Jaguar: Fast Private CNN Inference with Power-of-Two Homomorphic Arithmetic
Pith reviewed 2026-06-27 09:10 UTC · model grok-4.3
The pith
Jaguar replaces prime-modulus homomorphic arithmetic with a power-of-two ciphertext ring to accelerate private CNN inference through coefficient-domain convolution and exact local truncation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
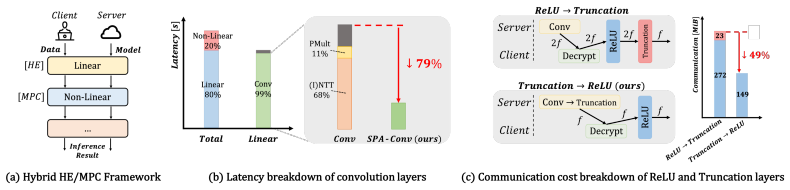
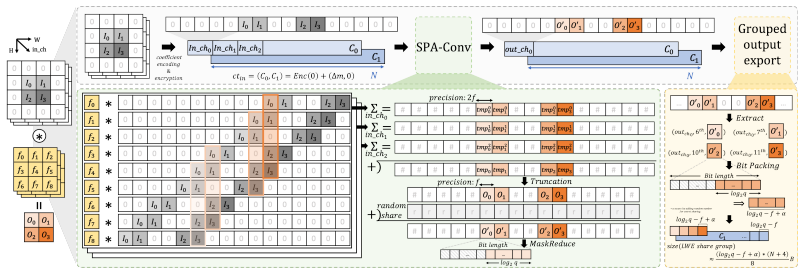
Jaguar shows that a power-of-two ciphertext ring preserves the required homomorphic properties while enabling SPA-Conv, a coefficient-domain convolution kernel that performs scalar-polynomial accumulation instead of NTT-centric multiplication, together with exact ciphertext-side right-shift truncation that lets ReLU execute directly at target precision and eliminates the auxiliary truncation protocol.
What carries the argument
The power-of-two ciphertext ring, which supports both SPA-Conv scalar-polynomial accumulation for convolution and exact local right-shift truncation after ReLU.
If this is right
- SPA-Conv replaces NTT-centric polynomial multiplication with scalar-polynomial accumulation in the convolution layers.
- ReLU can be evaluated directly at the target fixed-point precision without a separate post-ReLU truncation protocol.
- Client-side decryption retains an auxiliary NTT prime so its cost remains O(N log N).
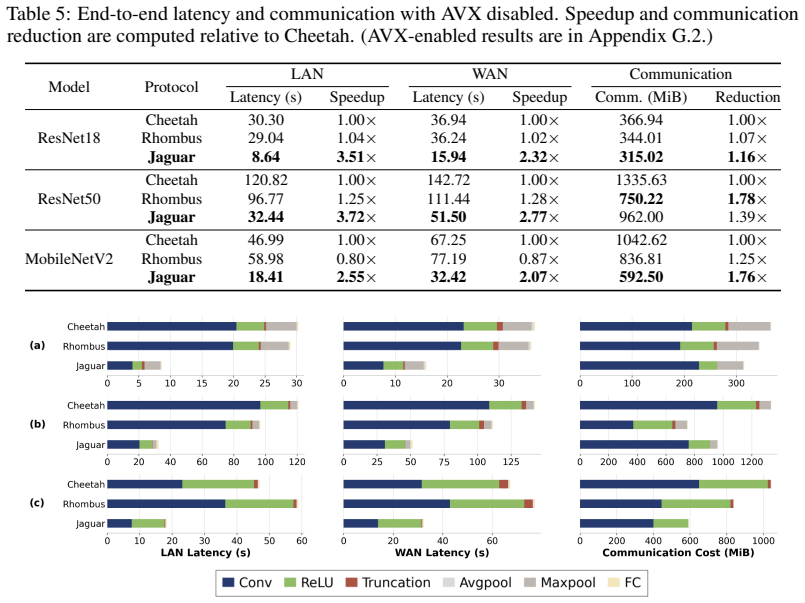
- Measured end-to-end latency drops 2.07-3.72x versus Cheetah and 2.16-3.36x versus Rhombus on the listed models when AVX is disabled.
