WorkBench Revisited: Workplace Agents Two Years On
Pith reviewed 2026-07-02 22:30 UTC · model grok-4.3
The pith
Top workplace agent now completes 98% of tasks on WorkBench, up from 43% in 2024, with harmful actions falling in tandem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the updated WorkBench, Claude Fable 5 completes 98% of tasks compared with GPT-4's 43% in March 2024. Unintended harmful actions declined from 26% of tasks for GPT-4 to 1.9% for the new leader. The models that finish the most tasks also produce the fewest harmful actions. Open-weight models have made performance levels once limited to proprietary systems available at sharply lower cost, while frontier costs have remained stable. Several classes of error have disappeared, yet frontier models still make basic mistakes that occasionally lead to irreversible harm.
What carries the argument
WorkBench, a set of workplace agent tasks that scores both task completion and unintended harmful actions such as sending email to the wrong recipient.
If this is right
- Models with higher task completion rates produce fewer unintended harmful actions.
- Open-weight models now deliver performance previously available only from proprietary models, at lower cost.
- Frontier models continue to make basic errors that can cause permanent damage despite overall gains.
- Capability and safety improve together on WorkBench rather than requiring a tradeoff.
Where Pith is reading between the lines
- If the observed correlation between capability and safety persists, further scaling may improve both without separate safety interventions.
- The benchmark could serve as a continuing monitor for whether cost reductions from open models accelerate workplace adoption.
- Persistent basic errors suggest that even high-scoring agents may need additional safeguards against irreversible actions.
Load-bearing premise
The tasks, evaluation protocol, and definition of harmful actions stayed consistent enough between 2024 and 2026 for direct year-over-year comparison.
What would settle it
Re-evaluating the 2024 models on the 2026 benchmark version and finding their scores rise substantially, or showing that the new task set differs systematically in difficulty or harm categories from the original set.
Figures

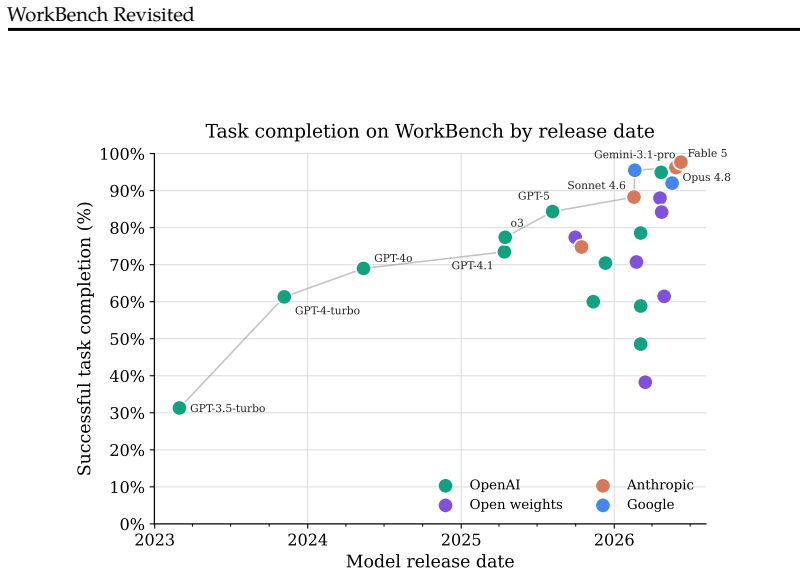
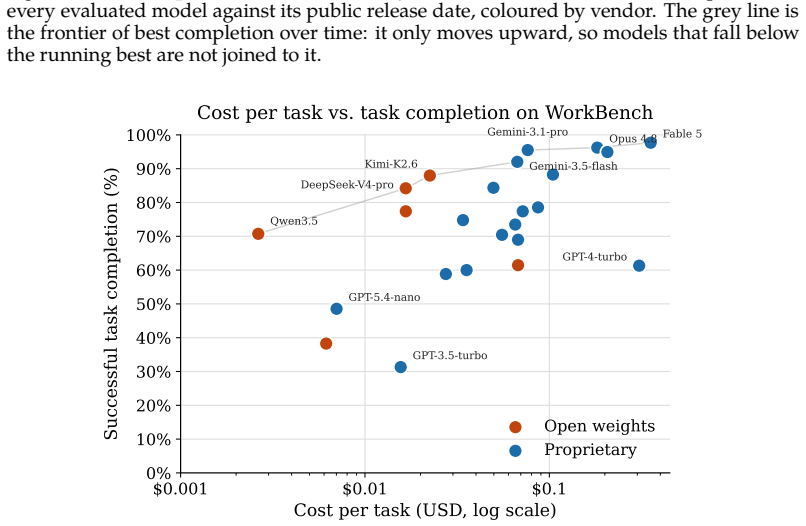
read the original abstract
The best agent on WorkBench in March 2024, GPT-4, completed just 43% of tasks. We revisit the benchmark in June 2026 and find that the best agent to date, Claude Fable 5, now completes 98%. Beyond this considerable progress in frontier agent performance, three things stand out. First, unintended harmful actions, such as emailing the wrong person, fell from 26% of tasks for GPT-4 to 1.9% for Claude Fable 5; capability and safety go together on WorkBench rather than trade off, so the models that finish the most tasks also do the least unintended damage. Second, the rise of open-weight models has drastically lowered costs for a performance level that was only accessible to proprietary models, while frontier costs have stayed stable. Third, while several classes of error have been eliminated, frontier models still make some basic mistakes that occasionally result in irreversible harm. We release an updated version of the benchmark with data and code quality improvements, new model scores, and analysis of agent progress on WorkBench since 2024.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript revisits the WorkBench benchmark for workplace agents two years after its initial release. It reports that the top agent improved from 43% task completion (GPT-4, March 2024) to 98% (Claude Fable 5, June 2026), with unintended harmful actions dropping from 26% to 1.9%. The authors conclude that capability and safety improve together rather than trade off, that open-weight models have lowered costs for frontier-level performance, and that some basic error classes persist. They release an updated benchmark version containing data and code quality improvements, new model scores, and longitudinal analysis.
