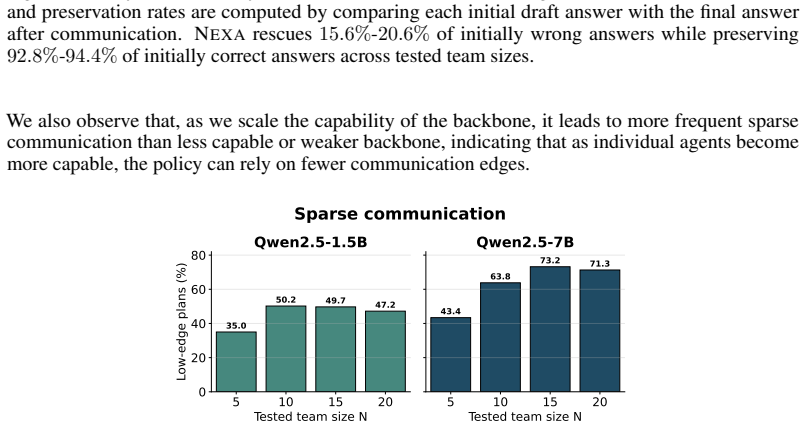
Response-Conditioned Parallel-to-Sequential Orchestration for Multi-Agent Systems
Pith reviewed 2026-05-20 19:24 UTC · model grok-4.3
The pith
A lightweight transformer learns to predict when to insert one sequential communication step after parallel LLM agent responses, and the same policy works across different agent counts, tasks, and base models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Nexa formalizes hybrid execution as a response-conditioned policy that, after parallel responses, predicts a sparse directed acyclic graph; an empty graph leaves the system in pure parallel mode while a non-empty graph triggers exactly one round of sequential message propagation. The framework is acyclic by construction, strictly contains pure parallel execution, and the policy is trained with policy-gradient optimization on response embeddings without external LLM judges or test-time topology search. The learned policy transfers across changes in agent count, task, or base agent models.
What carries the argument
Nexa, the response-conditioned policy realized as a lightweight transformer that maps parallel response embeddings to a sparse directed acyclic communication graph for optional one-step sequential refinement.
If this is right
- Pure parallel execution occurs automatically whenever the predicted graph is empty.
- The communication graph remains acyclic because of the way the policy constructs it.
- The hybrid method includes pure parallel execution with zero added communication cost as a special case.
- A policy trained once can be reused without retraining when the number of agents, the task, or the base models change.
- Training requires only policy-gradient updates on response embeddings and avoids external LLM judges or hand-designed topology search.
Where Pith is reading between the lines
- The transfer result suggests the policy could support runtime changes in agent population without retraining the orchestrator.
- Because the method embeds responses rather than relying on fixed topologies, it might reduce manual engineering when new multi-agent tasks are introduced.
- The single-step sequential addition could be tested for extension to two or three conditioned steps on tasks where deeper refinement is known to help.
- Absence of a separate reward model may allow the same policy head to attach to pipelines that already score final answer quality.
Load-bearing premise
A lightweight transformer trained via policy gradient on response embeddings can reliably predict useful sparse communication graphs that improve accuracy without external judges or reward models.
What would settle it
Train the policy on responses from one task and agent count, then apply it unchanged to a new task or different agent count and check whether accuracy rises or latency falls compared with pure parallel execution on the new setting.
Figures







read the original abstract
Multi-agent systems can solve complex tasks through collaboration between multiple Large Language Model agents. Existing collaboration frameworks typically operate in either a parallel or a sequential mode. In the parallel mode, agents respond independently to queries followed by aggregation of responses. In contrast, sequential systems allow agents to communicate via a directed topology and refine one another step by step. However, both modes are inadequate for achieving the desired objectives of minimizing communication and latency while simultaneously maximizing the accuracy of the final response. In this work, we introduce a hybrid paradigm called Nexa, a trainable response-conditioned policy that bridges the gap between the two modes. Nexa begins with a parallel execution stage, embeds the resulting responses into a shared semantic space, and then predicts a sparse directed acyclic communication graph. If the graph is empty, the system remains purely parallel; if it is non-empty, the system performs one sequential message propagation. The policy is a lightweight transformer model, and the method avoids the need for external LLM judges or reward models, as well as hand-crafted test-time topology search. We formalize this hybrid execution problem, show that the resulting graph is acyclic by construction, and that the framework strictly subsumes pure parallel execution, and present a training procedure based on policy-gradient optimization. Results demonstrate that the response-conditioned policy learned by Nexa under one setting can be reused when the number of agents, the task, or the underlying agent changes, thus emphasizing the generalizability of the learned communication policy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Nexa, a hybrid orchestration framework for multi-agent LLM systems. It begins with parallel agent responses to a query, embeds those responses into a shared semantic space, and uses a lightweight transformer policy to predict a sparse directed acyclic graph (DAG) that governs a single round of sequential message propagation. The framework is claimed to be acyclic by construction, to strictly subsume pure parallel execution (via the empty-graph case), to require no external LLM judges or hand-crafted topology search, and to admit policy-gradient training; experiments are said to show that the learned response-conditioned policy generalizes when the number of agents, the task, or the base models change.
