ZO-Act: Efficient Zeroth-Order Fine-Tuning via One-Shot Activation-Informed Low-Rank Subspaces
Pith reviewed 2026-07-02 15:34 UTC · model grok-4.3
The pith
Restricting zeroth-order perturbations to activation-derived low-rank subspaces improves convergence for LLM fine-tuning without backpropagation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
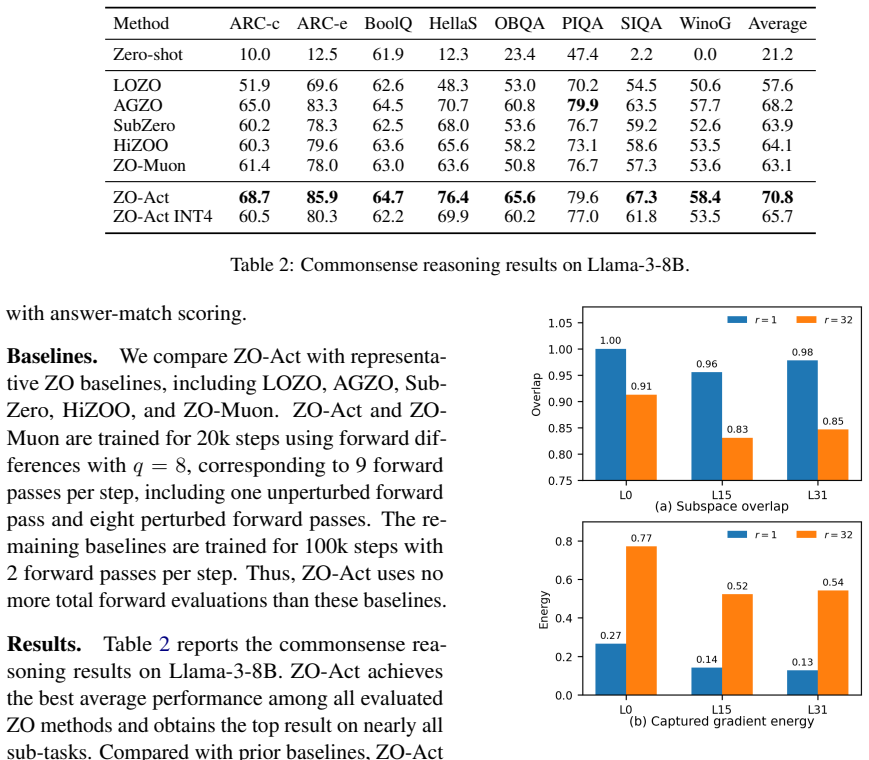
ZO-Act computes a small activation basis once at initialization for each linear layer and optimizes only lightweight coefficient matrices using forward-only loss evaluations. As zeroth-order optimization over a restricted coefficient space, perturbing the low-dimensional coefficients reduces both the variance-dependent convergence term and the finite-difference error of the ZO estimator. The subspace approximation bias remains controlled because of the low-rank structure of LLM activations and gradients. Experiments confirm gains over baselines on Llama-3-8B, OPT-13B, and their quantized versions for understanding, QA, and reasoning tasks.
What carries the argument
The one-shot activation-informed low-rank subspace that restricts perturbations to coefficient matrices for each linear layer.
If this is right
- The variance-dependent term in convergence decreases with lower perturbation dimension.
- Finite-difference error of the ZO estimator is reduced.
- Subspace bias is mitigated by low-rank activation structure, enabling practical use.
- The method supports momentum optimizers like Adam and quantized fine-tuning.
- Performance improves on standard LLM benchmarks compared to full-weight or random-subspace ZO methods.
Where Pith is reading between the lines
- If low-rank structure holds more generally, the approach could apply to other neural network types beyond transformers.
- Further reduction in memory could come from combining the fixed subspace with additional compression on the coefficients.
- The one-time basis computation suggests potential for online adaptation if activations shift significantly during training.
Load-bearing premise
LLM activations and gradients possess enough low-rank structure for the subspace approximation bias to remain controlled in practice.
What would settle it
Running the method on a model or task where the activation matrices do not exhibit low-rank structure and observing that performance falls below random low-dimensional subspace baselines would falsify the controlled-bias claim.
