Breaking chains with trees: Deep learning with mathcal{O}(log N) parallel time complexity
Pith reviewed 2026-06-26 14:26 UTC · model grok-4.3
The pith
Hierarchical Block-Local Learning trains deep neural networks in O(log N) parallel time by using local objectives on hierarchically linked blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
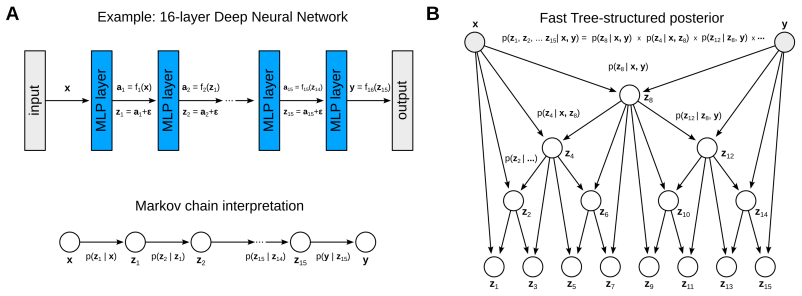
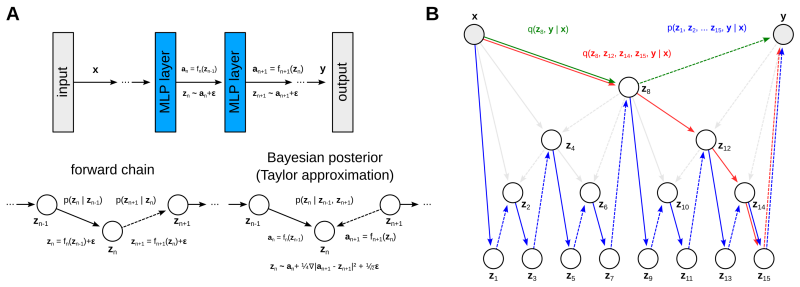
HBLL is the first algorithm able to train deep neural networks in O(log N) parallel time complexity by decomposing them into hierarchically linked blocks trained using local learning objectives derived from variational principles, eliminating the need for full end-to-end backpropagation while maintaining effective information propagation across the network.
What carries the argument
The Hierarchical Block-Local Learning (HBLL) framework that decomposes networks into hierarchically linked blocks for local variational training.
If this is right
- Training updates can proceed in parallel across different hierarchical levels rather than waiting for sequential error propagation.
- The weight transport problem is avoided since no symmetric backward pass is required.
- Multiple subnetworks corresponding to different hierarchical paths enable inference with varying numbers of effective layers.
- The approach applies to recurrent architectures without requiring backpropagation through time.
Where Pith is reading between the lines
- This could allow scaling to much deeper networks than currently feasible with backpropagation.
- Hardware accelerators might be redesigned to exploit the block-parallel structure for higher efficiency.
- The family of subnetworks suggests applications in model ensembling or adaptive computation during inference.
Load-bearing premise
That local learning objectives derived from variational principles can eliminate the need for full end-to-end backpropagation while still maintaining effective information propagation across the entire network.
What would settle it
Demonstrating that on a network with many layers the observed parallel training time scales linearly rather than logarithmically, or that accuracy on the reported tasks is significantly lower than backpropagation.
