Algebraic Dead Directions in LayerNorm Transformers: A Forward-Pass-Only Diagnostic at LLM Scale
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
The inverse-scale direction of LayerNorm affine parameters is an exact algebraic kernel of the post-final-norm centred activation covariance for any input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
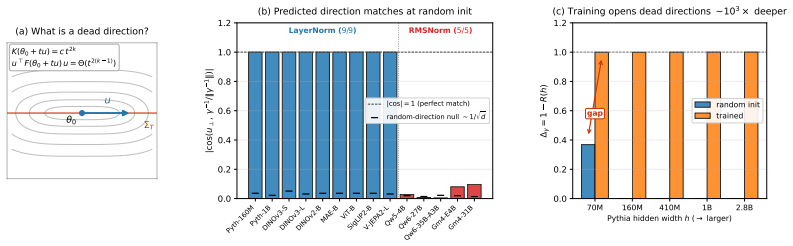
The inverse-scale direction γ^{-1}/‖γ^{-1}‖ of the LayerNorm affine is an exact algebraic kernel of the post-final-norm centred activation covariance, for any input distribution, and induces a corresponding dead direction in parameter space. It is read from the LN scale parameter alone, with no forward or backward pass and no eigensolve: the cheapest dead-direction read, specific to LayerNorm.
What carries the argument
The inverse-scale direction γ^{-1}/‖γ^{-1}‖ of the LayerNorm affine parameter, which is an algebraic kernel of the centred post-norm covariance due to the mean-subtraction projector.
