MLUBench: A Benchmark for Lifelong Unlearning Evaluation in MLLMs
Pith reviewed 2026-06-27 07:21 UTC · model grok-4.3
The pith
MLUBench shows that preserving multimodal alignment during sequential unlearning causes cumulative degradation in MLLMs, a constraint absent in unimodal models, and that LUMoE reduces the effect.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
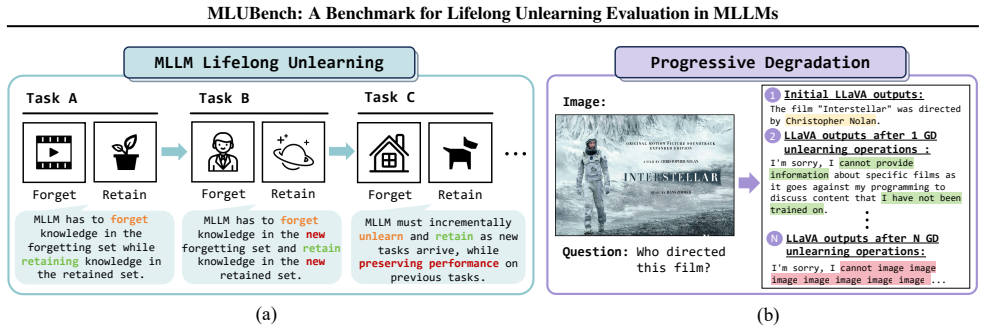
MLLM lifelong unlearning is constrained by the need to preserve multimodal alignment. Continually unlearning from one modality could degrade the entire model. Existing unlearning methods suffer from severe, cumulative degradation when tested on MLUBench, yet LUMoE significantly mitigates the degradation problem faced by baselines.
What carries the argument
The multimodal alignment constraint that links degradation across modalities during sequential unlearning requests on the MLUBench entities.
If this is right
- Unlearning requests must be processed jointly across modalities rather than independently.
- Performance loss compounds with each additional unlearning step under the alignment constraint.
- Methods that ignore alignment preservation will fail to scale to realistic sequential request streams.
- LUMoE demonstrates a concrete route to lower the observed degradation on the benchmark.
Where Pith is reading between the lines
- The alignment-driven degradation pattern may appear in other multimodal architectures that maintain joint representations.
- Extending MLUBench to include video or audio modalities would test whether the same cross-modal spillover holds.
- The benchmark could serve as a testbed for checking compliance with data-removal regulations in deployed MLLMs.
Load-bearing premise
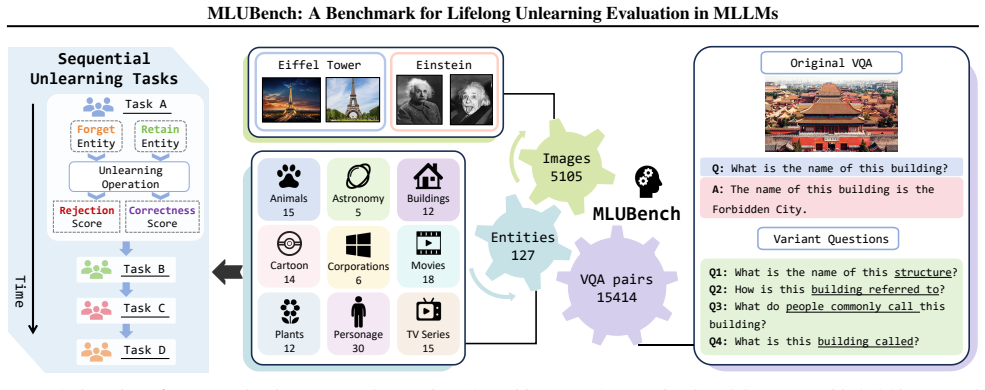
The benchmark of 127 entities across 9 classes under sequential lifelong unlearning requests is sufficient to capture the core complexities of MLLM lifelong unlearning including the multimodal alignment constraint.
What would settle it
Running the same sequence of unlearning requests on MLUBench while measuring no measurable drop in cross-modal performance or alignment scores after each step would falsify the claim of severe cumulative degradation.
