Output-Space Allocation Costs for Calibration-Guided LLM Compression: An Empirical Study
Pith reviewed 2026-06-29 04:39 UTC · model grok-4.3
The pith
Switching MCKP allocation cost from weight-space to output-space error in ROCKET compression raises zero-shot accuracy by 0.8 points but increases perplexity by 16% on Qwen3-8B at 50% compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Aligning the MCKP allocation cost with the output reconstruction objective improves average zero-shot accuracy by 0.8 percentage points on Qwen3-8B at 50% compression but increases WikiText perplexity by 16%, with the effect limited by >0.99 correlation between weight-space and output-space errors. On Llama-3.2-1B at 20% compression the two methods produce near-identical results.
What carries the argument
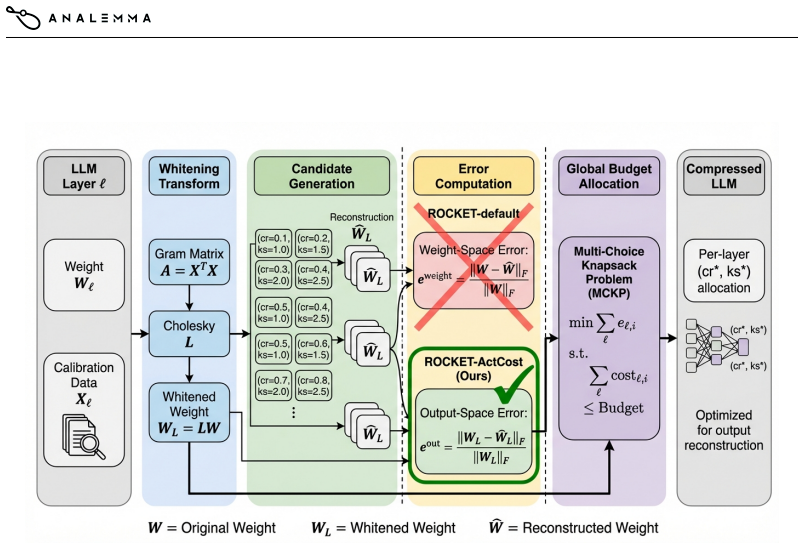
The MCKP allocation cost that assigns per-layer factorization budgets according to either weight-space Frobenius error or output-space reconstruction error.
Load-bearing premise
The eight zero-shot benchmarks plus WikiText perplexity serve as representative and sufficient proxies for overall compressed-model fidelity across downstream applications.
What would settle it
A measurement showing that weight-space and output-space errors correlate below 0.95 on some model or compression ratio, accompanied by visibly different layer budgets and larger accuracy or perplexity gaps, would falsify the claim that correlation limits the benefit of the output-space cost.
Figures
read the original abstract
Training-free compression methods for large language models (LLMs) often use calibration data to guide compression decisions. ROCKET, a recent method combining sparse-dictionary factorization with multi-choice knapsack problem (MCKP) allocation, derives its per-layer factorization from an output reconstruction objective but uses weight-space Frobenius error as the MCKP allocation cost. We investigate whether aligning the allocation cost with the output-space objective improves compressed model fidelity. On Qwen3-8B at 50\% compression, our ROCKET-ActCost achieves +0.8 percentage points higher average accuracy across 8 zero-shot benchmarks (53.1\% vs 52.3\%), but increases WikiText perplexity by 16\% (61.46 vs 52.98). This accuracy-perplexity tradeoff reveals that different allocation objectives favor different downstream metrics. The high correlation ($>$0.99) between weight-space and output-space errors limits allocation divergence, explaining the modest effect size. On Llama-3.2-1B at 20\% compression, the two methods produce near-identical results (53.3\% vs 53.5\% accuracy, 14.45 vs 14.66 PPL), suggesting that the effect of the cost function is minor at lower compression ratios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically studies whether replacing the weight-space Frobenius error with an output-reconstruction error as the per-layer cost in the MCKP allocation step of ROCKET compression improves compressed-LLM fidelity. On Qwen3-8B at 50% compression the output-aligned variant (ROCKET-ActCost) yields +0.8 pp average zero-shot accuracy across eight benchmarks (53.1% vs 52.3%) while raising WikiText perplexity by 16% (61.46 vs 52.98); the two variants produce nearly identical results on Llama-3.2-1B at 20% compression. The modest effect size is attributed to a >0.99 correlation between the two error surfaces.
Significance. If the reported correlation and metric-specific tradeoff hold under broader evaluation, the work supplies concrete evidence that cost-function alignment in calibration-guided compression has only limited downstream impact and that different allocation objectives can favor accuracy versus perplexity. The explicit numerical results on named models and the correlation measurement constitute the main contribution.
major comments (1)
- [Abstract] Abstract: the central claim that the observed accuracy-perplexity tradeoff is a genuine property of the allocation-cost change (rather than an artifact of the evaluation suite) is load-bearing on the assumption that the eight zero-shot benchmarks plus WikiText are representative proxies for compressed-model behavior across downstream applications; no justification or sensitivity analysis for task selection is provided.
minor comments (1)
- [Abstract] Abstract: the reported correlation coefficient is given only as “>0.99” without the exact value, the number of layers or samples used to compute it, or a figure showing the scatter.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We address the concern about benchmark selection and justification in the abstract below, and indicate the planned revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the observed accuracy-perplexity tradeoff is a genuine property of the allocation-cost change (rather than an artifact of the evaluation suite) is load-bearing on the assumption that the eight zero-shot benchmarks plus WikiText are representative proxies for compressed-model behavior across downstream applications; no justification or sensitivity analysis for task selection is provided.
