Gradient-Descent Steps to Success over Mean Accuracy: A Paradigm Shift for ML
Pith reviewed 2026-06-26 12:34 UTC · model grok-4.3
The pith
Shifting ML evaluation from peak accuracy to the number of gradient descent steps needed to reach target accuracy favors large learning rates and reveals phase transitions in restart strategy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
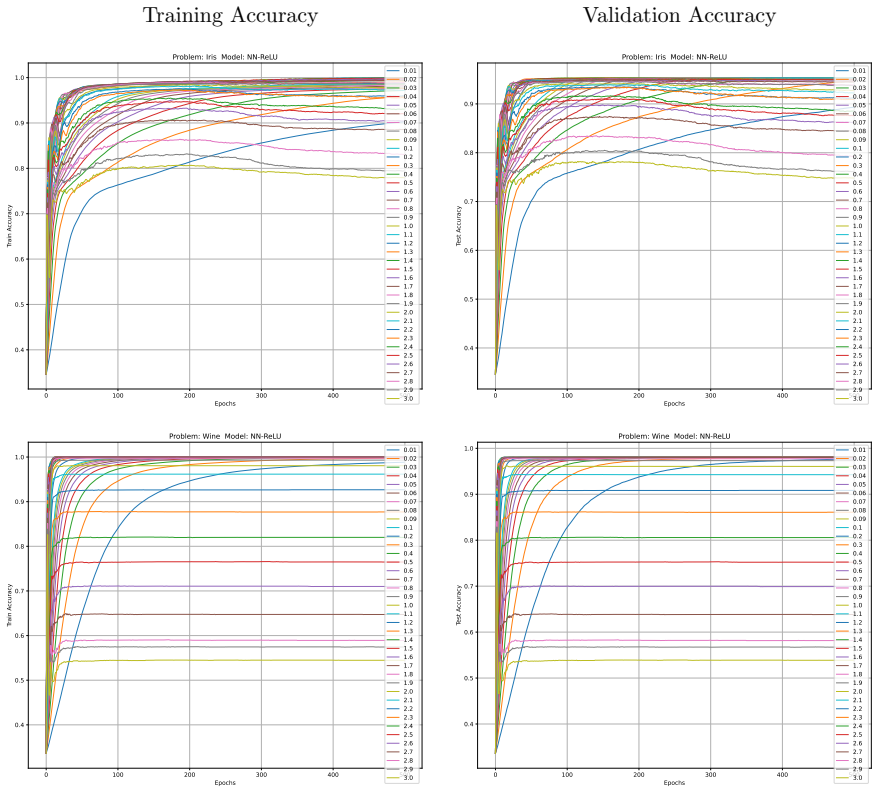
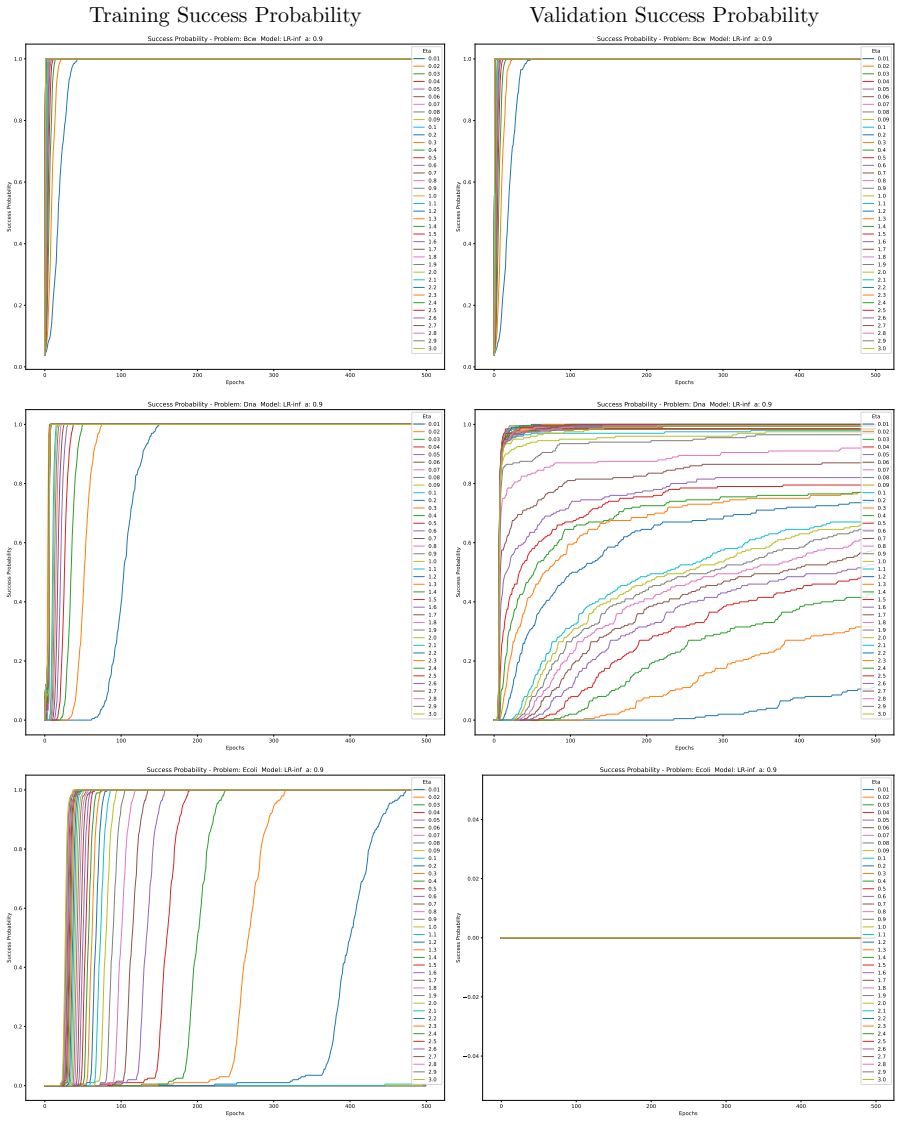
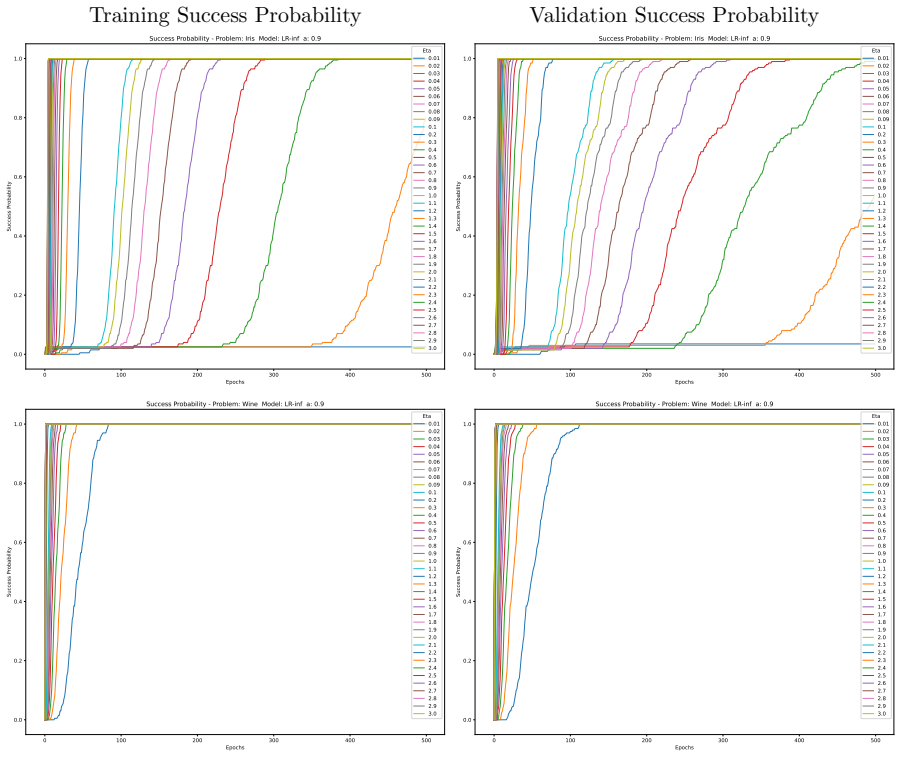
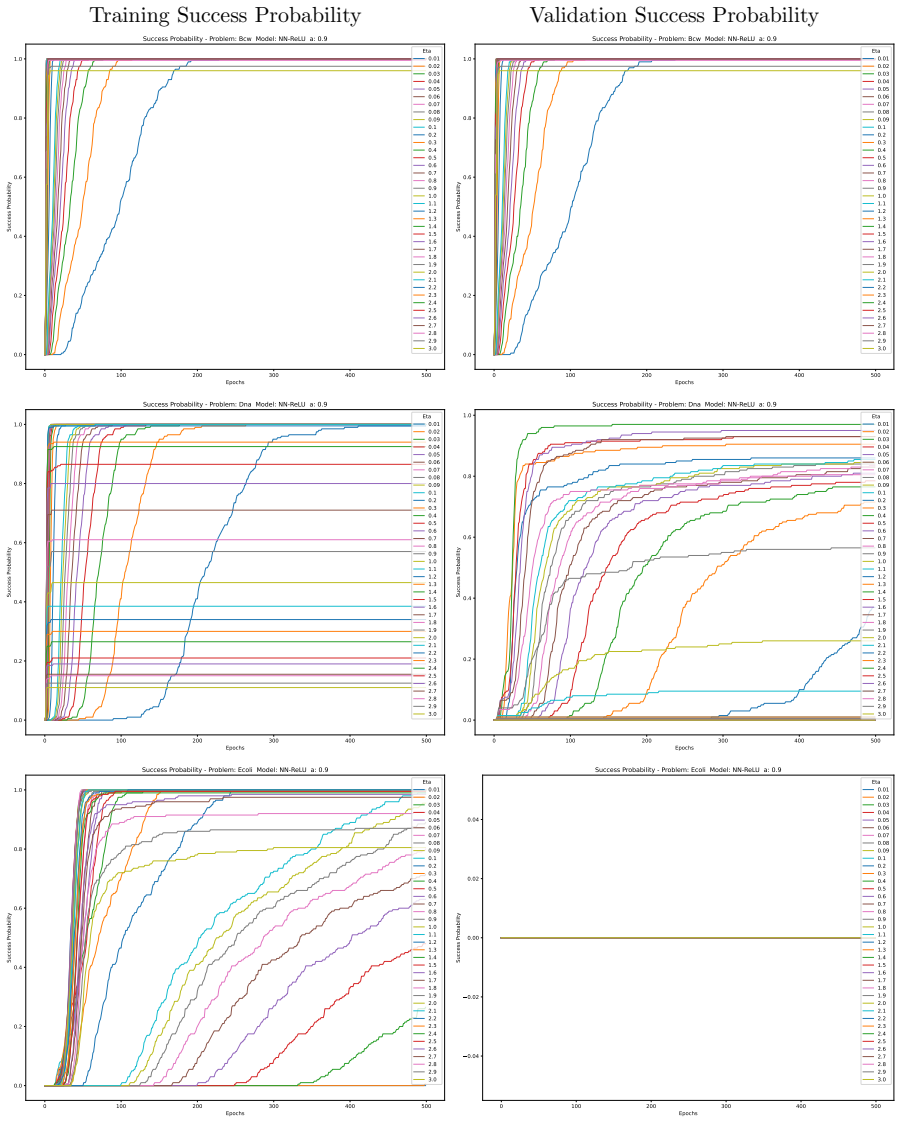
