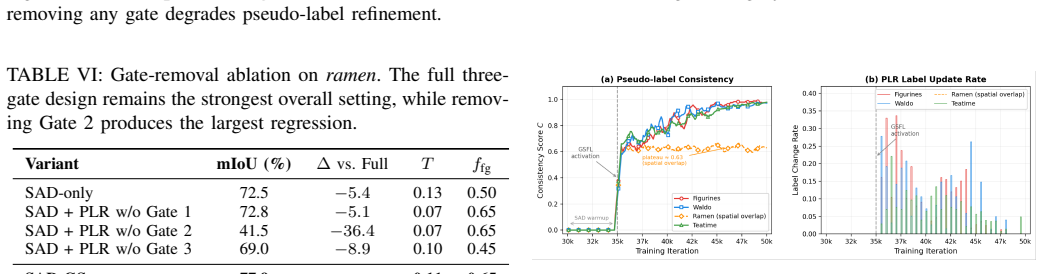
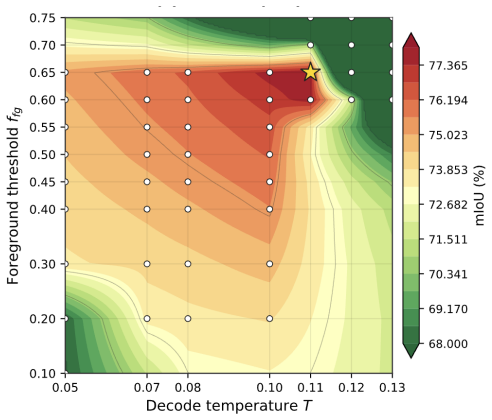
- [Abstract] The abstract states that SAD produces 'viewpoint-invariant semantic identity' and that GSFL 'actively filter[s] tracker anomalies' without propagating new errors, yet supplies no supporting measurements (e.g., per-object embedding variance across views, anomaly-filter precision/recall, or ablation removing the conservative gates). These quantities are load-bearing for the central claim that the framework resolves multi-view contradictions.
- [Abstract] The performance claim ('consistently achieves the best overall performance') is presented without reference to any table, figure, or quantitative comparison; the absence of these data prevents verification that gains arise from SAD and GSFL rather than implementation choices.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, clarifying that the full manuscript contains the requested quantitative support and ablations, while noting standard constraints on abstract length and referencing.
read point-by-point responses
-
Referee: [Abstract] The abstract states that SAD produces 'viewpoint-invariant semantic identity' and that GSFL 'actively filter[s] tracker anomalies' without propagating new errors, yet supplies no supporting measurements (e.g., per-object embedding variance across views, anomaly-filter precision/recall, or ablation removing the conservative gates). These quantities are load-bearing for the central claim that the framework resolves multi-view contradictions.
Authors: The abstract is a high-level summary. The full manuscript reports the requested measurements: per-object embedding variance across views to quantify viewpoint-invariance from SAD (Section 4.2), anomaly-filter precision/recall for GSFL, and an ablation removing the conservative three-gate rule (Table 4 and Section 4.3). These results demonstrate that multi-view contradictions are resolved without propagating new errors. We can revise the abstract to reference these specific results and sections if the editor prefers. revision: partial
-
Referee: [Abstract] The performance claim ('consistently achieves the best overall performance') is presented without reference to any table, figure, or quantitative comparison; the absence of these data prevents verification that gains arise from SAD and GSFL rather than implementation choices.