Significance. If the empirical generalization results hold, the work would provide a practical, reusable mechanism for trading off communication cost against accuracy in multi-agent LLM collaboration without per-instance search or external reward models. The explicit subsumption of parallel mode and the acyclicity guarantee are clean formal properties that could be useful for system design.
major comments (2)
- [Abstract] Abstract: the central claim that 'the response-conditioned policy learned by Nexa under one setting can be reused when the number of agents, the task, or the underlying agent changes' is load-bearing for the contribution, yet the abstract (and the manuscript as described) supplies no quantitative results, no evaluation protocol, and no details on how transfer across embedding distributions was measured. Without such evidence the transfer property remains an unverified assumption.
- [Abstract] Abstract: although the text states that the hybrid execution problem is formalized and that a training procedure based on policy-gradient optimization is presented, no equations appear for the policy, the objective, the DAG construction, or the acyclicity proof. The absence of these formal elements makes it impossible to verify the claimed 'acyclicity by construction' or the strict subsumption of parallel mode.
minor comments (2)
- [Abstract] The phrase 'underlying agent' is ambiguous; it should be clarified whether it refers to the base LLM, the prompt template, or another component.
- A diagram showing the parallel stage, embedding step, DAG prediction, and single propagation round would substantially improve readability of the hybrid execution flow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and indicate the revisions we will make to strengthen the presentation of our claims and formal elements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the response-conditioned policy learned by Nexa under one setting can be reused when the number of agents, the task, or the underlying agent changes' is load-bearing for the contribution, yet the abstract (and the manuscript as described) supplies no quantitative results, no evaluation protocol, and no details on how transfer across embedding distributions was measured. Without such evidence the transfer property remains an unverified assumption.
Authors: We appreciate this observation regarding the load-bearing nature of the generalization claim. The full manuscript reports quantitative transfer results in the experiments section, including accuracy retention rates and communication savings when the policy trained under one agent count or task is applied to new agent counts (e.g., 3 to 5 agents), different tasks, and alternate base models, with an evaluation protocol that measures performance on held-out configurations without retraining. To address the concern directly in the abstract, we will revise it to include concise quantitative highlights and a brief reference to the transfer evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract: although the text states that the hybrid execution problem is formalized and that a training procedure based on policy-gradient optimization is presented, no equations appear for the policy, the objective, the DAG construction, or the acyclicity proof. The absence of these formal elements makes it impossible to verify the claimed 'acyclicity by construction' or the strict subsumption of parallel mode.