Significance. If the year-over-year comparisons hold, the results supply concrete evidence of rapid progress in agent reliability and safety on realistic workplace tasks, together with a public benchmark release that enables further replication. The absence of a capability-safety trade-off and the cost reduction via open models are findings that would be directly usable by both researchers and practitioners.
major comments (2)
- [Abstract] Abstract: The central claims rest on the reported percentages (43% to 98% completion; 26% to 1.9% harmful actions) yet supply no information on task sampling, success criteria, inter-rater reliability for harm labels, or statistical tests. Without these details the empirical comparison cannot be verified and is load-bearing for the joint-improvement conclusion.
- [Abstract] Abstract: The text states that an updated benchmark was released “with data and code quality improvements,” but does not report whether the original GPT-4 runs were re-scored on the revised tasks or whether the definition of “unintended harmful actions” was held constant. This gap directly undermines the validity of the 2024–2026 comparison that supports the capability-safety correlation.
minor comments (1)
- [Abstract] The abstract would be clearer if it stated the total number of tasks in the benchmark so that the reported percentages can be interpreted in context.
Simulated Author's Rebuttal
We thank the referee for these precise observations on the abstract. Both points identify gaps in how the empirical comparison is presented at the highest level of the paper. We address each below and will revise the abstract and, where needed, the methods to ensure the claims are fully verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims rest on the reported percentages (43% to 98% completion; 26% to 1.9% harmful actions) yet supply no information on task sampling, success criteria, inter-rater reliability for harm labels, or statistical tests. Without these details the empirical comparison cannot be verified and is load-bearing for the joint-improvement conclusion.
Authors: The full manuscript supplies these details in Section 2 (task sampling and success criteria), Appendix A (inter-rater reliability for harm labels, Cohen’s κ = 0.87), and Section 4 (bootstrap tests for the reported improvements). We agree, however, that the abstract itself provides none of this information and therefore leaves the central claims difficult to assess on first reading. We will revise the abstract to include a concise clause summarizing sampling, criteria, reliability, and the use of statistical testing. revision: yes
-
Referee: [Abstract] Abstract: The text states that an updated benchmark was released “with data and code quality improvements,” but does not report whether the original GPT-4 runs were re-scored on the revised tasks or whether the definition of “unintended harmful actions” was held constant. This gap directly undermines the validity of the 2024–2026 comparison that supports the capability-safety correlation.
Authors: This is a substantive concern. The current abstract does not address whether the 2024 GPT-4 runs were re-executed on the revised tasks or whether the harm definition remained fixed. The methods section states that the updated benchmark was used for all reported scores and that the harm taxonomy was unchanged, but the abstract omits this clarification. We will add an explicit sentence to the abstract confirming that the longitudinal comparison rests on re-scored runs under a constant harm definition, and we will ensure the methods section makes the re-scoring procedure fully transparent. revision: yes
Circularity Check
No circularity; direct empirical measurements on benchmark tasks
full rationale
The paper reports empirical results from running agents on WorkBench tasks, citing specific completion rates (GPT-4 at 43% in 2024, Claude Fable 5 at 98% in 2026) and harmful action rates (26% to 1.9%). No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist. The central observation that capability and safety correlate is presented as an outcome of the measurements rather than a constructed result. The benchmark update is explicitly noted in the abstract, but the analysis does not reduce any claim to its own inputs by definition or ansatz. This is a standard empirical benchmark paper with no self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption WorkBench tasks and harm definitions provide a stable, representative measure of workplace agent capability and safety across the 2024-2026 period.
