Improving Visual Token Reduction via Rectifying Distortions for Efficient Multimodal LLM Inference
Pith reviewed 2026-06-28 15:51 UTC · model grok-4.3
The pith
RESTORE rectifies positional and attentional distortions in visual token reduction to raise MLLM accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
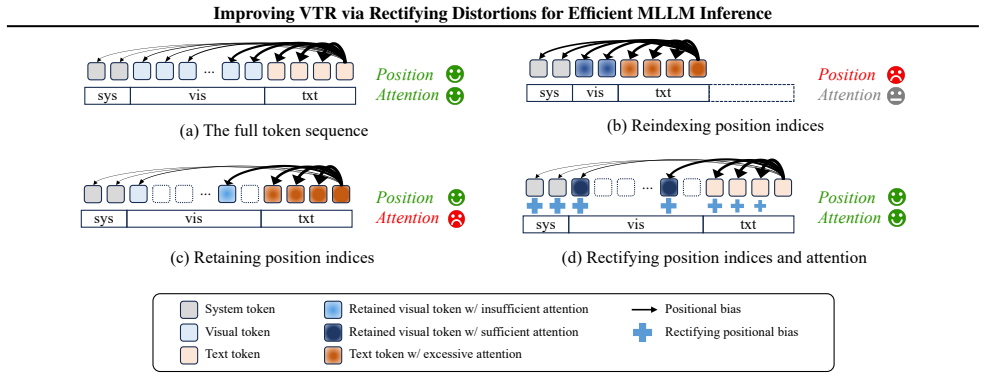
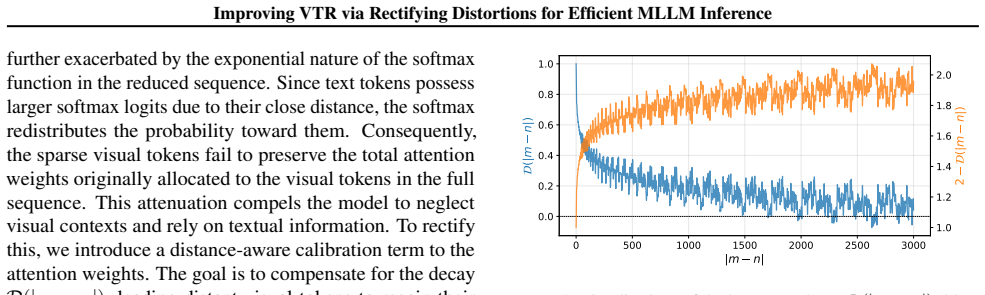
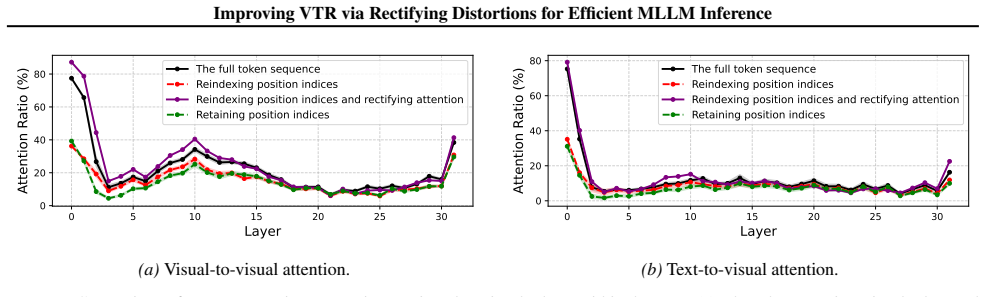
RESTORE is a visual token reduction framework that rectifies positional and attentional distortions by a calibration method that restores lost visual attention through augmentation of attention weights based on relative distances, together with a distinctive anchor selection for token merging that mitigates information loss during feature averaging.
What carries the argument
RESTORE calibration method using relative distances to augment attention weights, combined with anchor selection for token merging to preserve consistency between full and reduced sequences.
If this is right
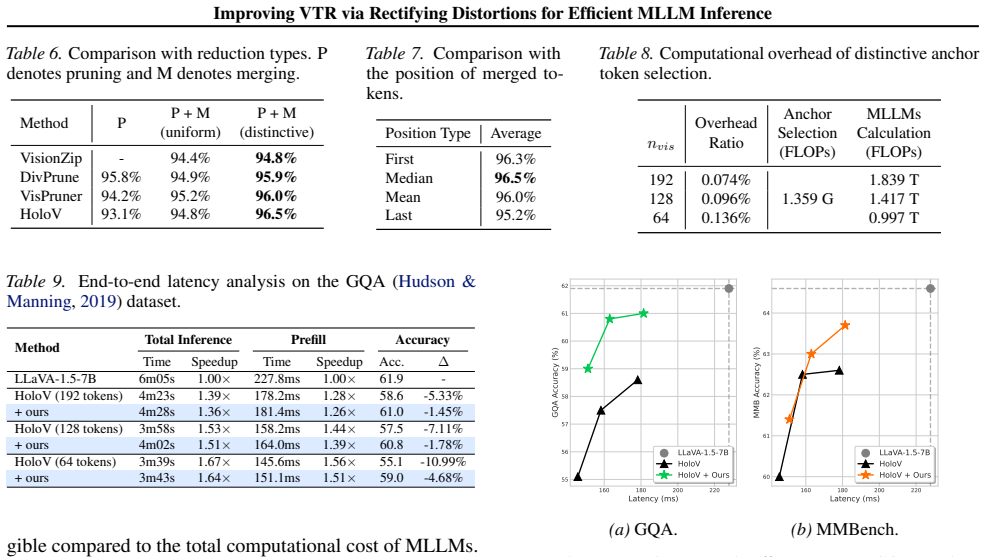
- Accuracy of multiple existing visual token reduction methods increases when RESTORE is applied.