Authors: The abstract summarizes the outcome of the experiments. Quantitative comparisons appear in Tables 1–3 (main results on LERF-OVS, 3D-OVS, Mip-NeRF360) and Figures 4–6, with ablations in Section 4.3 isolating the contributions of SAD and GSFL. These tables and ablations confirm that the reported gains are attributable to the proposed components rather than other implementation details. Abstracts conventionally omit direct table citations to preserve brevity. revision: no
Circularity Check
No significant circularity detected
full rationale
The abstract and available text describe a forward pipeline (SAD distillation into consensus anchors + GSFL three-gate filtering) without equations, fitted parameters renamed as predictions, or self-citation chains that reduce any claimed result to its own inputs by construction. Performance is asserted via external benchmarks (LERF-OVS, 3D-OVS, Mip-NeRF360) rather than internal self-reference. No load-bearing derivation steps are present that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srini- vasan, and Peter Hedman. Mip-NeRF 360: Unbounded anti- aliased neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5470–5479, 2022. 5
2022
-
[4]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J ´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vision (ICCV), 2021. 1, 2
2021
-
[5]
Kangjie Chen, Bingquan Dai, Minghan Qin, Peihao Li, Haoqian Wang, and Weidong Wang. Sparselgs: Fast language gaus- sian splatting from sparse multi-view images.arXiv preprint arXiv:2412.07258, 2024. 6
-
[6]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting
Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21476–21485, 2024. 2
2024
-
[7]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean Conference on Computer Vision, pages 370–386. Springer, 2024. 2
2024
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 2
2024
-
[10]
Tracking anything with de- coupled video segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, and Joon-Young Lee. Tracking anything with de- coupled video segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1316– 1326, 2023. 1, 2, 4
2023
-
[11]
Pla: Language-driven open-vocabulary 3d scene understanding
Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Pla: Language-driven open-vocabulary 3d scene understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7010–7019, 2023. 2
2023
-
[12]
Lowis3d: Language-driven open-world instance-level 3d scene understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Lowis3d: Language-driven open-world instance-level 3d scene understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2
2024
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa De- hghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Scaling open-vocabulary image segmentation with image-level labels
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scaling open-vocabulary image segmentation with image-level labels. InEuropean conference on computer vision, pages 540–557. Springer, 2022. 2
2022
-
[15]
Jun Guo, Xiaojian Ma, Yue Fan, Huaping Liu, and Qing Li. Semantic gaussians: Open-vocabulary scene understanding with 3d gaussian splatting.arXiv preprint arXiv:2403.15624, 2024. 5
-
[16]
Scene-centric unsupervised panoptic segmenta- tion
Oliver Hahn, Yuanchen Peng, Rami Briq, Sven Behnke, and Juergen Gall. Scene-centric unsupervised panoptic segmenta- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[17]
Refersplat: Referring segmentation in 3d gaussian splatting
Shuting He, Guangquan Jie, Changshuo Wang, Yun Zhou, Shuming Hu, Guanbin Li, and Henghui Ding. Refersplat: Referring segmentation in 3d gaussian splatting. InProceedings of the 42nd International Conference on Machine Learning, pages 22456–22467. PMLR, 2025. 1, 2, 6
2025
-
[18]
Identity-aware language gaus- sian splatting for open-vocabulary 3D semantic segmentation
SungMin Jang and Wonjun Kim. Identity-aware language gaus- sian splatting for open-vocabulary 3D semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 20467–20476, 2025. 1, 2
2025
-
[19]
Open-vocabulary 3d semantic segmentation with foundation models
Li Jiang, Shaoshuai Shi, and Bernt Schiele. Open-vocabulary 3d semantic segmentation with foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21284–21294, 2024. 1, 2
2024
-
[20]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):1–14,
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):1–14,
-
[21]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19729–19739, 2023. 2, 5, 6
2023
-
[22]
Jun-Seong Kim, Tae-Hyun Nam, Gyeong-Moon Kim, and Jun- Young Choi. Dr. Splat: Directly referring 3D Gaussian splatting via direct language embedding registration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. arXiv:2502.16652. 1
