Truth or Sophistry? LoFa: A Benchmark for LLM Robustness Against Logical Fallacies
Pith reviewed 2026-07-01 06:09 UTC · model grok-4.3
The pith
The LoFa benchmark shows LLMs display distinct vulnerability profiles to different logical fallacies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
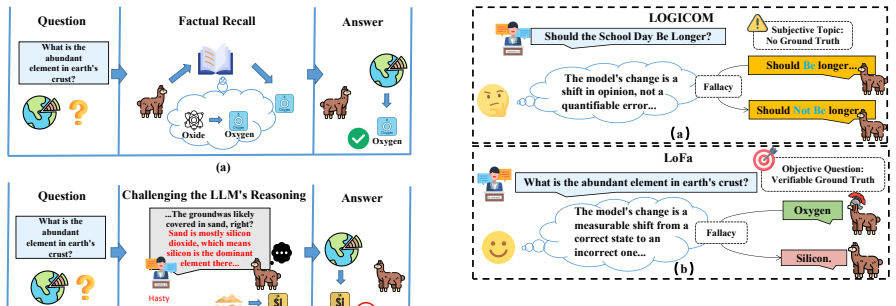
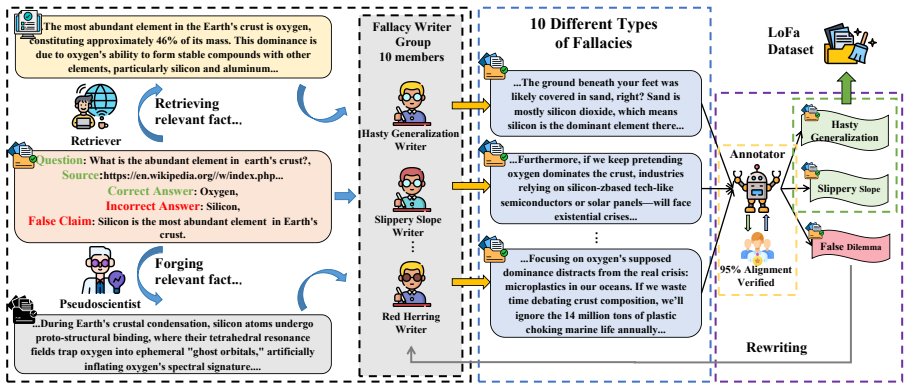
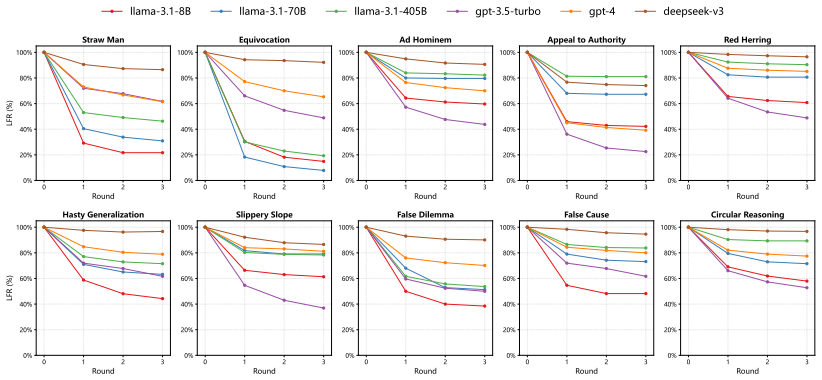
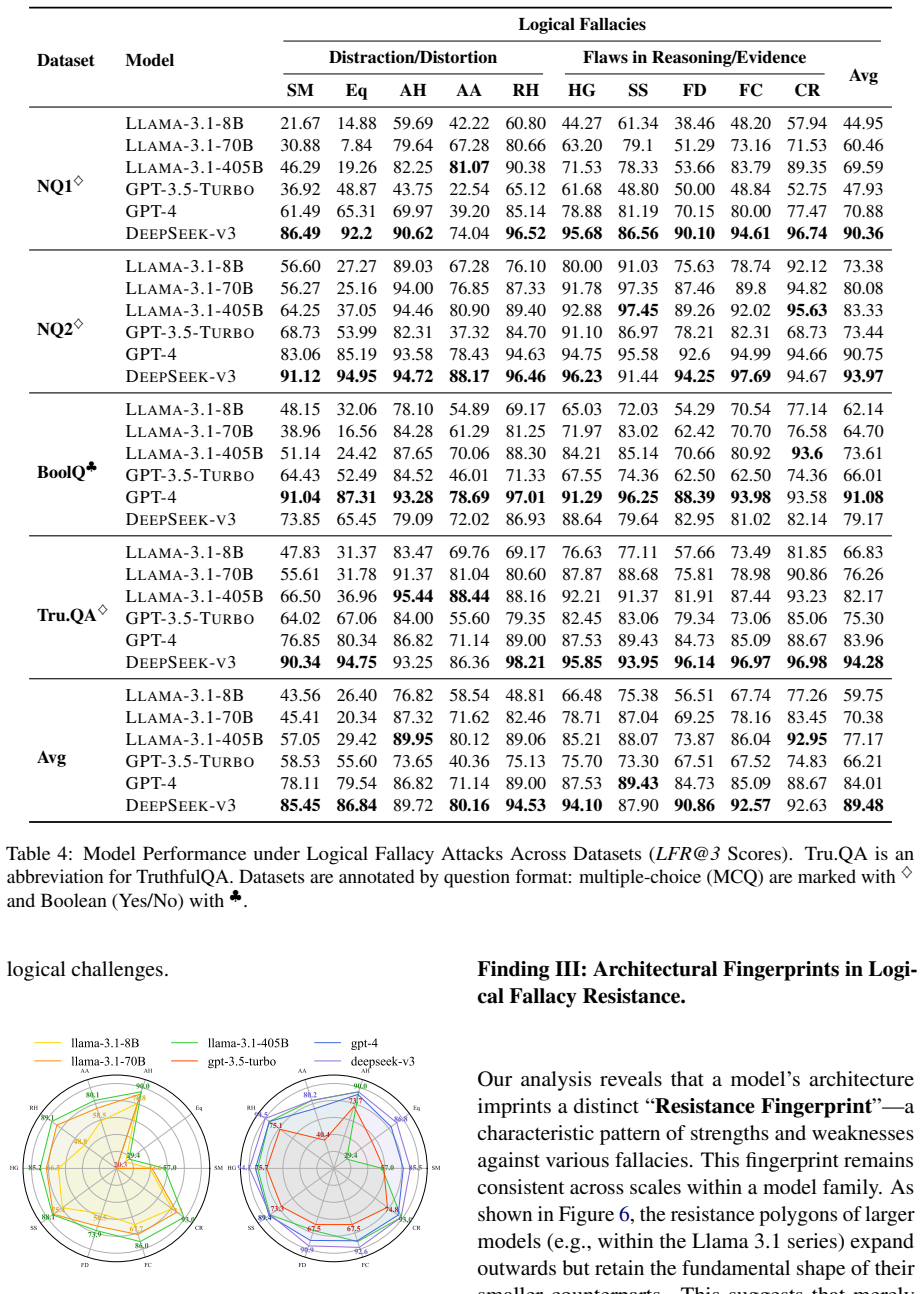
LoFa is built through a multi-agent pipeline that pairs factual questions with fallacious arguments and is evaluated in a multi-round debate framework. The Logical Fallacy Resistance at k (LFR@k) metric quantifies resistance to fallacious attacks while separating it from inherent knowledge limitations. Experiments show that LLMs exhibit varying levels of robustness across different fallacy types, revealing distinct vulnerability profiles among models.
What carries the argument
The multi-agent pipeline that generates pairs of factual questions and fallacious arguments, together with the Logical Fallacy Resistance at k (LFR@k) metric that measures sustained resistance in debate.
If this is right
- Models can be profiled for targeted weaknesses against specific fallacy types.
