Enabling Robust Cloth Manipulation via Inference-Time Simulator-in-the-Loop Refinement
Pith reviewed 2026-06-25 23:44 UTC · model grok-4.3
The pith
Simulator-in-the-loop refinement raises success rates for real-robot cloth manipulation from single RGB views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
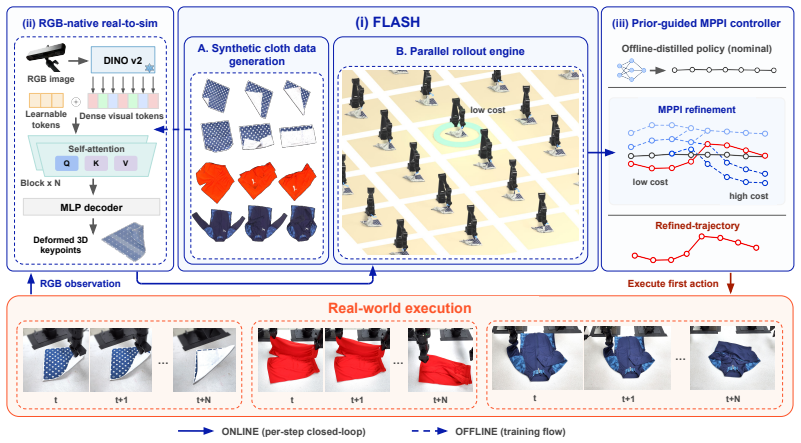
By training a real-to-sim module purely on synthetic data to map a single RGB observation to simulation-compatible cloth state via fused visual features and canonical tokens, then coupling a sparse-mesh FLASH simulator with prior-guided MPPI for online trajectory refinement, the method produces higher success rates and stronger robustness on real robots than baseline approaches.
What carries the argument
The real-to-sim module that fuses pretrained visual features with learnable canonical tokens to output simulation-compatible cloth states for subsequent MPPI rollouts inside the FLASH deformable simulator.
If this is right
- Manipulation policies can be refined online without additional real-world data collection for the state estimator.
- Sparse-mesh rollouts preserve enough deformation and contact detail to support parallel batch planning at inference time.
- Anchoring MPPI to an offline-distilled policy trajectory keeps the search focused on manipulation-relevant behaviors.
- The approach scales synthetic data generation to support both training of the state mapper and runtime planning.
Where Pith is reading between the lines
- If the same real-to-sim plus MPPI structure works for cloth, it may apply to other deformable objects whose simulators offer comparable stability and speed.
- Replacing the current visual backbone with stronger pretrained features could further reduce the sim-to-real gap without changing the rest of the pipeline.
- The method's reliance on a single RGB view suggests it could be tested on multi-view or depth-augmented inputs to measure additional robustness gains.
Load-bearing premise
The real-to-sim module trained only on synthetic data produces cloth states accurate enough that MPPI plans transfer to the physical robot.
What would settle it
A trial in which the real-to-sim module's output states produce MPPI trajectories that consistently fail on the physical robot while the same trajectories succeed when the true cloth configuration is supplied to the simulator.
Figures


read the original abstract
Simulator-in-the-loop optimization offers a promising inference-time mechanism for robot manipulation. It uses a physical simulator as a backend rollout engine to evaluate candidate trajectories in parallel and refine nominal actions online, a paradigm proven effective in rigid-body manipulation where state and contact are relatively tractable. We bring this paradigm to real-world cloth manipulation from a single RGB input through three pillars. (i) We design a scalable synthetic-data generation and inference-time rollout pipeline built on FLASH, a deformable-object simulator that provides a practical balance among physical fidelity, numerical stability, and rollout efficiency. (ii) We develop a real-to-sim module, trained purely on synthetic data, that maps a single RGB observation to simulation-compatible cloth state by fusing pretrained visual features with learnable canonical tokens. (iii) We perform online planning by coupling a sparse-mesh rollout backend with prior-guided MPPI, anchored at an offline-distilled policy trajectory, preserving manipulation-relevant deformation and contact while enabling sufficient parallel rollout batches. Real-robot experiments show higher success rates and stronger robustness than baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an inference-time simulator-in-the-loop method for single-RGB cloth manipulation. It introduces three pillars: (i) a scalable synthetic-data pipeline using the FLASH deformable simulator, (ii) a real-to-sim module trained only on synthetic RGB-to-state pairs via pretrained visual features and learnable canonical tokens, and (iii) sparse-mesh MPPI planning anchored to an offline-distilled policy trajectory. The central claim is that real-robot experiments demonstrate higher success rates and greater robustness than baseline methods.
