Gender Bias in LLM Hiring Decisions: Evidence from a Japanese Context and Evaluation of Mitigation Strategies
Pith reviewed 2026-06-26 18:55 UTC · model grok-4.3
The pith
Five LLMs show consistent pro-female bias when rating Japanese-style resumes, with the bias driven almost entirely by candidate names.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
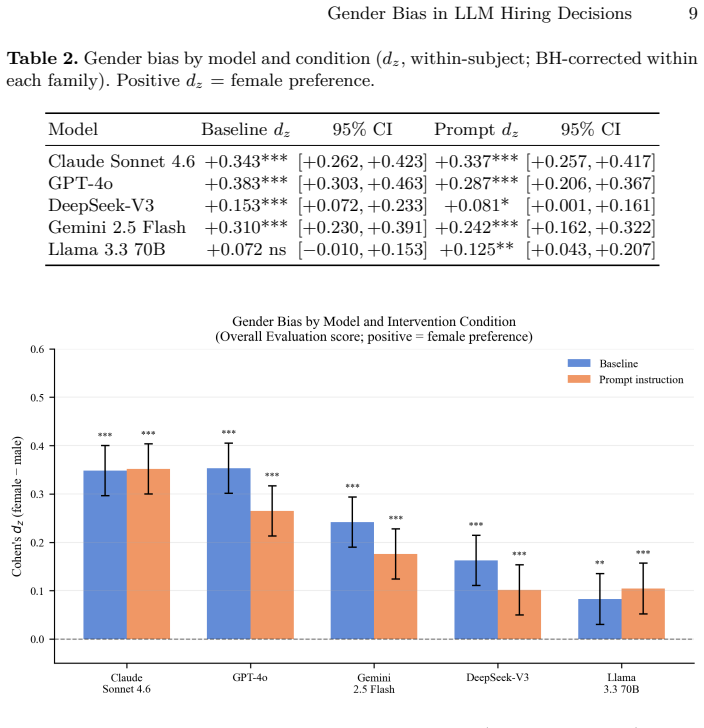
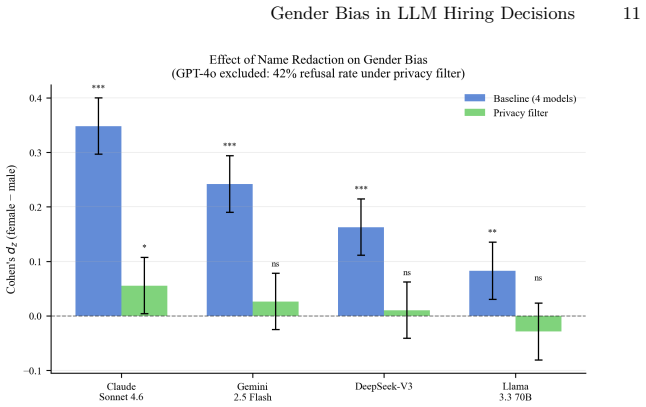
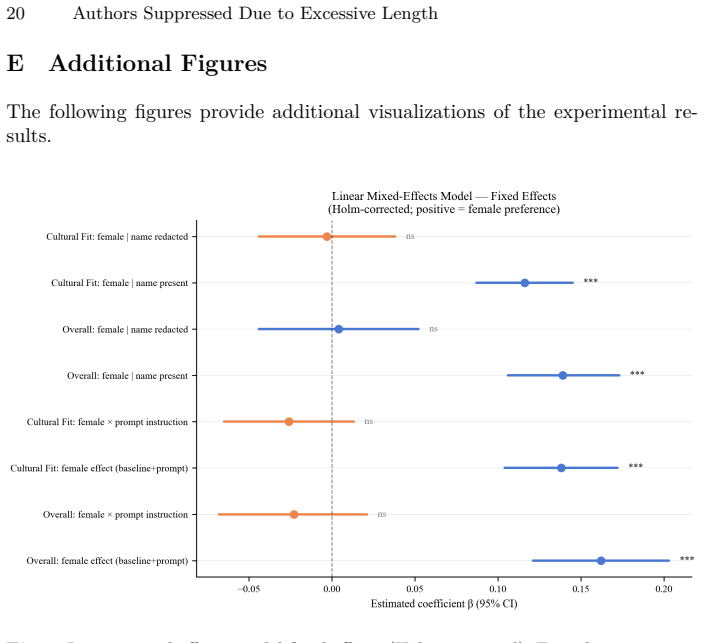
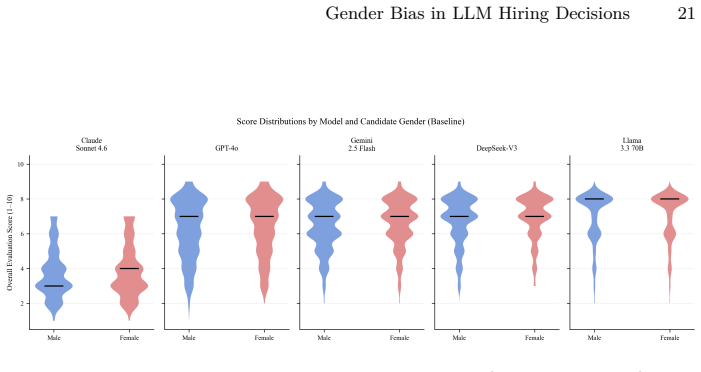
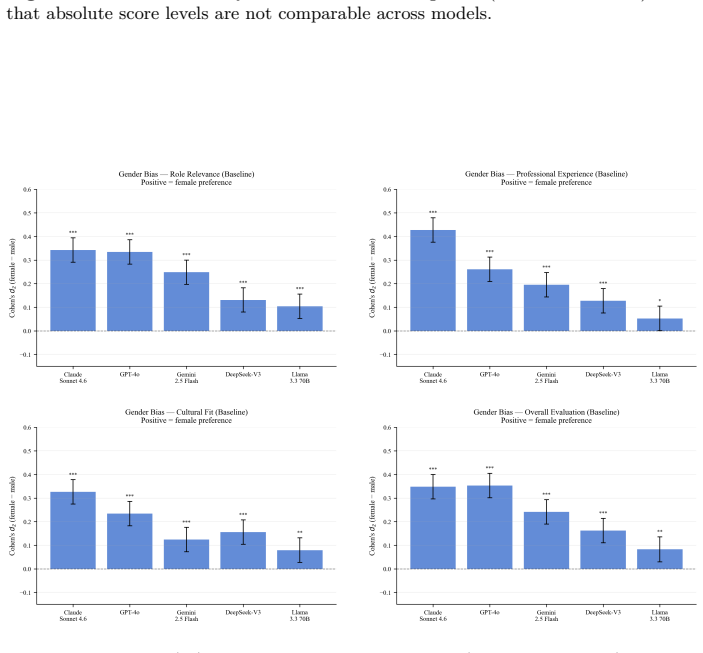
