Stationary Robust Mean-Field Games under Model Mismatches
Pith reviewed 2026-06-26 10:48 UTC · model grok-4.3
The pith
A mean-field game framework incorporates distributional model uncertainty into population dynamics and proves stationary equilibria exist via a contractive Bellman operator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that embedding distributional robustness into the population-coupled dynamics produces a contractive Bellman operator; this operator enables both a fixed-point argument establishing existence of a stationary robust mean-field equilibrium and an algorithm with convergence guarantees, while also delivering explicit non-asymptotic error bounds showing that the mean-field policy induces approximate equilibrium behavior in finite populations whose ambiguity sets depend on the empirical distribution.
What carries the argument
The contractive robust Bellman operator that folds an uncertainty set of transition models into the population-coupled dynamics and supports the fixed-point existence argument.
If this is right
- The mean-field equilibrium policy induces approximate equilibrium behavior in the corresponding finite-population robust game as population size grows.
- Explicit non-asymptotic error bounds hold between the mean-field solution and the finite-population game under the contractive regime.
- A concrete algorithm computes the equilibrium with provable convergence guarantees.
- Robustness to worst-case models drawn from the ambiguity set is achieved in the infinite-horizon stationary setting.
Where Pith is reading between the lines
- The contraction condition could be checked in specific application domains to decide whether the error bounds are usable in practice.
- The mean-field reduction might allow robust policies trained at infinite population size to be deployed directly in moderately large finite teams without retraining.
- The same fixed-point structure might extend to other forms of distributional uncertainty beyond the transition model.
Load-bearing premise
The robust dynamics must satisfy a contractive regime that renders the Bellman operator contractive.
What would settle it
A concrete counterexample in which the Bellman operator fails to be contractive under the paper's uncertainty sets would falsify both the existence proof and the non-asymptotic error bounds.
Figures
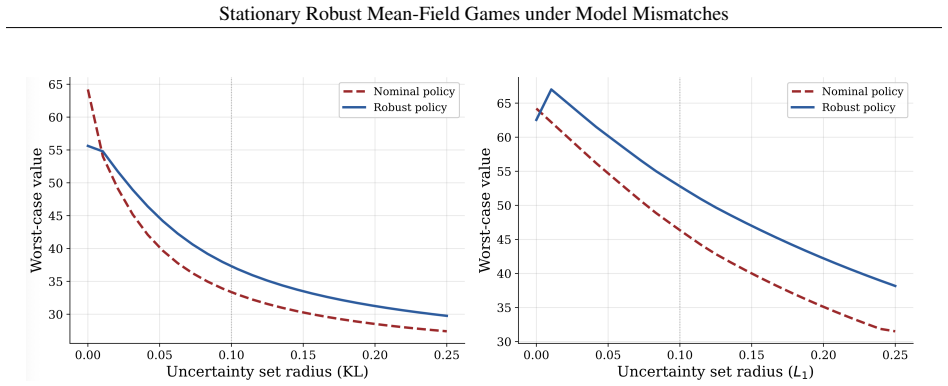
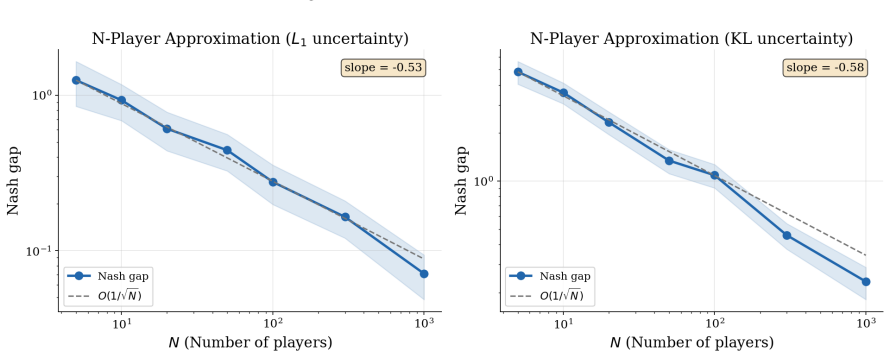
read the original abstract
Deploying multi-agent reinforcement learning (MARL) in the real world is often limited by model mismatches between the training simulators and the true environment, which could be further amplified through strategic interactions and result in severe performance degradation upon deployment. Distributional robustness offers a principled response by optimizing policies against worst-case transition models drawn from an uncertainty set, but standard robust MARL frameworks become increasingly intractable as the number of agents grows. This paper develops an infinite-horizon, stationary mean-field game framework that incorporates distributional model uncertainty directly into the population-coupled dynamics. We establish a robust dynamic programming principle with a contractive Bellman operator and prove the existence of a stationary robust mean-field