Significance. If the empirical results hold under rigorous evaluation, the work would demonstrate a practical route to robust deformable manipulation by coupling a synthetic-trained state estimator with online simulator rollouts, reducing reliance on real-world data collection while preserving contact and deformation fidelity.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the claim of higher success rates and stronger robustness is asserted without any reported quantitative success rates, baseline definitions, statistical significance tests, or failure-mode analysis, preventing assessment of the central empirical result.
- [Pillar (ii)] Pillar (ii), real-to-sim module: the module is trained exclusively on synthetic RGB-to-state pairs with no real data; no quantitative bound (e.g., mean vertex-position error or contact-point accuracy) is supplied on reconstruction fidelity, yet the manuscript acknowledges that small state errors can produce qualitatively different deformation and contact sequences under FLASH, directly threatening MPPI transfer validity.
minor comments (1)
- [Pillar (iii)] Clarify how the sparse-mesh representation in pillar (iii) preserves manipulation-relevant contact points relative to the full FLASH mesh.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical presentation and the real-to-sim evaluation. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim of higher success rates and stronger robustness is asserted without any reported quantitative success rates, baseline definitions, statistical significance tests, or failure-mode analysis, preventing assessment of the central empirical result.
Authors: We agree that the abstract and experiments section require quantitative support to substantiate the central claim. The current manuscript asserts higher success rates without embedding specific percentages, trial counts, baseline definitions, statistical tests, or failure-mode breakdowns in those sections. We will revise the abstract to include key quantitative results and expand the experiments section to explicitly define all baselines, report success rates with the number of trials, include statistical significance testing, and add a dedicated failure-mode analysis. revision: yes
-
Referee: [Pillar (ii)] Pillar (ii), real-to-sim module: the module is trained exclusively on synthetic RGB-to-state pairs with no real data; no quantitative bound (e.g., mean vertex-position error or contact-point accuracy) is supplied on reconstruction fidelity, yet the manuscript acknowledges that small state errors can produce qualitatively different deformation and contact sequences under FLASH, directly threatening MPPI transfer validity.
Authors: The real-to-sim module is trained exclusively on synthetic data, as stated. No quantitative reconstruction fidelity bound is currently supplied. We will add an evaluation reporting mean vertex-position error and contact-point accuracy on held-out synthetic test pairs. We will also expand the discussion of state-error sensitivity to explain how the prior-guided MPPI and end-to-end real-robot results support transfer. A direct quantitative bound on real-image reconstruction fidelity cannot be provided without real data collection and evaluation, which was outside the scope of this work; the real-robot task success serves as the primary validation of the integrated pipeline. revision: partial
- A quantitative bound on real reconstruction fidelity for the real-to-sim module cannot be supplied, as the module was trained and designed without any real data.