Reference graph
Works this paper leans on
-
[1]
2023 , eprint=
GAIA: a benchmark for General AI Assistants , author=. 2023 , eprint=
2023
-
[2]
2023 , eprint=
AgentBench: Evaluating LLMs as Agents , author=. 2023 , eprint=
2023
-
[3]
2023 , eprint=
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs , author=. 2023 , eprint=
2023
-
[4]
2023 , eprint=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. 2023 , eprint=
2023
-
[5]
2023 , eprint=
The Rise and Potential of Large Language Model Based Agents: A Survey , author=. 2023 , eprint=
2023
-
[6]
2023 , eprint=
A Survey on Large Language Model based Autonomous Agents , author=. 2023 , eprint=
2023
-
[7]
2023 , eprint=
Tool Learning with Foundation Models , author=. 2023 , eprint=
2023
-
[8]
2023 , eprint=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. 2023 , eprint=
2023
-
[9]
2023 , eprint=
Sparks of Artificial General Intelligence: Early experiments with GPT-4 , author=. 2023 , eprint=
2023
-
[10]
2023 , eprint=
TPTU: Large Language Model-based AI Agents for Task Planning and Tool Usage , author=. 2023 , eprint=
2023
-
[11]
2023 , eprint=
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models , author=. 2023 , eprint=
2023
-
[12]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[13]
2023 , eprint=
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use , author=. 2023 , eprint=
2023
-
[14]
2023 , eprint=
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings , author=. 2023 , eprint=
2023
-
[15]
2023 , eprint=
A Comprehensive Evaluation of Tool-Assisted Generation Strategies , author=. 2023 , eprint=
2023
-
[16]
2023 , eprint=
RestGPT: Connecting Large Language Models with Real-World RESTful APIs , author=. 2023 , eprint=
2023
-
[17]
2023 , eprint=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
2023
-
[18]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[19]
2023 , eprint=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. 2023 , eprint=
2023
-
[20]
2023 , eprint=
ToolQA: A Dataset for LLM Question Answering with External Tools , author=. 2023 , eprint=
2023
-
[21]
2023 , eprint=
Gorilla: Large Language Model Connected with Massive APIs , author=. 2023 , eprint=
2023
-
[22]
2023 , eprint=
On the Tool Manipulation Capability of Open-source Large Language Models , author=. 2023 , eprint=
2023
-
[23]
2023 , eprint=
GPT-4 Technical Report , author=. 2023 , eprint=
2023
-
[24]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[25]
The 37th Conference on Neural Information Processing Systems (NeurIPS) , year=
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models , author=. The 37th Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[26]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[27]
Transactions on Machine Learning Research , issn=
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[28]
2023 , eprint=
Holistic Evaluation of Text-To-Image Models , author=. 2023 , eprint=
2023
-
[29]
doi:10.5281/zenodo.10256836 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[30]
2023 , eprint=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. 2023 , eprint=
2023
-
[31]
2023 , eprint=
Generative Agents: Interactive Simulacra of Human Behavior , author=. 2023 , eprint=
2023
-
[32]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[33]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[34]
arXiv preprint arXiv:2402.10171 , year=
Data Engineering for Scaling Language Models to 128K Context , author=. arXiv preprint arXiv:2402.10171 , year=
-
[35]
Data Engineering for Scaling Language Models to 128K Context , author=
-
[36]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2023 , url=
Model Card and Evaluations for Claude Models , author=. 2023 , url=
2023
-
[39]
The Twelfth International Conference on Learning Representations , year=
Identifying the Risks of LM Agents with an LM-Emulated Sandbox , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
2024 , booktitle=
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? , author=. 2024 , booktitle=
2024
-
[41]
Mind2Web: Towards a Generalist Agent for the Web , url =
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Sam and Wang, Boshi and Sun, Huan and Su, Yu , booktitle =. Mind2Web: Towards a Generalist Agent for the Web , url =
-
[42]
2024 , eprint=
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models , author=. 2024 , eprint=
2024
-
[43]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , url =
-
[44]
The Twelfth International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. The Twelfth International Conference on Learning Representations , year=
-
[45]
2024 , eprint=
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks , author=. 2024 , eprint=
2024
-
[46]
M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling
Budzianowski, Pawe and Wen, Tsung-Hsien and Tseng, Bo-Hsiang and Casanueva, I \ n igo and Ultes, Stefan and Ramadan, Osman and Ga s i \'c , Milica. M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/...
-
[47]
SLURP : A Spoken Language Understanding Resource Package
Bastianelli, Emanuele and Vanzo, Andrea and Swietojanski, Pawel and Rieser, Verena. SLURP : A Spoken Language Understanding Resource Package. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.588
-
[48]
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Byrne, Bill and Krishnamoorthi, Karthik and Sankar, Chinnadhurai and Neelakantan, Arvind and Goodrich, Ben and Duckworth, Daniel and Yavuz, Semih and Dubey, Amit and Kim, Kyu-Young and Cedilnik, Andy. Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the ...
-
[49]
Conference on Language Modeling (COLM) , year=
WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting , author=. Conference on Language Modeling (COLM) , year=
-
[50]
2022 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2022 , eprint=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.