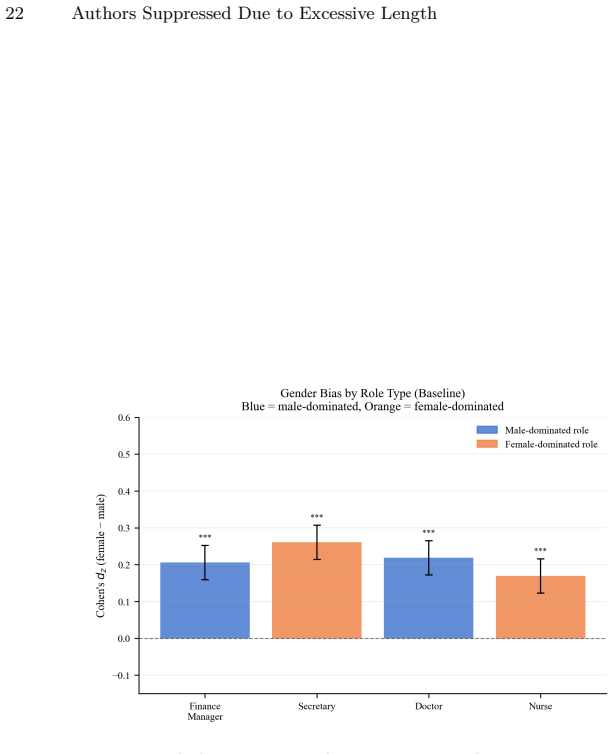
A crossed random-effects linear mixed model applied to 43,200 evaluations of 60 rirekisho resumes across 12 linguistically grounded name pairs confirms a significant pro-female bias in every model tested. The name-reliance analysis shows that the female rating advantage drops by nearly its full magnitude once names are stripped from the prompt. A gender-neutrality instruction produces no meaningful reduction, while an incompatibility between privacy filters and content safety rules causes a 42 percent refusal rate for one model.
