RoAd-RL: A Unified Library and Benchmark for Robust Adversarial Reinforcement Learning
Pith reviewed 2026-06-30 06:58 UTC · model grok-4.3
The pith
RoAd-RL supplies unified abstractions and pipelines for testing reinforcement learning agents against 192 attack-defense combinations in two environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a single open-source framework with common interfaces for policies, attacks, defenses, and robustness metrics, together with fixed evaluation pipelines, makes it possible to run reproducible comparisons across 192 attack-defense configurations on DQN, PPO, and SAC agents in LunarLander and Highway-v0, exposing substantial robustness differences between environments and showing that some widely used defenses reduce agent performance more than the attacks they target while temporal smoothing remains effective.
What carries the argument
The RoAd-RL library, which supplies shared abstractions for policies, attacks, defenses, and robustness metrics plus reproducible evaluation pipelines that integrate with existing reinforcement learning codebases.
If this is right
- Robustness levels differ markedly between environments even when the same agents and attacks are used.
- Some standard defenses can reduce agent returns more than the attacks they are meant to block.
- Temporal smoothing produces the most stable performance across the tested attack-defense pairs.
- A common library removes duplicated implementation work and enables direct comparison of new attacks or defenses against prior results.
Where Pith is reading between the lines
- Researchers can now add new environments to the same pipeline to test whether the observed defense rankings hold more broadly.
- The finding that some defenses are counterproductive suggests that future defense design should include explicit checks against performance degradation on clean episodes.
- The library's structure makes it straightforward to measure how robustness changes when agent training itself incorporates the same attacks used at test time.
Load-bearing premise
The two environments and the 192 attack-defense configurations together capture a representative range of adversarial challenges without hidden bias from implementation choices or environment selection.
What would settle it
Re-running the identical 192 configurations in at least two additional distinct environments and finding that every commonly used defense improves robustness scores with no defense ever lowering performance below the no-defense baseline.
Figures
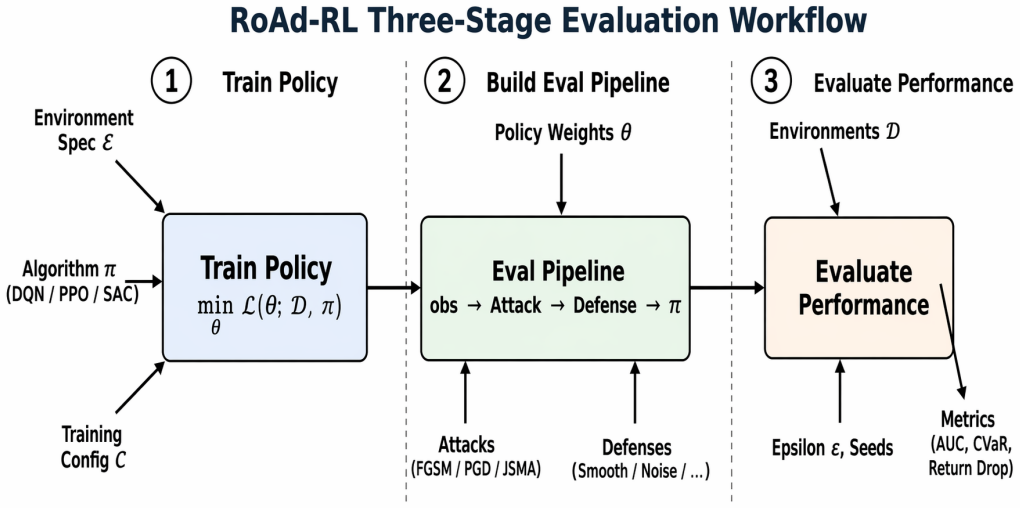
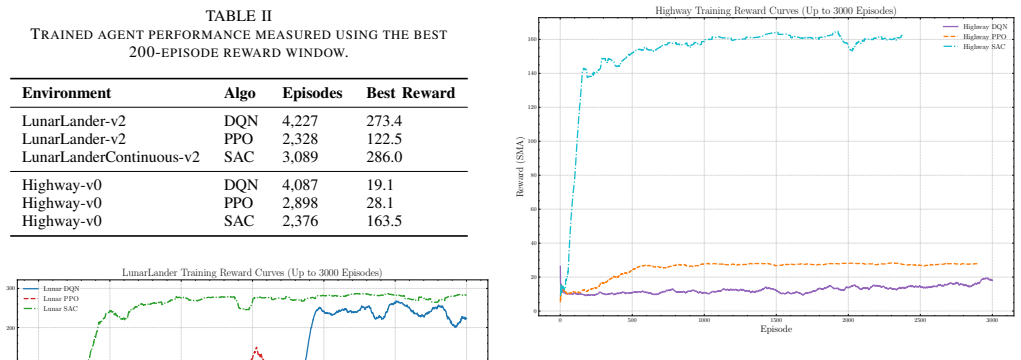
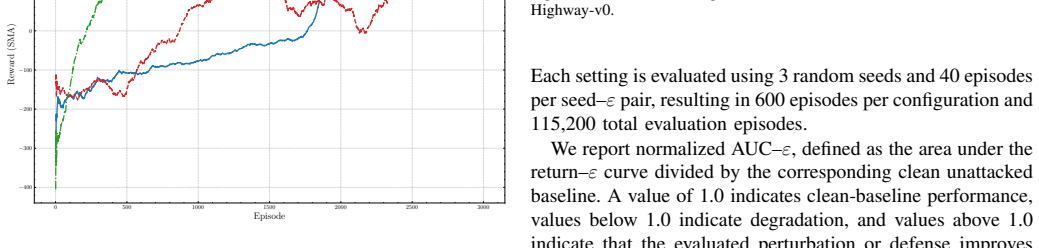
read the original abstract
Deep Reinforcement Learning (DRL) has achieved significant success in robotics and autonomous systems, yet remains vulnerable to adversarial perturbations that can severely degrade performance. Research in adversarial reinforcement learning is often limited by fragmented implementations, inconsistent evaluation protocols, and poor reproducibility. To address these challenges, we present \textbf{RoAd-RL}, an open-source benchmarking framework that provides unified abstractions for policies, attacks, defenses, and robustness metrics, together with reproducible evaluation pipelines and seamless integration