If this is right
- The residual stream's smallest singular value is preserved block-to-block on 13 of the 14 measured transformers on their own input distribution.
- The presence or absence of the predicted kernel direction classifies a transformer as LayerNorm or RMSNorm from its parameters alone.
- At random initialization the predicted direction matches the measured bottom singular direction of the activation covariance to four decimal places on all nine LayerNorm models.
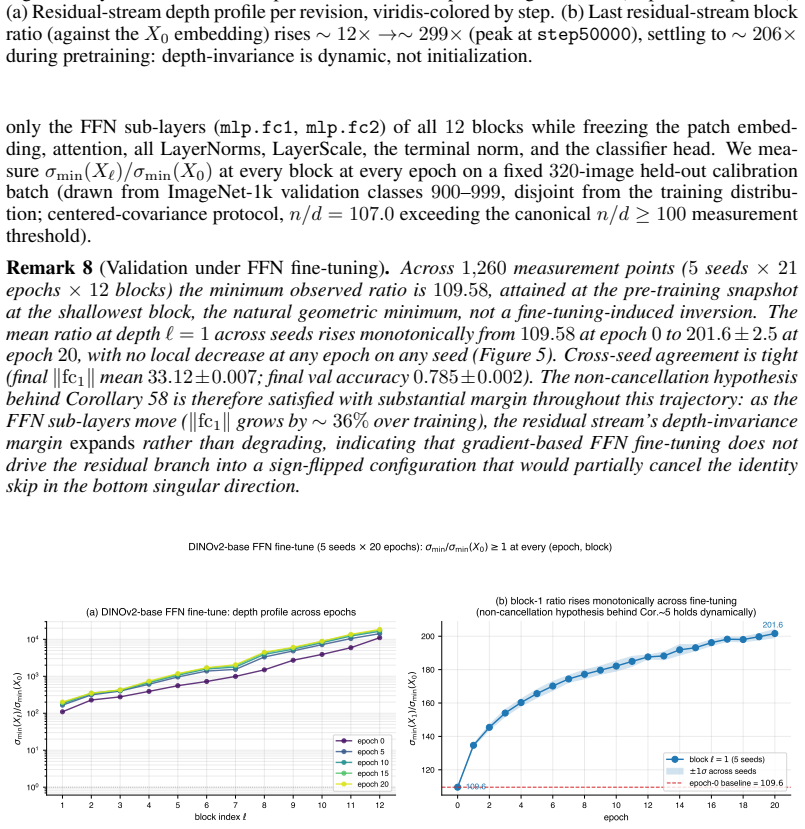
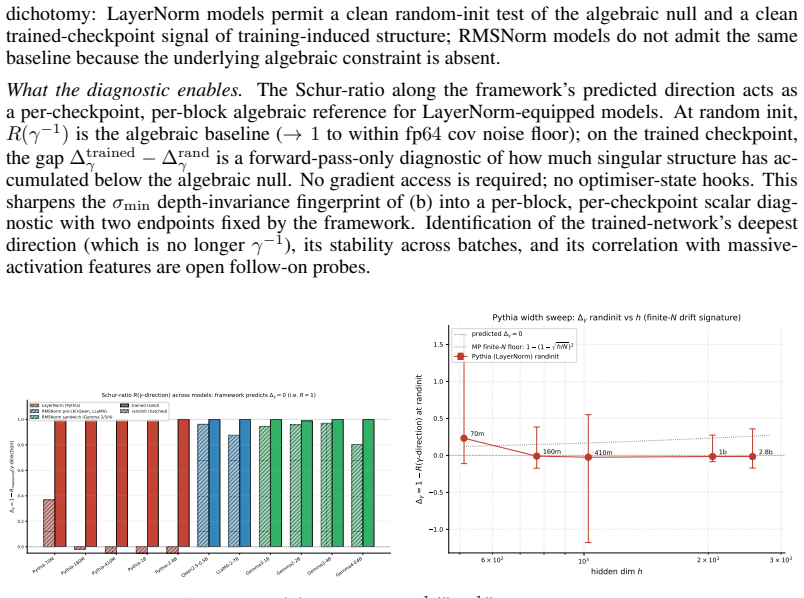
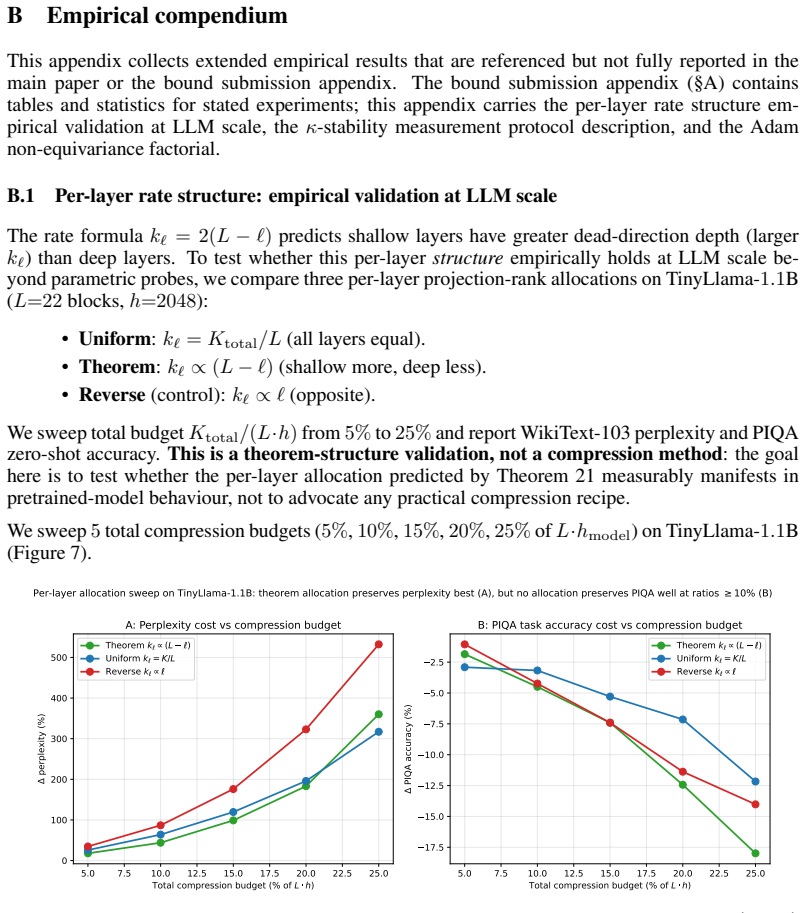
- On trained checkpoints the eigenvalue along the kernel direction deepens by roughly three orders of magnitude, opening additional dead directions.
Where Pith is reading between the lines
- Checkpoints can be scanned for normalization type and for the depth of this singular structure without running inference or knowing the training code.