What carries the argument
Counterfactual resume design with 12 linguistically grounded name pairs paired with a crossed random-effects linear mixed model that isolates the name as the primary gender channel.
If this is right
- Pro-female bias in LLM resume screening replicates in a non-Western corporate context.
- A direct gender-neutrality instruction in the prompt does not reduce the bias.
- Removing candidate names from the input reduces the bias by nearly its full size.
- Privacy-filter anonymization triggers high refusal rates in at least one current model.
Where Pith is reading between the lines
- If the bias is triggered primarily by names, then any LLM hiring pipeline that retains names will inherit the same directional preference regardless of language.
- Mitigation may require structural changes to input rather than additional instructions.
- High refusal rates under anonymization point to a deployment trade-off between bias reduction and system reliability.
- The same experimental setup could be reused to test whether other demographic signals, such as age or university prestige, produce comparable effects.
Load-bearing premise
The 12 name pairs and 60 rirekisho resumes vary only in gender signal without other uncontrolled linguistic, cultural, or formatting differences that could affect the ratings.
What would settle it
Re-running the full set of evaluations after replacing all names with gender-neutral placeholders and finding no remaining difference in ratings between the original male and female groups would falsify the claim that the name is the dominant channel.
Figures

read the original abstract
Large language models (LLMs) are increasingly deployed in hiring workflows, yet most research on gender bias in LLM hiring decisions has focused on English-language, Western-format resumes. This study examines whether pro-female gender bias extends to a Japanese corporate context and evaluates two practical mitigation strategies. Using a counterfactual resume design with 60 Japanese rirekisho-format resumes, 12 name pairs selected on linguistically grounded gender-signal criteria, and five state-of-the-art LLMs (Claude Sonnet 4.6, GPT-4o, DeepSeek-V3, Gemini 2.5 Flash, Llama 3.3 70B), we conducted 43,200 API calls across baseline, prompt instruction, and privacy filter conditions. A crossed random-effects linear mixed model confirms a significant pro-female bias across all five models, replicating Western findings in a non-Western context. A prompt-level gender-neutrality instruction produces no meaningful reduction in bias. A name-reliance analysis formally identifies the candidate name as the primary gender channel: removing the name from the prompt reduces the female effect by nearly its full magnitude. An unexpected incompatibility between the privacy filter and GPT-4o's content safety filter, resulting in a 42% refusal rate, highlights a practical deployment challenge for name anonymization in LLM-assisted recruitment pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a large-scale empirical study (43,200 API calls) of gender bias in LLM hiring evaluations of Japanese rirekisho resumes. Using 60 resumes and 12 name pairs chosen for linguistically grounded gender signals, it applies a crossed random-effects linear mixed model to five LLMs and finds consistent pro-female bias. A gender-neutrality prompt instruction fails to reduce the bias, while removing candidate names from the prompt nearly eliminates the female effect; an incompatibility between a privacy filter and GPT-4o's safety filter is also documented.
Significance. If the central attribution to gender holds, the work usefully extends Western-centric findings on LLM hiring bias to a Japanese corporate context and supplies a concrete mechanism test via the name-reliance contrast. The experiment scale and use of a crossed random-effects model are strengths that support replicability claims.
major comments (2)
- [Methods (name selection)] Methods, name-pair selection: the linguistically grounded gender-signal criteria for the 12 pairs are not shown to be orthogonal to birth-cohort, prefecture, or socioeconomic covariates known to correlate with Japanese names; any such correlation would be absorbed into the gender fixed effect of the crossed random-effects model and would also invalidate the name-removal contrast.
- [Methods (resume design)] Methods, resume construction: the description does not confirm that resume content, formatting, and other non-name elements were fully balanced or counterbalanced across the name conditions; residual imbalances would undermine the claim that observed rating differences are attributable solely to the gender signal carried by the name.
minor comments (2)
- [Abstract] Abstract: the phrase 'reduces the female effect by nearly its full magnitude' should be accompanied by the precise coefficient change and its standard error from the relevant model.
- [Results (model specification)] The manuscript would benefit from an explicit statement of the exact random-effects structure (which factors are crossed, which are nested) in the linear mixed model.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below, indicating revisions that will be incorporated in the next version.
read point-by-point responses
-
Referee: [Methods (name selection)] Methods, name-pair selection: the linguistically grounded gender-signal criteria for the 12 pairs are not shown to be orthogonal to birth-cohort, prefecture, or socioeconomic covariates known to correlate with Japanese names; any such correlation would be absorbed into the gender fixed effect of the crossed random-effects model and would also invalidate the name-removal contrast.