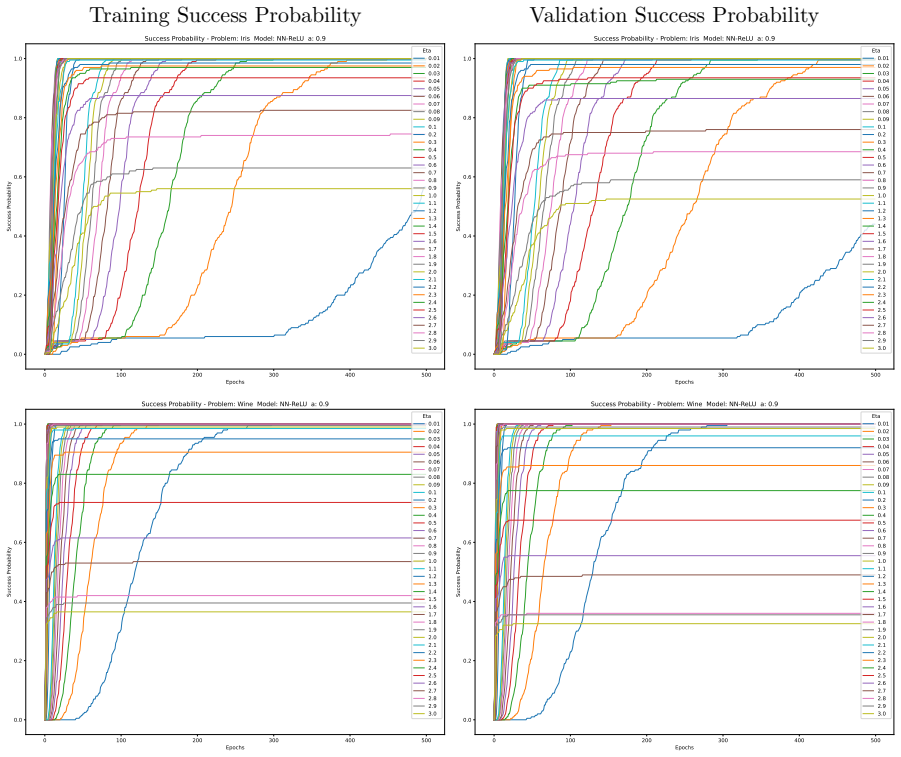
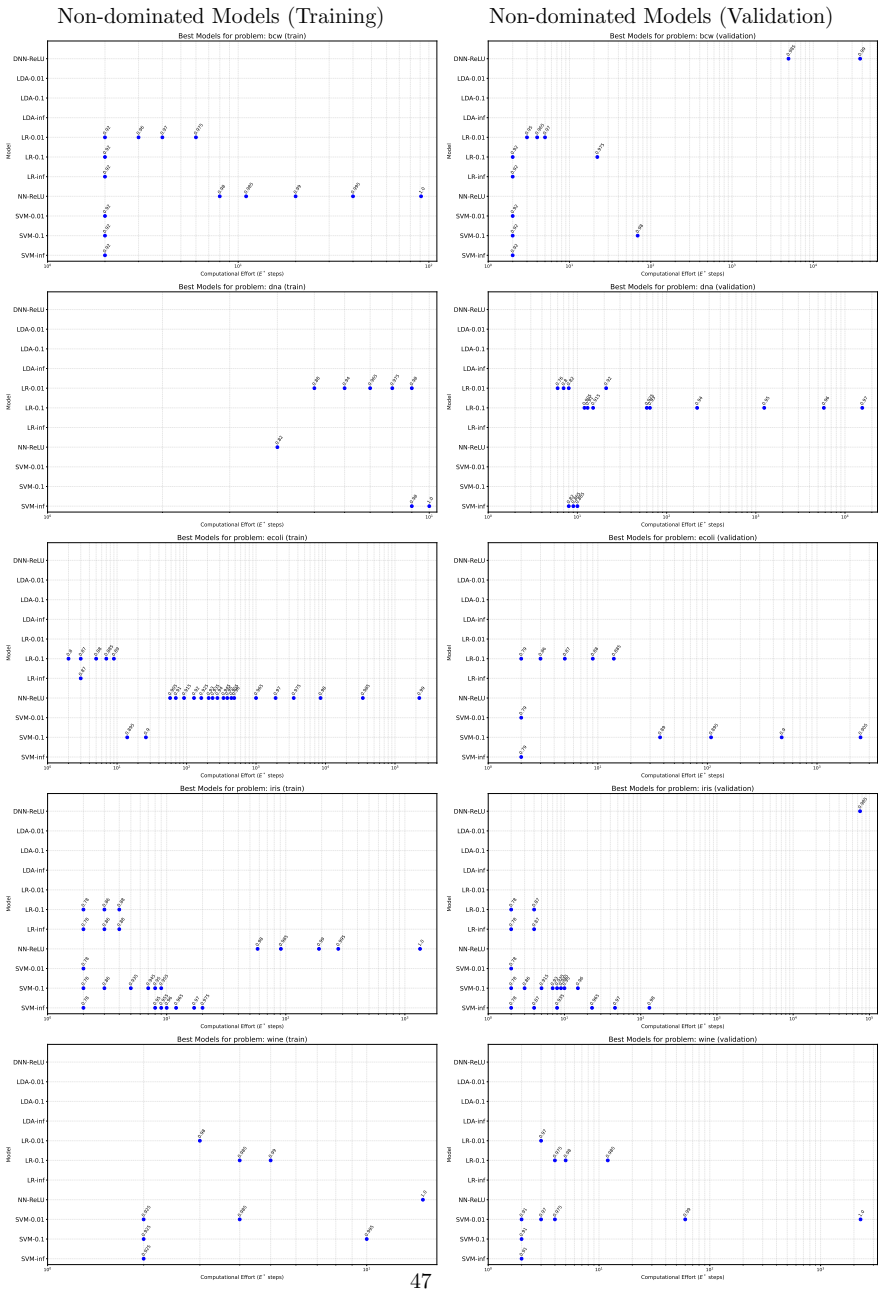
Minimising the expected number of gradient descent steps to reach a target accuracy with high probability leads to hyperparameter choices, in particular unusually large learning rates, that promote generalisation while statistically minimising training effort, accompanied by distinct phase transitions in optimal search strategy between single runs for lower targets and numerous independent short restarts for maximum performance.