equilibrium via a fixed-point argument. We further develop the first concrete algorithm with convergence guarantees. We then connect the mean-field solution to a finite-population robust game whose ambiguity sets depend on the empirical distribution, showing that the mean-field equilibrium policy induces approximate equilibrium behavior as the population size increases. Under a contractive robust-dynamics regime, we further obtain explicit non-asymptotic error bounds. Numerical experiments further illustrate the qualitative and quantitative impact of robustness under multiple uncertainty models, validating our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops an infinite-horizon stationary mean-field game framework for robust multi-agent RL that incorporates distributional model uncertainty into population-coupled dynamics. It claims to establish a robust dynamic programming principle via a contractive Bellman operator, prove existence of a stationary robust mean-field equilibrium by fixed-point argument, provide the first algorithm with convergence guarantees, connect the mean-field solution to finite-population robust games with empirical-distribution-dependent ambiguity sets, and derive explicit non-asymptotic error bounds under a contractive robust-dynamics regime. Numerical experiments illustrate robustness effects under multiple uncertainty models.
Significance. If the central claims hold, the work would provide a scalable approach to distributional robustness in large-population MARL with explicit approximation guarantees between mean-field and finite-population equilibria. The combination of a contractive operator for existence, an algorithm with convergence, and non-asymptotic bounds would be a notable technical contribution in robust mean-field games.
major comments (1)
- [Abstract and assumptions section] The contractive robust-dynamics regime is invoked as the key assumption enabling the contractive Bellman operator, the fixed-point existence argument, algorithm convergence, and the non-asymptotic error bounds for the finite-population approximation (abstract, final paragraph). No explicit modulus of contraction, no sufficient conditions on the ambiguity sets or transition kernels, and no verification that the numerical experiments operate inside this regime are supplied; without these the fixed-point argument and error bounds cannot be checked and the mean-field to finite-population connection remains unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comment, which highlights the need for greater explicitness around our key assumption. We address it below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract and assumptions section] The contractive robust-dynamics regime is invoked as the key assumption enabling the contractive Bellman operator, the fixed-point existence argument, algorithm convergence, and the non-asymptotic error bounds for the finite-population approximation (abstract, final paragraph). No explicit modulus of contraction, no sufficient conditions on the ambiguity sets or transition kernels, and no verification that the numerical experiments operate inside this regime are supplied; without these the fixed-point argument and error bounds cannot be checked and the mean-field to finite-population connection remains unsupported.