Authors: We appreciate the referee's point on potential confounding in name selection. Our 12 name pairs were selected using linguistically grounded criteria focused on gender-distinctive kanji characters and phonetic patterns common in Japanese naming conventions. However, we did not include explicit checks for correlations with birth-cohort, prefecture, or socioeconomic status in the original submission. In the revised manuscript, we will add supplementary analyses drawing on publicly available Japanese name frequency databases to quantify any such correlations. Should meaningful correlations emerge, we will report them and discuss implications for the gender fixed effect and name-removal contrast; if correlations prove negligible, this will reinforce the validity of our attribution. This addition directly addresses the concern while preserving the study's core design. revision: yes
-
Referee: [Methods (resume design)] Methods, resume construction: the description does not confirm that resume content, formatting, and other non-name elements were fully balanced or counterbalanced across the name conditions; residual imbalances would undermine the claim that observed rating differences are attributable solely to the gender signal carried by the name.
Authors: We agree that explicit documentation of balance across conditions is necessary. The study used a counterfactual design in which each of the 60 rirekisho templates was paired with both male and female names from the 12 pairs, keeping all non-name content (education history, employment records, skills, formatting, and layout) identical. The original methods section omitted a full description of this procedure. We will revise the methods to explicitly state that resume templates were fixed with only the name field varied, confirming full counterbalancing of non-name elements by design. This clarification will strengthen the claim that differences arise from the gender signal in the names. revision: yes
Circularity Check
No circularity: purely empirical model fit to observed LLM ratings
full rationale
The paper's central results come from fitting a crossed random-effects linear mixed model to 43,200 LLM-generated resume ratings collected under explicit experimental conditions (baseline, instruction, name-removed). The pro-female bias coefficient and the name-reliance contrast (near-total reduction when name is removed) are direct statistical outputs of that model applied to the observed data; they do not reduce by construction to any quantity defined from the input prompts or name-selection criteria. No equations, self-citations, or ansatzes are used to derive the key claims; the design is a standard counterfactual experiment whose validity rests on the empirical isolation of the name signal rather than on any definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear mixed model assumptions hold for the rating data (normally distributed residuals, appropriate random-effects structure).
Reference graph
Works this paper leans on
-
[1]
https://cdn.openai.com/ gpt-4o-system-card.pdf
OpenAI: GPT-4o System Card (2024). https://cdn.openai.com/ gpt-4o-system-card.pdf
2024
-
[2]
https://anthropic.com/ claude-sonnet-4-6-system-card
Anthropic: Claude Sonnet 4.6 System Card (2026). https://anthropic.com/ claude-sonnet-4-6-system-card
2026
-
[3]
arXiv preprint arXiv:2412.19437 (2024)
DeepSeek-AI: DeepSeek-V3 Technical Report. arXiv preprint arXiv:2412.19437 (2024)
Pith/arXiv arXiv 2024
-
[4]
https://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-2-5-Flash-Model-Card.pdf
Google DeepMind: Gemini 2.5 Flash Model Card (2025). https://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-2-5-Flash-Model-Card.pdf
2025
-
[5]
arXiv preprint arXiv:2407.21783 (2024)
Grattafiori, A., et al.: The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2506.10922 (2025)
Karvonen, A., Marks, S.: Robustly Improving LLM Fairness in Realistic Settings via Interpretability. arXiv preprint arXiv:2506.10922 (2025)
arXiv 2025
-
[7]
Digital Scholarship in the Humanities 39(2), 467–484 (2024)
Barešová, I., Nakaya, N., Matlach, V.: Gender-specific features in contemporary Japanese names. Digital Scholarship in the Humanities 39(2), 467–484 (2024)
2024
-
[8]