What carries the argument
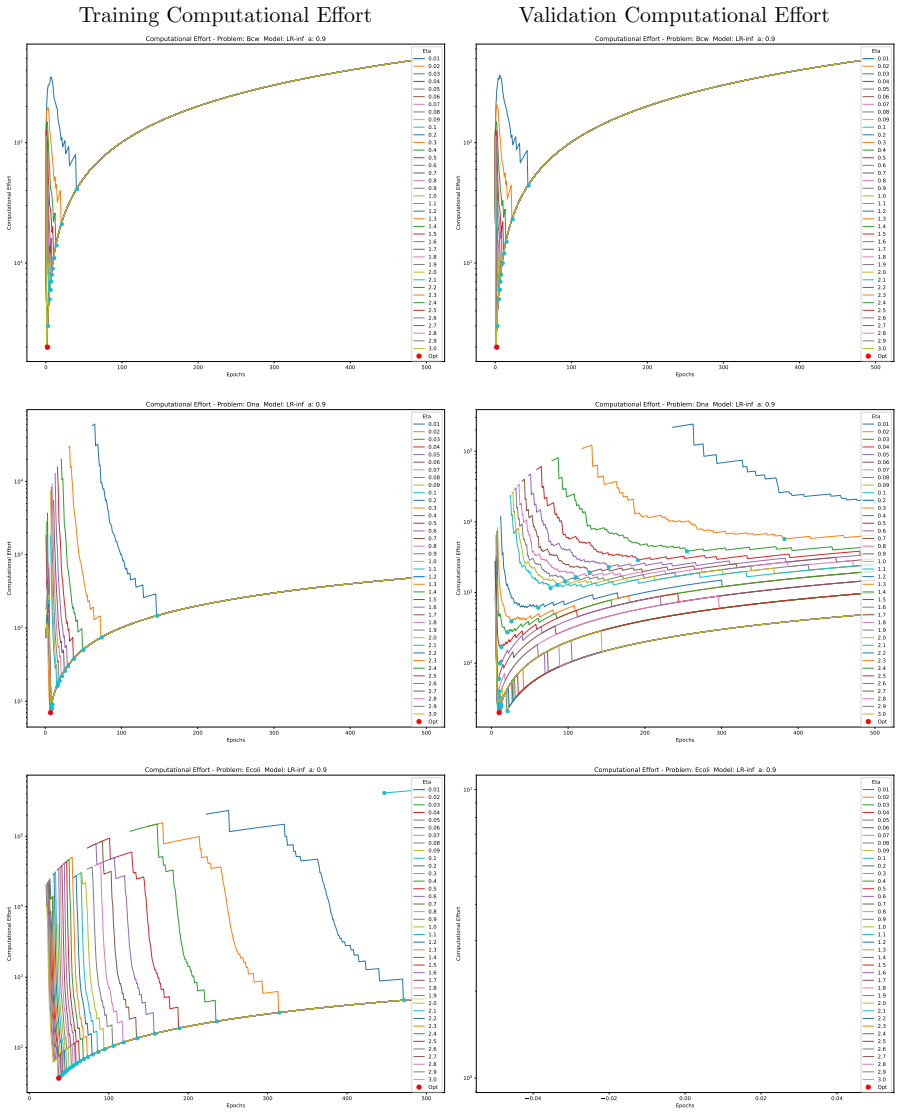
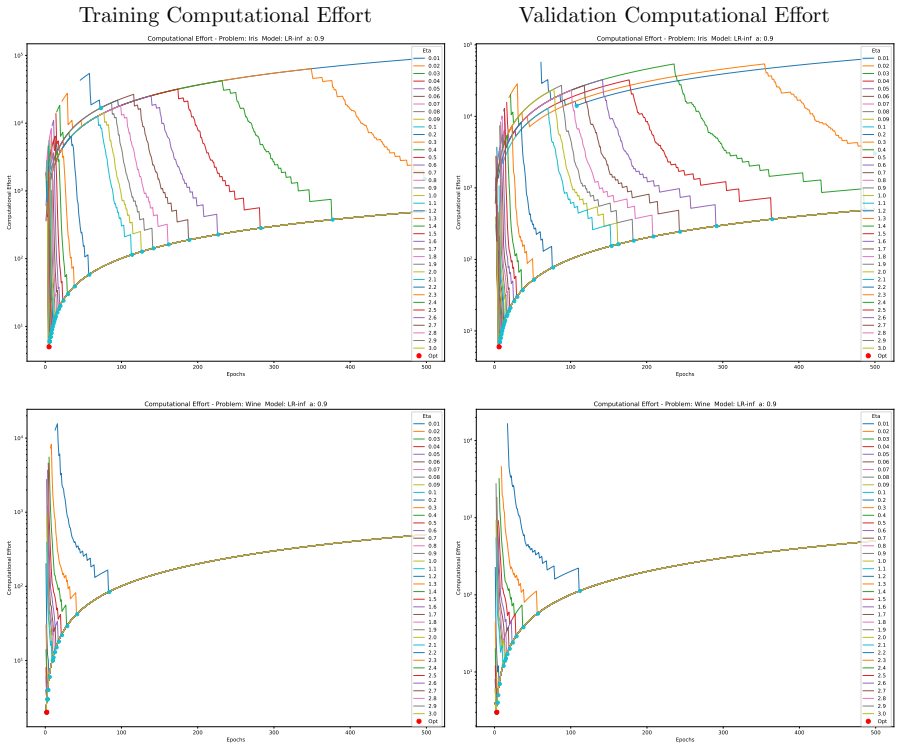
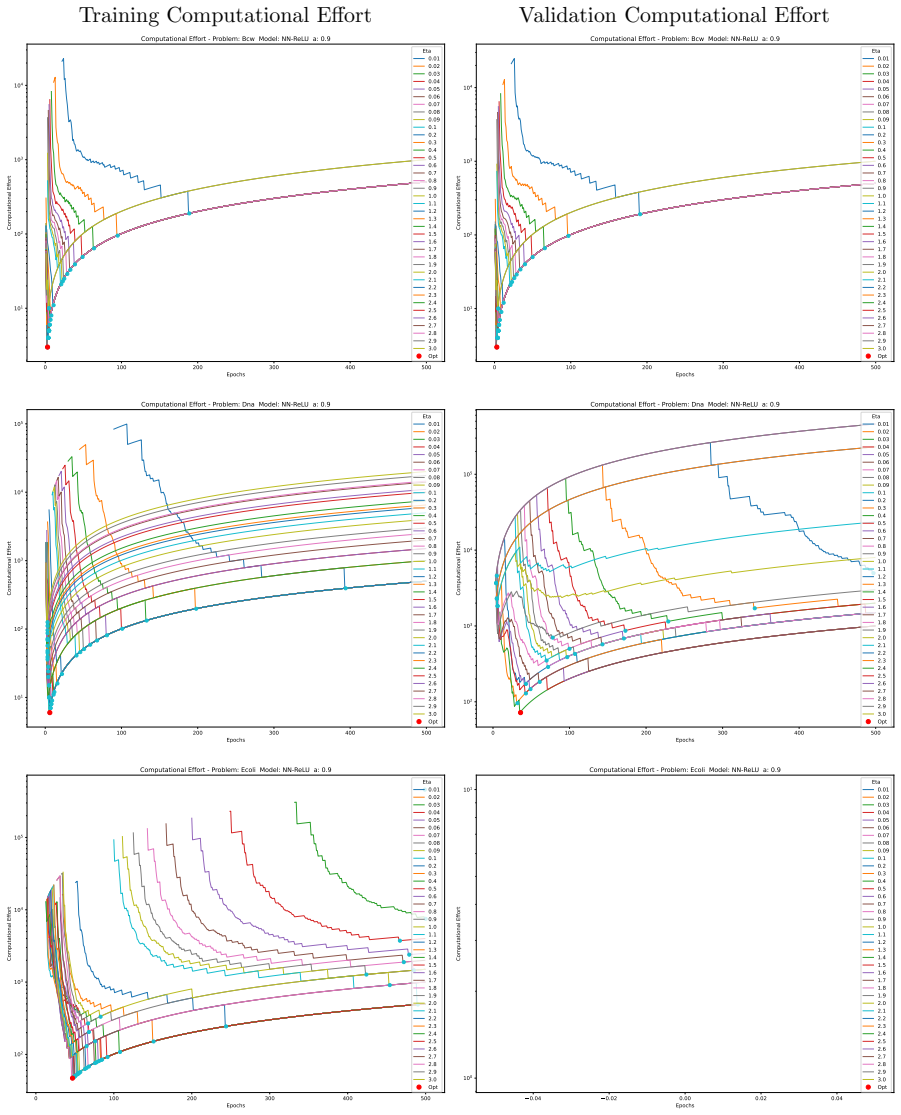
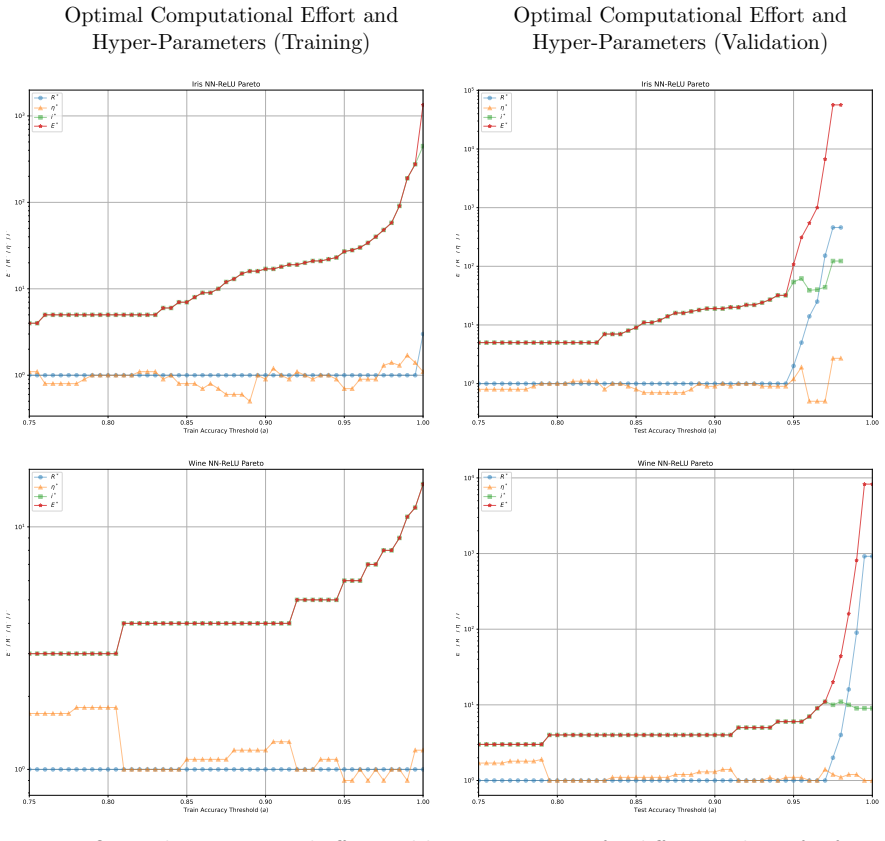
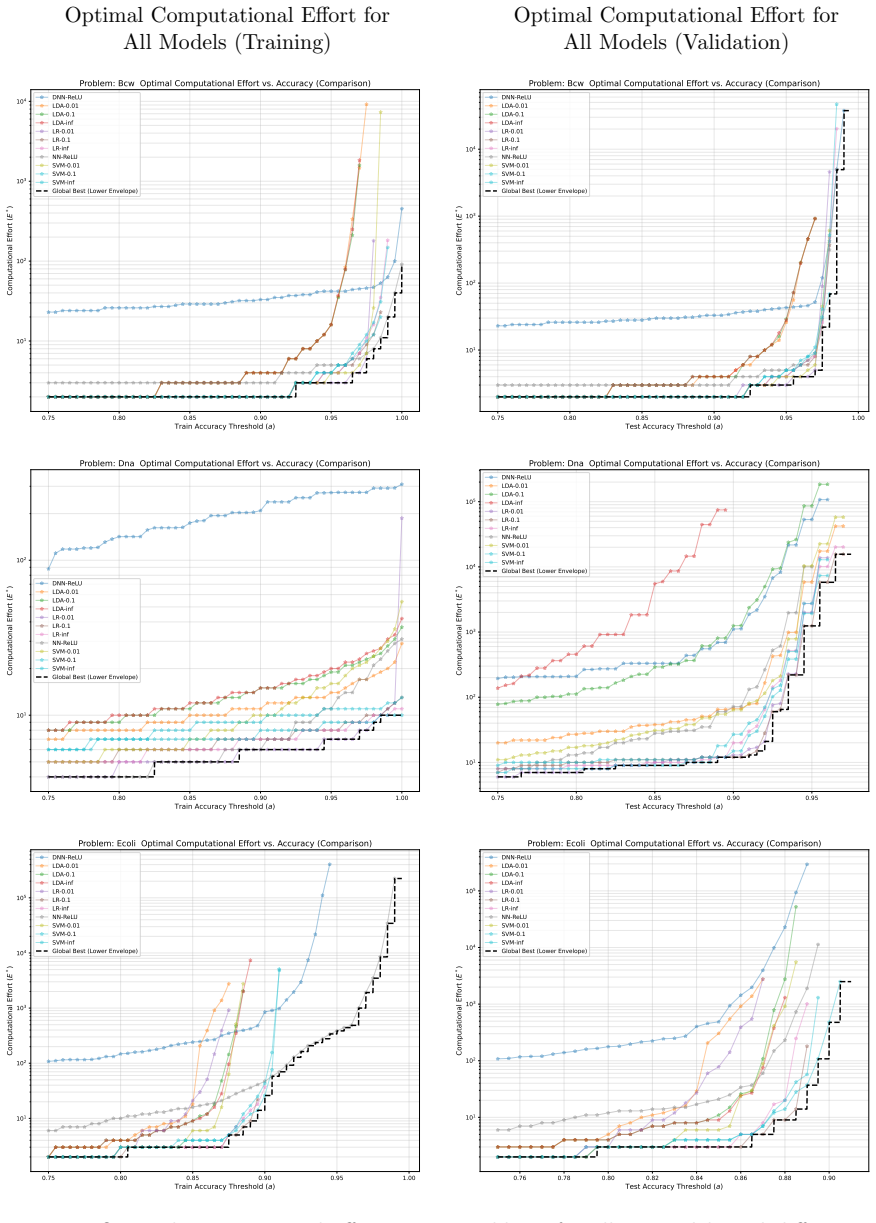
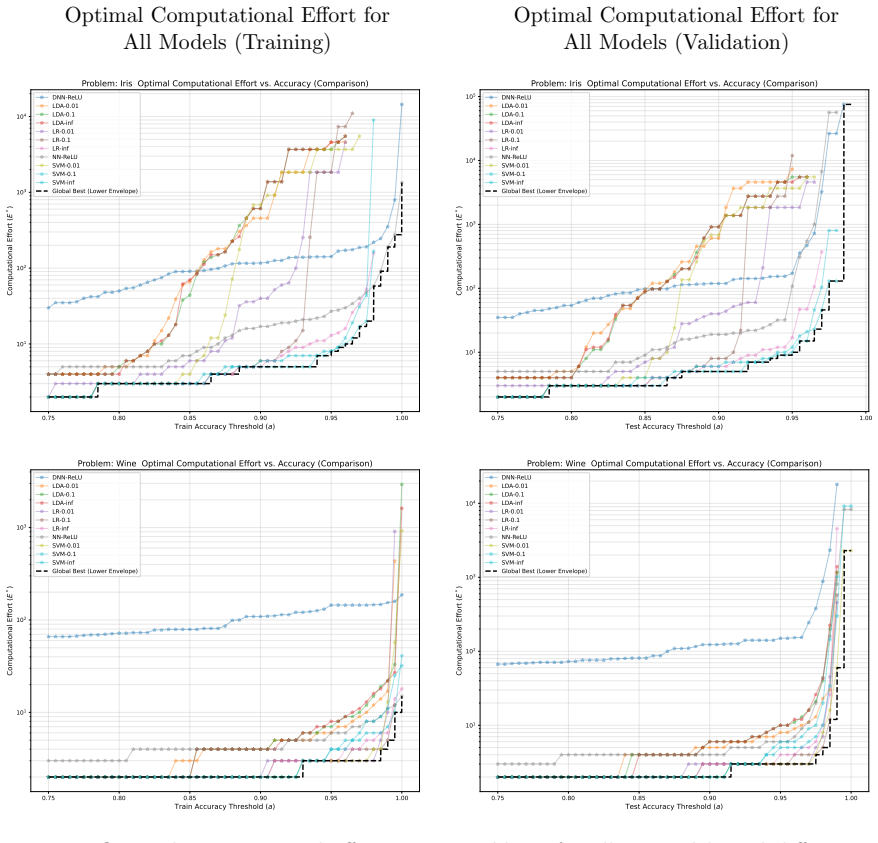
The computational effort metric: total gradient descent steps to reach acceptable accuracy with high probability, used as a hardware-independent proxy that extends Koza's genetic programming concept to gradient-descent models and serves as the objective for hyperparameter search.
If this is right
- Optimal hyperparameters consistently include unusually large learning rates.
- Rapid aggressive landscape traversal with large rates promotes generalisation and minimises expected computational effort.
- A single training run suffices for lower accuracy targets while numerous independent short restarts become necessary to reach a model's performance limit.