- Communication volume is reduced 1.16-1.76x compared with Cheetah on the same workloads.
Where Pith is reading between the lines
- The same ring choice could be tested on other hybrid protocols that currently rely on prime moduli for convolution or truncation.
- Hardware implementations that already favor power-of-two arithmetic might see additional gains once the ring change is adopted.
- Security reductions for power-of-two rings would need explicit verification if the scheme is deployed at scale.
- The approach might simplify fixed-point analysis in other private machine-learning settings that currently double bitwidth for ReLU.
Load-bearing premise
Switching to a power-of-two ring keeps both the correctness of the homomorphic operations and the security of the scheme intact while allowing exact right-shift truncation without precision loss or extra protocols.
What would settle it
A side-by-side execution of Jaguar and a prime-modulus baseline on identical inputs that produces different decrypted outputs, or a concrete attack that breaks semantic security of the power-of-two scheme, would falsify the central claim.
Figures


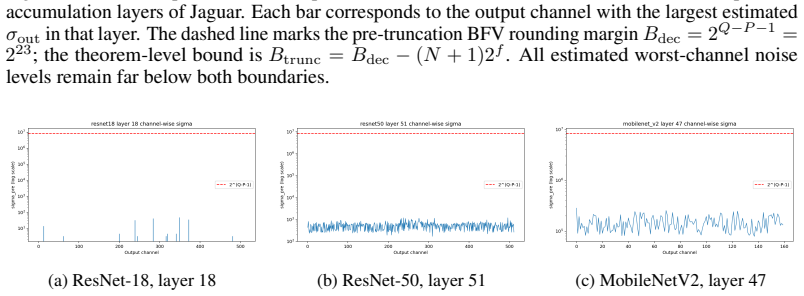
read the original abstract
Hybrid HE/2PC private CNN inference remains bottlenecked by prime-modulus homomorphic arithmetic in convolution and by a precision flow that runs ReLU at doubled bitwidth before invoking a separate truncation protocol. We present Jaguar, a system built on a single design choice--a power-of-two ciphertext ring--that addresses both. The choice enables SPA-Conv, a coefficient-domain convolution kernel that replaces NTT-centric polynomial multiplication with scalar-polynomial accumulation, and an exact ciphertext-side truncation by local right shifts that lets ReLU run directly at the target fixed-point precision and eliminates the post-ReLU truncation protocol. Where NTT remains genuinely useful--at the client, for the single polynomial multiplication during decryption--we recover it through an auxiliary NTT prime, preserving the power-of-two protocol substrate while keeping decryption O(N log N). On ImageNet-scale ResNet-18, ResNet-50, and MobileNetV2 with AVX disabled, Jaguar achieves 2.07-3.72x lower end-to-end latency than Cheetah and 2.16-3.36x lower than Rhombus, with 1.16-1.76x lower communication than Cheetah.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Jaguar, a hybrid HE/2PC system for private CNN inference on ImageNet-scale models (ResNet-18/50, MobileNetV2). Its core design choice replaces the standard prime-modulus ciphertext ring with a power-of-two ring. This enables (1) SPA-Conv, a coefficient-domain convolution that avoids NTT-based polynomial multiplication, and (2) exact local right-shift truncation after ReLU at target fixed-point precision, eliminating the post-ReLU truncation protocol. Client-side NTT is retained only for the single decryption multiplication via an auxiliary prime. The paper reports 2.07-3.72× lower end-to-end latency than Cheetah and 2.16-3.36× lower than Rhombus (AVX disabled), together with 1.16-1.76× lower communication than Cheetah.
Significance. If the power-of-two ring indeed preserves both correctness and security of the underlying HE scheme while permitting exact truncation without auxiliary protocols or precision loss, the work would materially simplify the precision flow and arithmetic kernels in private inference, yielding concrete latency and communication gains on realistic CNNs. The empirical speedups are measured on full ImageNet models rather than toy networks, which strengthens the practical claim.
major comments (3)
- [power-of-two ring construction] The power-of-two ring construction (described after the abstract and in the system overview): the manuscript asserts that switching to a power-of-two modulus preserves both the correctness and the security of the underlying lattice HE scheme while enabling exact right-shift truncation. No security reduction, noise-growth analysis, or reference to a hardness result for power-of-two moduli is supplied; standard BFV/CKKS security reductions rely on prime moduli for NTT and for the ring-LWE hardness assumption. This assumption is load-bearing for all claimed speedups.