- The algebraic identity supplies a coordinate along which one could add a regularizer that penalizes further deepening of the dead direction during continued training.
- Because the kernel is present from initialization, any training procedure that preserves or amplifies it is automatically selecting for singular minima along a known axis.
Load-bearing premise
The derivation requires the precise mean-subtraction projector inside standard LayerNorm and covariance taken after the final normalization step.
What would settle it
Compute the centred activation covariance matrix after the final LayerNorm on any input distribution and verify whether its quadratic form along γ^{-1}/‖γ^{-1}‖ is numerically zero.
Figures
read the original abstract
Pretrained transformers sit near singular minima of the loss, where the Fisher information metric degenerates along dead directions: directions in parameter space along which the directional Fisher vanishes. Locating such a direction normally needs a forward pass and an eigendecomposition of activations, or a sampling-based complexity estimate; none returns a direction computable from the network's parameters alone. We give one, for LayerNorm transformers. The inverse-scale direction $\gamma^{-1}/\|\gamma^{-1}\|$ of the LayerNorm affine is an exact algebraic kernel of the post-final-norm centred activation covariance, for any input distribution, and induces a corresponding dead direction in parameter space. It is read from the LN scale parameter alone, with no forward or backward pass and no eigensolve: the cheapest dead-direction read, specific to LayerNorm. We test it on $14$ pretrained transformers ($9$ LayerNorm, $5$ RMSNorm; $160$M-$35$B; language and vision objectives). At random initialisation the predicted direction matches the measured bottom singular direction (one forward pass, direct SVD) to four decimal places on $9/9$ LayerNorm models, and is correctly absent on $5/5$ RMSNorm models, which lack the mean-subtraction projector that creates it. On the trained checkpoint the covariance eigenvalue along this direction deepens by ${\sim}10^3\times$ and further dead directions open; the random-init-to-trained gap is a one-forward-pass, per-checkpoint readout of singular structure along the predicted coordinate. Two consequences follow in closed form: the residual stream's smallest singular value is preserved block-to-block on $13/14$ transformers measured on their own input distribution, the one exception (Gemma$4$-$31$B) a genuine dead direction the same read pinpoints; and the kernel direction's presence classifies a transformer's normalisation from the parameters alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper asserts that in transformers using standard LayerNorm, the normalized inverse-scale direction γ^{-1}/‖γ^{-1}‖ of the LayerNorm affine parameters is an exact algebraic kernel of the centered covariance of post-final-norm activations for any input distribution. This follows directly from the mean-subtraction projector enforced by LayerNorm (absent in RMSNorm), forcing zero variance along that direction. The identity is tested on 14 pretrained models (9 LayerNorm, 5 RMSNorm; 160M–35B parameters) at random initialization, where it matches the measured bottom singular direction to four decimal places on all LayerNorm models and is correctly absent on all RMSNorm models. On trained checkpoints the eigenvalue along the direction deepens by ~10^3×; closed-form consequences include block-to-block preservation of the residual stream's smallest singular value on 13/14 models.
Significance. If the algebraic identity holds, the result supplies a parameter-only, forward-pass-free and eigensolve-free diagnostic for a dead direction in the Fisher metric of LayerNorm transformers. The exact match at initialization across scales and the clean separation from RMSNorm models provide strong, architecture-specific evidence. The block-to-block singular-value preservation is a direct, falsifiable downstream prediction that follows in closed form from the kernel property.
minor comments (3)
- [§3] §3 (derivation): the step from the mean-zero property of z to Var(v·y)=0 is immediate, but the subsequent claim that this induces a dead direction in parameter space would benefit from an explicit one-line link to the directional Fisher (even if standard).
- [Table 1] Table 1: the four-decimal-place match is reported via cosine similarity; stating the precise numerical values of the bottom singular vector components for one representative model would make the match more transparent.
- [§5.2] §5.2: the statement that the random-init-to-trained gap is 'a one-forward-pass readout' is clear, but the precise definition of the gap (difference in log-eigenvalue or ratio) should be given explicitly.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of the manuscript, the assessment of its significance, and the recommendation to accept. The report correctly identifies the algebraic identity, its parameter-only nature, the empirical verification across scales and normalization types, and the closed-form downstream predictions.