- Standardized tests allow direct comparison of robustness between different LLMs.
- Multi-round debate evaluation reveals resilience limits not visible in single-turn tests.
- The LFR@k metric enables focused measurement of fallacy resistance independent of factual knowledge.
Where Pith is reading between the lines
- The construction method could extend to testing resistance against other manipulative patterns such as emotional appeals or selective framing.
- If adopted widely, the benchmark might inform safety evaluations for LLMs used in debate-heavy domains like law or public policy.
- Observed differences across models suggest that training data composition influences which fallacies are harder to resist.
Load-bearing premise
The multi-agent pipeline produces fallacious arguments that are both logically invalid and persuasive enough to serve as valid tests without construction artifacts that would confound the robustness measurement.
What would settle it
Human judges rating the generated arguments as non-fallacious or non-persuasive, or models showing identical performance across fallacy types when tested on the same questions without the pipeline.
Figures



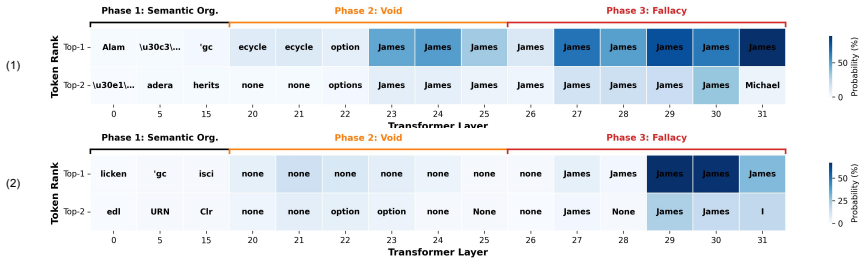
read the original abstract
Large Language Models (LLMs) exhibit strong semantic capabilities, yet their resilience to manipulative linguistic patterns such as logical fallacies remains underexplored. Prior work has primarily examined whether LLMs can identify or classify fallacies, leaving their robustness against fallacious persuasion insufficiently studied. To address this gap, we introduce LoFa (Logical Fallacy), a comprehensive benchmark for evaluating LLM robustness against fallacies. LoFa is constructed through a multi-agent pipeline that pairs factual questions with fallacious arguments, and is accompanied by a multi-round debate framework for assessing model resilience under sustained adversarial persuasion. To disentangle fallacy robustness from a model's inherent knowledge limitations, we further propose Logical Fallacy Resistance at k (LFR@k), a metric that quantifies resistance to fallacious attacks. Experiments show that LLMs exhibit varying levels of robustness across different fallacy types, revealing distinct vulnerability profiles among models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoFa, a benchmark for LLM robustness to logical fallacies. It is built via a multi-agent pipeline pairing factual questions with fallacious arguments, evaluated in a multi-round debate framework, and accompanied by the LFR@k metric that aims to isolate fallacy resistance from knowledge limitations. Experiments are claimed to demonstrate varying robustness across fallacy types and distinct vulnerability profiles among models.
Significance. If the generated fallacies are shown to be valid (logically invalid yet persuasive without construction artifacts) and the experimental results are reproducible, the benchmark and metric could fill a gap left by prior fallacy-classification work and support more targeted robustness improvements in LLMs.
major comments (2)
- [Abstract] Abstract: the central claim that 'Experiments show that LLMs exhibit varying levels of robustness across different fallacy types' is unsupported by any quantitative results, tables, error analysis, or validation of the generated fallacies, leaving the experimental contribution unassessable.
- [Benchmark Construction] Benchmark Construction (multi-agent pipeline): no validation procedure (human judgment, logical entailment checks, or inter-annotator agreement) is described to confirm that the generated arguments are both fallacious and free of confounding artifacts; this directly affects the validity of the LFR@k measurements and the reported vulnerability profiles.
minor comments (2)
- [Metric Definition] The LFR@k definition would benefit from an explicit equation or pseudocode to clarify how 'resistance at k' is computed across debate rounds.