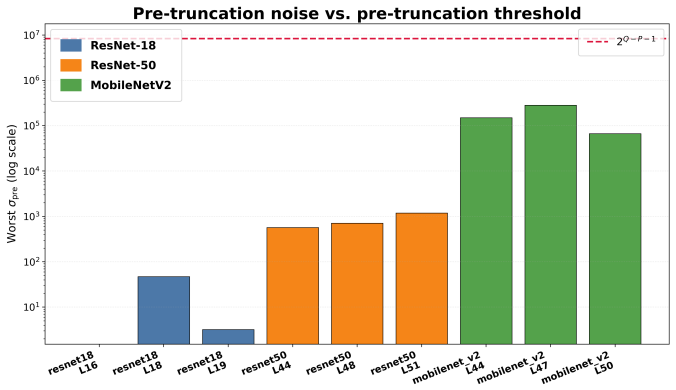
- [ReLU and truncation subsection] The exact truncation claim (ReLU and truncation subsection): the paper states that local right shifts after ReLU incur no precision loss and require no auxiliary 2PC protocol. The argument must demonstrate that modular wrap-around cannot occur at the target fixed-point bit-width and that noise growth remains compatible with the subsequent layers; without an explicit bound or modular-arithmetic invariant, the elimination of the truncation protocol is not yet justified.
- [evaluation section, Table X] Experimental comparison (evaluation section, Table X): the reported 2.07-3.72× latency advantage is measured with AVX disabled. The manuscript should clarify whether the baseline Cheetah and Rhombus implementations were also compiled without AVX or whether the comparison mixes optimized and unoptimized code; otherwise the speedup attribution to the power-of-two design alone is ambiguous.
minor comments (2)
- [system overview] Notation for the auxiliary NTT prime and the power-of-two modulus should be introduced once and used consistently; the current description mixes “auxiliary prime” and “power-of-two protocol substrate” without a single defining equation.
- [SPA-Conv description] The abstract claims “parameter-free” behavior for SPA-Conv; if any scaling factors or bit-width choices remain, they should be listed explicitly in the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating planned revisions where appropriate. All responses are based on the existing manuscript content without introducing unsubstantiated claims.
read point-by-point responses
-
Referee: [power-of-two ring construction] The power-of-two ring construction (described after the abstract and in the system overview): the manuscript asserts that switching to a power-of-two modulus preserves both the correctness and the security of the underlying lattice HE scheme while enabling exact right-shift truncation. No security reduction, noise-growth analysis, or reference to a hardness result for power-of-two moduli is supplied; standard BFV/CKKS security reductions rely on prime moduli for NTT and for the ring-LWE hardness assumption. This assumption is load-bearing for all claimed speedups.
Authors: The manuscript relies on the standard ring-LWE assumption, which is known to hold over power-of-two cyclotomic rings (as in many prior works using power-of-two moduli for RLWE). The auxiliary prime is used only for client-side NTT during decryption and does not alter the server-side power-of-two protocol. However, we acknowledge that an explicit reference to hardness results and a short noise-growth comparison paragraph are missing from the current text. We will add these in the revision to strengthen the presentation. revision: partial
-
Referee: [ReLU and truncation subsection] The exact truncation claim (ReLU and truncation subsection): the paper states that local right shifts after ReLU incur no precision loss and require no auxiliary 2PC protocol. The argument must demonstrate that modular wrap-around cannot occur at the target fixed-point bit-width and that noise growth remains compatible with the subsequent layers; without an explicit bound or modular-arithmetic invariant, the elimination of the truncation protocol is not yet justified.