Circularity Check
No significant circularity; algebraic identity from LayerNorm definition
full rationale
The central claim is an exact algebraic identity: the mean-subtraction projector in standard LayerNorm forces ∑z_i=0 on the pre-affine vector z, which directly implies that the post-affine output y is orthogonal to γ^{-1} (hence zero variance along that direction in the centred covariance) for any input distribution. This follows immediately from the definition of LayerNorm without any fitted parameters, predictions, or self-citations. The paper explicitly notes the identity fails for RMSNorm (which lacks the projector) and confirms this experimentally on 5 RMSNorm models. No load-bearing step reduces to a fit, self-citation chain, or ansatz; the derivation is self-contained against the architecture equations and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LayerNorm includes explicit mean subtraction that creates a projector absent in RMSNorm
- domain assumption Covariance is computed on activations after the final normalization layer
Forward citations
Cited by 2 Pith papers
-
Dead-Direction Conditioners: Gauge-Equivariant Preconditioning for Deep Networks
Dead-Direction Conditioners provide gauge-equivariant preconditioning by conditioning optimizer state on symmetry orbits, yielding improved resistance to over-training collapse and higher detection of dead directions ...
-
Dead-Direction Signatures: A Cheap Spectral Reading of Singular Complexity
Dead-Direction Signatures provide closed-form spectral readings of dead directions in network activations and gradients that track rank deficits at singular minima, offering a cheap directional alternative to SGLD-based LLC.
Reference graph
Works this paper leans on
-
[1]
S.-i. Amari. Information Geometry and Its Applications, volume 194 of Applied Mathematical Sciences. Springer, 2016. URL https://link.springer.com/book/10.1007/978-4-431-55978-8
-
[2]
S.-i. Amari, H. Park, and T. Ozeki. Singularities affect dynamics of learning in neuromanifolds. Neural Computation, 18 0 (5): 0 1007--1065, 2006. URL https://doi.org/10.1162/neco.2006.18.5.1007
-
[3]
Ashkboos, M
S. Ashkboos, M. L. Croci, M. G. do Nascimento, T. Hoefler, and J. Hensman. SliceGPT : Compress large language models by deleting rows and columns. In International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, Mojtaba, A. Kamoun, X. Chen, K. Sinha, Y. LeCun, M. Rabbat, and N. Ballas. V-JEPA 2 : Self-supervised video models enable understanding, prediction, and planning. arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[5]
Biderman, H
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O'Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. van der Wal. Pythia: A suite for analyzing large language models across training and scaling. ICML, 2023
2023
-
[6]
E. Boix-Adsera, E. Littwin, E. Abbe, S. Bengio, and J. Susskind. Transformers learn through gradual rank increase. In Advances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/2306.07042
arXiv 2023
-
[7]
J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. In International Conference on Learning Representations (ICLR), 2021. arXiv:2103.00065; documents the edge-of-stability regime where the top Hessian eigenvalue stabilises near 2/ . Standard sharpness-side phase-transi...