Authors: We agree that the abstract does not contain an explicit justification for the choice of the eight zero-shot benchmarks and WikiText. These tasks follow the evaluation protocol of the original ROCKET paper and are standard in the calibration-guided LLM compression literature because they probe a broad range of capabilities (reasoning, commonsense, knowledge, and language modeling). The central empirical finding—the >0.99 correlation between weight-space and output-space errors—directly limits allocation divergence and thereby explains the modest, metric-specific effect size; this correlation is independent of any particular downstream task. Nevertheless, we acknowledge that a short clarifying sentence would strengthen the abstract. We will revise the abstract to note that the selected benchmarks are the standard suite used in prior work on ROCKET-style methods. A comprehensive sensitivity analysis across additional tasks lies outside the scope of the present focused empirical study. revision: partial
Circularity Check
No circularity: purely empirical comparison with no derivation chain
full rationale
The paper is an empirical study measuring the effect of switching MCKP allocation cost from weight-space Frobenius error to output-reconstruction error on Qwen3-8B and Llama-3.2-1B. Results (accuracy deltas, PPL changes, >0.99 correlation) are direct benchmark measurements on held-out tasks; no equations, fitted parameters, or predictions are claimed to derive from the paper's own inputs. No self-citation load-bearing steps, ansatzes, or renamings appear in the provided text. The central claim reduces to external evaluation rather than internal construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Ammar Ali and Baher Mohammad and Denis Makhov and Dmitriy Shopkhoev and Magauiya Zhussip and Stamatios Lefkimmiatis , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.11008 , eprinttype =
-
[5]
Qwen3 Technical Report , volume =
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and others , journal =. Qwen3 Technical Report , volume =
-
[6]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and others , title =
-
[7]
Llama 3.2: Lightweight Text Models (1B and 3B) , year =
-
[8]
The RefinedWeb Dataset for Falcon
Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Hamza Alobeidli and Alessandro Cappelli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay , editor =. The RefinedWeb Dataset for Falcon. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIP...
2023
-
[9]
Tow and others , journal =
Stella Biderman and Hailey Schoelkopf and Lintang Sutawika and Leo Gao and J. Tow and others , journal =. Lessons from the Trenches on Reproducible Evaluation of Language Models , volume =
-
[10]
HellaSwag: Can a Machine Really Finish Your Sentence? , booktitle =
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , editor =. HellaSwag: Can a Machine Really Finish Your Sentence? , booktitle =. 2019 , url =
2019
-
[11]
Denis Paperno and Germ. The. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,. 2016 , url =
2016
-
[12]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , volume =
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , journal =. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , volume =
-
[13]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[14]
Xunyu Zhu and Jian Li and Yong Liu and Can Ma and Weiping Wang , title =. Trans. Assoc. Comput. Linguistics , volume =. 2024 , url =
2024
-
[15]
Hoefler and Dan Alistarh , journal =
Elias Frantar and Saleh Ashkboos and T. Hoefler and Dan Alistarh , journal =. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , volume =
-
[16]
Proceedings of the Seventh Annual Conference on Machine Learning and Systems, MLSys 2024, Santa Clara, CA, USA, May 13-16, 2024 , publisher =
Ji Lin and Jiaming Tang and Haotian Tang and Shang Yang and Wei. Proceedings of the Seventh Annual Conference on Machine Learning and Systems, MLSys 2024, Santa Clara, CA, USA, May 13-16, 2024 , publisher =. 2024 , url =
2024
-
[17]
SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot , booktitle =
Elias Frantar and Dan Alistarh , editor =. SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot , booktitle =. 2023 , url =
2023
-
[18]
Zico Kolter , title =
Mingjie Sun and Zhuang Liu and Anna Bair and J. Zico Kolter , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[19]
The Thirteenth International Conference on Learning Representations,
Xin Wang and Yu Zheng and Zhongwei Wan and Mi Zhang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[20]
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models , volume =
Zhihang Yuan and Yuzhang Shang and Yue Song and Qiang Wu and Yan Yan and Guangyu Sun , journal =. ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models , volume =
-
[21]
Croci and Marcelo Gennari do Nascimento and Torsten Hoefler and James Hensman , booktitle=
Saleh Ashkboos and Maximilian L. Croci and Marcelo Gennari do Nascimento and Torsten Hoefler and James Hensman , booktitle=. Slice. 2024 , url=
2024
-
[22]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models , booktitle =
Guangxuan Xiao and Ji Lin and Micka. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models , booktitle =. 2023 , url =
2023
-
[23]
COSPADI: Compressing LLMs via Calibration-Guided Sparse Dictionary Learning , volume =
Dmitriy Shopkhoev and Denis Makhov and Magauiya Zhussip and Ammar Ali and Stamatios Lefkimmiatis , journal =. COSPADI: Compressing LLMs via Calibration-Guided Sparse Dictionary Learning , volume =
-
[24]
The Thirty-Fourth
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. The Thirty-Fourth. 2020 , url =
2020
-
[25]
Liu and Matt Gardner , editor =
Johannes Welbl and Nelson F. Liu and Matt Gardner , editor =. Crowdsourcing Multiple Choice Science Questions , booktitle =. 2017 , url =
2017
-
[26]
Hovy , editor =
Guokun Lai and Qizhe Xie and Hanxiao Liu and Yiming Yang and Eduard H. Hovy , editor =. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing,. 2017 , url =
2017
-
[27]
5th International Conference on Learning Representations,
Stephen Merity and Caiming Xiong and James Bradbury and Richard Socher , title =. 5th International Conference on Learning Representations,. 2017 , url =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.