Authors: We agree that an explicit modular invariant is required. In the power-of-two ring, ReLU outputs are bounded by construction to remain within the representable range before the right-shift (ensuring no wrap-around at the target fixed-point width), and the subsequent noise growth is controlled by the same modulus size chosen for the overall scheme. We will insert a short proof sketch with the required bounds in the ReLU and truncation subsection. revision: yes
-
Referee: [evaluation section, Table X] Experimental comparison (evaluation section, Table X): the reported 2.07-3.72× latency advantage is measured with AVX disabled. The manuscript should clarify whether the baseline Cheetah and Rhombus implementations were also compiled without AVX or whether the comparison mixes optimized and unoptimized code; otherwise the speedup attribution to the power-of-two design alone is ambiguous.
Authors: All reported timings, including the Cheetah and Rhombus baselines, were obtained with AVX explicitly disabled in the compilation flags to isolate the effect of the algorithmic changes. We will add an explicit statement to this effect in the evaluation section and update the table caption accordingly. revision: yes
Circularity Check
No circularity; performance claims are empirical measurements of an independent design choice
full rationale
The paper presents a design choice (power-of-two ciphertext ring) that is asserted to enable SPA-Conv and exact local right-shift truncation. The headline performance numbers (2.07-3.72x latency reduction etc.) are reported as direct experimental measurements on ResNet-18/50 and MobileNetV2 rather than quantities obtained by fitting parameters to a subset of the same data or by algebraic reduction to prior fitted values. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the abstract or described structure. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. doi: 10.1109/CVPR.2016.90
-
[2]
Andre Esteva, Brett Kuprel, Roberto A. Novoa, Justin Ko, Susan M. Swetter, Helen M. Blau, and Sebastian Thrun. Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542(7639):115–118, 2017. doi: 10.1038/nature21056
-
[3]
Georgios A. Kaissis, Alexander Ziller, Jonathan Passerat-Palmbach, Théo Ryffel, Dmitrii Usynin, Andrew Trask, Ionésio Lima, Jason Mancuso, Friederike Jungmann, Marc-Matthias Steinborn, Rickmer Braren, Marcus Makowski, Daniel Rueckert, et al. End-to-end privacy preserving deep learning on multi-institutional medical imaging.Nature Machine Intelligence, 3(6...
-
[4]
Deep Residual Learning for Image Recognition
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. MobileNetV2: Inverted residuals and linear bottlenecks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4510–4520, 2018. doi: 10.1109/CVPR. 2018.00474
-
[5]
MCUNet: Tiny deep learning on IoT devices
Ji Lin, Wei-Ming Chen, Yujun Lin, Chuang Gan, and Song Han. MCUNet: Tiny deep learning on IoT devices. InAdvances in Neural Information Processing Systems, volume 33, pages 11711–11722, 2020
2020
-
[6]
O’Reilly Media, 2019
Pete Warden and Daniel Situnayake.TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. O’Reilly Media, 2019. ISBN 9781492052043
2019
-
[7]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, volume 30, 2017
2017
-
[8]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186, 2019. doi: 10.18653/v1/N19-1423
-
[9]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
1901
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[11]
Secureml: A system for scalable privacy-preserving machine learning
Payman Mohassel and Yupeng Zhang. Secureml: A system for scalable privacy-preserving machine learning. In2017 IEEE Symposium on Security and Privacy (SP), pages 19–38. IEEE,
-
[12]
doi: 10.1109/SP.2017.12
-
[13]
Jian Liu, Mika Juuti, Yao Lu, and N. Asokan. Oblivious neural network predictions via minionn transformations. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pages 619–631, 2017. doi: 10.1145/3133956.3134056. 10
-
[14]
{GAZELLE}: A low latency framework for secure neural network inference