Figures
read the original abstract
Modern deep neural network architectures are trained via backpropagation, which requires errors to be sequentially propagated through all layers before parameters can be updated. This introduces two limitations: locking, where layer-wise updates are strictly interdependent and cannot proceed in parallel, and the weight transport problem, which requires symmetric forward and backward pathways for exact gradient computation. These constraints restrict parallelism, increase memory and communication overhead, and pose challenges for scalable learning. In this work, we propose Hierarchical Block-Local Learning (HBLL), a framework that decomposes deep neural networks into hierarchically linked blocks trained using local learning objectives derived from variational principles, eliminating the need for full end-to-end backpropagation while maintaining effective information propagation across the network. HBLL is the first algorithm that is able to train deep neural networks in $\mathcal{O}(\log N)$ parallel time complexity, where $N$ is the number of network layers. We show that HBLL implicitly defines a family of subnetworks corresponding to different hierarchical paths, enabling flexible inference with different effective numbers of layers. We evaluate HBLL on a set of challenging vision and language modeling tasks, achieving competitive performance. We also extend HBLL to recurrent sequence architectures, applying to settings that otherwise rely on backpropagation through time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hierarchical Block-Local Learning (HBLL), a framework that decomposes deep neural networks into hierarchically linked blocks trained with local learning objectives derived from variational principles. This is claimed to remove the need for full end-to-end backpropagation, solve locking and weight-transport issues, and achieve O(log N) parallel training time complexity (N = number of layers) while delivering competitive performance on vision and language tasks and extending to recurrent architectures. The method is also said to implicitly define families of subnetworks corresponding to different hierarchical paths.
Significance. If the O(log N) parallel-time claim and performance results hold with a correct derivation that local variational objectives preserve effective credit assignment, the work would constitute a significant contribution to scalable deep learning by enabling logarithmic parallelism without end-to-end gradient pathways.
major comments (2)
- [Abstract] Abstract (paragraph on HBLL framework): the central O(log N) parallel-time claim requires that updates from local variational objectives compose to approximate the global gradient at every level of the hierarchy. No derivation, error analysis, or proof is supplied showing that the variational relaxation preserves long-range credit assignment rather than introducing bias that would leave effective depth linear.
- [Abstract] Abstract (claim of being 'the first algorithm'): the statement that HBLL is the first method achieving O(log N) parallel time rests on the unproven assumption that hierarchical local objectives transmit usable signals from output to input without any end-to-end pathway; this assumption is load-bearing and unsupported by any complexity argument or convergence analysis in the visible text.
minor comments (1)
- [Abstract] Abstract: the description of 'implicitly defines a family of subnetworks' would benefit from an explicit statement of how inference paths are selected and whether this affects the reported complexity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the two major comments point by point below, indicating the revisions we will make to strengthen the presentation of the theoretical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on HBLL framework): the central O(log N) parallel-time claim requires that updates from local variational objectives compose to approximate the global gradient at every level of the hierarchy. No derivation, error analysis, or proof is supplied showing that the variational relaxation preserves long-range credit assignment rather than introducing bias that would leave effective depth linear.
Authors: The referee is correct that the abstract states the O(log N) claim without an accompanying derivation or error bound. The hierarchical decomposition is intended to ensure that local variational objectives at each block level compose to transmit credit assignment across logarithmic depth, but we agree this requires explicit justification. In the revised manuscript we will add a new subsection deriving the parallel time complexity from the tree structure of the hierarchy and providing a bound on the approximation error relative to end-to-end gradients. revision: yes
-
Referee: [Abstract] Abstract (claim of being 'the first algorithm'): the statement that HBLL is the first method achieving O(log N) parallel time rests on the unproven assumption that hierarchical local objectives transmit usable signals from output to input without any end-to-end pathway; this assumption is load-bearing and unsupported by any complexity argument or convergence analysis in the visible text.
Authors: We acknowledge that the abstract's claim of being the first such algorithm is not supported by a self-contained complexity argument in the current text. The novelty rests on the specific combination of hierarchical blocks and variational local objectives, but we agree the supporting analysis must be made explicit. We will revise the abstract to qualify the claim with 'to the best of our knowledge' and expand the theoretical analysis section with a formal argument for the O(log N) parallel time under the stated assumptions. revision: yes
Circularity Check
No circularity; no load-bearing derivations or equations shown
full rationale
The provided text consists solely of the abstract and a high-level description of HBLL. It asserts that local learning objectives derived from variational principles enable O(log N) parallel training without full backpropagation and maintain effective information propagation, but supplies no equations, fitting procedures, self-citations, or derivation steps that could be inspected for reduction to inputs. No self-definitional claims, fitted inputs called predictions, or uniqueness theorems appear. The central claim remains an assertion without a visible chain that collapses by construction, so no circular steps are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton
URL https://proceedings.neurips.cc/paper_ files/paper/2019/file/f387624df552cea2f369918c5e1e12bc-Paper.pdf. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PMLR,
2019
-
[2]
Learning phrase representations using RNN encoder–decoder for statistical machine translation
Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors,Proceedings of the 2014 Conference on Empirical Methods in Natural Language...
