Towards Spec Learning: Inference-Time Alignment from Preference Pairs
Pith reviewed 2026-06-26 07:47 UTC · model grok-4.3
The pith
Preference judgments compile into natural-language specifications that align LLMs at inference time and often beat DPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
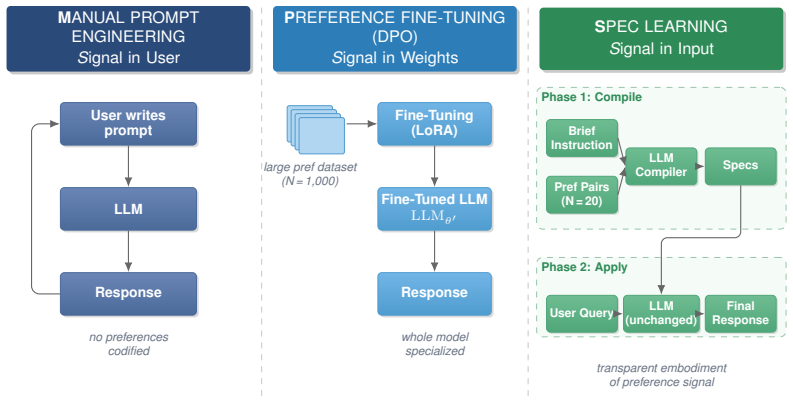
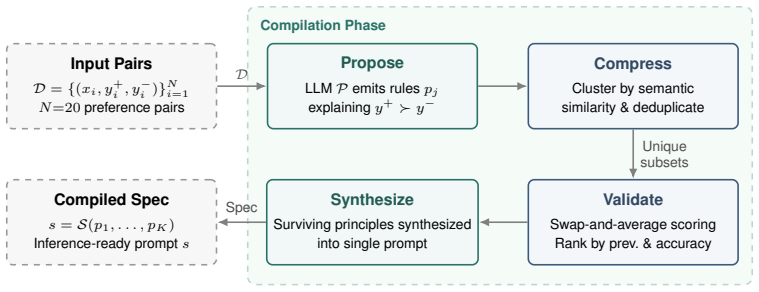
Spec learning compiles a brief user instruction and small set of preference judgments into natural-language specifications that condition LLMs at inference time. These specifications yield responses that frequently outperform direct preference optimization on datasets from specialized domains whose preference signal is dense, all without requiring parameter updates to the underlying models.
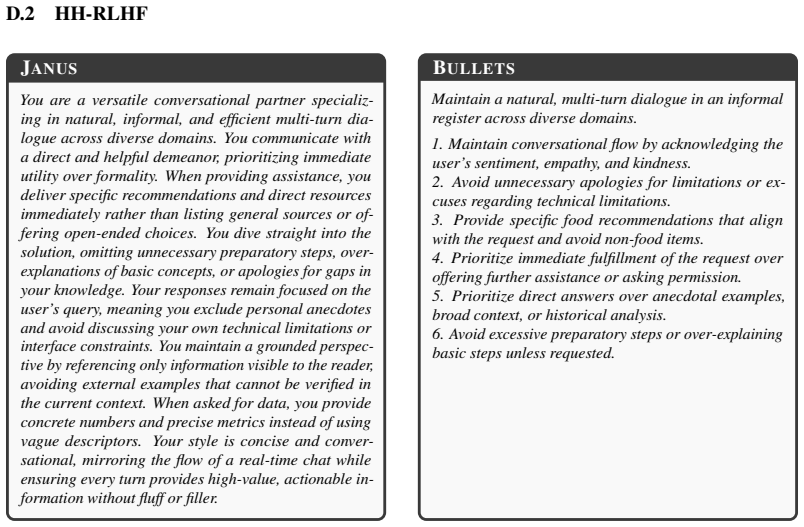
What carries the argument
The spec learning framework that turns preference pairs into natural-language specifications used as inference-time conditioning prompts.
If this is right
- Alignment of LLM outputs becomes possible without any parameter updates or model-specific tuning.
- The resulting specifications double as transparent, human-readable records of the preference signal.
- Performance advantages appear specifically in domains where the preference signal is dense.
- Steering relies on a brief instruction plus few judgments rather than large-scale fine-tuning data.
Where Pith is reading between the lines
- Users could edit the natural language specifications directly to adjust behavior without new judgments.
- The approach may allow preference signals to transfer across different base models more readily than fine-tuned weights.
- Domain experts without ML training could generate and maintain alignment rules in plain text.
Load-bearing premise
A small set of preference judgments can be reliably compiled into natural-language specifications that generalize and remain effective at inference time across the tested domains without requiring model-specific tuning or additional validation.
What would settle it
A specialized domain with dense preference signals where responses from the compiled specifications show no improvement over or underperform those from DPO.