Figures
read the original abstract
Zeroth-order (ZO) optimization enables fine-tuning large language models when backpropagation is unavailable or memory-prohibitive, but existing methods often perturb full model weights or randomly constructed low-dimensional subspaces, yielding high-variance estimates and limited performance. We propose ZO-Act, an activation-informed ZO fine-tuning method that restricts perturbations to a fixed low-rank subspace derived from input activations. For each linear layer, ZO-Act computes a small activation basis once at initialization and optimizes only lightweight coefficient matrices using forward-only loss evaluations. This reduces the effective perturbation dimension, exposes explicit trainable variables compatible with momentum-based optimizers such as Adam, and naturally supports quantized LLM fine-tuning by keeping low-bit weights frozen. We analyze ZO-Act as zeroth-order optimization over a restricted coefficient space and show that perturbing the low-dimensional coefficients reduces both the variance-dependent convergence term and the finite-difference error of the ZO estimator, at the cost of a controlled subspace approximation bias that is mitigated by the low-rank structure of LLM activations and gradients. Experiments on Llama-3-8B, OPT-13B, and INT4 Llama-3-8B show consistent gains over strong ZO fine-tuning baselines across language understanding, question answering, and commonsense reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ZO-Act, a zeroth-order fine-tuning method that computes a fixed low-rank activation basis once at initialization for each linear layer and restricts perturbations to the corresponding coefficient matrices. It analyzes this as ZO optimization over a restricted coefficient space, claiming reductions in the variance-dependent convergence term and finite-difference error of the ZO estimator at the cost of a controlled subspace approximation bias mitigated by low-rank structure in LLM activations and gradients. Experiments report consistent gains over ZO baselines on Llama-3-8B, OPT-13B, and INT4 Llama-3-8B for language understanding, QA, and commonsense reasoning tasks.
Significance. If the bias remains controlled throughout training, the method offers a practical advance for memory-efficient ZO fine-tuning of large models, including quantized ones, by enabling lower-dimensional perturbations compatible with standard optimizers like Adam while using only forward passes.
major comments (2)
- [Abstract] Abstract (analysis paragraph): The central claim that perturbing low-dimensional coefficients reduces variance and finite-difference error 'at the cost of a controlled subspace approximation bias that is mitigated by the low-rank structure of LLM activations and gradients' treats the one-shot initial basis as fixed; no explicit bound is given on how the approximation error evolves as gradients change during fine-tuning, which is load-bearing for the convergence analysis.
- [Abstract] The analysis invokes low-rank structure to control bias but provides no quantitative condition (e.g., in terms of singular-value decay rates or a dynamic error term) under which the fixed initial subspace remains a sufficient approximation to evolving gradient directions; this assumption is invoked to justify practical performance but lacks a supporting lemma or corollary.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the analysis in the abstract. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (analysis paragraph): The central claim that perturbing low-dimensional coefficients reduces variance and finite-difference error 'at the cost of a controlled subspace approximation bias that is mitigated by the low-rank structure of LLM activations and gradients' treats the one-shot initial basis as fixed; no explicit bound is given on how the approximation error evolves as gradients change during fine-tuning, which is load-bearing for the convergence analysis.
Authors: We agree that no explicit bound on the evolution of the approximation error is provided. The convergence analysis is derived for optimization over the fixed coefficient space and demonstrates reductions in the variance-dependent term and finite-difference error relative to full-parameter ZO methods. The subspace bias is described as controlled due to the low-rank structure of activations and gradients, an assumption supported by prior observations in the LLM literature and by the empirical results across models. We will revise the abstract to state this assumption explicitly and to clarify that the analysis does not claim a dynamic bound on bias evolution. revision: partial
-
Referee: [Abstract] The analysis invokes low-rank structure to control bias but provides no quantitative condition (e.g., in terms of singular-value decay rates or a dynamic error term) under which the fixed initial subspace remains a sufficient approximation to evolving gradient directions; this assumption is invoked to justify practical performance but lacks a supporting lemma or corollary.
Authors: We acknowledge that the manuscript provides no quantitative condition on singular-value decay or a supporting lemma for the persistence of the initial subspace. The low-rank structure is invoked as an empirical property of LLM activations that enables the one-shot basis construction; the method's practical gains are demonstrated experimentally rather than through a formal dynamic error bound. Deriving such a lemma would require additional assumptions on gradient trajectories that fall outside the paper's scope. We will revise the text to make the empirical nature of this assumption explicit. revision: partial
- Deriving an explicit bound or lemma on the evolution of the fixed initial subspace approximation error during training without further assumptions on gradient dynamics.