-
[23]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023. 1, 2, 5
2023
-
[24]
Language-driven Semantic Segmentation
Boyi Li, Kilian Q Weinberger, Serge Belongie, Vladlen Koltun, and Ren ´e Ranftl. Language-driven semantic segmentation. arXiv preprint arXiv:2201.03546, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
4D LangSplat: 4D language gaussian splatting via multimodal large language models
Wanhua Li, Renping Zhou, Jiawei Zhou, Yingwei Song, Jo- hannes Herter, Minghan Qin, Gao Huang, and Hanspeter Pfister. 4D LangSplat: 4D language gaussian splatting via multimodal large language models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 22001–22011, 2025. 2
2025
-
[26]
Langsplatv2: High- dimensional 3d language gaussian splatting with 450+ fps.Ad- vances in Neural Information Processing Systems, 38:174306– 174330, 2026
Wanhua Li, Yujie Zhao, Minghan Qin, Yang Liu, Yuanhao Cai, Chuang Gan, and Hanspeter Pfister. Langsplatv2: High- dimensional 3d language gaussian splatting with 450+ fps.Ad- vances in Neural Information Processing Systems, 38:174306– 174330, 2026. 6, 7
2026
-
[27]
Guibiao Liao, Jiankun Li, Zhenyu Bao, Xiaoqing Ye, Jingdong Wang, Qing Li, and Kanglin Liu. Clip-gs: Clip-informed gaussian splatting for real-time and view-consistent 3d semantic understanding.arXiv preprint arXiv:2404.14249, 2024. 2
-
[28]
Weakly supervised 3d open-vocabulary segmenta- tion.Advances in Neural Information Processing Systems, 36: 53433–53456, 2023
Kunhao Liu, Fangneng Zhan, Jiahui Zhang, Muyu Xu, Yingchen Yu, Abdulmotaleb El Saddik, Christian Theobalt, Eric Xing, and Shijian Lu. Weakly supervised 3d open-vocabulary segmenta- tion.Advances in Neural Information Processing Systems, 36: 53433–53456, 2023. 2, 5
2023
-
[29]
3dgs-enhancer: En- hancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors.Advances in Neural Information Processing Systems, 37:133305–133327, 2024
Xi Liu, Chaoyi Zhou, and Siyu Huang. 3dgs-enhancer: En- hancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors.Advances in Neural Information Processing Systems, 37:133305–133327, 2024. 2
2024
-
[30]
Open3DIS: Open-vocabulary 3D instance segmentation with 2D mask guid- ance
Phuc Nguyen, Tuan Duc Ngo, Evangelos Kalogerakis, Chuang Gan, Anh Tran, Cuong Pham, and Khoi Nguyen. Open3DIS: Open-vocabulary 3D instance segmentation with 2D mask guid- ance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4018–4028,
-
[31]
Dinov2: Learning robust visual features without supervision.Transac- tions on Machine Learning Research Journal, pages 1–31, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transac- tions on Machine Learning Research Journal, pages 1–31, 2024. 2
2024
-
[32]
Open- Splat3D: Open-vocabulary 3D instance segmentation using gaussian splatting
Jens Piekenbrinck, Christian Schmidt, Alexander Hermans, Narunas Vaskevicius, Timm Linder, and Bastian Leibe. Open- Splat3D: Open-vocabulary 3D instance segmentation using gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Work- shops, pages 5285–5294, 2025. 1, 2
2025
-
[33]
Langsplat: 3d language gaussian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024. 1, 2, 3, 5, 6, 7
2024
-
[34]
GOI: Find 3D gaussians of interest with an optimizable open-vocabulary semantic-space hyperplane
Yansong Qu, Shaohui Dai, Xinyang Li, Jianghang Lin, Liu- juan Cao, Shengchuan Zhang, and Rongrong Ji. GOI: Find 3D gaussians of interest with an optimizable open-vocabulary semantic-space hyperplane. InProceedings of the 32nd ACM International Conference on Multimedia, pages 5328–5337,
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
-
[36]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R ¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll ´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. 1, 2
2024
-
[37]
Grounded sam: Assembling open- world models for diverse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded sam: Assembling open- world models for diverse visual tasks, 2024. 2
2024
-
[38]
Unscene3d: Unsupervised 3d instance segmentation for indoor scenes
David Rozenberszki, Or Litany, and Angela Dai. Unscene3d: Unsupervised 3d instance segmentation for indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19957–19967, 2024. 2
2024
-
[39]
Mask3d: Mask trans- former for 3d semantic instance segmentation
Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3d: Mask trans- former for 3d semantic instance segmentation. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8216–8223. IEEE, 2023. 2
2023
-
[40]
Superpoint transformer for 3d scene instance segmentation