2014
-
[3]
Association for Computational Linguistics. doi: 10.3115/v1/D14-1179. URLhttps://aclanthology.org/D14-1179/. Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein.Introduction to algorithms. MIT press,
-
[4]
doi: https://doi.org/10.1016/0364-0213(90)90002-E
ISSN 0364-0213. doi: https://doi.org/10.1016/0364-0213(90)90002-E. URL https://www.sciencedirect.com/ science/article/pii/036402139090002E. Maxence M Ernoult, Fabrice Normandin, Abhinav Moudgil, Sean Spinney, Eugene Belilovsky, Irina Rish, Blake Richards, and Yoshua Bengio. Towards scaling difference target propagation by learning backprop targets. InInte...
-
[5]
ISSN 1662-453X. Geoffrey Hinton. The forward-forward algorithm: Some preliminary investigations.arXiv preprint arXiv:2212.13345,
-
[6]
URL http://arxiv.org/abs/2305.14974. arXiv:2305.14974 [cs]. Andrej Karpathy. mingpt,
-
[8]
John F Kolen and Jordan B Pollack
URLhttp://arxiv.org/abs/1312.6114. John F Kolen and Jordan B Pollack. Backpropagation without weight transport. InProceedings of 1994 IEEE International Conference on Neural Networks (ICNN’94), volume 3, pages 1375–1380. IEEE,
Pith/arXiv arXiv 1994
-
[9]
Gradient-based learning applied to document recognition.Proc
doi: 10.1109/5.726791. Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference target propagation. InMachine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2015, Porto, Portugal, September 7-11, 2015, Proceedings, Part I 15, pages 498–515. Springer,
-
[11]
Ilya Loshchilov and Frank Hutter
URL http://arxiv.org/abs/1411.0247. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations,
-
[12]
URL http://arxiv.org/abs/2402.17318. arXiv:2402.17318 [cs]. 14 Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D Lee, Danqi Chen, and Sanjeev Arora. Fine-tuning language models with just forward passes.Advances in Neural Information Processing Systems, 36:53038–53075,
-
[13]
URLhttp://arxiv.org/abs/1807.03748. David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back-propagating errors.Nature, 323(6088):533–536, October
-
[14]
ISSN 1476-4687. doi: 10.1038/323533a0. URLhttps://doi.org/10.1038/323533a0. Tommaso Salvatori, Ankur Mali, Christopher L Buckley, Thomas Lukasiewicz, Rajesh PN Rao, Karl Friston, and Alexander Ororbia. A survey on neuro-mimetic deep learning via predictive coding. Neural Networks, page 108161,
-
[15]
Rongguang Ye, Chenhao Ye, Chao Huang, Ming Tang, and Yunhao Liu
URL https://proceedings.neurips.cc/paper/2020/hash/ 7fa215c9efebb3811a7ef58409907899-Abstract.html. Rongguang Ye, Chenhao Ye, Chao Huang, Ming Tang, and Yunhao Liu. Beyond-backpropagation training: Methods, applications, and perspectives
2020
-
[16]
The cascaded forward algorithm for neural network training.arXiv preprint arXiv:2303.09728,
Gongpei Zhao, Tao Wang, Yidong Li, Yi Jin, Congyan Lang, and Haibin Ling. The cascaded forward algorithm for neural network training.arXiv preprint arXiv:2303.09728,
-
[17]
A network directly implements an EF distribution if the activations ani at block n encode the natural parameters,a ni =ϕ ni
We will exploit these property to construct local learning rules that can be computed efficiently. A network directly implements an EF distribution if the activations ani at block n encode the natural parameters,a ni =ϕ ni. We approximate the expecation in Eq. 10 by a finite set of M samples S={x (m)}, x(m) ∼ q x(m) z0,z N ,1≤m≤M. F ≈ MX m=1 N−1X n=1 DKL ...