Circularity Check
Empirical pipeline with no derivation chain
full rationale
The manuscript presents a three-pillar empirical pipeline (synthetic data generation on FLASH, real-to-sim module trained exclusively on synthetic RGB-to-state pairs, and prior-guided MPPI planning) whose central claims are validated by real-robot success rates rather than any first-principles derivation or prediction. No equations, fitted parameters, or uniqueness theorems appear in the provided text, so none of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) can be exhibited by direct quotation and reduction. The approach is therefore self-contained as a practical engineering method whose validity is external to any internal mathematical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Zhu, A. Cherubini, C. Dune, D. Navarro-Alarcon, F. Alambeigi, D. Berenson, F. Ficuciello, K. Harada, J. Kober, X. Li, et al. Challenges and outlook in robotic manipulation of deformable objects.IEEE Robotics & Automation Magazine, 29(3):67–77, 2022
2022
-
[2]
V . E. Arriola-Rios, P. Guler, F. Ficuciello, D. Kragic, B. Siciliano, and J. L. Wyatt. Modeling of deformable objects for robotic manipulation: A tutorial and review.Frontiers in Robotics and AI, 7:82, 2020
2020
-
[3]
X. Lin, Y . Wang, J. Olkin, and D. Held. Softgym: Benchmarking deep reinforcement learning for deformable object manipulation. InProceedings of the 2020 Conference on Robot Learn- ing, volume 155 ofProceedings of Machine Learning Research, pages 432–448, 16–18 Nov 2021
2020
-
[4]
W. Hu, X. Tang, Y . Li, Z. Shu, W. Li, H. Wang, R. Yang, et al. Real garment benchmark (rgbench): A comprehensive benchmark for robotic garment manipulation featuring a high- fidelity scalable simulator.arXiv preprint arXiv:2511.06434, 2025
arXiv 2025
-
[5]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. C. Burchfiel, and S. Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023
2023
-
[6]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile ALOHA: Learning bimanual mobile manipulation with low-cost whole-body teleoperation. InConference on Robot Learning (CoRL), 2024
2024
-
[7]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3D diffusion policy: Generalizable visuomotor policy learning via simple 3D representations. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[8]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems, 2023
2023
-
[9]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[10]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[11]
S. Yang, Y . Du, K. Ghasemipour, J. Tompson, L. P. Kaelbling, D. Schuurmans, and P. Abbeel. Learning interactive real-world simulators. InInternational Conference on Learning Repre- sentations (ICLR), 2024
2024
-
[12]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end- to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026. 9
Pith/arXiv arXiv 2026
-
[13]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[14]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[15]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, et al. Open x-embodiment: Robotic learning datasets and rt-x models : Open x-embodiment collaboration0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903, 2024
2024
-
[16]
T. Tian, H. Li, B. Ai, X. Yuan, Z. Huang, and H. Su. Diffusion dynamics models with gener- ative state estimation for cloth manipulation. InProceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 1703–1725, 27– 30 Sep 2025
2025
- [17]
-
[18]
S. Luo, B. Zhou, C. Zhang, X. Liu, Z. Huang, G. Yang, Z. Han, X. Hu, E. Yang, R. Yu, et al. Flash: Fast learning via gpu-accelerated simulation for high-fidelity deformable manipulation in minutes.arXiv preprint arXiv:2604.17513, 2026
Pith/arXiv arXiv 2026
-
[19]
Xiang, T
Y . Xiang, T. Schmidt, V . Narayanan, and D. Fox. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. InProceedings of Robotics: Science and Systems, Pittsburgh, Pennsylvania, June 2018
2018
-
[20]
B. Wen, J. Tremblay, V . Blukis, S. Tyree, T. M¨uller, A. Evans, D. Fox, J. Kautz, and S. Birch- field. Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 606–617, 2023
2023
-
[21]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17868–17879, 2024