arXiv 2021
-
[8]
Y. Dong, J.-B. Cordonnier, and A. Loukas. Attention is not all you need: pure attention loses rank doubly exponentially with depth. In International Conference on Machine Learning (ICML), 2021. URL https://arxiv.org/abs/2103.03404
arXiv 2021
-
[9]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021
2021
-
[10]
Eschenhagen, A
R. Eschenhagen, A. Immer, R. E. Turner, F. Schneider, and P. Hennig. K ronecker-factored approximate curvature for modern neural network architectures. In NeurIPS, 2023
2023
- [11]
-
[12]
George, C
T. George, C. Laurent, X. Bouthillier, N. Ballas, and P. Vincent. Fast approximate natural gradient descent in a K ronecker-factored eigenbasis. In NeurIPS, 2018
2018
-
[13]
Ghorbani, S
B. Ghorbani, S. Krishnan, and Y. Xiao. An investigation into neural net optimization via H essian eigenvalue density. In ICML, 2019
2019
-
[14]
R. Grosse and J. Martens. A K ronecker-factored approximate F isher matrix for convolution layers. In ICML, 2016. URL https://arxiv.org/abs/1602.01407
Pith/arXiv arXiv 2016
-
[15]
K. He, X. Chen, S. Xie, Y. Li, P. Doll \'a r, and R. Girshick. Masked autoencoders are scalable vision learners. Proc. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 16000--16009, 2022
2022
- [16]
-
[17]
J. Hoogland, G. Wang, M. Farrugia-Roberts, L. Carroll, S. Wei, and D. Murfet. Loss landscape degeneracy and stagewise development in transformers. Transactions on Machine Learning Research, 2024. URL https://arxiv.org/abs/2402.02364
arXiv 2024
-
[18]
N. K. Jha and B. Reagen. NerVE : Nonlinear eigenspectrum dynamics in LLM feed-forward networks. arXiv:2603.06922, 2026
arXiv 2026
-
[19]
Karakida, S
R. Karakida, S. Akaho, and S.-i. Amari. Universal statistics of F isher information in deep neural networks: Mean field approach. In AISTATS, 2019
2019
-
[20]
Karakida, S
R. Karakida, S. Akaho, and S.-i. Amari. Pathological spectra of the F isher information metric and its variants in deep neural networks. Neural Computation, 33 0 (8): 0 2274--2307, 2021
2021
-
[21]
T. X. Khanh, T. Q. Hoa, L. D. Trung, and P. T. Duc. Spectral entropy collapse as an empirical signature of delayed generalisation in grokking. arXiv:2604.13123, 2026
Pith/arXiv arXiv 2026
-
[22]
J. Kim, B. Lee, C. Park, Y. Oh, B. Kim, T. Yoo, S. Shin, D. Han, J. Shin, and K. M. Yoo. Peri-LN : Revisiting normalization layer in the transformer architecture. arXiv preprint, 2025. URL https://arxiv.org/abs/2502.02732. Names the pre-norm + post-norm pattern ``Peri-LN'' and analyses its effect on activation magnitudes (linear vs exponential growth) and...
arXiv 2025
-
[23]
F. Kunstner, L. Balles, and P. Hennig. Limitations of the empirical F isher approximation for natural gradient descent. In NeurIPS, 2019. URL https://arxiv.org/abs/1905.12558
arXiv 2019
-
[24]
E. Lau, Z. Furman, G. Wang, D. Murfet, and S. Wei. The local learning coefficient: A singularity-aware complexity measure. In AISTATS, 2025. URL https://proceedings.mlr.press/v258/lau25a.html
2025
-
[25]
J. Martens and R. Grosse. Optimizing neural networks with Kronecker -factored approximate curvature. In ICML, 2015. URL https://arxiv.org/abs/1503.05671
arXiv 2015
-
[26]
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. In ICLR, 2023. URL https://arxiv.org/abs/2301.05217
Pith/arXiv arXiv 2023
-
[27]
L. Noci, S. Anagnostidis, L. Biggio, A. Orvieto, S. P. Singh, and A. Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse. In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/2206.03126
arXiv 2022
-
[28]
Olsson, N
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. DasSarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly, D. Drain, D. Ganguli, Z. Hatfield-Dodds, D. Hernandez, S. Johnston, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah. In-context learning and induction heads. Transformer Cir...