Authors: We agree that the contractive robust-dynamics regime must be characterized more explicitly for the claims to be fully verifiable. In the revised version we will add a new subsection (likely in Section 3 or 4) that (i) states an explicit modulus of contraction for the robust Bellman operator, (ii) supplies sufficient conditions on the ambiguity sets and transition kernels that guarantee this modulus (e.g., via a uniform Lipschitz bound on the worst-case transition and a contraction factor derived from the discount and the radius of the ambiguity set), and (iii) numerically verifies that the parameter choices in the experiments satisfy the regime (by reporting the computed contraction modulus for each uncertainty model). These additions will make the fixed-point argument, algorithm convergence, and finite-population bounds directly checkable. revision: yes
Circularity Check
No circularity; standard contraction mapping and fixed-point arguments
full rationale
The derivation chain relies on establishing a contractive Bellman operator under an explicit contractive robust-dynamics regime assumption, then applying a standard fixed-point theorem for existence of the stationary robust mean-field equilibrium. The algorithm convergence and non-asymptotic error bounds are derived directly from the contraction property. These steps use textbook techniques from robust MDPs and mean-field games; none of the results are defined in terms of themselves, no parameters are fitted to data and relabeled as predictions, and no self-citations serve as load-bearing premises. The abstract and claims contain no self-definitional reductions or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Robust Bellman operator is contractive
- standard math Fixed-point theorem applies to the robust operator
Reference graph
Works this paper leans on
-
[1]
The Limits of Transfer Reinforcement Learning with Latent Low-rank Structure , author=
-
[2]
Mathematics of Operations Research , year=
On the convex formulations of robust Markov decision processes , author=. Mathematics of Operations Research , year=
-
[3]
Offline multitask representation learning for reinforcement learning , author=
-
[4]
IEEE Transactions on Intelligent Vehicles , volume=
Robust multi-agent reinforcement learning method based on adversarial domain randomization for real-world dual-uav cooperation , author=. IEEE Transactions on Intelligent Vehicles , volume=. 2023 , publisher=
2023
-
[5]
Proceedings of the AAAI conference on artificial intelligence , volume=
Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[6]
2009 , publisher=
Stochastic approximation: a dynamical systems viewpoint , author=. 2009 , publisher=
2009
-
[7]
The Fourteenth International Conference on Learning Representations , year=
Sample-Efficient Distributionally Robust Multi-Agent Reinforcement Learning via Online Interaction , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
environment , volume=
A survey of POMDP solution techniques , author=. environment , volume=
-
[9]
2018 , organization=
Concentration bounds for two time scale stochastic approximation , author=. 2018 , organization=
2018
-
[10]
The International Journal of Robotics Research , volume=
Reinforcement Learning in Robotics: A Survey , author=. The International Journal of Robotics Research , volume=. 2013 , publisher=
2013
-
[11]
arXiv preprint arXiv:1712.09652 , year=
On convergence of some gradient-based temporal-differences algorithms for off-policy learning , author=. arXiv preprint arXiv:1712.09652 , year=
-
[12]
Two time-scale stochastic approximation with controlled
Karmakar, Prasenjit and Bhatnagar, Shalabh , journal=. Two time-scale stochastic approximation with controlled. 2018 , publisher=
2018
-
[13]
Finite sample analysis of the
Wang, Yue and Chen, Wei and Liu, Yuting and Ma, Zhi-Ming and Liu, Tie-Yan , booktitle=nips, pages=. Finite sample analysis of the
-
[14]
, author=
Finite-Sample Analysis of Proximal Gradient TD Algorithms. , author=. 2015 , organization=
2015
-
[15]
Neural temporal-difference learning converges to global optima , author=
-
[16]
Spider: Near-optimal non-convex optimization via stochastic path-integrated differential estimator , author=
-
[17]
Methods for Machine Learning , author=
Lectures on Optimization. Methods for Machine Learning , author=. H. Milton Stewart School of Industrial and Systems Engineering, Georgia Institute of Technology, Atlanta, GA , year=