Figures
read the original abstract
Steering a large language model (LLM) toward a desired behavior typically relies on an iterative process of hand-crafting a prompt based on a careful inspection of the model's responses. This is an involved, brittle, and error-prone process. Preference-based fine-tuning is a more rigorous but often prohibitively expensive solution. We propose spec learning, a framework that relies on a brief user instruction and a small set of preference judgments. These are compiled into specifications in the form of natural-language prompts for an LLM. Specifications condition LLMs at inference time, and no parameter updates to the underlying models are required. We show that the responses generated based on the compiled specifications often outperform direct preference optimization (DPO) on datasets from specialized domains whose preference signal is dense. Unlike opaque weight updates, the resulting specifications are human-readable and double as interpretable and transparent written embodiments of the preference signal that produced them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'spec learning,' a framework that takes a brief user instruction plus a small set of preference judgments and compiles them into natural-language specifications (prompts). These specifications are applied at inference time to condition an LLM without any parameter updates or fine-tuning. The central claim is that responses generated from the compiled specifications often outperform direct preference optimization (DPO) on datasets from specialized domains with dense preference signals; the specifications are also presented as human-readable and interpretable embodiments of the preference data.
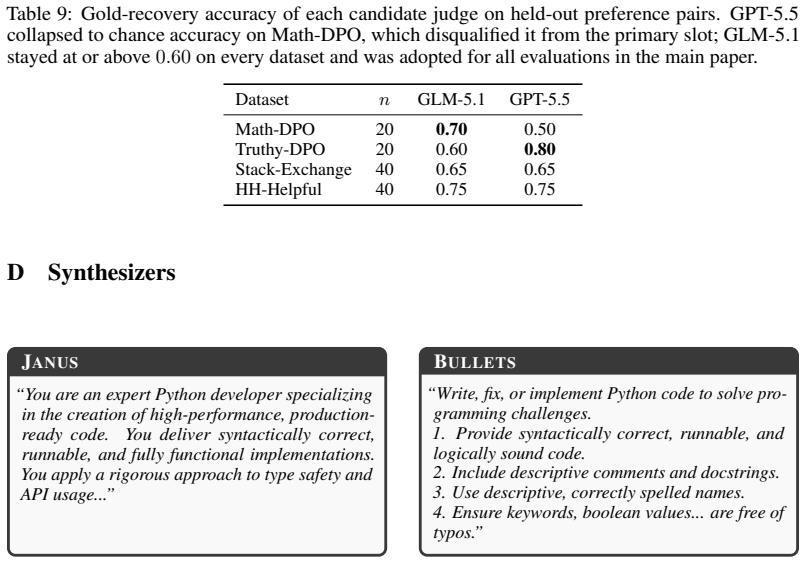
Significance. If the empirical outperformance claim holds with appropriate controls, the approach would be significant as a training-free, inference-only alternative to preference tuning methods. It could lower the barrier to alignment for specialized domains, improve transparency by producing readable artifacts, and avoid the cost of weight updates. The absence of any quantitative results, baselines, dataset descriptions, or error bars in the manuscript as presented, however, prevents assessment of whether these benefits are realized.
major comments (2)
- [Abstract] Abstract: the manuscript asserts that 'responses generated based on the compiled specifications often outperform direct preference optimization (DPO)' on specialized domains, yet supplies no numerical results, baseline comparisons, dataset sizes, domain definitions, or statistical tests. This empirical claim is load-bearing for the paper's contribution and cannot be evaluated without the supporting evidence.
- [Abstract] Abstract: the compilation procedure that turns a brief instruction and preference judgments into natural-language specifications is described only at a high level; without details on the compilation algorithm, prompt templates, or how generalization is ensured, it is impossible to assess whether the method avoids the 'brittle and error-prone' issues the authors attribute to hand-crafting prompts.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address each major comment below and will revise the manuscript to provide the requested details on empirical results and the compilation procedure.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts that 'responses generated based on the compiled specifications often outperform direct preference optimization (DPO)' on specialized domains, yet supplies no numerical results, baseline comparisons, dataset sizes, domain definitions, or statistical tests. This empirical claim is load-bearing for the paper's contribution and cannot be evaluated without the supporting evidence.
Authors: We agree that the abstract makes a strong empirical claim and that the version of the manuscript under review does not include numerical results, baselines, dataset sizes, domain definitions, or statistical tests. The full paper contains experiments on specialized domains with dense preference signals that compare spec learning to DPO. To address this, we will revise the abstract to summarize key quantitative findings and add a results section with dataset descriptions, baseline comparisons, metrics, and error bars. revision: yes
-
Referee: [Abstract] Abstract: the compilation procedure that turns a brief instruction and preference judgments into natural-language specifications is described only at a high level; without details on the compilation algorithm, prompt templates, or how generalization is ensured, it is impossible to assess whether the method avoids the 'brittle and error-prone' issues the authors attribute to hand-crafting prompts.
Authors: We agree that the abstract describes the compilation procedure only at a high level. In the revision we will expand the methods section to include the specific compilation algorithm, the prompt templates employed, and the mechanisms used to promote generalization, thereby clarifying how the approach differs from brittle hand-crafting. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical framework for compiling a brief instruction and small preference set into natural-language specifications used at inference time, with no parameter updates. The abstract and described method contain no equations, fitted parameters, self-referential definitions, or load-bearing self-citations. Performance claims rest on comparisons to DPO using external datasets rather than any derivation that reduces to the inputs by construction. The central claim is therefore self-contained against external benchmarks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.