- State-of-the-art results appear on multiple vision-language benchmarks.
- Computational efficiency remains intact with lower memory and latency than full-token baselines.
- The improvements hold across different reduction strategies without task-specific tuning.
Where Pith is reading between the lines
- The same distortion-rectification steps could be tested on text-only token pruning in standard LLMs.
- Integration with quantization or pruning pipelines might further extend usable context lengths.
- Deployment on mobile or edge hardware becomes more feasible if the accuracy recovery scales.
Load-bearing premise
The calibration based on relative distances and anchor selection will restore lost visual attention and mitigate information loss without introducing new distortions or needing per-task adjustments.
What would settle it
Apply RESTORE to an existing reduction method on a standard benchmark and observe no accuracy gain or added latency compared with the same reduction method without RESTORE.
Figures
read the original abstract
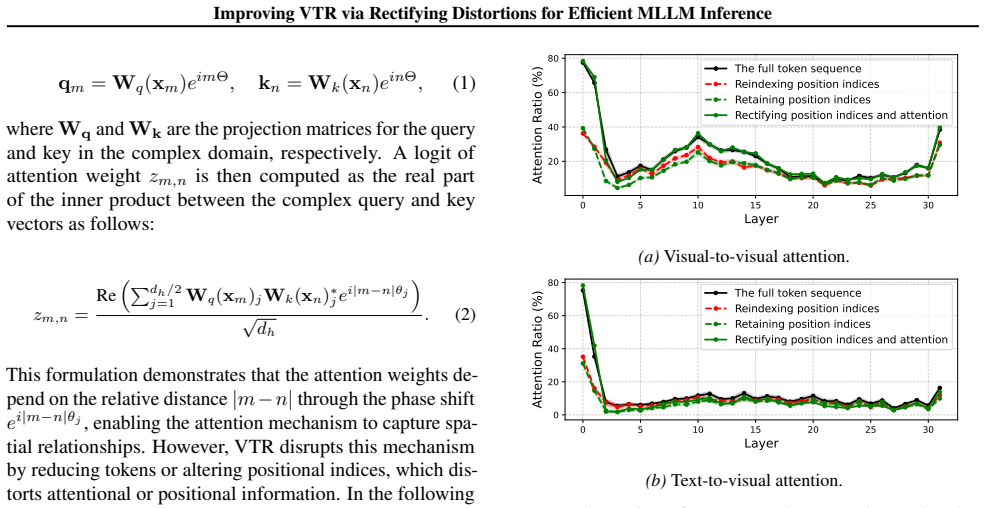
Recent advancements in Multimodal Large Language Models (MLLMs) have achieved remarkable success in vision-language tasks, yet the quadratic computational complexity arising from the vast number of visual tokens incurs significant memory and latency bottlenecks. While visual token reduction (VTR) strategies have been explored to mitigate this burden, existing methods overlook the positional and attentional consistency between the full and reduced sequences, resulting in a distorted representation. To this end, we propose RESTORE, a novel VTR framework that rectifies the positional and attentional distortions while maintaining efficiency. Specifically, we present a simple yet effective calibration method that restores lost visual attention by augmenting attention weights based on relative distances. We also introduce a distinctive anchor selection for token merging to mitigate information loss during feature averaging. Experimental results on multiple benchmarks demonstrate that our method consistently improves the accuracy of various reduction methods, achieving state-of-the-art performance while maintaining computational efficiency. Project page is available at https://cvlab.yonsei.ac.kr/projects/RESTORE
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RESTORE, a visual token reduction (VTR) framework for Multimodal Large Language Models that rectifies positional and attentional distortions between full and reduced token sequences. It proposes a calibration step that augments attention weights using relative distances and an anchor-based selection strategy for token merging. The central empirical claim is that RESTORE consistently improves accuracy across multiple existing VTR baselines, reaches SOTA performance on standard vision-language benchmarks, and preserves computational efficiency.
Significance. If the reported gains hold under the provided ablations and cross-benchmark evaluation, the work offers a practical, additive improvement to existing VTR techniques without introducing new hyperparameters or substantial overhead. The empirical focus, with multiple reduction baselines and ablation studies, strengthens the contribution for efficient MLLM inference.
minor comments (3)
- [Abstract] Abstract: the claim of 'consistent' accuracy gains and SOTA results would be stronger if the abstract named the specific benchmarks and reported the magnitude of improvements (e.g., average accuracy delta).
