Accelerating SAV-based optimization via randomized low-rank Hessian approximation
Pith reviewed 2026-06-27 12:26 UTC · model grok-4.3
The pith
N-RSAV accelerates RSAV optimization by using a randomized low-rank Nyström approximation of the Hessian while preserving the modified energy dissipation law.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that replacing the linear operator in the RSAV scheme with a positive semidefinite Nyström approximation of the Hessian, obtained via randomization and eigenvalue truncation, yields faster convergence on effectively low-rank problems while satisfying an unconditional modified energy dissipation law, supported by convergence guarantees under the PL condition plus convexity.
What carries the argument
The Nyström-enhanced linear operator inside the RSAV scheme, built from a randomized low-rank Nyström Hessian approximation with eigenvalue truncation to ensure positive semidefiniteness.
If this is right
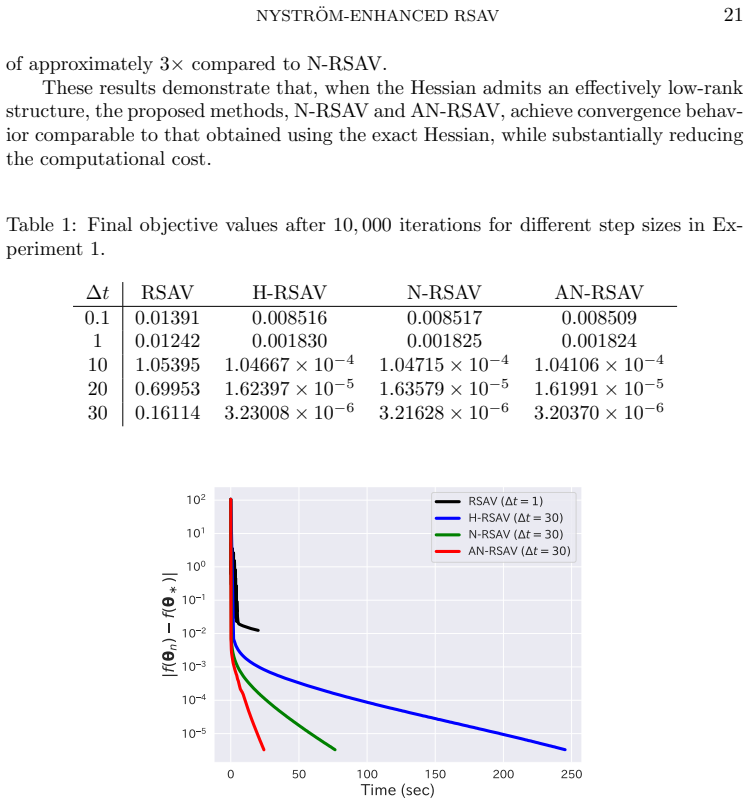
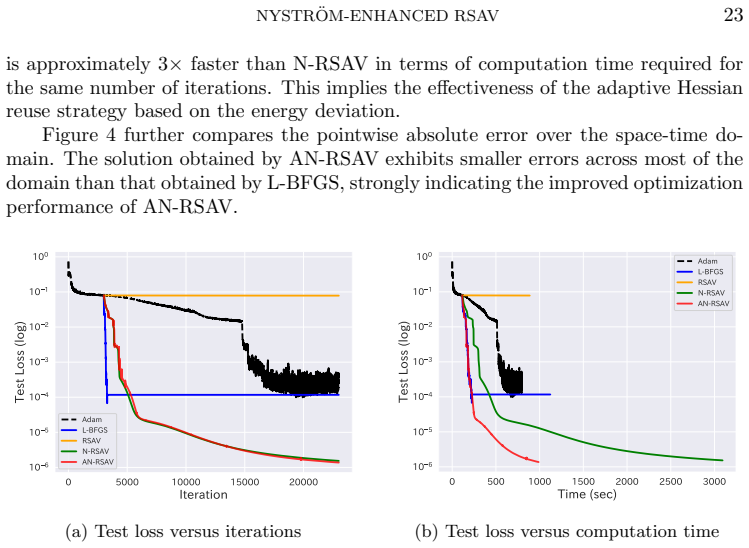
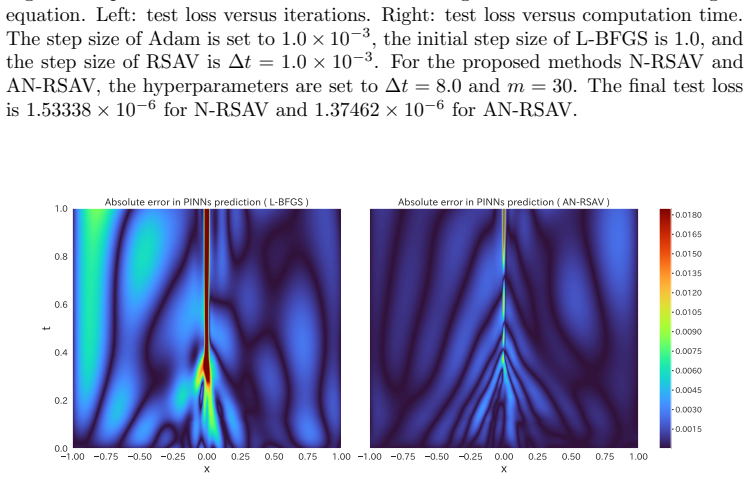
- The method achieves faster convergence than standard RSAV on ill-conditioned problems with low-rank Hessian structure.
- The modified energy dissipation law holds unconditionally.
- Adaptive reuse of the approximate Hessian lowers computational cost while retaining acceleration.
- Convergence is guaranteed under the PL condition with an added convexity assumption.
Where Pith is reading between the lines
- The adaptive reuse idea could be applied to other curvature approximations beyond Nyström.
- On problems lacking low-rank Hessian structure the approximation may lose accuracy and slow the method.
- The approach might extend to other auxiliary-variable optimization schemes that rely on energy dissipation.
Load-bearing premise
The target problems must have an effectively low-rank Hessian structure that makes the Nyström approximation accurate, and the convergence analysis requires both the Polyak-Łojasiewicz condition and convexity.
What would settle it
A run on an ill-conditioned convex quadratic problem with low-rank Hessian where N-RSAV shows no faster convergence than RSAV or where the modified energy increases in an iteration.
Figures