Jiahao Sun, Chunmei Qing, Junpeng Tan, and Xiangmin Xu. Superpoint transformer for 3d scene instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2393–2401, 2023. 2
2023
-
[41]
Going denser with open- vocabulary part segmentation
Peize Sun, Shoufa Chen, Chenchen Zhu, Fanyi Xiao, Ping Luo, Saining Xie, and Zhicheng Yan. Going denser with open- vocabulary part segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15453– 15465, 2023. 2
2023
-
[42]
Hanchen Tai, Qingdong He, Jiangning Zhang, Yijie Qian, Zhenyu Zhang, Xiaobin Hu, Xiangtai Li, Yabiao Wang, and Yong Liu. Open-vocabulary sam3d: Towards training-free open-vocabulary 3d scene understanding.arXiv preprint arXiv:2405.15580, 2024. 2
-
[43]
CCL-LGS: Con- trastive codebook learning for 3D language gaussian splatting
Lei Tian, Xiaomin Li, Liqian Ma, Hao Yin, Zirui Zheng, Hefei Huang, Taiqing Li, Huchuan Lu, and Xu Jia. CCL-LGS: Con- trastive codebook learning for 3D language gaussian splatting. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9855–9864, 2025. 2
2025
-
[44]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source mul- timodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Use: Universal segment embeddings for open-vocabulary image segmentation
Xiaoqi Wang, Wenbin He, Xiwei Xuan, Clint Sebastian, Jorge Piazentin Ono, Xin Li, Sima Behpour, Thang Doan, Liang Gou, Han-Wei Shen, et al. Use: Universal segment embeddings for open-vocabulary image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4187–4196, 2024. 2
2024
-
[46]
Grit: A generative region- to-text transformer for object understanding
Jialian Wu, Jianfeng Wang, Zhengyuan Yang, Zhe Gan, Zicheng Liu, Junsong Yuan, and Lijuan Wang. Grit: A generative region- to-text transformer for object understanding. InEuropean Con- ference on Computer Vision, pages 207–224. Springer, 2024. 2
2024
-
[47]
Opengaussian: Towards point- level 3d gaussian-based open vocabulary understanding
Yanmin Wu, Jiarui Meng, Haijie Li, Chenming Wu, Yahao Shi, Xinhua Cheng, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, and Jian Zhang. Opengaussian: Towards point- level 3d gaussian-based open vocabulary understanding. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), pages 19114–19138, 2024. 1, 2, 6, 7
2024
-
[48]
Mutian Xu, Xingyilang Yin, Lingteng Qiu, Yang Liu, Xin Tong, and Xiaoguang Han. Sampro3d: Locating sam prompts in 3d for zero-shot scene segmentation.arXiv preprint arXiv:2311.17707,
-
[49]
Regionplc: Regional point-language contrastive learning for open-world 3d scene understanding
Jihan Yang, Runyu Ding, Weipeng Deng, Zhe Wang, and Xiaojuan Qi. Regionplc: Regional point-language contrastive learning for open-world 3d scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19823–19832, 2024. 2
2024
-
[50]
Gaus- sian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaus- sian grouping: Segment and edit anything in 3d scenes. In European Conference on Computer Vision, pages 162–179. Springer, 2024. 1, 6, 7
2024
-
[51]
Absgs: Recovering fine details in 3d gaussian splatting
Zongxin Ye, Wenyu Li, Sidun Liu, Peng Qiao, and Yong Dou. Absgs: Recovering fine details in 3d gaussian splatting. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 1053–1061, 2024. 2
2024
-
[52]
Sai3d: Segment any instance in 3d scenes
Yingda Yin, Yuzheng Liu, Yang Xiao, Daniel Cohen-Or, Jing- wei Huang, and Baoquan Chen. Sai3d: Segment any instance in 3d scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3292–3302,
-
[53]
Omniseg3d: Omniversal 3d seg- mentation via hierarchical contrastive learning
Haiyang Ying, Yixuan Yin, Jinzhi Zhang, Fan Wang, Tao Yu, Ruqi Huang, and Lu Fang. Omniseg3d: Omniversal 3d seg- mentation via hierarchical contrastive learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20612–20622, 2024. 2
2024
-
[54]
Mip-splatting: Alias-free 3d gaussian splatting
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19447–19456, 2024. 6
2024
-
[55]
Diffgs: Functional gaussian splatting diffusion.Advances in Neural Information Processing Systems, 37:37535–37560, 2024
Junsheng Zhou, Weiqi Zhang, and Yu-Shen Liu. Diffgs: Functional gaussian splatting diffusion.Advances in Neural Information Processing Systems, 37:37535–37560, 2024. 2
2024
-
[56]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test- time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding.International Journal of Computer Vision, 133(2):611–627, 2025
Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, and Mingyang Li. Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding.International Journal of Computer Vision, 133(2):611–627, 2025. 2
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.