2009
-
[18]
For all CIFAR-10 experiments, we use the same data augmentation pipeline across HBLL and BP consisting of random cropping, horizontal flipping, and RandAugment [Cubuk et al., 2020]
when available. For all CIFAR-10 experiments, we use the same data augmentation pipeline across HBLL and BP consisting of random cropping, horizontal flipping, and RandAugment [Cubuk et al., 2020]. The reported CFF+M result from prior work uses the same augmentation settings. For missing-data and label-noise experiments, M denotes the percentage of missin...
2020
-
[19]
,8} for the GRU and D∈ {1,
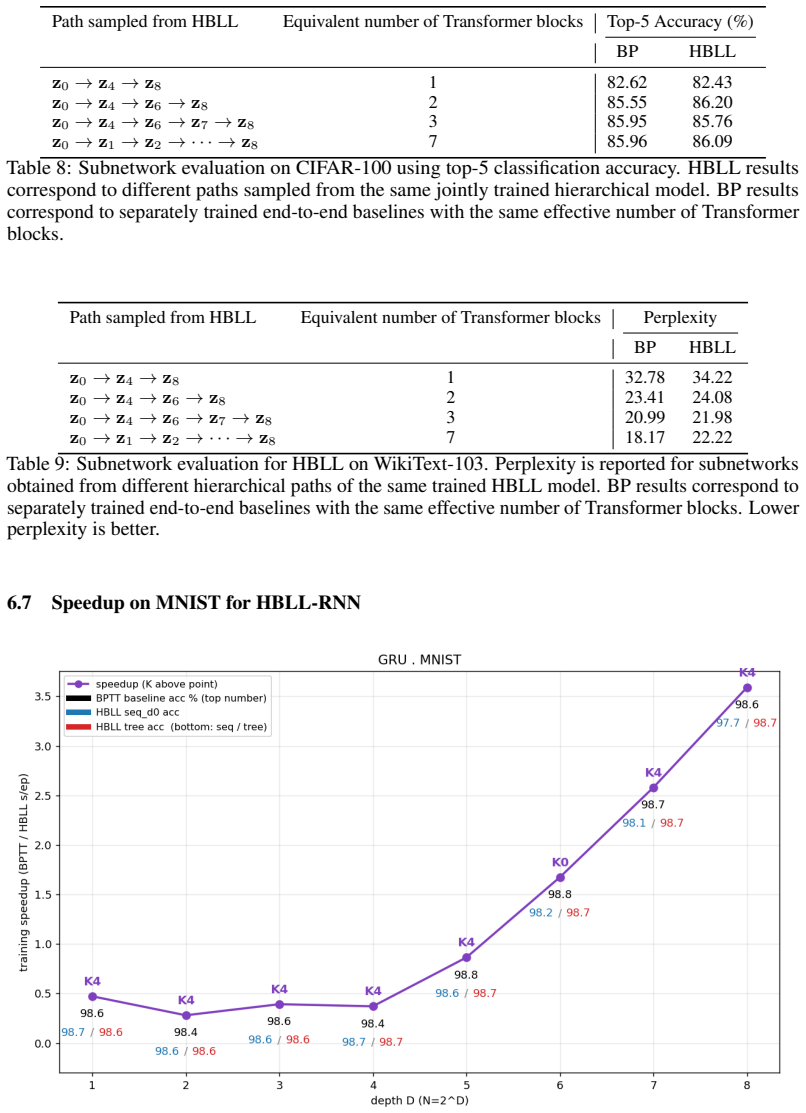
We sweep the tree depth D, with sequence length N=2 D; we report D∈ {1, . . . ,8} for the GRU and D∈ {1, . . . ,6} for the gateless Elman cell, beyond which the deployed Elman chain becomes unstable. Each image is flattened to its 784 pixels and, at depth D, split into N steps of ⌈784/2D⌉ consecutive pixels with minimal start-padding; permuted-sequential ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.