with Stable-Baselines3 and Gymnasium. We evaluate DQN, PPO, and SAC agents in LunarLander and Highway-v0 under 192 attack-defense configurations. Results reveal substantial variations in robustness across environments and show that some commonly used defenses can be more detrimental than the attacks they aim to mitigate, while temporal smoothing consistently achieves strong performance. RoAd-RL establishes a standardized benchmark for adversarial reinforcement learning research and is publicly available at https://pypi.org/project/road-rl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoAd-RL, an open-source library providing unified abstractions for policies, attacks, defenses, and robustness metrics in adversarial RL, with integration to Stable-Baselines3 and Gymnasium plus reproducible pipelines. It reports an evaluation of DQN, PPO, and SAC agents on LunarLander and Highway-v0 across 192 attack-defense configurations, claiming substantial robustness variations across environments, that some defenses can be more detrimental than the attacks they target, and that temporal smoothing consistently performs strongly. The library is released on PyPI.
Significance. If the library implementation is robust and the evaluation protocol is reproducible, the work provides a valuable standardized benchmark and tooling that could improve reproducibility in adversarial RL. The explicit release of the package and integration with existing frameworks is a concrete strength that supports community adoption.
major comments (2)
- [Abstract and evaluation description] The central benchmark claim (abstract) that the results 'reveal substantial variations in robustness across environments' and identify generally applicable patterns (e.g., temporal smoothing 'consistently achieves strong performance') rests on evaluations confined to only LunarLander and Highway-v0. These are low-dimensional, fully observed, non-contact-rich tasks; no justification or additional environments are provided to show the observed defense orderings are not environment-specific.
- [Abstract] The abstract states empirical findings from 192 configurations but supplies no information on implementation details, statistical testing, baseline comparisons, or potential confounds (e.g., hyperparameter sensitivity or attack strength calibration), so the support for claims about defense efficacy cannot be verified from the provided text.
minor comments (1)
- [Abstract] The abstract could more explicitly list the library's core abstractions and metrics to clarify the contribution beyond the two-environment evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and for recognizing the potential value of RoAd-RL as a standardized benchmark. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract and evaluation description] The central benchmark claim (abstract) that the results 'reveal substantial variations in robustness across environments' and identify generally applicable patterns (e.g., temporal smoothing 'consistently achieves strong performance') rests on evaluations confined to only LunarLander and Highway-v0. These are low-dimensional, fully observed, non-contact-rich tasks; no justification or additional environments are provided to show the observed defense orderings are not environment-specific.