read the original abstract
We propose a new optimization method, the Nystr\"om-enhanced relaxed scalar auxiliary variable method (N-RSAV), which incorporates curvature information into the RSAV framework to accelerate convergence while preserving an unconditional modified energy dissipation law. Existing RSAV-based methods rely solely on first-order information and often suffer from slow convergence, particularly for ill-conditioned problems such as those arising in physics-informed neural networks (PINNs). To address this limitation, we design the linear operator in the RSAV scheme using approximate Hessian information obtained from a randomized low-rank Nystr\"om approximation. To preserve the dissipation structure, we enforce positive semidefiniteness through eigenvalue truncation. Furthermore, we introduce an adaptive strategy that reuses the approximate Hessian based on the deviation between the original and modified energies, significantly reducing computational cost. We also provide a convergence analysis of the RSAV scheme with a general positive semidefinite operator under the Polyak-Lojasiewicz (PL) condition and establish corresponding convergence guarantees for N-RSAV under the PL condition and an additional convexity assumption. Numerical experiments on ill-conditioned problems with effectively low-rank structure, including convex quadratic problems and training of PINNs, demonstrate that the proposed methods achieve substantially faster convergence than conventional RSAV-based approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Nyström-enhanced relaxed scalar auxiliary variable (N-RSAV) method, which replaces the linear operator in RSAV with a randomized low-rank Nyström approximation of the Hessian (enforced PSD via eigenvalue truncation) to accelerate convergence on ill-conditioned problems while preserving an unconditional modified energy dissipation law. An adaptive reuse strategy based on energy deviation is introduced to lower cost. Convergence is analyzed for general RSAV with PSD operator under the PL condition, and for N-RSAV under PL plus an additional convexity assumption. Experiments on convex quadratics and PINN training report substantially faster convergence than standard RSAV approaches.