- [Method] Method section: the anchor selection procedure and relative-distance augmentation would benefit from a short pseudocode listing or explicit algorithmic steps to aid reproducibility.
- [Experiments] Experiments: while ablations are supplied, adding error bars or reporting the number of runs would further substantiate the 'consistent' improvement claim across reduction methods.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and the recommendation for minor revision. We appreciate the recognition that RESTORE provides a practical, additive improvement to existing VTR techniques.
Circularity Check
No significant circularity
full rationale
The paper's contribution is an empirical calibration method (relative-distance attention augmentation and anchor-based merging) added to existing VTR techniques. No equations, derivations, or self-citations are presented that reduce any claimed result to fitted parameters or prior self-work by construction. The central claims rest on benchmark experiments with ablations, not on any internal reduction or uniqueness theorem imported from the authors' prior papers. This is the common case of a self-contained empirical addition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NeurIPS , year=
Visual instruction tuning , author=. NeurIPS , year=
-
[2]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
EMNLP , year=
Video-llava: Learning united visual representation by alignment before projection , author=. EMNLP , year=
-
[4]
OpenAI blog , year=
Language models are unsupervised multitask learners , author=. OpenAI blog , year=
-
[5]
NeurIPS , year=
Language models are few-shot learners , author=. NeurIPS , year=
-
[6]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ICML , year=
Learning transferable visual models from natural language supervision , author=. ICML , year=
-
[9]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[10]
science , volume=
Clustering by fast search and find of density peaks , author=. science , volume=. 2014 , publisher=
2014
-
[11]
AAAI , year=
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models , author=. AAAI , year=
-
[12]
EMNLP , year=
Stop looking for important tokens in multimodal language models: Duplication matters more , author=. EMNLP , year=
-
[13]
ICCV , year=
Llava-prumerge: Adaptive token reduction for efficient large multimodal models , author=. ICCV , year=
-
[14]
ICLR , year=
Dynamic-LLaVA: Efficient Multimodal Large Language Models via Dynamic Vision-language Context Sparsification , author=. ICLR , year=
-
[15]
CVPR , year=
Atp-llava: Adaptive token pruning for large vision language models , author=. CVPR , year=
-
[16]
NeurIPS , year=
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning , author=. NeurIPS , year=
-
[17]
ICCV , year=
Growing a twig to accelerate large vision-language models , author=. ICCV , year=
-
[18]
NeurIPS , year=
Attention is all you need , author=. NeurIPS , year=
-
[19]
CVPR , year=
Improved baselines with visual instruction tuning , author=. CVPR , year=
-
[20]
ECCV , year=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. ECCV , year=
-
[21]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction , author=. arXiv preprint arXiv:2410.17247 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
ICML , year=
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference , author=. ICML , year=
-
[23]
ICLR , year=
Token Merging: Your ViT But Faster , author=. ICLR , year=
-
[24]
CVPR , year=
Visionzip: Longer is better but not necessary in vision language models , author=. CVPR , year=
-
[25]
CVPR , year=
Divprune: Diversity-based visual token pruning for large multimodal models , author=. CVPR , year=
-
[26]
ICCV , year=
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms , author=. ICCV , year=
-
[27]
Highlighted Tokens
Don't Just Chase “Highlighted Tokens” in MLLMs: Revisiting Visual Holistic Context Retention , author=. NeurIPS , year=
-
[28]
NeurIPS , year=
Flowcut: Rethinking redundancy via information flow for efficient vision-language models , author=. NeurIPS , year=
-
[29]
CVPR , year=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. CVPR , year=
-
[30]
ECCV , year=
Mmbench: Is your multi-modal model an all-around player? , author=. ECCV , year=
-
[31]
NeurIPS , year=
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. NeurIPS , year=
-
[32]
EMNLP , year=
Evaluating Object Hallucination in Large Vision-Language Models , author=. EMNLP , year=
-
[33]
NeurIPS , year=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. NeurIPS , year=
-
[34]
CVPR , year=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. CVPR , year=
-
[35]
CVPR , year=
Towards vqa models that can read , author=. CVPR , year=
-
[36]
CVPR , year=
Seed-bench: Benchmarking multimodal large language models , author=. CVPR , year=
-
[37]
ACM MM , year=
Video question answering via gradually refined attention over appearance and motion , author=. ACM MM , year=
-
[38]
CVPR , year=
TGIF: A new dataset and benchmark on animated GIF description , author=. CVPR , year=
-
[39]
Science China Information Sciences , volume=
Ocrbench: on the hidden mystery of ocr in large multimodal models , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[40]
IEEE Transactions on pattern analysis and machine intelligence , volume=
Comparing images using the Hausdorff distance , author=. IEEE Transactions on pattern analysis and machine intelligence , volume=. 2002 , publisher=
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.