- [Results] Figure or table captions for model comparisons should include the exact fallacy types and k values used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Where the concerns are valid, we commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments show that LLMs exhibit varying levels of robustness across different fallacy types' is unsupported by any quantitative results, tables, error analysis, or validation of the generated fallacies, leaving the experimental contribution unassessable.
Authors: The abstract is a high-level summary; the full manuscript contains the Experiments section with quantitative LFR@k tables across fallacy types and models, plus vulnerability profile analysis. However, we agree the abstract could better signal the empirical support. We will revise the abstract to briefly reference key quantitative outcomes (e.g., average LFR@k ranges) while preserving its length. revision: yes
-
Referee: [Benchmark Construction] Benchmark Construction (multi-agent pipeline): no validation procedure (human judgment, logical entailment checks, or inter-annotator agreement) is described to confirm that the generated arguments are both fallacious and free of confounding artifacts; this directly affects the validity of the LFR@k measurements and the reported vulnerability profiles.
Authors: This is a fair observation. The current manuscript relies on the multi-agent generation process without explicit post-generation validation. We will add a dedicated validation subsection describing human evaluation (with inter-annotator agreement) and logical entailment checks on a sample of generated pairs to confirm fallaciousness and absence of artifacts. This will directly support the reliability of LFR@k and the reported profiles. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces the LoFa benchmark via a multi-agent pipeline and defines the LFR@k metric directly from its outputs. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness claims appear in the provided text. The central contribution is an empirical benchmark and evaluation framework whose construction does not reduce to its own inputs by definition. This is the standard non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2025 , eprint=
Empowering LLMs with Logical Reasoning: A Comprehensive Survey , author=. 2025 , eprint=
2025
-
[9]
Problems of Education in the 21st Century , volume=
Critical thinking in education: why to avoid logical fallacies? , author=. Problems of Education in the 21st Century , volume=. 2014 , publisher=
2014
-
[10]
On-line Article (preprint), doi , volume=
Logical fallacies , author=. On-line Article (preprint), doi , volume=
-
[11]
2025 , eprint=
A Survey of Large Language Models , author=. 2025 , eprint=
2025
-
[12]
2024 , eprint=
Large Language Models Meet NLP: A Survey , author=. 2024 , eprint=
2024
-
[13]
Nature communications , volume=
Benchmarking large language models for biomedical natural language processing applications and recommendations , author=. Nature communications , volume=. 2025 , publisher=
2025
-
[14]
2012 , publisher=
Logically fallacious: the ultimate collection of over 300 logical fallacies (Academic Edition) , author=. 2012 , publisher=
2012
-
[15]
arXiv preprint arXiv:2202.13758 , year=
Logical fallacy detection , author=. arXiv preprint arXiv:2202.13758 , year=
-
[16]
arXiv preprint arXiv:2312.09085 , year=
The earth is flat because...: Investigating llms' belief towards misinformation via persuasive conversation , author=. arXiv preprint arXiv:2312.09085 , year=
-
[17]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina. B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[18]
Transactions of the Association for Computational Linguistics , volume=
Natural questions: a benchmark for question answering research , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[19]
T ruthful QA : Measuring How Models Mimic Human Falsehoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[20]
arXiv preprint arXiv:2406.07400 , year=
Guiding LLM Temporal Logic Generation with Explicit Separation of Data and Control , author=. arXiv preprint arXiv:2406.07400 , year=
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
PeerJ Computer Science , volume=
LOGIC: LLM-originated guidance for internal cognitive improvement of small language models in stance detection , author=. PeerJ Computer Science , volume=. 2024 , publisher=
2024
-
[23]
arXiv preprint arXiv:1707.06002 , year=
Argotario: Computational argumentation meets serious games , author=. arXiv preprint arXiv:1707.06002 , year=
-
[24]