2024
-
[22]
Chi and S
C. Chi and S. Song. Garmentnets: Category-level pose estimation for garments via canonical space shape completion. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3304–3313, 2021
2021
-
[23]
Huang, X
Z. Huang, X. Lin, and D. Held. Mesh-based Dynamics with Occlusion Reasoning for Cloth Manipulation. InProceedings of Robotics: Science and Systems, New York City, NY , USA, June 2022
2022
-
[24]
Longhini, M
A. Longhini, M. B ¨usching, B. P. Duisterhof, J. Lundell, J. Ichnowski, M. Bj ¨orkman, and D. Kragic. Cloth-splatting: 3d cloth state estimation from rgb supervision. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 2845–2865, 06–09 Nov 2025
2025
-
[25]
H. Chen, J. Li, R. Wu, Y . Liu, Y . Hou, Z. Xu, J. Guo, C. Gao, Z. Wei, S. Xu, J. Huang, and L. Shao. Metafold: Language-guided multi-category garment folding framework via trajectory generation and foundation model. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4339–4346, 2025
2025
-
[26]
Deng and D
Y . Deng and D. Hsu. General-purpose clothes manipulation with semantic keypoints. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13181–13187, 2025. 10
2025
-
[27]
Y . Ru, L. Zhuang, Z. He, F. P. Audonnet, and G. Aragon-Caramasa. Can real-to-sim ap- proaches capture dynamic fabric behavior for robotic fabric manipulation?arXiv preprint arXiv:2503.16310, 2025
arXiv 2025
-
[28]
Isaac Sim.https://github.com/isaac-sim/IsaacSim, 2025
NVIDIA. Isaac Sim.https://github.com/isaac-sim/IsaacSim, 2025
2025
-
[29]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su. Sapien: A simulated part-based interactive environment. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11094–11104, 2020
2020
-
[30]
G. Authors. Genesis: A generative and universal physics engine for robotics and beyond, December 2024. URLhttps://github.com/Genesis-Embodied-AI/Genesis
2024
-
[31]
Pfaff, M
T. Pfaff, M. Fortunato, A. Sanchez-Gonzalez, and P. Battaglia. Learning mesh-based simula- tion with graph networks. InInternational Conference on Learning Representations, 2021
2021
-
[32]
Y . Li, J. Wu, R. Tedrake, J. B. Tenenbaum, and A. Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. InInternational Conference on Learning Representations, 2019
2019
-
[33]
X. Lin, Y . Wang, Z. Huang, and D. Held. Learning visible connectivity dynamics for cloth smoothing. InProceedings of the 5th Conference on Robot Learning, volume 164 ofProceed- ings of Machine Learning Research, pages 256–266, 08–11 Nov 2022
2022
-
[34]
Zhang, B
K. Zhang, B. Li, K. Hauser, and Y . Li. AdaptiGraph: Material-Adaptive Graph-Based Neural Dynamics for Robotic Manipulation. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024
2024
-
[35]
W. Chen, K. Li, D. Lee, X. Chen, R. Zong, and P. Kormushev. Graphgarment: Learning garment dynamics for bimanual cloth manipulation tasks. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7615–7621, 2025
2025
-
[36]
P. I. Frazier. A tutorial on bayesian optimization.arXiv preprint arXiv:1807.02811, 2018
Pith/arXiv arXiv 2018
-
[37]
Theodorou, J
E. Theodorou, J. Buchli, and S. Schaal. A generalized path integral control approach to rein- forcement learning.Journal of Machine Learning Research, 11(104):3137–3181, 2010
2010
-
[38]
H. J. Suh, M. Simchowitz, K. Zhang, and R. Tedrake. Do differentiable simulators give better policy gradients? InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 20668–20696, 17–23 Jul 2022
2022
-
[39]
R. Y . Rubinstein and D. P. Kroese.The Cross-Entropy Method: A Unified Approach to Com- binatorial Optimization, Monte-Carlo Simulation and Machine Learning. Springer Science & Business Media, 2004
2004
-
[40]
Williams, P
G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou. Aggressive driving with model predictive path integral control. In2016 IEEE International Conference on Robotics and Automation (ICRA), pages 1433–1440, 2016
2016
-
[41]
Williams, A
G. Williams, A. Aldrich, and E. A. Theodorou. Model predictive path integral control: From theory to parallel computation.Journal of Guidance, Control, and Dynamics, 40(2):344–357, 2017
2017
-
[42]