Authors: We agree that the evaluation uses only two environments, which limits the generalizability of the observed patterns. These environments were selected because they are standard in the RL community, cover different action spaces, and permit running the full 192 configurations efficiently. The manuscript reports results specific to these settings without claiming broader applicability. In the revised version, we will include explicit justification for the environment choices in Section 4 and add a limitations paragraph noting that extending to more complex, high-dimensional, or contact-rich environments is an important future direction enabled by the library. revision: partial
-
Referee: [Abstract] The abstract states empirical findings from 192 configurations but supplies no information on implementation details, statistical testing, baseline comparisons, or potential confounds (e.g., hyperparameter sensitivity or attack strength calibration), so the support for claims about defense efficacy cannot be verified from the provided text.
Authors: The abstract is a high-level summary. Detailed information on the implementation, the evaluation protocol, statistical testing using multiple random seeds, baseline comparisons, and potential confounds such as hyperparameter choices and attack calibration is provided in the main body of the manuscript (Sections 3 and 4). The empirical claims are supported by the full paper. revision: no
Circularity Check
Empirical benchmark paper with no derivations or self-referential predictions
full rationale
The paper releases a library (RoAd-RL) and reports direct empirical observations from evaluating DQN/PPO/SAC agents under 192 attack-defense configurations in LunarLander and Highway-v0. No equations, fitted parameters, predictions, or derivation chains are present in the abstract or described content. The central claims are observational statements about robustness variations and defense performance; these do not reduce to inputs by construction. Self-citations, if any, are not load-bearing for any claimed result. This is a standard non-circular software/benchmark contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Toward robust agents: A survey of adversarial attacks and defenses in deep reinforcement learning,
A. Mohan and T. Sch ¨on, “Toward robust agents: A survey of adversarial attacks and defenses in deep reinforcement learning,”IEEE Access, 2026
2026
-
[2]
The evolution of criticality in deep reinforcement learning,
C. Karpenahalli Ramakrishna, A. Mohan, Z. Zeinaly, and L. Belzner, “The evolution of criticality in deep reinforcement learning,” inPro- ceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025)-Volume 3. SciTePress, 2025, pp. 217–224
2025
-
[3]
Adversarial Attacks on Neural Network Policies
S. Huang, N. Papernot, I. Goodfellow, Y . Duan, and P. Abbeel, “Adversarial attacks on neural network policies,” 2017. [Online]. Available: https://arxiv.org/abs/1702.02284
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Robust deep reinforcement learning against adversarial perturbations on state observations,
H. Zhang, H. Chen, C. Xiao, B. Li, M. Liu, D. Boning, and C.-J. Hsieh, “Robust deep reinforcement learning against adversarial perturbations on state observations,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 21 024–21 037
2020
-
[5]
Advancing robustness in deep reinforcement learning with an ensemble defense approach,
A. Mohan, D. R ¨oßle, D. Cremers, and T. Sch ¨on, “Advancing robustness in deep reinforcement learning with an ensemble defense approach,” arXiv preprint arXiv:2507.17070, 2025
-
[6]
Real-Time Evaluation of Autonomous Systems under Adversarial Attacks
A. Mohan, X. Xie, V . T. Sambandham, and T. Sch ¨on, “Real-time evaluation of autonomous systems under adversarial attacks,”arXiv preprint arXiv:2605.03491, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[8]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inInternational Conference on Learning Representations, 2018
2018
-
[9]
The limitations of deep learning in adversarial settings,
N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami, “The limitations of deep learning in adversarial settings,” in2016 IEEE European Symposium on Security and Privacy. IEEE, 2016, pp. 372–387