Significance. If the results hold, the approach provides a concrete way to inject curvature information into SAV/RSAV schemes for faster convergence on problems with effectively low-rank Hessians, while retaining the unconditional stability property that makes these methods attractive. The provision of a convergence analysis under stated assumptions (PL for the general case) is a positive feature, as is the adaptive reuse mechanism for computational efficiency.
major comments (3)
- [Abstract and convergence analysis] Abstract and convergence analysis section: the N-RSAV convergence guarantee requires the PL condition plus an additional convexity assumption, yet the strongest empirical claim concerns acceleration on PINN training (non-convex loss landscapes). The analysis therefore supplies no theoretical support for the reported PINN results.
- [Numerical experiments] Numerical experiments section: the claim of substantially faster convergence on ill-conditioned problems (including PINNs) is presented without error bars, multiple random seeds, explicit baseline definitions, or quantitative verification that the adaptive reuse strategy preserves the exact dissipation law.
- [Method] Method section on adaptive strategy: it is not shown whether the combination of Nyström approximation, eigenvalue truncation, and energy-deviation-based reuse continues to satisfy the unconditional modified energy dissipation law exactly, which is load-bearing for the stability claim.
minor comments (2)
- [Abstract] The abstract refers to 'effectively low-rank structure' without a precise definition or quantitative criterion for when the Nyström approximation is expected to be accurate.
- [Method] Notation for the randomized Nyström operator and the reuse threshold parameter should be introduced with explicit definitions and ranges.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the method's potential. We address each major comment below, proposing revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract and convergence analysis] Abstract and convergence analysis section: the N-RSAV convergence guarantee requires the PL condition plus an additional convexity assumption, yet the strongest empirical claim concerns acceleration on PINN training (non-convex loss landscapes). The analysis therefore supplies no theoretical support for the reported PINN results.
Authors: We agree that the N-RSAV convergence result requires both the PL condition and an additional convexity assumption, while the general RSAV analysis holds under PL alone. The PINN experiments demonstrate practical acceleration on non-convex problems and are not claimed to be covered by the N-RSAV theory. We will revise the abstract to explicitly distinguish the scope of the theoretical guarantees (general RSAV under PL; N-RSAV under PL plus convexity) from the empirical results on PINNs. revision: yes
-
Referee: [Numerical experiments] Numerical experiments section: the claim of substantially faster convergence on ill-conditioned problems (including PINNs) is presented without error bars, multiple random seeds, explicit baseline definitions, or quantitative verification that the adaptive reuse strategy preserves the exact dissipation law.
Authors: We accept that the experimental presentation lacks statistical rigor and explicit verification. In the revision we will report results with error bars over multiple random seeds, clearly define all baselines (including standard RSAV variants), and include quantitative checks (e.g., tables or plots of energy deviation) confirming that the adaptive reuse strategy preserves the modified energy dissipation law to machine precision. revision: yes
-
Referee: [Method] Method section on adaptive strategy: it is not shown whether the combination of Nyström approximation, eigenvalue truncation, and energy-deviation-based reuse continues to satisfy the unconditional modified energy dissipation law exactly, which is load-bearing for the stability claim.