Authors: We agree that the abstract, due to length constraints, omits explicit equations. The main body formalizes the hybrid execution problem, defines the lightweight transformer policy that predicts edge probabilities for the sparse DAG, presents the policy-gradient training objective, details the DAG construction procedure, and includes the proof of acyclicity by construction together with the strict subsumption of the parallel (empty-graph) case. We will add a short formal overview subsection early in the paper that explicitly states the key equations and proof outline to improve verifiability. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's formal claims—that the predicted graph is acyclic by construction and that the framework strictly subsumes pure parallel execution via the empty-graph case—follow directly from the one-round parallel execution followed by optional single propagation design, without reducing to fitted parameters or prior self-referential results. The training procedure is described as policy-gradient optimization without external judges or reward models, indicating an objective defined externally to the policy itself. The reported reusability of the response-conditioned policy across agent counts, tasks, or base models is presented as an empirical experimental outcome rather than a first-principles derivation or prediction forced by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the abstract or described chain.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The predicted communication graph is acyclic by construction
- domain assumption The hybrid framework strictly subsumes pure parallel execution
invented entities (1)
-
Nexa response-conditioned policy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Fourteenth International Conference on Learning Representations , year =
Stochastic Self-Organization in Multi-Agent Systems , author =. The Fourteenth International Conference on Learning Representations , year =
-
[2]
Proceedings of the 41st International Conference on Machine Learning , pages =
Zhuge, Mingchen and Wang, Wenyi and Kirsch, Louis and Faccio, Francesco and Khizbullin, Dmitrii and Schmidhuber, J\". Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
work page 2024
-
[3]
Cut the Crap: An Economical Communication Pipeline for
Guibin Zhang and Yanwei Yue and Zhixun Li and Sukwon Yun and Guancheng Wan and Kun Wang and Dawei Cheng and Jeffrey Xu Yu and Tianlong Chen , booktitle=. Cut the Crap: An Economical Communication Pipeline for. 2025 , url=
work page 2025
-
[4]
Forty-second International Conference on Machine Learning , year=
G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks , author=. Forty-second International Conference on Machine Learning , year=
-
[5]
Gradient Driven Rewards to Guarantee Fairness in Collaborative Machine Learning , url =
Xu, Xinyi and Lyu, Lingjuan and Ma, Xingjun and Miao, Chenglin and Foo, Chuan Sheng and Low, Bryan Kian Hsiang , booktitle =. Gradient Driven Rewards to Guarantee Fairness in Collaborative Machine Learning , url =
-
[6]
Qingyun Wu and Gagan Bansal and Jieyu Zhang and Yiran Wu and Beibin Li and Erkang Zhu and Li Jiang and Xiaoyun Zhang and Shaokun Zhang and Jiale Liu and Ahmed Hassan Awadallah and Ryen W White and Doug Burger and Chi Wang , booktitle=. AutoGen: Enabling Next-Gen. 2024 , url=
work page 2024
-
[7]
arXiv preprint arXiv:2505.24239 , year=
An Adversary-Resistant Multi-Agent LLM System via Credibility Scoring , author=. arXiv preprint arXiv:2505.24239 , year=
-
[8]
arXiv preprint arXiv:2505.16997 , year=
X-MAS: Towards Building Multi-Agent Systems with Heterogeneous LLMs , author=. arXiv preprint arXiv:2505.16997 , year=
-
[9]
Rui Ye and Shuo Tang and Rui Ge and Yaxin Du and Zhenfei Yin and Siheng Chen and Jing Shao , booktitle=. 2025 , url=
work page 2025
-
[10]
arXiv preprint arXiv:2505.16988 , year=
MASLab: A Unified and Comprehensive Codebase for LLM-based Multi-Agent Systems , author=. arXiv preprint arXiv:2505.16988 , year=
-
[11]
The Thirteenth International Conference on Learning Representations , year=
Scaling Large Language Model-based Multi-Agent Collaboration , author=. The Thirteenth International Conference on Learning Representations , year=
-
[12]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and Aiesha Letman and Akhil Mathur and Alan Schelten and Amy Yang and Angela Fan and Anirudh Goyal and Anthony Hartshorn and Aobo Yang and Archi Mitra and Archie Sravankumar and Artem Korenev and Arthur Hinsvark and Arun Rao and Aston Zhang and Aurélien Rodriguez ...