Circularity Check
No significant circularity detected
full rationale
The abstract presents ZO-Act as constructing a fixed low-rank activation basis once at initialization and then analyzing zeroth-order optimization over the resulting coefficient space, claiming variance reduction and controlled bias due to low-rank structure of activations/gradients. No quoted equations, self-citations, or derivation steps reduce the claimed convergence benefits or bias control to quantities fitted from the same data or to prior self-referential results by construction. The subspace construction is an explicit one-shot procedure independent of the optimization trajectory, and the analysis is presented as a standard restricted-space ZO bound rather than a renaming or self-definition. This matches the reader's assessment of non-circularity; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM layer activations and gradients exhibit low-rank structure sufficient to control subspace approximation bias
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Learning Representa- tions, volume 2025, pages 62581–62607
Enhancing zeroth-order fine- tuning for language models with low-rank structures. InInternational Conference on Learning Representa- tions, volume 2025, pages 62581–62607. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova
2025
-
[2]
Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chap- ter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), pages 2924–2936. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoen...
2019
-
[3]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question an- swering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457. Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Selcuk Gurses, Aozhong Zhang, Yanxia Deng, Xun Dong, Xin Li, Naigang Wang, Penghang Yin, and Zi Yang
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Diablo: Diagonal blocks are sufficient for finetuning.arXiv preprint arXiv:2506.03230. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685. Yicheng Lang, Changsheng Wang, Yihua Zhang, Mingyi Hong, Zheng Zhang, Wotao Yin, and Sijia Liu
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Wei Lin, Yining Jiang, Qingyu Song, Qiao Xiang, and Hong Xu
Powering up zeroth-order training via subspace gradient orthogonalization.arXiv preprint arXiv:2602.17155. Wei Lin, Yining Jiang, Qingyu Song, Qiao Xiang, and Hong Xu
-
[8]
AGZO: Activation-Guided Zeroth-Order Optimization for LLM Fine-Tuning
Agzo: Activation-guided zeroth- order optimization for llm fine-tuning.arXiv preprint arXiv:2601.17261. Sijia Liu, Jie Chen, Pin-Yu Chen, and Alfred Hero
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391
Can a suit of armor conduct elec- tricity? a new dataset for open book question an- swering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391. Yurii Nesterov and Vladimir Spokoiny
2018
-
[10]
Social iqa: Com- monsense reasoning about social interactions. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473. Alex Wang, Yada Pruksachatkun, Nikita Nangia, Aman- preet Singh, Julian Michael, Felix Hill, Omer...
2019
-
[11]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068. Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Ja- son D Lee, Wotao Yin, Mingyi Hong, and 1 oth- ers. 2024b. Revisiting zeroth-order optimization for memory-efficient llm fine-tuning: A benchmark. arXiv preprint arXiv:2402.1159...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Galore: Memory-efficient llm training by gradient low-rank projection.arXiv preprint arXiv:2403.03507. Yanjun Zhao, Sizhe Dang, Haishan Ye, Guang Dai, Yi Qian, and Ivor Tsang
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InInternational Conference on Learning Representations, volume 2025, pages 43496–43520
Second-order fine- tuning without pain for llms: A hessian informed zeroth-order optimizer. InInternational Conference on Learning Representations, volume 2025, pages 43496–43520. A Proofs and Analysis A.1 Formal Statement and Proof of Theorem 1 Theorem 2(Convergence of ZO-Act).Let ϕ(β) = F(θ 0 +U β) , where β∈R k collects all trainable coefficient matric...
2025
-
[14]
Thus, E⟨gt,bgt⟩=E⟨g t,¯at⟩+E⟨g t,¯bt⟩ ≥ ∥g t∥2 − ∥gt∥E∥¯bt∥ ≥ ∥g t∥2 − 1 2 ∥gt∥2 + 1 2(E∥¯bt∥)2 = 1 2 ∥gt∥2 − L2 F µ2 8 Mk
, Then E∥¯bt∥ ≤(L F µ/2)√Mk. Thus, E⟨gt,bgt⟩=E⟨g t,¯at⟩+E⟨g t,¯bt⟩ ≥ ∥g t∥2 − ∥gt∥E∥¯bt∥ ≥ ∥g t∥2 − 1 2 ∥gt∥2 + 1 2(E∥¯bt∥)2 = 1 2 ∥gt∥2 − L2 F µ2 8 Mk. Next, we upper bound the second moment ofbgt. For the leading Gaussian term, E∥a(j) t ∥2 =E[⟨g t, z⟩2∥z∥2] = (k+ 2)∥g t∥2. Therefore, since the a(j) t ’s are independent and each has meang t, E∥¯at∥2 =∥E¯...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.