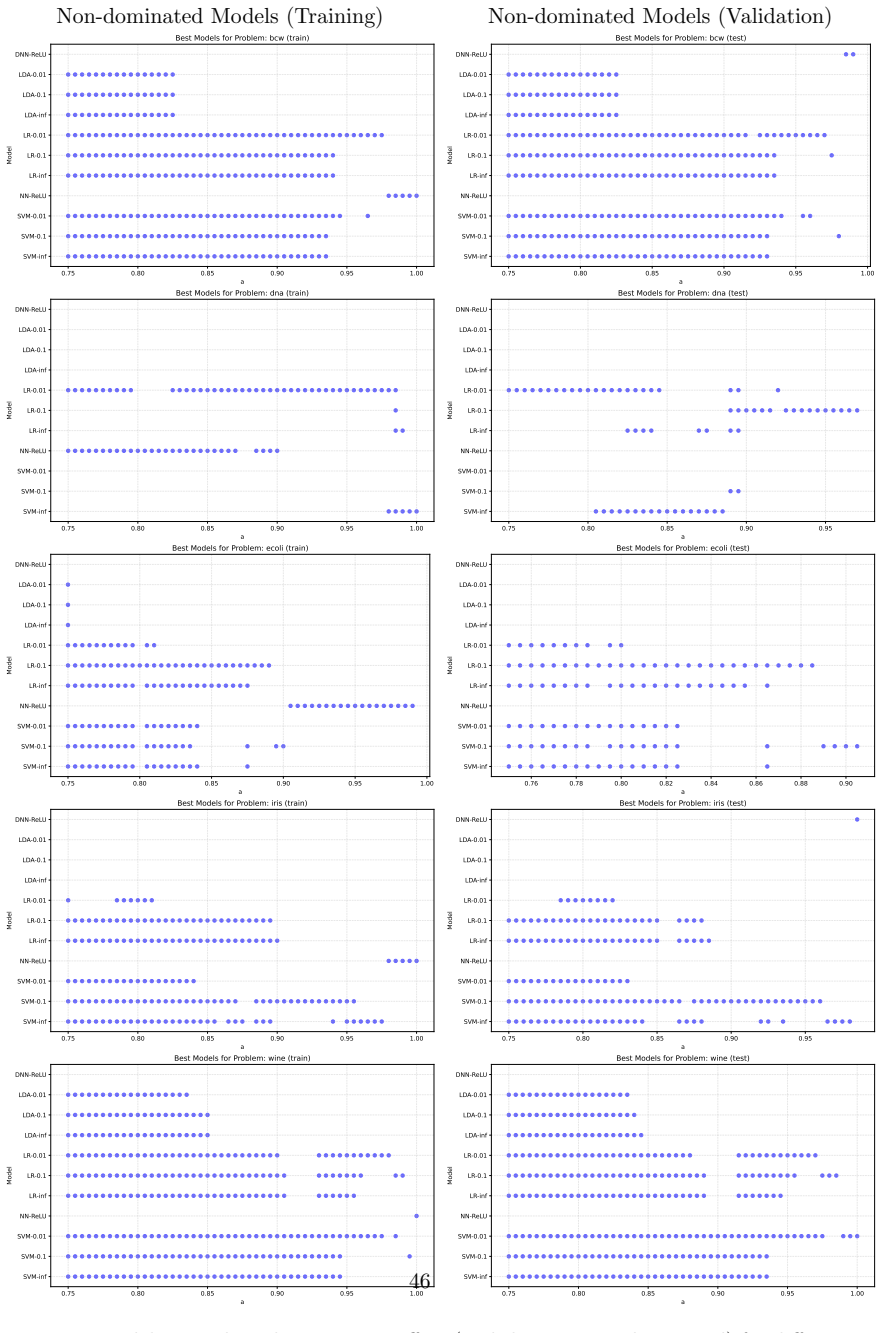
- The effort metric supplies a framework for choosing among algorithms according to how efficiently each perceives the difficulty of a given problem at a chosen accuracy level.
Where Pith is reading between the lines
- AutoML systems could be redesigned to search directly over effort rather than accuracy or validation loss.
- Training protocols might routinely begin with large rates followed by adaptive restarts once a target accuracy band is specified.
- Model selection in practice could shift from accuracy tables to effort curves that indicate the cheapest route to each accuracy level.
- The same effort accounting could be applied to non-gradient optimizers to compare training cost across fundamentally different algorithms.
Load-bearing premise
The number of gradient descent steps to reach an acceptable accuracy level with high probability can be measured consistently and serves as a valid hardware-independent proxy for computational effort.
What would settle it
An experiment on the same models and datasets that finds small learning rates achieve target accuracy in fewer total gradient steps than large rates, or shows no observable switch from single-run to multi-restart strategy as accuracy targets increase.
Figures
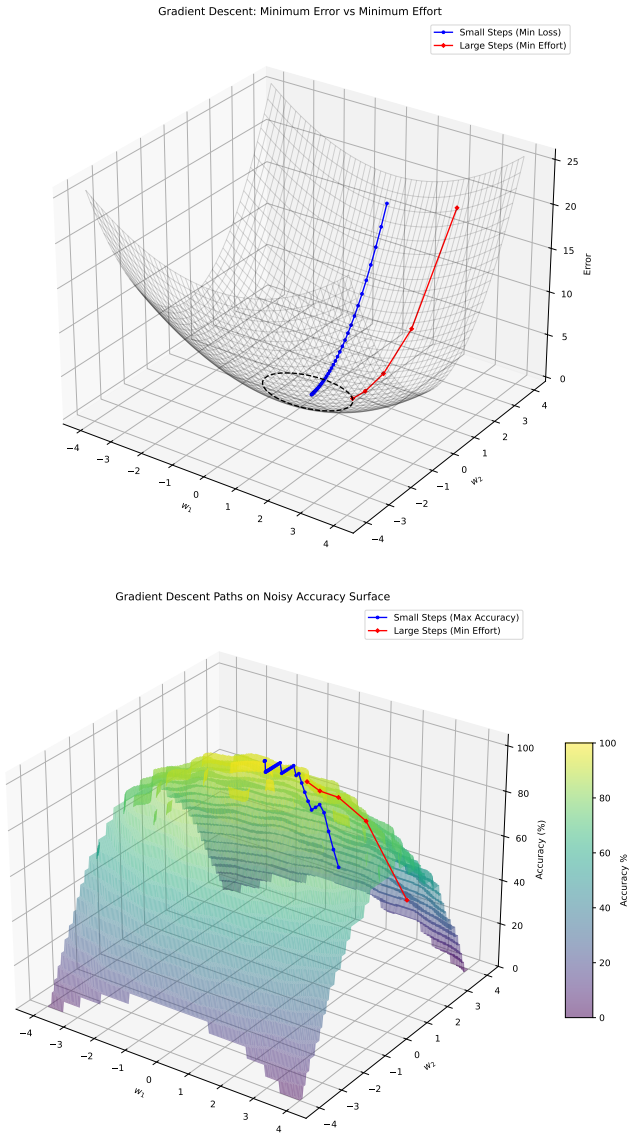
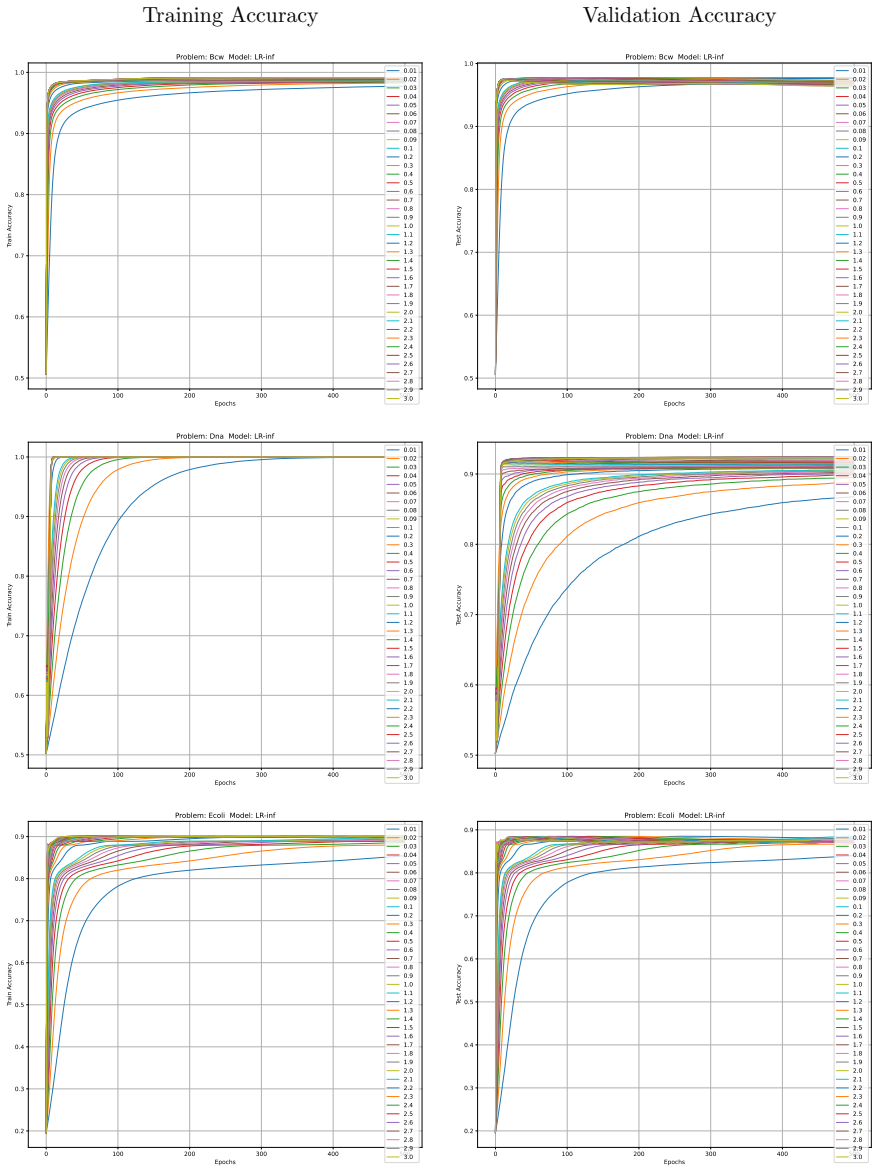
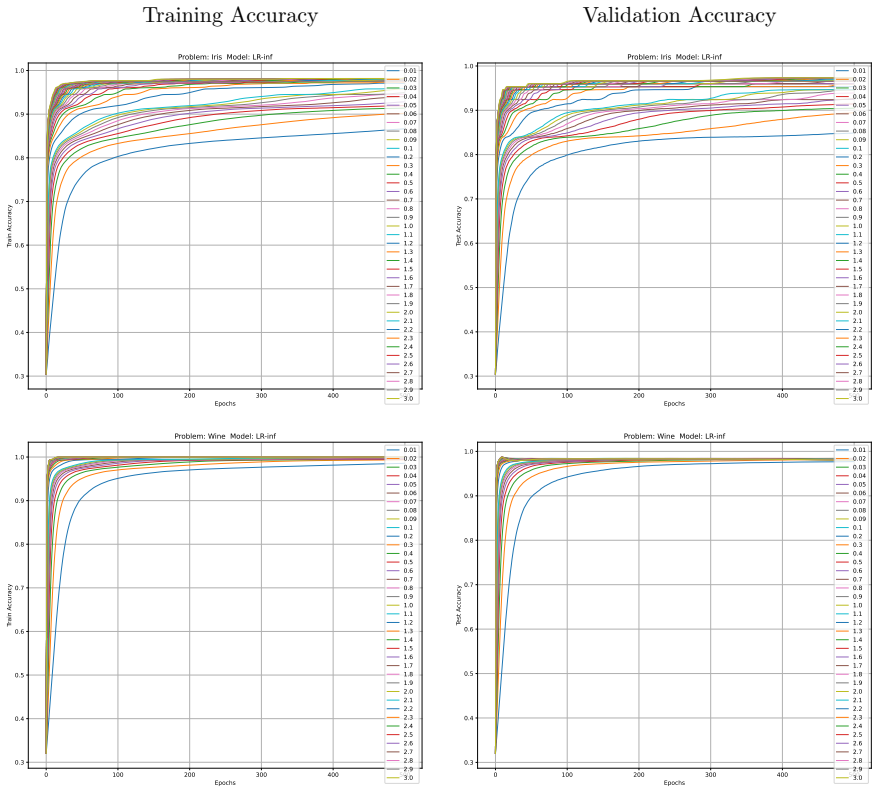