work page 2024
- [14]
-
[15]
Guohao Li and Hasan Abed Al Kader Hammoud and Hani Itani and Dmitrii Khizbullin and Bernard Ghanem , booktitle=. 2023 , url=
work page 2023
-
[16]
C hat D ev: Communicative Agents for Software Development
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong. C hat D ev: Communicative Agents for Software Development. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
-
[17]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[19]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
work page 2019
-
[20]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
Redefining Contributions: Shapley-Driven Federated Learning , author =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,. 2024 , month =
work page 2024
-
[21]
Transactions on Machine Learning Research , issn=
Nurbek Tastan and Samuel Horv. Transactions on Machine Learning Research , issn=. 2025 , url=
work page 2025
-
[22]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Tastan, Nurbek and Horv\'. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
work page 2025
-
[23]
Contributions to the Theory of Games II , editor =
A Value for n-Person Games , author =. Contributions to the Theory of Games II , editor =. 1953 , publisher =
work page 1953
-
[24]
Federated Learning: Privacy and Incentive , pages=
Collaborative fairness in federated learning , author=. Federated Learning: Privacy and Incentive , pages=. 2020 , publisher=
work page 2020
-
[25]
Forty-first International Conference on Machine Learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first International Conference on Machine Learning , year=
-
[26]
The Thirteenth International Conference on Learning Representations , year=
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains , author=. The Thirteenth International Conference on Learning Representations , year=
-
[27]
Liang, Tian and He, Zhiwei and Jiao, Wenxiang and Wang, Xing and Wang, Yan and Wang, Rui and Yang, Yujiu and Shi, Shuming and Tu, Zhaopeng. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.992
-
[28]
The Twelfth International Conference on Learning Representations , year=
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , author=. The Twelfth International Conference on Learning Representations , year=
- [29]
-
[30]
The Thirteenth International Conference on Learning Representations , year=
Automated Design of Agentic Systems , author=. The Thirteenth International Conference on Learning Representations , year=
-
[31]
Jiayi Zhang and Jinyu Xiang and Zhaoyang Yu and Fengwei Teng and Xiong-Hui Chen and Jiaqi Chen and Mingchen Zhuge and Xin Cheng and Sirui Hong and Jinlin Wang and Bingnan Zheng and Bang Liu and Yuyu Luo and Chenglin Wu , booktitle=. 2025 , url=
work page 2025
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Tastan, Nurbek and Nandakumar, Karthik , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
work page 2023
-
[33]
Conference on Parsimony and Learning , pages =
Tastan, Nurbek and Horv\'. Conference on Parsimony and Learning , pages =. 2025 , editor =
work page 2025
-
[34]
Advances in Neural Information Processing Systems , volume=
Fjord: Fair and accurate federated learning under heterogeneous targets with ordered dropout , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
The Twelfth International Conference on Learning Representations , year=
Incentive-Aware Federated Learning with Training-Time Model Rewards , author=. The Twelfth International Conference on Learning Representations , year=
-
[36]
International Conference on Learning Representations , year=
Slimmable Neural Networks , author=. International Conference on Learning Representations , year=
- [37]
-
[38]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[39]
arXiv preprint arXiv:2106.07289 , year=
Decentralized personalized federated min-max problems , author=. arXiv preprint arXiv:2106.07289 , year=
-
[40]
EURO Journal on Computational Optimization , volume=
Decentralized personalized federated learning: Lower bounds and optimal algorithm for all personalization modes , author=. EURO Journal on Computational Optimization , volume=. 2022 , publisher=
work page 2022
-
[41]
arXiv preprint arXiv:2406.00846 , year=
Local Methods with Adaptivity via Scaling , author=. arXiv preprint arXiv:2406.00846 , year=
-
[42]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [43]
-
[44]
Generalizing AI: challenges and opportunities for plug and play AI solutions , author=. IEEE Network , volume=. 2020 , publisher=
work page 2020
-
[45]
arXiv preprint arXiv:2312.11230 , year=
Dirichlet-based uncertainty quantification for personalized federated learning with improved posterior networks , author=. arXiv preprint arXiv:2312.11230 , year=
-
[46]
arXiv preprint arXiv:2402.05050 , year=
Federated Learning Can Find Friends That Are Advantageous , author=. arXiv preprint arXiv:2402.05050 , year=
-
[47]
Federated Learning: Privacy and Incentive , pages=
A principled approach to data valuation for federated learning , author=. Federated Learning: Privacy and Incentive , pages=. 2020 , publisher=
work page 2020
-
[48]
Towards More Efficient Data Valuation in Healthcare Federated Learning Using Ensembling , author=. Distributed, Collaborative, and Federated Learning, and Affordable AI and Healthcare for Resource Diverse Global Health: Third MICCAI Workshop, DeCaF 2022, and Second MICCAI Workshop, FAIR 2022, Held in Conjunction with MICCAI 2022, Singapore, September 18 a...