Authors: Eigenvalue truncation guarantees that the Nyström operator remains positive semidefinite, which is the key property used to establish the unconditional dissipation law for the general RSAV scheme with a PSD operator. The adaptive reuse is triggered only when the energy deviation remains small, preserving the structure. We will add an explicit verification (or short proof sketch) in the revised Method section showing that the full combination continues to satisfy the exact unconditional modified energy dissipation law. revision: yes
Circularity Check
No circularity in derivation chain or analysis
full rationale
The paper introduces N-RSAV by constructing a PSD linear operator via randomized Nyström Hessian approximation (with eigenvalue truncation) inside the existing RSAV framework, then separately states convergence results for the general PSD-operator RSAV under PL and for N-RSAV under PL plus convexity. These steps are independent of the target data or fitted values; the PINN experiments are presented purely as numerical evidence without any claim that the convexity assumption holds for them. No self-definitional equations, fitted-input predictions, load-bearing self-citations, or ansatz smuggling appear in the abstract or described structure. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Nyström rank
- reuse threshold
axioms (3)
- domain assumption The objective satisfies the Polyak-Lojasiewicz condition
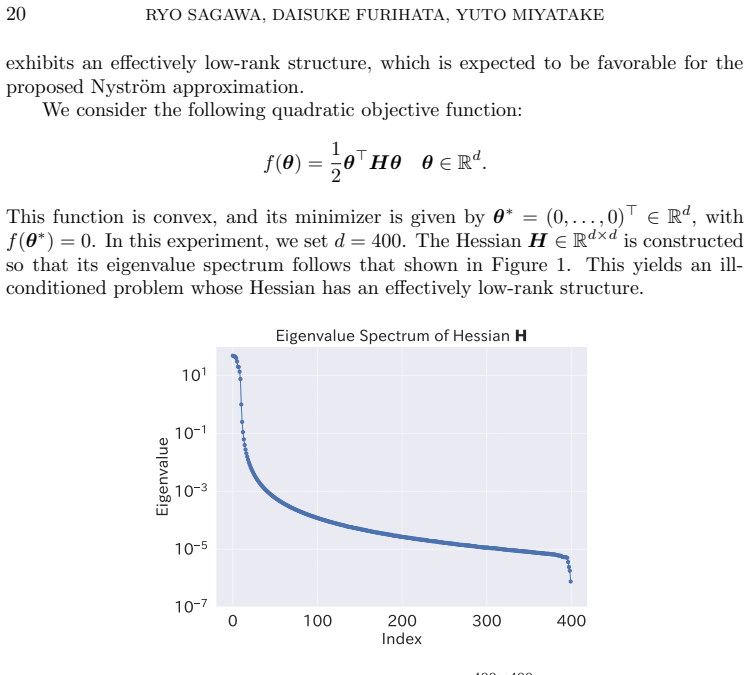
- domain assumption The Hessian possesses effectively low-rank structure
- domain assumption Additional convexity assumption for N-RSAV
Reference graph
Works this paper leans on
-
[1]
and Ahmad, S
Mehmood, F. and Ahmad, S. and Whangbo, T. K. , title =. Mathematics , volume =. 2023 , pages =
2023
-
[2]
and Mohri, M
Kumar, S. and Mohri, M. and Talwalkar, A. , title =. Proceedings of Machine Learning Research , volume =. 2009 , pages =
2009
-
[3]
and Shen, J
Liu, X. and Shen, J. and Zhang, X. , title =. SIAM Journal on Scientific Computing , volume =. 2023 , pages =
2023
-
[4]
and Wright, S
Nocedal, J. and Wright, S. J. , title =
-
[5]
and Xu, J
Shen, J. and Xu, J. and Yang, J. , title =. Journal of Computational Physics , volume =. 2018 , pages =
2018
-
[6]
On the saddle point problem for non-convex optimization
Pascanu, R. and Dauphin, Y. N. and Ganguli, S. and Bengio, Y. , title =. arXiv preprint arXiv:1405.4604 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
and Perdikaris, P
Raissi, M. and Perdikaris, P. and Karniadakis, G. E. , title =. Journal of Computational Physics , volume =. 2019 , pages =
2019
-
[8]
and Lei, W
Rathore, P. and Lei, W. and Frangella, Z. and Lu, L. and Udell, M. , title =. Proceedings of Machine Learning Research , volume =. 2024 , pages =
2024
-
[9]
and Zhang, Z
Jiang, M. and Zhang, Z. and Zhao, J. , title =. Journal of Computational Physics , volume =. 2022 , pages =
2022
-
[10]
and Shen, J
Zhang, Y. and Shen, J. , title =. Journal of Computational Physics , volume =. 2022 , pages =
2022
-
[11]
and Roosta-Khorasani, F
Ye, N. and Roosta-Khorasani, F. and Cui, T. , title =. 2017 MATRIX Annals , volume =. 2019 , pages =
2017
-
[12]
and Cao, Z
Sun, S. and Cao, Z. and Zhu, H. and Zhao, J. , title =. IEEE Transactions on Cybernetics , volume =. 2020 , pages =
2020
-
[13]
and Zhang, J
Zhang, S. and Zhang, J. and Shen, J. and Lin, G. , title =. SIAM Journal on Scientific Computing , volume =
-
[14]
and Mao, Z
Ma, Z. and Mao, Z. and Shen, J. , title =. Journal of Computational Physics , volume =
-
[15]
and Krishnan, S
Ghorbani, B. and Krishnan, S. and Xiao, Y. , booktitle =. An Investigation into Neural Net Optimization via. 2019 , volume =