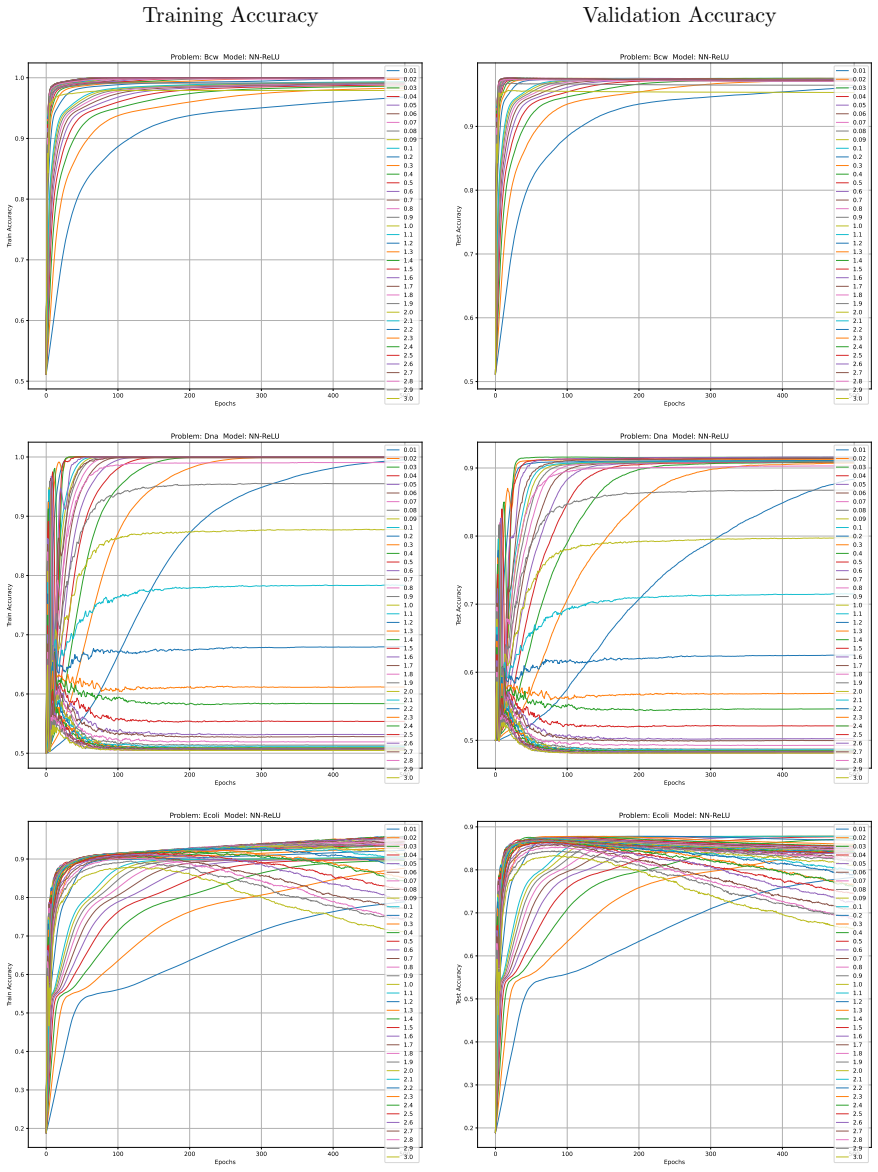
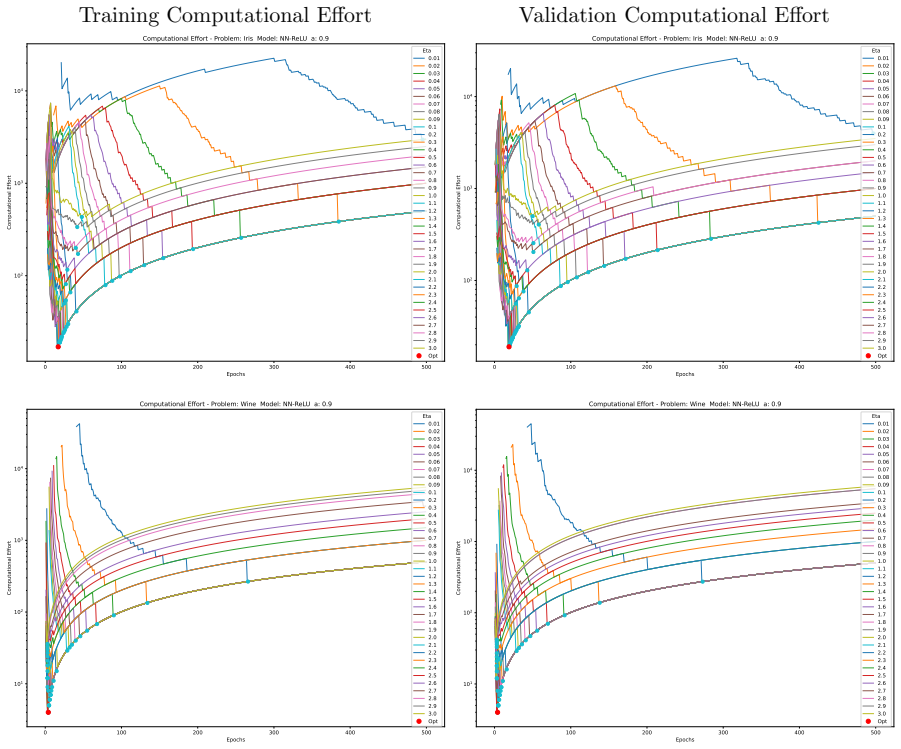
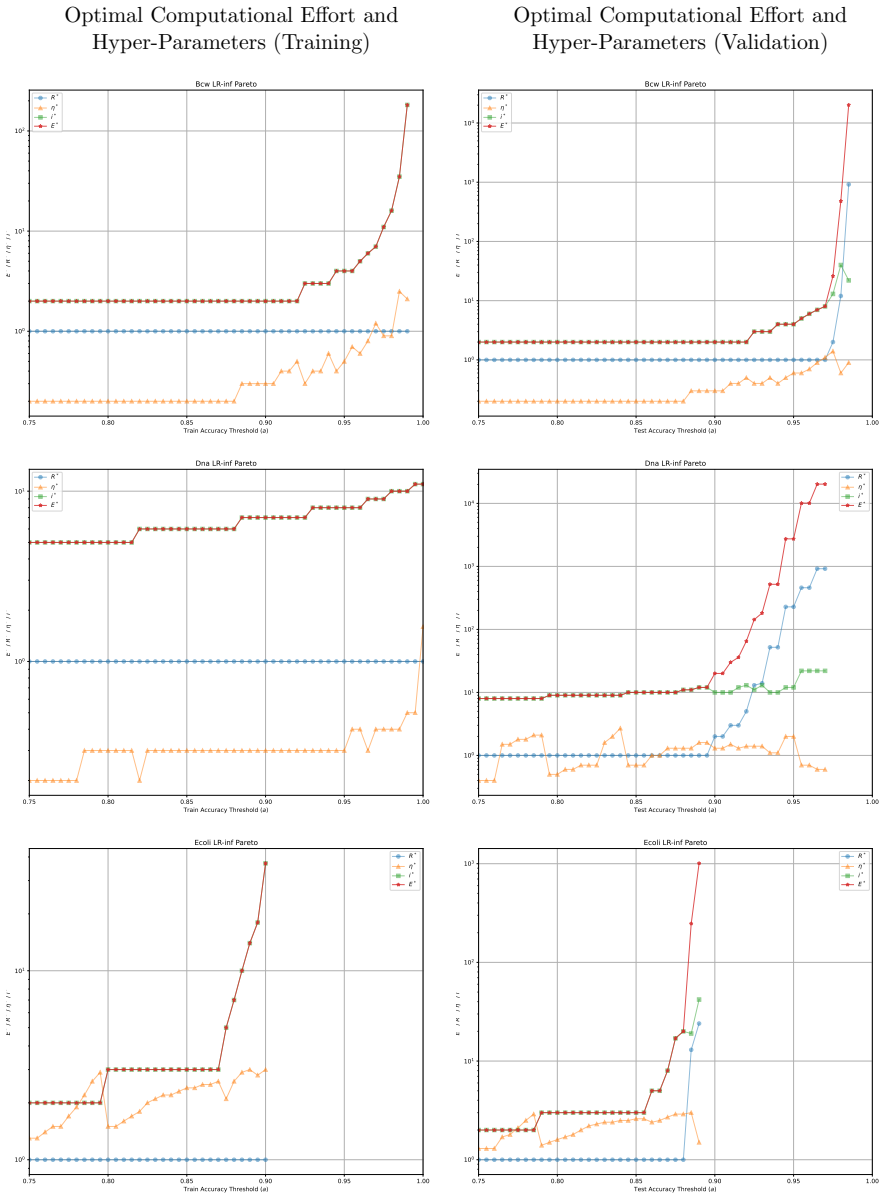
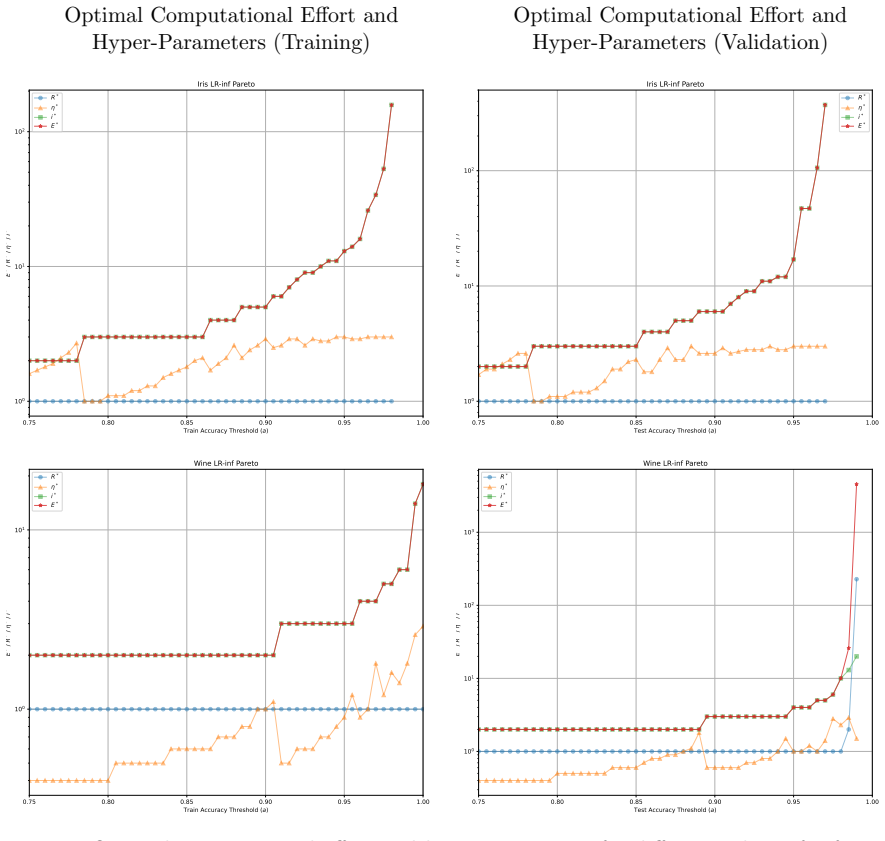
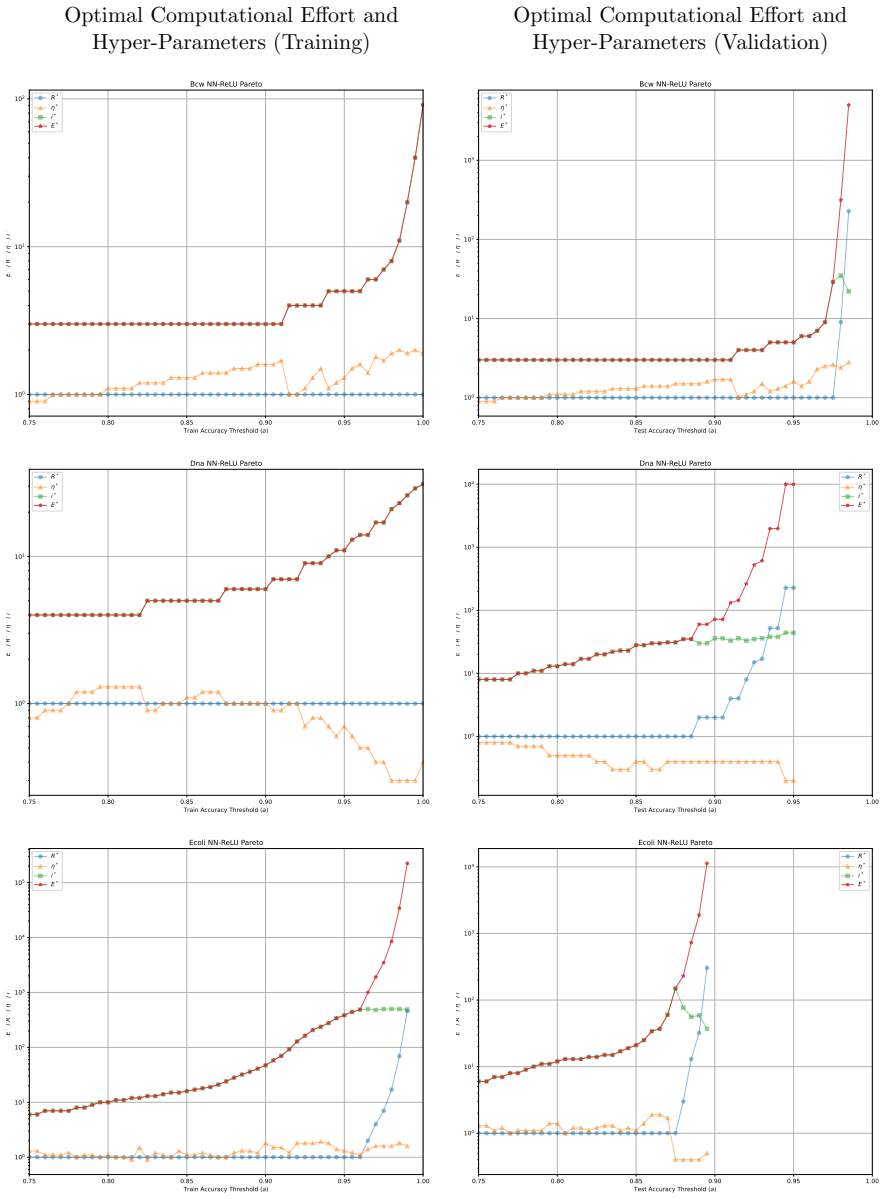
read the original abstract
Traditional evaluation of machine learning (ML) models typically focuses on achieving the maximum possible accuracy irrespective of the computational cost. In this article, we propose a paradigm shift towards evaluating performance based on computational effort-explicitly defined here as the total number of gradient descent steps required to reach an acceptable level of accuracy with high probability. Building upon the concept of computational effort originally introduced by Koza for Genetic Programming, we extend this metric to any ML model trained via gradient descent. Furthermore, we demonstrate that minimising this effort acts as a novel form of Automatic Machine Learning (AutoML). By evaluating it across 11 diverse ML models and five standard classification datasets, we uncover significant insights into the dynamics of gradient-based learning. Our findings reveal that optimal hyper-parameters consistently favour unusually large learning rates. Crucially, we demonstrate that the rapid, aggressive landscape traversal enabled by these large rates not only promotes generalisation-as seen in phenomena like superconvergence-but also statistically minimises the expected computational effort for training. Furthermore, we identify distinct phase transitions in the optimal search strategy: while a single training run suffices for lower accuracy targets, reaching a model's performance limit requires a dramatic shift towards conducting numerous independent, short restarts. Finally, we illustrate how this effort-based paradigm provides a robust framework for model selection, allowing practitioners to choose optimal algorithms based on the difficulty of a problem as perceived by different models for a given target accuracy, or to maximise the achievable accuracy for a fixed budget of gradient descent steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a paradigm shift in ML evaluation from maximizing accuracy to minimizing computational effort, defined as the expected number of gradient-descent steps required to reach an acceptable accuracy level with high probability. It extends Koza's metric from genetic programming to gradient-descent models, claims that minimizing this effort constitutes a novel AutoML procedure, and reports experiments across 11 models and 5 datasets showing that optimal hyperparameters favor unusually large learning rates (linked to superconvergence), distinct phase transitions in restart strategies (single run vs. many short restarts), and a framework for model selection based on problem difficulty.