N. A. Hansen, H. Su, and X. Wang. Temporal difference learning for model predictive control. InProceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 8387–8406, 17–23 Jul 2022. 11
2022
-
[43]
Hansen, H
N. Hansen, H. Su, and X. Wang. TD-MPC2: Scalable, robust world models for continuous control. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[44]
J. Yin, Z. Zhang, E. Theodorou, and P. Tsiotras. Trajectory distribution control for model predictive path integral control using covariance steering. In2022 International Conference on Robotics and Automation (ICRA), pages 1478–1484, 2022
2022
-
[45]
Z. Yi, C. Pan, G. He, G. Qu, and G. Shi. CoVO-MPC: Theoretical analysis of sampling- based MPC and optimal covariance design. InProceedings of the 6th Annual Learning for Dynamics & Control Conference, volume 242 ofProceedings of Machine Learning Research, pages 1122–1135, 15–17 Jul 2024
2024
-
[46]
Trevisan and J
E. Trevisan and J. Alonso-Mora. Biased-mppi: Informing sampling-based model predictive control by fusing ancillary controllers.IEEE Robotics and Automation Letters, 9(6):5871– 5878, 2024
2024
-
[47]
H. Xue, C. Pan, Z. Yi, G. Qu, and G. Shi. Full-order sampling-based mpc for torque-level locomotion control via diffusion-style annealing. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4974–4981, 2025
2025
-
[48]
Ha and S
H. Ha and S. Song. Flingbot: The unreasonable effectiveness of dynamic manipulation for cloth unfolding. In5th Annual Conference on Robot Learning, 2021
2021
-
[49]
Matas, S
J. Matas, S. James, and A. J. Davison. Sim-to-real reinforcement learning for deformable object manipulation. InProceedings of The 2nd Conference on Robot Learning, volume 87 of Proceedings of Machine Learning Research, pages 734–743, 29–31 Oct 2018
2018
-
[50]
Jangir, G
R. Jangir, G. Aleny `a, and C. Torras. Dynamic cloth manipulation with deep reinforcement learning. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 4630–4636, 2020
2020
-
[51]
Z. Zeng, S. Luo, F. Shi, and Z. Zhang. Fast but accurate: A real-time hyperelastic simulator with robust frictional contact.ACM Trans. Graph., 44(4), July 2025
2025
-
[52]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Dol- lar, and C. Feichtenhofer. SAM 2: Segment anything in images and videos. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[53]
Bernardini, J
F. Bernardini, J. Mittleman, H. Rushmeier, C. Silva, and G. Taubin. The ball-pivoting algorithm for surface reconstruction.IEEE Transactions on Visualization and Computer Graphics, 5(4): 349–359, 1999
1999
-
[54]
Botsch and L
M. Botsch and L. Kobbelt. A remeshing approach to multiresolution modeling. InProceed- ings of the 2004 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing, page 185–192, New York, NY , USA, 2004
2004
-
[55]
G. Taubin. A signal processing approach to fair surface design. InProceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’95, page 351–358, New York, NY , USA, 1995. Association for Computing Machinery. ISBN 0897917014
1995
-
[56]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without s...
2024
-
[57]
Newton: GPU-accelerated physics simulation for robotics and sim- ulation research.https://github.com/newton-physics/newton, Apr
The Newton Contributors. Newton: GPU-accelerated physics simulation for robotics and sim- ulation research.https://github.com/newton-physics/newton, Apr. 2025
2025
-
[58]
M. Patel, J. Frey, M. Mittal, F. Yang, A. Hansson, A. Bar, C. Cadena, and M. Hutter. DeFM: Learning foundation representations from depth for robotics.arXiv preprint arXiv:2601.18923, 2026. 13 Appendix A Implementation Details This section provides the full implementation details of the two modules introduced in the main paper. We describe the RGB-native ...
arXiv 2026
-
[59]
A learnable linear projectionP:R 384 →R d maps each patch token to the model dimensiond= 256
The392×392input yieldsM v = (392/14)2 = 784dense patch tokens at the backbone hidden dimensiond vit = 384. A learnable linear projectionP:R 384 →R d maps each patch token to the model dimensiond= 256. Canonical Tokens.We maintainNlearnable canonical tokensC={c i}N i=1 ∈R N×d , one per mesh vertex (N= 464for the towel,N= 1156for the pants, andN= 1379for th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.