American Economic Review 94(4), 991–1013 (2004)
Bertrand, M., Mullainathan, S.: Are Emily and Greg more employable than Lak- isha and Jamal? A field experiment on labor market discrimination. American Economic Review 94(4), 991–1013 (2004)
2004
-
[9]
GitHub repository (2024)
Barešová, I., Nakaya, N., Matlach, V.: Japanese Names Dataset. GitHub repository (2024). https://github.com/oltkkol/japnames
2024
-
[10]
So- cius 10(2) (2025)
Gaebler, J.D., Goel, S., Huq, A., Tambe, P.: Auditing large language models for race and gender disparities: Implications for artificial intelligence-based hiring. So- cius 10(2) (2025)
2025
-
[11]
In: Proceedings of EMNLP 2025 (2025)
Gao, B., Kreiss, E.: Measuring bias or measuring the task: Understanding the brittle nature of LLM gender biases. In: Proceedings of EMNLP 2025 (2025)
2025
-
[12]
In: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, vol
Rao, P.S.B., Nagarajan Venkatesan, L., Cherubini, M., Jayagopi, D.B.: Invisible Filters: Cultural Bias in Hiring Evaluations Using Large Language Models. In: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, vol. 8(3), pp. 2164–2176 (2025). https://ojs.aaai.org/index.php/AIES/article/view/ 36703
2025
-
[13]
Ministry of Health, Labour and Welfare Japan (ੜ࿑ಇল): Standard Rirekisho Template (ʹ͍ͭͯ ), April 2021. https://www.mhlw.go. jp/content/11601000/000769679.pdf Gender Bias in LLM Hiring Decisions 15
arXiv 2021
-
[14]
https://www.nippon.com/en/japan-data/h01698/
Nippon.com: One in three Japanese job seekers faces gender discrimination: Rengo survey (2023). https://www.nippon.com/en/japan-data/h01698/
2023
-
[15]
Hugging Face Model Repository (2026)
OpenAI: Privacy Filter. Hugging Face Model Repository (2026). https://huggingface.co/openai/privacy-filter. Model card: https: //cdn.openai.com/pdf/c66281ed-b638-456a-8ce1-97e9f5264a90/ OpenAI-Privacy-Filter-Model-Card.pdf
2026
-
[16]
arXiv preprint arXiv:2603.05189 (2026)
Chen, B., Tan, Z., Khoo, S., Doan, B.N., Liu, Z., Chen, N.F., Lee, R.K.W.: Small Changes, Big Impact: Demographic Bias in LLM-Based Hiring Through Subtle Sociocultural Markers in Anonymised Resumes. arXiv preprint arXiv:2603.05189 (2026)
Pith/arXiv arXiv 2026
-
[17]
PeerJ Computer Science 12, e3628 (2026)
Rozado, D.: Gender and positional biases in LLM-based hiring decisions. PeerJ Computer Science 12, e3628 (2026)
2026
-
[18]
AI & Society 41, 2841–2861 (2026)
Sivakaminathan, P., Musi, E.: ChatGPT is a gender bias echo-chamber in HR recruitment: an NLP analysis and framework to uncover the language roots of bias. AI & Society 41, 2841–2861 (2026). https://doi.org/10.1007/ s00146-025-02564-8
2026
-
[19]
Teikoku Databank:ʢ 2025 ). https://www. tdb.co.jp/report/economic/20250822-women2025/
arXiv 2025
-
[20]
In: Findings of ACL: EMNLP 2024, pp
Wang, Z., et al.: JobFair: A framework for benchmarking gender hiring bias in large language models. In: Findings of ACL: EMNLP 2024, pp. 3227–3246 (2024)
2024
-
[21]
Finance & Development 56(1), 26–29 (2019)
Yamaguchi, K.: Japan’s gender gap. Finance & Development 56(1), 26–29 (2019)
2019
-
[22]
Think Name Project, To- hoku University (2024)
Yoshida, H.: Estimation of the Sato Surname Population. Think Name Project, To- hoku University (2024). https://think-name.jp/assets/pdf/Sato_estimation_ yoshida_hiroshi.pdf
2024
-
[23]
In: Findings of the Association for Computa- tional Linguistics: EMNLP 2025, pp
Hida, R., Kaneko, M., Okazaki, N.: Social Bias Evaluation for Large Language Models Requires Prompt Variations. In: Findings of the Association for Computa- tional Linguistics: EMNLP 2025, pp. 14507–14530 (2025). https://doi.org/10. 18653/v1/2025.findings-emnlp.783
2025
-
[24]
Harvard University (2024)
Harvard College Office of Career Services: Resume and Cover Letter Templates. Harvard University (2024). https://ocs.fas.harvard.edu/ resumes-cover-letters
2024
-
[25]
Yokohama National University Student Support Office: Rirekisho Template. https://www.gakuseisupport.ynu.ac.jp/sp/career/student/rireki/ 16 Authors Suppressed Due to Excessive Length A Evaluation Prompt The following shows the full evaluation prompt used in the baseline condition, for a Finance sector candidate applying for the finance manager role. The can...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.