-
[18]
Reshaped wirtinger flow for solving quadratic system of equations , author=
-
[19]
Finite-sample analysis of
Wang, Yue and Zou, Shaofeng , booktitle=uai, pages=. Finite-sample analysis of. 2020 , organization=
2020
-
[20]
The Annals of Applied Probability , volume=
Convergence rate of linear two-time-scale stochastic approximation , author=. The Annals of Applied Probability , volume=. 2004 , publisher=
2004
-
[21]
The Annals of Applied Probability , volume=
Convergence rate and averaging of nonlinear two-time-scale stochastic approximation algorithms , author=. The Annals of Applied Probability , volume=. 2006 , publisher=
2006
-
[22]
arXiv preprint arXiv:2011.01868 , year=
Nonlinear Two-Time-Scale Stochastic Approximation: Convergence and Finite-Time Performance , author=. arXiv preprint arXiv:2011.01868 , year=
arXiv 2011
-
[23]
2021 , organization=
Sample complexity bounds for two timescale value-based reinforcement learning algorithms , author=. 2021 , organization=
2021
-
[24]
Finite time analysis of linear two-timescale stochastic approximation with
Kaledin, Maxim and Moulines, Eric and Naumov, Alexey and Tadic, Vladislav and Wai, Hoi-To , booktitle=colt, pages=. Finite time analysis of linear two-timescale stochastic approximation with. 2020 , organization=
2020
-
[25]
Seminaire de probabilites XXXIII , pages=
Dynamics of stochastic approximation algorithms , author=. Seminaire de probabilites XXXIII , pages=. 1999 , publisher=
1999
-
[26]
2003 , publisher=
Stochastic approximation and recursive algorithms and applications , author=. 2003 , publisher=
2003
-
[27]
Actor-critic algorithms , author=
-
[28]
Neurocomputing , volume=
Natural actor-critic , author=. Neurocomputing , volume=. 2008 , publisher=
2008
-
[29]
A natural policy gradient , author=
-
[30]
Automatica , volume=
Natural actor--critic algorithms , author=. Automatica , volume=. 2009 , publisher=
2009
-
[31]
Provably global convergence of actor-critic: A case for linear quadratic regulator with ergodic cost , author=
-
[32]
arXiv preprint arXiv:1910.08412 , year=
On the sample complexity of actor-critic method for reinforcement learning with function approximation , author=. arXiv preprint arXiv:1910.08412 , year=
arXiv 1910
-
[33]
Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=
When is Mean-Field Reinforcement Learning Tractable and Relevant? , author=. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[34]
Propagation of chaos: a review of models, methods and applications. I. Models and methods , author=. arXiv preprint arXiv:2203.00446 , year=
-
[35]
On the finite-time convergence of actor-critic algorithm , author=. Proc. Optimization Foundations for Reinforcement Learning Workshop at Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[36]
arXiv preprint arXiv:2005.03557 , year=
Non-asymptotic Convergence Analysis of Two Time-scale (Natural) Actor-Critic Algorithms , author=. arXiv preprint arXiv:2005.03557 , year=
arXiv 2005
-
[37]
1995 , publisher=
Archibald, TW and McKinnon, KIM and Thomas, LC , journal=. 1995 , publisher=
1995
-
[38]
Brockman, Greg and Cheung, Vicki and Pettersson, Ludwig and Schneider, Jonas and Schulman, John and Tang, Jie and Zaremba, Wojciech , journal=
-
[39]
Systems & Control Letters , volume=
Stochastic approximation with two time scales , author=. Systems & Control Letters , volume=. 1997 , publisher=
1997
-
[40]
Proceedings of the 2004 American Control Conference , volume=
Almost sure convergence of two time-scale stochastic approximation algorithms , author=. Proceedings of the 2004 American Control Conference , volume=. 2004 , organization=
2004
-
[41]
Improving sample complexity bounds for (natural) actor-critic algorithms , author=
-
[42]
A tale of two-timescale reinforcement learning with the tightest finite-time bound , pages =
Dalal, Gal and Sz. A tale of two-timescale reinforcement learning with the tightest finite-time bound , pages =
-
[43]
SpiderBoost and momentum: Faster variance reduction algorithms , author=
-
[44]
Convergent temporal-difference learning with arbitrary smooth function approximation , author=
-
[45]
Finite-Sample Analysis of Decentralized Temporal-Difference Learning with Linear Function Approximation , author=
-
[46]
arXiv preprint arXiv:1906.01786 , year=
Global optimality guarantees for policy gradient methods , author=. arXiv preprint arXiv:1906.01786 , year=
arXiv 1906
-
[47]