work page 2022
-
[49]
Advances in neural information processing systems , volume=
Deep leakage from gradients , author=. Advances in neural information processing systems , volume=
-
[50]
Artificial intelligence and statistics , pages=
Communication-efficient learning of deep networks from decentralized data , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
work page 2017
-
[51]
How the GDPR will change the world , author=. Eur. Data Prot. L. Rev. , volume=. 2016 , publisher=
work page 2016
-
[52]
Beyond the HIPAA privacy rule: enhancing privacy, improving health through research , author=. 2009 , journal=
work page 2009
-
[53]
arXiv preprint arXiv:2001.02610 , year=
idlg: Improved deep leakage from gradients , author=. arXiv preprint arXiv:2001.02610 , year=
-
[54]
Learning multiple layers of features from tiny images , author=. 2009 , journal=
work page 2009
-
[55]
Christopher A. Choquette-Choo and Natalie Dullerud and Adam Dziedzic and Yunxiang Zhang and Somesh Jha and Nicolas Papernot and Xiao Wang , booktitle=. 2021 , url=
work page 2021
-
[56]
Cronus: Robust and Heterogeneous Collaborative Learning with Black-Box Knowledge Transfer,
Cronus: Robust and heterogeneous collaborative learning with black-box knowledge transfer , author=. arXiv preprint arXiv:1912.11279 , year=
-
[57]
The algorithmic foundations of differential privacy , author=. Foundations and Trends. 2014 , publisher=
work page 2014
-
[58]
International Conference on Machine Learning , pages=
The distributed discrete gaussian mechanism for federated learning with secure aggregation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[59]
arXiv preprint arXiv:2001.03618 , year=
Encode, shuffle, analyze privacy revisited: Formalizations and empirical evaluation , author=. arXiv preprint arXiv:2001.03618 , year=
-
[60]
Learning Differentially Private Recurrent Language Models
Learning differentially private recurrent language models , author=. arXiv preprint arXiv:1710.06963 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[62]
International conference on machine learning , pages=
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[63]
International Conference on Artificial Intelligence and Statistics , pages=
How to backdoor federated learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
work page 2020
-
[64]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
Towards fair federated learning , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
-
[65]
arXiv preprint arXiv:2303.16520 , year=
Fair Federated Medical Image Segmentation via Client Contribution Estimation , author=. arXiv preprint arXiv:2303.16520 , year=
-
[66]
Ogier du Terrail, Jean and Ayed, Samy-Safwan and Cyffers, Edwige and Grimberg, Felix and He, Chaoyang and Loeb, Regis and Mangold, Paul and Marchand, Tanguy and Marfoq, Othmane and Mushtaq, Erum and Muzellec, Boris and Philippenko, Constantin and Silva, Santiago and Tele\'. FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Hea...
-
[67]
Advances in Neural Information Processing Systems , volume=
Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
arXiv preprint arXiv:2011.10464 , year=
A reputation mechanism is all you need: Collaborative fairness and adversarial robustness in federated learning , author=. arXiv preprint arXiv:2011.10464 , year=
-
[69]
IEEE Transactions on Big Data , year=
FedFAIM: A Model Performance-based Fair Incentive Mechanism for Federated Learning , author=. IEEE Transactions on Big Data , year=
-
[70]
International Journal of Computer Vision , volume=
Knowledge distillation: A survey , author=. International Journal of Computer Vision , volume=. 2021 , publisher=
work page 2021
-
[71]
IEEE Internet of Things Journal , volume=
Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory , author=. IEEE Internet of Things Journal , volume=. 2019 , publisher=
work page 2019
-
[72]
Proceedings of the Web Conference 2021 , pages=
Incentive mechanism for horizontal federated learning based on reputation and reverse auction , author=. Proceedings of the Web Conference 2021 , pages=
work page 2021
-
[73]
To federate or not to federate: incentivizing client participation in federated learning , author=. Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022) , year=
work page 2022
-
[74]
arXiv preprint arXiv:2205.14840 , year=
Maximizing global model appeal in federated learning , author=. arXiv preprint arXiv:2205.14840 , year=
-
[75]
The MNIST database of handwritten digits , author=. http://yann. lecun. com/exdb/mnist/ , year=
-
[76]
Proceedings of the VLDB Endowment , volume=
Distributed learning of fully connected neural networks using independent subnet training , author=. Proceedings of the VLDB Endowment , volume=
-
[77]
The Eleventh International Conference on Learning Representations , year=
Sparse Random Networks for Communication-Efficient Federated Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[78]
Federated Optimization in Heterogeneous Networks , url =
Li, Tian and Sahu, Anit Kumar and Zaheer, Manzil and Sanjabi, Maziar and Talwalkar, Ameet and Smith, Virginia , booktitle =. Federated Optimization in Heterogeneous Networks , url =
-
[79]
Advances and open problems in federated learning , author=. Foundations and trends. 2021 , publisher=
work page 2021
-
[80]
Advances in neural information processing systems , volume=
Tackling the objective inconsistency problem in heterogeneous federated optimization , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.