Significance. If the effort metric can be shown to be robustly defined and the experimental protocol made reproducible, the work could supply a useful alternative lens on training efficiency and hyperparameter choice that complements accuracy-centric evaluation. The reported preference for large learning rates and the identified phase transitions would then constitute concrete, testable observations about optimization dynamics. At present the significance is constrained by the absence of a verifiable protocol for the metric itself.
major comments (2)
- [Abstract / experimental design] Abstract and experimental protocol: the central claims (large-LR optimality, superconvergence link, single-run vs. many-restart phase transitions) rest on treating the expected number of GD steps to a target accuracy (with high probability) as a well-defined, hardware-independent proxy. No explicit protocol is supplied for choosing the per-model/dataset accuracy threshold, for estimating the success probability (number of trials, success criterion), or for controlling confounding factors such as batch-size changes or restart overhead that alter per-step cost.
- [Metric definition] The assertion that the metric extends Koza's GP effort measure without modification is load-bearing for the novelty claim, yet the manuscript does not demonstrate that the step count remains comparable when per-step floating-point operations vary with learning-rate magnitude or when divergence forces smaller batches.
minor comments (1)
- [Abstract] The abstract refers to "11 diverse ML models and five standard classification datasets" without naming them or providing data-split details; this should be stated explicitly in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater clarity on the experimental protocol and metric robustness. We address each major comment below and will incorporate revisions to strengthen reproducibility while preserving the core contributions on effort-based evaluation.
read point-by-point responses
-
Referee: [Abstract / experimental design] Abstract and experimental protocol: the central claims (large-LR optimality, superconvergence link, single-run vs. many-restart phase transitions) rest on treating the expected number of GD steps to a target accuracy (with high probability) as a well-defined, hardware-independent proxy. No explicit protocol is supplied for choosing the per-model/dataset accuracy threshold, for estimating the success probability (number of trials, success criterion), or for controlling confounding factors such as batch-size changes or restart overhead that alter per-step cost.
Authors: We agree an explicit protocol is required for verifiability. In revision we will add a Methods subsection specifying: accuracy thresholds are chosen as 90% of the highest accuracy attained by any configuration for that model-dataset pair; success probability is estimated from 50 independent random-seed trials per hyperparameter setting, with success defined as reaching the threshold before a hard step limit; batch size is fixed across all runs and restart overhead is excluded because the metric counts only gradient-descent steps. These choices keep the proxy hardware-independent by design. revision: yes
-
Referee: [Metric definition] The assertion that the metric extends Koza's GP effort measure without modification is load-bearing for the novelty claim, yet the manuscript does not demonstrate that the step count remains comparable when per-step floating-point operations vary with learning-rate magnitude or when divergence forces smaller batches.
Authors: The definitional extension is direct: Koza's effort is the expected number of evaluations to a high-probability solution; we substitute gradient-descent steps for evaluations. We do not claim the count is invariant to per-step cost. In the revised manuscript we will add a short analysis confirming that, in the reported experiments, batch size remained constant and large learning rates did not trigger divergence requiring batch reduction, so step counts are directly comparable. We will also note that any future extension to variable-batch regimes could weight steps by relative FLOPs. revision: partial
Circularity Check
Minimizing explicitly defined effort metric claimed as novel AutoML by construction
specific steps
-
self definitional
[Abstract]
"Furthermore, we demonstrate that minimising this effort acts as a novel form of Automatic Machine Learning (AutoML)."
Once computational effort is defined as the quantity whose minimization constitutes good performance, the claim that minimizing it is a novel AutoML follows tautologically from the definition itself; the 'demonstration' requires no independent argument or evidence beyond the introduction of the metric.
full rationale
The paper's central proposal is the redefinition of performance as the expected number of GD steps to a target accuracy (with high probability), explicitly extending Koza's GP metric. The assertion that 'minimising this effort acts as a novel form of Automatic Machine Learning (AutoML)' follows directly from that definition without further derivation or external validation. All reported empirical findings (large-LR preference, phase transitions, model selection) are downstream applications of the new metric to experiments on 11 models and 5 datasets and do not reduce to the definition. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. This yields one minor self-definitional step that is not load-bearing for the experimental results, producing a low but non-zero circularity score.
Axiom & Free-Parameter Ledger
free parameters (2)
- acceptable accuracy level
- high probability threshold
axioms (1)
- domain assumption Number of gradient descent steps is a valid and comparable measure of computational effort across different ML models
Reference graph
Works this paper leans on
-
[1]
Robert J. N. Baldock, Hartmut Maennel, and Behnam Neyshabur. Deep learning through the lens of example difficulty.arXiv preprint arXiv:2106.09647,
-
[2]
David F Barrero, Mar´ ıa D R-Moreno, Bonifacio Casta˜ no, and David Camacho
URLhttps: //doi.org/10.48550/arxiv.2106.09647. David F Barrero, Mar´ ıa D R-Moreno, Bonifacio Casta˜ no, and David Camacho. An empirical study on the accuracy of computational effort in genetic programming. In2011 IEEE Congress on Evolutionary Computation (CEC), pages 1164–1171. IEEE,
-
[3]
We need to talk about random seeds.arXiv preprint arXiv:2210.13393,
Steven Bethard. We need to talk about random seeds.arXiv preprint arXiv:2210.13393,
-
[4]
P. Calle, A. Bates, J. C. Reynolds, Y. Liu, H. Cui, S. Ly, C. Wang, Q. Zhang, A. J. de Armendi, S. S. Shettar, K. M. Fung, Q. Tang, and C. Pan. Integration of nested cross-validation, automated hyperparameter optimization, high-performance computing to reduce and quantify the variance of test performance estimation of deep learning models.arXiv preprint a...
-
[5]
URLhttps://doi.org/10.1016/j. cmpb.2025.109063. Tom Castle and Colin G Johnson. Evolving high-level imperative program trees with strongly formed genetic programming. InEuropean Conference on Genetic Programming, pages 1–12. Springer,
work page doi:10.1016/j 2025
-
[6]
An analysis of koza’s computational effort statistic for genetic programming
Steffen Christensen and Franz Oppacher. An analysis of koza’s computational effort statistic for genetic programming. InGenetic Programming: 5th European Conference, EuroGP 2002 Kinsale, Ireland, April 3–5, 2002 Proceedings 5, pages 182–191. Springer,
2002
-
[7]
Leakage and the reproducibility crisis in ml-based science.arXiv preprint arXiv:2207.07048,
Sayash Kapoor and Arvind Narayanan. Leakage and the reproducibility crisis in ml-based science.arXiv preprint arXiv:2207.07048,
-
[8]
Andrey N
Ac- cessed: 2026-04-21. Andrey N. Kolmogorov. Three approaches to the quantitative definition of information. Problems of Information Transmission, 1(1):1–7,
2026
-
[9]
Aitor Lewkowycz, Yasaman Bahri, Ethan Dyer, Jascha Sohl-Dickstein, and Guy Gur-Ari. The large learning rate phase of deep learning: the catapult mechanism.arXiv preprint arXiv:2003.02218,
arXiv 2003
-
[10]
Moslem Noori, Elisabetta Valiante, Ignacio Rozada, Thomas Van Vaerenbergh, and Ma- soud Mohseni. A statistical analysis for per-instance evaluation of stochastic optimizers: Avoiding unreliable conclusions.arXiv preprint arXiv:2503.16589v2,
-
[12]
Liah Rosenfeld and Leonardo Vanneschi
URL https://arxiv.org/abs/2601.17655. Liah Rosenfeld and Leonardo Vanneschi. A survey on batch training in genetic program- ming.Genetic Programming and Evolvable Machines, 26(1):2,
-
[13]
An overview of gradient descent optimization algorithms.arXiv preprint arXiv:1609.04747,
Sebastian Ruder. An overview of gradient descent optimization algorithms.arXiv preprint arXiv:1609.04747,
-
[14]
Leslie N Smith. A disciplined approach to neural network hyper-parameters: Part 1–learning rate, batch size, momentum, and weight decay.arXiv preprint arXiv:1803.09820,
-
[15]
Samuel L Smith, Benoit Dherin, David GT Barrett, and Soham De. On the origin of implicit regularization in stochastic gradient descent.arXiv preprint arXiv:2101.12176,
-
[16]
doi: https://doi.org/10.1016/j.neunet.2022.05.030
ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2022.05.030. URLhttps://www.sciencedirect.com/ science/article/pii/S0893608022002040. 54 Supplementary Material Appendix S1. Test Problems and Degree of Overparametrisation TheIris,Wine, andBCWdatasets were sourced from the Scikit-learn library (Pedregosa et al., 2011), whileE-coliandDNAwere obtained f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.