2016
-
[10]
Stealthy and efficient adversarial attacks against deep reinforcement learning,
J. Sun, T. Zhang, X. Xie, L. Ma, Y . Zheng, K. Chen, and Y . Liu, “Stealthy and efficient adversarial attacks against deep reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelli- gence, vol. 34, no. 04, 2020, pp. 5883–5891
2020
-
[11]
Feature squeezing: Detecting adversarial examples in deep neural networks,
W. Xu, D. Evans, and Y . Qi, “Feature squeezing: Detecting adversarial examples in deep neural networks,” inNetwork and Distributed System Security Symposium, 2018
2018
-
[12]
Certified adversarial robustness via randomized smoothing,
J. Cohen, E. Rosenfeld, and Z. Kolter, “Certified adversarial robustness via randomized smoothing,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 1310–1320
2019
-
[13]
Robustbench: a standardized adversarial robustness benchmark,
F. Croce, M. Andriushchenko, V . Sehwag, E. Debenedetti, N. Flammarion, M. Chiang, P. Mittal, and M. Hein, “Robustbench: a standardized adversarial robustness benchmark,” 2021. [Online]. Available: https://arxiv.org/abs/2010.09670
-
[14]
Foolbox: A Python toolbox to benchmark the robustness of machine learning models,
J. Rauber, W. Brendel, and M. Bethge, “Foolbox: A Python toolbox to benchmark the robustness of machine learning models,” inICML 2017 Workshop on Visualization for Deep Learning, 2017
2017
-
[15]
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
N. Papernot, F. Faghri, N. Carlini, I. Goodfellow, R. Feinman, A. Kurakin, C. Xie, Y . Sharma, T. Brown, A. Roy, A. Matyasko, V . Behzadan, K. Hambardzumyan, Z. Zhang, Y .-L. Juang, Z. Li, R. Sheatsley, A. Garg, J. Uesato, W. Gierke, Y . Dong, D. Berthelot, P. Hendricks, J. Rauber, R. Long, and P. McDaniel, “Technical report on the cleverhans v2.1.0 adver...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Stable-Baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-Baselines3: Reliable reinforcement learning implementa- tions,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021
2021
-
[17]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, A. KGet al., “Gymnasium: A standard interface for reinforcement learning environments,”arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Robust deep reinforcement learning with adversarial attacks,
A. Pattanaik, Z. Tang, S. Liu, G. Bommannan, and G. Chowdhary, “Robust deep reinforcement learning with adversarial attacks,” inPro- ceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 2018, pp. 2040–2042
2018
-
[19]
Tactics of adversarial attack on deep reinforcement learning agents,
Y .-C. Lin, Z.-W. Hong, Y .-H. Liao, M.-L. Shih, M.-Y . Liu, and M. Sun, “Tactics of adversarial attack on deep reinforcement learning agents,”
-
[20]
Available: https://arxiv.org/abs/1703.06748
[Online]. Available: https://arxiv.org/abs/1703.06748
-
[21]
Certified robustness to adversarial examples with differential privacy,
M. Lecuyer, V . Atlidakis, R. Geambasu, D. Hsu, and S. Jana, “Certified robustness to adversarial examples with differential privacy,” in2019 IEEE Symposium on Security and Privacy. IEEE, 2019, pp. 656–672
2019
-
[22]
K. C. Sekaran, M. Geisler, D. R ¨oßle, A. Mohan, D. Cremers, W. Utschick, M. Botsch, W. Huber, and T. Sch ¨on, “Urbaning- v2x: A large-scale multi-vehicle, multi-infrastructure dataset across multiple intersections for cooperative perception,”arXiv preprint arXiv:2510.23478, 2025
-
[23]
An environment for autonomous driving decision-making,
E. Leurent, “An environment for autonomous driving decision-making,” https://github.com/eleurent/highway-env, 2018
2018
-
[24]
Driving: A large-scale multimodal driving dataset with full digital twin integration,
D. R ¨oßle, X. Xie, A. Mohan, V . T. Sambandham, D. Cremers, and T. Sch ¨on, “Driving: A large-scale multimodal driving dataset with full digital twin integration,”arXiv preprint arXiv:2601.15260, 2026
-
[25]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[26]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” inarXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational Conference on Machine Learning. PMLR, 2018, pp. 1861–1870
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.