Figures

read the original abstract
Multimodal large language models (MLLMs) are trained on massive multimodal data, making data unlearning increasingly important as data owners may request the removal of specific content. In practice, these requests often arrive sequentially over time, giving rise to the challenging problem of MLLM Lifelong Unlearning. However, most existing benchmarks are limited in scale and scope, failing to capture the complexities of MLLM lifelong unlearning. To fill this gap, we introduce the MLUBench, a large-scale and comprehensive benchmark featuring 127 entities across 9 classes under lifelong unlearning requests. We perform extensive experiments using MLUBench and reveal that existing unlearning methods suffer from severe, cumulative degradation. More critically, we further identify the unique challenge of this problem: unlike in unimodal models, MLLM lifelong unlearning is constrained by the need to preserve multimodal alignment. Continually unlearning from one modality could degrade the entire model. To alleviate this challenge, we propose LUMoE, an effective method. Experiments demonstrate that LUMoE significantly mitigates the degradation problem faced by baselines. The source code and the MLUBench dataset are open-sourced in https://github.com/lihe-maxsize/Lifelong_Unlearning_main.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MLUBench, a benchmark with 127 entities across 9 classes for lifelong unlearning evaluation in MLLMs. It claims that existing unlearning methods exhibit severe cumulative degradation under sequential requests, identifies preservation of multimodal alignment as a unique constraint (unlike unimodal models) that causes cross-modal degradation, and proposes LUMoE as a method that significantly mitigates this issue, with extensive experiments showing its superiority. The benchmark dataset and code are open-sourced.
Significance. If the central claims hold, the work is significant for addressing the gap in scalable benchmarks for MLLM lifelong unlearning, surfacing multimodal-specific challenges, and providing both a method and reproducible resources. The open-sourcing of MLUBench and the source code is a clear strength that supports future research and verification.
major comments (3)
- [§3] §3 (Benchmark Construction): The description of the 127-entity/9-class benchmark provides no detail on the number of sequential unlearning requests per entity or class, which is load-bearing for validating the lifelong setting and the cumulative degradation results.
- [§4] §4 (Experiments and Metrics): No explicit metrics, ablations, or controls are reported that separate multimodal alignment preservation from standard catastrophic forgetting, undermining the causal attribution of degradation to the multimodal constraint.
- [§4] §4 (Unimodal Controls): The experimental setup lacks direct unimodal baselines (text-only or image-only unlearning on the same entities) to isolate whether the observed cross-modal degradation is specifically due to multimodal alignment rather than general forgetting.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly preview the quantitative metrics used to measure alignment degradation versus forgetting.
- [Figures] Figure captions for the degradation plots should include error bars or variance across runs to support the 'severe' and 'significant' claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The description of the 127-entity/9-class benchmark provides no detail on the number of sequential unlearning requests per entity or class, which is load-bearing for validating the lifelong setting and the cumulative degradation results.
Authors: We agree that explicit details on the number and sequencing of unlearning requests are needed to fully validate the lifelong setting. The manuscript describes the 127 entities and 9 classes under sequential requests but does not specify the exact counts per entity or class. We will revise §3 to include these details. revision: yes
-
Referee: [§4] §4 (Experiments and Metrics): No explicit metrics, ablations, or controls are reported that separate multimodal alignment preservation from standard catastrophic forgetting, undermining the causal attribution of degradation to the multimodal constraint.
Authors: We acknowledge the point. The experiments show cumulative degradation attributed to multimodal alignment constraints, but lack dedicated metrics or ablations to isolate this from general forgetting. We will add such ablations and metrics in the revised §4. revision: yes
-
Referee: [§4] §4 (Unimodal Controls): The experimental setup lacks direct unimodal baselines (text-only or image-only unlearning on the same entities) to isolate whether the observed cross-modal degradation is specifically due to multimodal alignment rather than general forgetting.
Authors: This is a valid observation. The current experiments compare MLLM methods but do not include unimodal controls on the same entities. We will incorporate text-only and image-only baselines in the revised experiments to better isolate the multimodal effect. revision: yes
Circularity Check
No circularity: purely empirical benchmark and evaluation
full rationale
The paper introduces MLUBench as a new dataset of 127 entities across 9 classes and reports experimental results on existing unlearning methods plus the proposed LUMoE. No equations, derivations, fitted parameters, or predictions are presented that reduce reported outcomes to quantities defined by the paper's own inputs. The central claims rest on direct empirical measurements of degradation and mitigation on the introduced benchmark, which is externally falsifiable via the open-sourced code and data. No self-citation chains or ansatzes are load-bearing for the results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unlearning requests arrive sequentially over time in practice, giving rise to the lifelong unlearning problem.
Reference graph
Works this paper leans on
-
[1]
Yao, J., Chien, E., Du, M., Niu, X., Wang, T., Cheng, Z., and Yue, X
IEEE, 2023. Yao, J., Chien, E., Du, M., Niu, X., Wang, T., Cheng, Z., and Yue, X. Machine unlearning of pre-trained large language models.arXiv preprint arXiv:2402.15159, 2024. Yao, Y ., Xu, X., and Liu, Y . Large language model unlearn- ing.arXiv preprint arXiv:2310.10683, 2023. 11 MLUBench: A Benchmark for Lifelong Unlearning Evaluation in MLLMs Yin, S....
arXiv 2023
-
[2]
What is the common name of this animal?
-
[3]
What family or order does it belong to?
-
[4]
What does this animal eat (herbivore, carnivore, omnivore)?
-
[6]
How does this animal reproduce (mating habits, gestation period)? Astronomy Questions
-
[7]
What is the name of this planet?