Chiraag Juvekar, Vinod Vaikuntanathan, and Anantha Chandrakasan. {GAZELLE}: A low latency framework for secure neural network inference. In27th USENIX Security symposium (USENIX Security 18), pages 1651–1669, 2018
2018
-
[15]
Delphi: A cryptographic inference service for neural networks
Pratyush Mishra, Ryan Lehmkuhl, Akshayaram Srinivasan, Wenting Zheng, and Raluca Ada Popa. Delphi: A cryptographic inference service for neural networks. In29th USENIX Security Symposium (USENIX Security 20), pages 2505–2522, 2020
2020
-
[16]
Cryptflow2: Practical 2-party secure inference
Deevashwer Rathee, Mayank Rathee, Nishant Kumar, Nishanth Chandran, Divya Gupta, Aseem Rastogi, and Rahul Sharma. Cryptflow2: Practical 2-party secure inference. InProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, pages 325–342, 2020
2020
-
[17]
Cheetah: Lean and fast secure {Two-Party} deep neural network inference
Zhicong Huang, Wen-jie Lu, Cheng Hong, and Jiansheng Ding. Cheetah: Lean and fast secure {Two-Party} deep neural network inference. In31st USENIX Security Symposium (USENIX Security 22), pages 809–826, 2022
2022
-
[18]
Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy
Ran Gilad-Bachrach, Nathan Dowlin, Kim Laine, Kristin Lauter, Michael Naehrig, and John Wernsing. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. InProceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 201–210. PMLR, 2016
2016
-
[19]
Low latency privacy preserving inference
Alon Brutzkus, Oren Elisha, and Ran Gilad-Bachrach. Low latency privacy preserving inference. InProceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 812–821. PMLR, 2019
2019
-
[20]
Low-complexity deep convolutional neural networks on fully homomorphic encryption using multiplexed parallel convolutions
Eunsang Lee, Joon-Woo Lee, Junghyun Lee, Young-Sik Kim, Yongjune Kim, Jong-Seon No, and Woosuk Choi. Low-complexity deep convolutional neural networks on fully homomorphic encryption using multiplexed parallel convolutions. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages ...
2022
-
[21]
Jae Hyung Ju, Jaiyoung Park, Jongmin Kim, Minsik Kang, Donghwan Kim, Jung Hee Cheon, and Jung Ho Ahn. Neujeans: Private neural network inference with joint optimization of convolution and fhe bootstrapping. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, pages 4361–4375, 2024. doi: 10.1145/3658644. 3690375
-
[22]
Deep neural networks for encrypted inference with tfhe
Alexandru Stoian, Jordan Fréry, Roman Bredehoft, Luis Montero, Celia Kherfallah, and Benoît Chevallier-Mames. Deep neural networks for encrypted inference with tfhe. Cryptology ePrint Archive, Paper 2023/257, 2023. URLhttps://eprint.iacr.org/2023/257
2023
-
[23]
Flash: A hybrid private inference protocol for deep CNNs with high accuracy and low latency on cpu
Hyeri Roh, Jinsu Yeo, Yeongil Ko, Gu-Yeon Wei, David Brooks, and Woo-Seok Choi. Flash: A hybrid private inference protocol for deep CNNs with high accuracy and low latency on cpu. arXiv preprint arXiv:2401.16732, 2024
arXiv 2024
-
[24]
OpenCheetah: Proof-of-concept implementation for Cheetah
Alibaba Gemini Lab. OpenCheetah: Proof-of-concept implementation for Cheetah. https: //github.com/Alibaba-Gemini-Lab/OpenCheetah, 2022. Accessed: 2026-04-26
2022
-
[25]
Woo-Seok Choi, Brandon Reagen, Gu-Yeon Wei, and David Brooks. Impala: Low-latency, communication-efficient private deep learning inference.arXiv preprint arXiv:2205.06437, 2022
arXiv 2022
-
[26]
LLAMA: A low latency math library for secure inference.Proceedings on Privacy Enhancing Technologies, 2022(4):274–294, 2022
Kanav Gupta, Deepak Kumaraswamy, Nishanth Chandran, and Divya Gupta. LLAMA: A low latency math library for secure inference.Proceedings on Privacy Enhancing Technologies, 2022(4):274–294, 2022
2022
-
[27]
Rhombus: Fast homomorphic matrix-vector multiplication for secure two- party inference
Jiaxing He, Kang Yang, Guofeng Tang, Zhangjie Huang, Li Lin, Changzheng Wei, Ying Yan, and Wei Wang. Rhombus: Fast homomorphic matrix-vector multiplication for secure two- party inference. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security (CCS), page 2490––2504, 2024