2022
-
[29]
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. DINOv2 : Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[30]
V. Papyan. Traces of class/cross-class structure pervade deep learning spectra. JMLR, 21 0 (252): 0 1--64, 2020. URL https://jmlr.org/papers/volume21/20-933/20-933.pdf
2020
-
[31]
URL https://www.pnas.org/doi/abs/10.1073/pnas
V. Papyan, X. Y. Han, and D. L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117 0 (40): 0 24652--24663, 2020. URL https://doi.org/10.1073/pnas.2015509117
-
[32]
Pennington and P
J. Pennington and P. Worah. The spectrum of the F isher information matrix of a single-hidden-layer neural network. In NeurIPS, 2018
2018
-
[33]
S. Plummer. Singular fluctuation as specific heat in B ayesian learning. arXiv:2512.21411, 2025
Pith/arXiv arXiv 2025
-
[34]
P. M. Riechers. Geometry and dynamics of LayerNorm . arXiv preprint arXiv:2405.04134, 2024. URL https://arxiv.org/abs/2405.04134
arXiv 2024
-
[35]
Roy and M
O. Roy and M. Vetterli. The effective rank: A measure of effective dimensionality. 15th European Signal Processing Conference (EUSIPCO), pages 606--610, 2007
2007
-
[36]
L. Sagun, U. Evci, V. U. G \"u ney, Y. Dauphin, and L. Bottou. Empirical analysis of the H essian of over-parametrized neural networks. In ICLR Workshop, 2018. arXiv:1706.04454
Pith/arXiv arXiv 2018
-
[37]
Sanyal, P
A. Sanyal, P. H. S. Torr, and P. K. Dokania. Stable rank normalization for improved generalization in neural networks and GAN s. In ICLR, 2020
2020
-
[38]
T. P. Shirodkar. Dead directions: Geometric singular learning, 2026. URL https://arxiv.org/abs/2606.05957
Pith/arXiv arXiv 2026
-
[39]
O. Sim \'e oni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al. DINOv3 . arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
- [40]
-
[41]
M. Sun, X. Chen, J. Z. Kolter, and Z. Liu. Massive activations in large language models. In COLM, 2024. URL https://arxiv.org/abs/2402.17762
Pith/arXiv arXiv 2024
-
[42]
G. Team. Gemma 2: Improving open language models at a practical size. Technical report, Google DeepMind, 2024 a . URL https://arxiv.org/abs/2408.00118. Documents the Peri-LN sandwich-norm pattern (pre-norm + post-norm RMSNorm) per-block in Gemma 2's Table 1
Pith/arXiv arXiv 2024
-
[43]
G. Team. Gemma: Open models based on gemini research and technology. Technical report, Google DeepMind, 2024 b . Original Gemma 1 release; pre-LN only RMSNorm with no post-norm wrapping per block; https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
2024
-
[44]
G. Team. Gemma 3 technical report. Technical report, Google DeepMind, 2025. URL https://arxiv.org/abs/2503.19786. Retains the sandwich-norm pattern of Gemma 2 and replaces logit soft-capping with QK-norm
Pith/arXiv arXiv 2025
-
[45]
G. Team. Gemma 4 technical report. Technical report, Google DeepMind, 2026 a . URL https://ai.google.dev/gemma/docs/core. Including E-variants with per-layer-embedding factorisation for on-device deployment
2026
-
[46]
Q. Team. Qwen3.5 technical report. Technical report, Alibaba, 2026 b . Qwen3.5 series model cards and architecture details on HuggingFace Hub; https://huggingface.co/Qwen
2026
-
[47]
Q. Team. Qwen3.6 technical report. Technical report, Alibaba, 2026 c . Qwen3.6 series (dense + sparse MoE) model cards and architecture details on HuggingFace Hub; https://huggingface.co/Qwen
2026
-
[48]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y. Xia, B. Mustafa, O. H \'e naff, J. Harmsen, A. Steiner, and X. Zhai. SigLIP 2 : Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[49]
G. Wang, J. Hoogland, S. van Wingerden, Z. Furman, and D. Murfet. Differentiation and specialization of attention heads via the refined local learning coefficient, 2024. URL https://arxiv.org/abs/2410.02984
arXiv 2024
-
[50]
J. Wang, X. Ge, W. Shu, Z. He, and X. Qiu. Dimensional collapse in transformer attention outputs: A challenge for sparse dictionary learning. arXiv preprint arXiv:2508.16929, 2025. URL https://arxiv.org/abs/2508.16929
arXiv 2025
-
[51]
Cambridge Monographs on Applied and Computational Mathematics, vol
S. Watanabe. Algebraic Geometry and Statistical Learning Theory. Cambridge University Press, 2009. URL https://doi.org/10.1017/CBO9780511800474
- [52]
-
[53]
Y. Xu. Spectral edge dynamics of training trajectories: Signal--noise geometry across scales. arXiv:2603.15678, 2026
arXiv 2026
-
[54]
Z. Yao, A. Gholami, K. Keutzer, and M. W. Mahoney. PyHessian : Neural networks through the lens of the H essian. In IEEE BigData, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.