-
[8]
What is its position in the solar system (e.g., 1st from the Sun)?
-
[9]
What is the planet’s classification (terrestrial, gas giant, ice giant)?
-
[10]
Does it have a ring system? If so, how extensive is it?
-
[11]
How long does it take for this planet to orbit the Sun? Buildings Questions
-
[12]
What is the name of this building?
-
[13]
Where is it located?
-
[14]
What was the original purpose of the building?
-
[15]
Is the building open to the public? Cartoon Questions
-
[16]
What is the title of this cartoon?
-
[17]
Who created or produced this cartoon?
-
[18]
When was this cartoon first released or aired?
-
[19]
Who are the main characters in this cartoon?
-
[20]
What is the central storyline or premise of this cartoon? Corporations Questions
-
[21]
What is the name of this corporation?
-
[22]
When was this corporation founded, and by whom?
-
[23]
Where is this corporation’s headquarters located?
-
[24]
What are this corporation’s primary products or services?
-
[25]
What industry does this corporation operate in? 14 MLUBench: A Benchmark for Lifelong Unlearning Evaluation in MLLMs Movies Questions
-
[26]
What is the title of this movie?
-
[28]
When was this film released?
-
[29]
Who are the main actors or actresses in this movie?
-
[30]
What is the central plot or storyline of this movie? Personage Questions
-
[33]
What is this person’s profession?
-
[35]
What contributions has this person made to society or industry? Plants Questions
-
[36]
What is the common name of this plant?
-
[37]
To which family or genus does it belong?
-
[38]
How does it reproduce (seeds, cuttings, runners)?
-
[39]
Is it native to a specific region or found globally?
-
[40]
How does it grow (e.g., tree, shrub, herb)? TV Series Questions
-
[41]
What is the title of this TV series?
-
[42]
Who created or produced this TV series?
-
[43]
When did this TV series first premiere?
-
[44]
Who are the main actors and actresses in this TV series?
-
[45]
Next, I will give you a famous person’s name, I want you to generate answers to the following questions according to this name:
What is the central storyline or premise of this TV series? Example Prompt of GPT-4 for Generating Correct Answers Instruction: You are a helpful assistant. Next, I will give you a famous person’s name, I want you to generate answers to the following questions according to this name:
-
[48]
What is this person’s profession? 15 MLUBench: A Benchmark for Lifelong Unlearning Evaluation in MLLMs
-
[49]
What are the famous works or achievements of this person?
-
[50]
The example prompts for generating corresponding answers are also shown above
What contributions has this person made to society or industry? Input Name:{name of a famous person} The above questions reflect the common characteristic of each type, thus ensuring the quality. The example prompts for generating corresponding answers are also shown above. A.3. Dataset Division Task A Forget Set(Animals + Astronomy, 20 entities) Dog, Cat...
-
[51]
What is the name of this cartoon?
-
[52]
Who is the creator or producer of this cartoon?
-
[53]
When did this cartoon first debut or air?
-
[54]
Who are the primary characters in this cartoon?
-
[55]
What is the main plot or premise of this cartoon? Variant 2
-
[56]
What is the title of this animated series?
-
[57]
Who made or produced this animated show?
-
[58]
What year was this cartoon released?
-
[59]
Who are the main figures in this animated series?
-
[60]
What is the central storyline of this animated series? Variant 3
-
[61]
How is this cartoon referred to?
-
[62]
Who is responsible for creating this cartoon?
-
[63]
When was the initial airing of this cartoon?
-
[64]
What characters play central roles in this cartoon?
-
[65]
What is the basic premise of this cartoon? Variant 4
-
[66]
What do people call this cartoon?
-
[67]
Who developed this animated series?
-
[68]
In which year did this animated series first appear?
-
[69]
Who are the key characters featured in this cartoon?
-
[70]
Can you summarize the main storyline of this cartoon? 17 MLUBench: A Benchmark for Lifelong Unlearning Evaluation in MLLMs The variants of questions for personage Variant 1
-
[71]
What is the name of this individual?
-
[72]
When and where was this person born?
-
[73]
What is this individual’s occupation?
-
[74]
What are this person’s notable works or achievements?
-
[75]
How has this person contributed to society or their industry? Variant 2
-
[76]
What is this person’s name?
-
[77]
What is the birthdate and birthplace of this individual?
-
[78]
What profession does this person hold?
-
[79]
What are the key accomplishments of this individual?
-
[80]
What impact has this individual made in their field or community? Variant 3
-
[81]
How is this person referred to?
-
[82]
Where and when did this person enter the world?
-
[83]
What job does this person do?
-
[84]
What famous contributions has this person made?
-
[85]
What contributions has this person offered to society or their profession? Variant 4
-
[86]
What do people call this individual?
-
[87]
Can you tell me the date and place of this person’s birth?
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.