2019
-
[16]
and Gholami, A
Yao, Z. and Gholami, A. and Keutzer, K. and Mahoney, M. W. , booktitle=. Py. 2020 , pages=
2020
-
[17]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author =. arXiv preprint arXiv:1412.6980 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Wiley Interdisciplinary Reviews: Computational Statistics , volume=
Steepest descent , author=. Wiley Interdisciplinary Reviews: Computational Statistics , volume=. 2010 , publisher=
2010
-
[19]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Understanding the difficulty of training deep feedforward neural networks , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
-
[20]
Journal of Research of the National Bureau of Standards , volume=
Methods of conjugate gradients for solving linear systems , author=. Journal of Research of the National Bureau of Standards , volume=
-
[21]
2001 , publisher=
Chebyshev and Fourier spectral methods , author=. 2001 , publisher=
2001
-
[22]
Wanner, Gerhard and Hairer, Ernst , volume=. Solving. 1996 , publisher=
1996
-
[23]
Mathematical Programming , volume=
On the limited memory BFGS method for large scale optimization , author=. Mathematical Programming , volume=. 1989 , publisher=
1989
-
[24]
Computers & Mathematics with Applications , volume=
A computationally optimal relaxed scalar auxiliary variable approach for solving gradient flow systems , author=. Computers & Mathematics with Applications , volume=. 2024 , publisher=
2024
-
[25]
A novel energy-optimal scalar auxiliary variable (
Liu, Zhengguang and Zhang, Yanrong and Li, Xiaoli , journal=. A novel energy-optimal scalar auxiliary variable (
-
[26]
SIAM Journal on Scientific Computing , volume=
A Relaxed Vector Auxiliary Variable Algorithm for Unconstrained Optimization Problems , author=. SIAM Journal on Scientific Computing , volume=. 2025 , publisher=
2025
-
[27]
Neural Computation , volume=
Fast estimation of approximate matrix ranks using spectral densities , author=. Neural Computation , volume=. 2017 , publisher=
2017
-
[28]
Linear Algebra and its Applications , volume=
Fast randomized numerical rank estimation for numerically low-rank matrices , author=. Linear Algebra and its Applications , volume=. 2024 , publisher=
2024
-
[29]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[30]
Journal of Optimization Theory and Applications , volume=
Some effective methods for unconstrained optimization based on the solution of systems of ordinary differential equations , author=. Journal of Optimization Theory and Applications , volume=. 1989 , publisher=
1989
-
[31]
Weijie Su and Stephen Boyd and Emmanuel J. Cand. A Differential Equation for Modeling Nesterov's Accelerated Gradient Method: Theory and Insights , journal =. 2016 , volume =
2016
-
[32]
Advances in Neural Information Processing Systems , volume=
Acceleration via symplectic discretization of high-resolution differential equations , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Pearlmutter, B. A. , title =. Neural Computation , volume =. 1994 , pages =
1994
-
[34]
and Shukla, K
Kiyani, E. and Shukla, K. and Urb. Optimizing the optimizer for physics-informed neural networks and. Computer Methods in Applied Mechanics and Engineering , volume=. 2025 , publisher=
2025
-
[35]
Gradient alignment in physics-informed neural networks: A second-order optimization perspective , author=. arXiv preprint arXiv:2502.00604 , year=
-
[36]
and Matsuda, T
Ito, S. and Matsuda, T. and Miyatake, Y. , journal=. Adjoint-based exact
-
[37]
Randomized
Frangella, Zachary and Tropp, Joel A and Udell, Madeleine , journal=. Randomized
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.