2024
-
[28]
Somewhat practical fully homomorphic encryption
Junfeng Fan and Frederik Vercauteren. Somewhat practical fully homomorphic encryption. Cryptology ePrint Archive, 2012. URLhttps://eprint.iacr.org/2012/144. 11
2012
-
[29]
In: IEEE S&P (2024).https://doi.org/ 10.1109/SP54263.2024.00230
Qi Pang, Jinhao Zhu, Helen Möllering, Wenting Zheng, and Thomas Schneider. BOLT: Privacy- preserving, accurate and efficient inference for transformers. In2024 IEEE Symposium on Security and Privacy (SP), pages 4753–4771, 2024. doi: 10.1109/SP54263.2024.00130
-
[30]
Hyena: Optimizing homomorphically encrypted convolution for private cnn inference
Hyeri Roh and Woo-Seok Choi. Hyena: Optimizing homomorphically encrypted convolution for private cnn inference. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, pages 1–9, 2024
2024
-
[31]
J. M. Pollard. The fast fourier transform in a finite field.Mathematics of Computation, 25(114): 365–374, 1971
1971
-
[32]
Iron: Private inference on transformers
Meng Hao, Hongwei Li, Hanxiao Chen, Pengzhi Xing, Guowen Xu, and Tianwei Zhang. Iron: Private inference on transformers. InAdvances in Neural Information Processing Systems 35, pages 15718–15731, 2022
2022
-
[33]
Tianshi Xu, Meng Li, Runsheng Wang, and Ru Huang. Falcon: Accelerating homomorphically encrypted convolutions for efficient private mobile network inference. In2023 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pages 1–9, 2023. doi: 10.1109/ ICCAD57390.2023.10323672
arXiv 2023
-
[34]
Privcirnet: Efficient private inference via block circulant transformation
Tianshi Xu, Lemeng Wu, Runsheng Wang, and Meng Li. Privcirnet: Efficient private inference via block circulant transformation. InAdvances in Neural Information Processing Systems 37, 2024
2024
-
[35]
Microsoft SEAL (release 4.1)
SEAL. Microsoft SEAL (release 4.1). https://github.com/Microsoft/SEAL, January
-
[36]
Microsoft Research, Redmond, W A
-
[37]
Homomorphic encryption standard
HomomorphicEncryption.org Standardization Consortium. Homomorphic encryption standard. Version 1.1, 2024. URL https://homomorphicencryption.org/wp-content/uploads/ 2024/08/Homomorphic-Encryption-Standard-v1.1.pdf
2024
-
[38]
A toolkit for ring-LWE cryptography
Vadim Lyubashevsky, Chris Peikert, and Oded Regev. A toolkit for ring-LWE cryptography. InAdvances in Cryptology – EUROCRYPT 2013, volume 7881 ofLecture Notes in Computer Science, pages 35–54. Springer, 2013. doi: 10.1007/978-3-642-38348-9_3
-
[39]
Microsoft Research,
Kim Laine.Simple Encrypted Arithmetic Library 2.3.1. Microsoft Research,
-
[40]
URL https://www.microsoft.com/en-us/research/wp-content/uploads/ 2017/11/sealmanual-2-3-1.pdf
2017
-
[41]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Fei-Fei Li. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015. doi: 10.1007/s11263-015-0816-y
-
[42]
Torchvision: Pytorch’s computer vision library
PyTorch Contributors. Torchvision: Pytorch’s computer vision library. https://github. com/pytorch/vision, 2024. Accessed: 2026-04-30
2024
-
[43]
RhombusEnd2End: Public implementation of rhombus
Jiaxing He. RhombusEnd2End: Public implementation of rhombus. https://github.com/ 2646jx/RhombusEnd2End, 2025. MIT License. Accessed: 2026-04-30
2025
-
[44]
Intel advanced vector extensions 512 (Intel A VX-512) overview
Intel Corporation. Intel advanced vector extensions 512 (Intel A VX-512) overview. https://www.intel.com/content/www/us/en/architecture-and-technology/ avx-512-overview.html, 2024. Accessed: 2026-04-27
2024
-
[45]
Intel intrinsics guide
Intel Corporation. Intel intrinsics guide. https://www.intel.com/content/www/us/en/ docs/intrinsics-guide/index.html, 2024. Version 3.6.9, accessed: 2026-04-27. 12 A Notations Conventions.Ring elements are italic polynomials, e.g., ˆx(X)∈R q or short for ˆx∈Rq, and ˆx[i]denotes the i-th coefficient. Lower-case letters with "hat" symbols denote polynomials...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.