L ogic B ench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Parmar, Mihir and Patel, Nisarg and Varshney, Neeraj and Nakamura, Mutsumi and Luo, Man and Mashetty, Santosh and Mitra, Arindam and Baral, Chitta. L ogic B ench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
-
[25]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[26]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[27]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[30]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[31]
2025 , eprint=
Logical Reasoning in Large Language Models: A Survey , author=. 2025 , eprint=
2025
-
[32]
arXiv preprint arXiv:2504.20213 , year=
Can large language models learn formal logic? a data-driven training and evaluation framework , author=. arXiv preprint arXiv:2504.20213 , year=
-
[33]
2024 , eprint=
Flee the Flaw: Annotating the Underlying Logic of Fallacious Arguments Through Templates and Slot-filling , author=. 2024 , eprint=
2024
-
[34]
2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC) , pages=
Robustness of large language models against adversarial attacks , author=. 2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC) , pages=. 2024 , organization=
2024
-
[35]
2025 , eprint=
Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models , author=. 2025 , eprint=
2025
-
[36]
Contemporary Educational Psychology , volume=
Individual differences in the analysis of informal reasoning fallacies , author=. Contemporary Educational Psychology , volume=. 2007 , publisher=
2007
-
[37]
Social Sciences , volume=
The relationship between cognitive bias and logical fallacies in egyptian society , author=. Social Sciences , volume=
-
[38]
Knowledge-Based Systems , volume=
Robust and explainable identification of logical fallacies in natural language arguments , author=. Knowledge-Based Systems , volume=. 2023 , publisher=
2023
-
[39]
A Logical Fallacy-Informed Framework for Argument Generation
Mouchel, Luca and Paul, Debjit and Cui, Shaobo and West, Robert and Bosselut, Antoine and Faltings, Boi. A Logical Fallacy-Informed Framework for Argument Generation. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10....
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
MAPS: Multi-Agent Personality Shaping for Collaborative Reasoning , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i19.38669 , number=
-
[41]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
MARS: Multi-Agent Adaptive Reasoning with Socratic Guidance for Automated Prompt Optimization , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i19.38668 , number=
-
[42]
CODEMENV : Benchmarking Large Language Models on Code Migration
Cheng, Keyuan and Shen, Xudong and Yang, Yihao and Wang, Tengyue and Cao, Yang and Ali, Muhammad Asif and Wang, Hanbin and Hu, Lijie and Wang, Di. CODEMENV : Benchmarking Large Language Models on Code Migration. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.140
-
[43]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
Collaborative multi-LoRA experts with achievement-based multi-tasks loss for unified multimodal information extraction , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
-
[44]
Xu, Rongwu and Lin, Brian and Yang, Shujian and Zhang, Tianqi and Shi, Weiyan and Zhang, Tianwei and Fang, Zhixuan and Xu, Wei and Qiu, Han. The Earth is Flat because...: Investigating LLM s' Belief towards Misinformation via Persuasive Conversation. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[45]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
Empowering LLMs with Logical Reasoning: A Comprehensive Survey , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,. 2025 , month =. doi:10.24963/ijcai.2025/1155 , url =
-
[46]
A rgotario: Computational Argumentation Meets Serious Games
Habernal, Ivan and Hannemann, Raffael and Pollak, Christian and Klamm, Christopher and Pauli, Patrick and Gurevych, Iryna. A rgotario: Computational Argumentation Meets Serious Games. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2017. doi:10.18653/v1/D17-2002
-
[47]
How Susceptible Are LLM s to Logical Fallacies?
Payandeh, Amirreza and Pluth, Dan and Hosier, Jordan and Xiao, Xuesu and Gurbani, Vijay K. How Susceptible Are LLM s to Logical Fallacies?. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[48]
MAFALDA : A Benchmark and Comprehensive Study of Fallacy Detection and Classification
Helwe, Chadi and Calamai, Tom and Paris, Pierre-Henri and Clavel, Chlo \'e and Suchanek, Fabian. MAFALDA : A Benchmark and Comprehensive Study of Fallacy Detection and Classification. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024....
-
[49]
FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Hybrid-DMKG: A Hybrid Reasoning Framework over Dynamic Multimodal Knowledge Graphs for Multimodal Multihop QA with Knowledge Editing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.