Journal of Machine Learning Research , volume=
On the theory of policy gradient methods: Optimality, approximation, and distribution shift , author=. Journal of Machine Learning Research , volume=
-
[48]
2020 , organization=
On the global convergence rates of softmax policy gradient methods , author=. 2020 , organization=
2020
-
[49]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[50]
Variance-Reduced Off-Policy
Ma, Shaocong and Zhou, Yi and Zou, Shaofeng , booktitle=nipsnew, volume=. Variance-Reduced Off-Policy
-
[51]
Variance reduced policy evaluation with smooth function approximation , author=
-
[52]
arXiv preprint arXiv:2110.03239 , year=
Understanding domain randomization for sim-to-real transfer , author=. arXiv preprint arXiv:2110.03239 , year=
-
[53]
A convergent
Sutton, Richard S and Szepesv. A convergent. 2008 , publisher=
2008
-
[54]
Spectral Normalization for Generative Adversarial Networks , author=. Proc. International Conference on Learning Representations (ICLR) , year=
-
[55]
arXiv preprint arXiv:1709.01953 , year=
Implicit regularization in deep learning , author=. arXiv preprint arXiv:1709.01953 , year=
-
[56]
2019 , organization=
Gradient descent finds global minima of deep neural networks , author=. 2019 , organization=
2019
-
[57]
Ma, Shaocong and Zhou, Yi and Zou, Shaofeng , booktitle=. Greedy-
-
[58]
Sample complexity of asynchronous
Li, Gen and Wei, Yuting and Chi, Yuejie and Gu, Yuantao and Chen, Yuxin , booktitle=nipsnew, year=. Sample complexity of asynchronous
-
[59]
Mathematics of Operations Research , volume=
Robust dynamic programming , author=. Mathematics of Operations Research , volume=. 2005 , publisher=
2005
-
[60]
Reinforcement learning under model mismatch , author=
-
[61]
arXiv preprint arXiv:2502.08259 , year=
Balancing optimism and pessimism in offline-to-online learning , author=. arXiv preprint arXiv:2502.08259 , year=
-
[62]
Solving robust Markov decision processes: Generic, reliable, efficient , author=
-
[63]
Wiesemann, Wolfram and Kuhn, Daniel and Rustem, Ber. Robust. Mathematics of Operations Research , volume=. 2013 , publisher=
2013
-
[64]
1973 , publisher=
Satia, Jay K and Lave Jr, Roy E , journal=. 1973 , publisher=
1973
-
[65]
arXiv preprint arXiv:2008.01825 , year=
Robust Reinforcement Learning using Adversarial Populations , author=. arXiv preprint arXiv:2008.01825 , year=
arXiv 2008
-
[66]
2017 , organization=
Robust adversarial reinforcement learning , author=. 2017 , organization=
2017
-
[67]
Robust Reinforcement Learning with
Hou, Linfang and Pang, Liang and Hong, Xin and Lan, Yanyan and Ma, Zhiming and Yin, Dawei , journal=. Robust Reinforcement Learning with
-
[68]
Neural computation , volume=
Robust reinforcement learning , author=. Neural computation , volume=. 2005 , publisher=
2005
-
[69]
Adversarial attacks on neural network policies , author=
-
[70]
Delving into adversarial attacks on deep policies , author=
-
[71]
Tactics of adversarial attack on deep reinforcement learning agents , author=
-
[72]
Robust Deep Reinforcement Learning with Adversarial Attacks , author=. Proc. International Conference on Autonomous Agents and MultiAgent Systems , pages=
-
[73]
2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Adversarially robust policy learning: Active construction of physically-plausible perturbations , author=. 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2017 , organization=
2017
-
[74]
Finite-Time Analysis of Asynchronous Stochastic Approximation and
Qu, Guannan and Wierman, Adam , booktitle=colt, pages=. Finite-Time Analysis of Asynchronous Stochastic Approximation and. 2020 , organization=
2020
-
[75]
Proceedings of 1995 34th IEEE conference on decision and control , volume=
Neuro-dynamic programming: an overview , author=. Proceedings of 1995 34th IEEE conference on decision and control , volume=. 1995 , organization=
1995
-
[76]
Variance-reduced
Wainwright, Martin J , journal=. Variance-reduced
-
[77]
Non-asymptotic analysis for two time-scale TDC with general smooth function approximation , author=
-
[78]
P. J. Huber , Date-Added =
-
[79]
Scaling up robust
Tamar, Aviv and Mannor, Shie and Xu, Huan , booktitle=icml, pages=. Scaling up robust. 2014 , organization=
2014
-
[80]
Reinforcement learning in robust
Lim, Shiau Hong and Xu, Huan and Mannor, Shie , booktitle=nips, pages=. Reinforcement learning in robust
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.