Rethinking Foundation Model Collaboration: Enhancing Specialized Models through Proxy Task Reasoning
Pith reviewed 2026-07-01 06:36 UTC · model grok-4.3
The pith
Foundation models enhance specialized vision models by performing proxy selection or verification on reconstructed hypotheses rather than direct structured prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
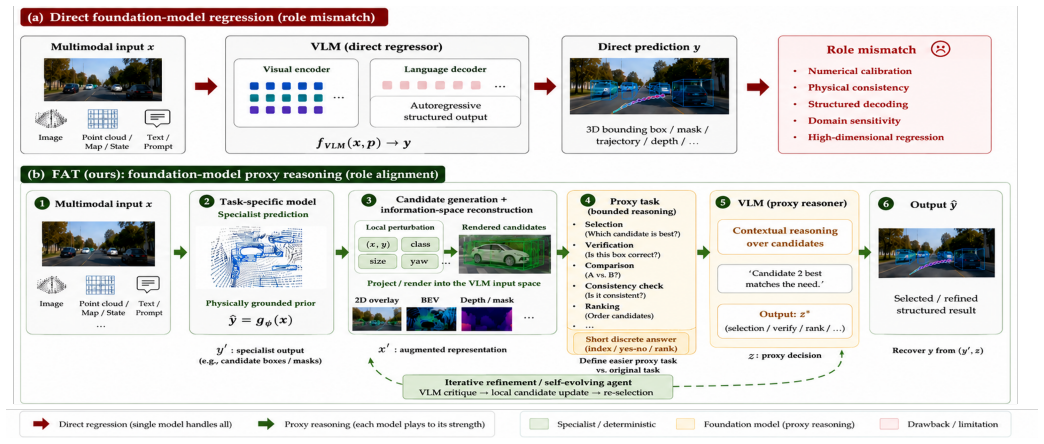
FAT decomposes structured prediction into specialist prediction of geometrically and physically valid hypotheses, information-space reconstruction that produces multimodal candidates, and foundation-model proxy reasoning such as selection or verification. The ProxySelect instantiation demonstrates that this decomposition improves specialized baselines across four vision tasks and substantially outperforms direct foundation-model regression while using less compute, supporting the principle that specialized models keep task-specific structure and foundation models refine it through contextual proxy reasoning.
What carries the argument
ProxySelect, the instantiation of FAT in which a vision-language model executes a bounded proxy task of selection or verification over multimodal candidates reconstructed from specialist outputs.
Load-bearing premise
The information-space reconstruction step yields multimodal candidates on which the foundation model's bounded proxy task stays effective and does not introduce errors that outweigh the specialist's initial hypotheses.
What would settle it
Running ProxySelect on any of the four evaluated tasks and observing no accuracy gain or higher error than the pure specialist baseline would falsify the claim that the proxy-reasoning collaboration improves performance.
Figures
read the original abstract
Foundation models are increasingly integrated into embodied intelligence systems, but directly assigning them structured prediction tasks requires precise geometric and numerical estimation, where specialized models often remain stronger. This capability mismatch raises a key question: should foundation models replace task-specific predictors, or should they collaborate through tasks better aligned with their strengths? We propose FAT, a foundation-model-augmented task-specific reasoning framework that treats collaboration as task decomposition rather than model replacement. FAT decomposes structured prediction into specialist prediction, information-space reconstruction, and foundation-model proxy reasoning. The specialist generates geometrically and physically valid hypotheses in the native output space, while the foundation model performs a bounded proxy task, such as selection or verification, over reconstructed multimodal candidates. We instantiate this principle as ProxySelect with a vision--language model. Across 2D object detection, 3D object detection, trajectory prediction, and semantic segmentation, ProxySelect consistently improves specialized baselines and substantially outperforms direct foundation-model regression at lower computational cost. These results suggest a general collaboration principle: specialized models preserve task-specific structure, while foundation models refine their hypotheses through contextual proxy reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the FAT framework for foundation-model collaboration with specialized models on structured prediction tasks. It decomposes the problem into specialist hypothesis generation in native output space, information-space reconstruction to produce multimodal candidates, and a bounded proxy task (selection or verification) performed by a foundation model. The ProxySelect instantiation is evaluated on 2D object detection, 3D object detection, trajectory prediction, and semantic segmentation, with the claim that it consistently improves specialized baselines while outperforming direct foundation-model regression at lower computational cost.
Significance. If the empirical results and the reconstruction step hold, the work supplies concrete evidence for a task-decomposition collaboration principle that exploits the respective strengths of specialists (geometric/physical validity) and foundation models (contextual reasoning), rather than model replacement. The multi-task scope is a strength. However, the central claim cannot be assessed without verification that reconstruction preserves sufficient fidelity and diversity.
major comments (2)
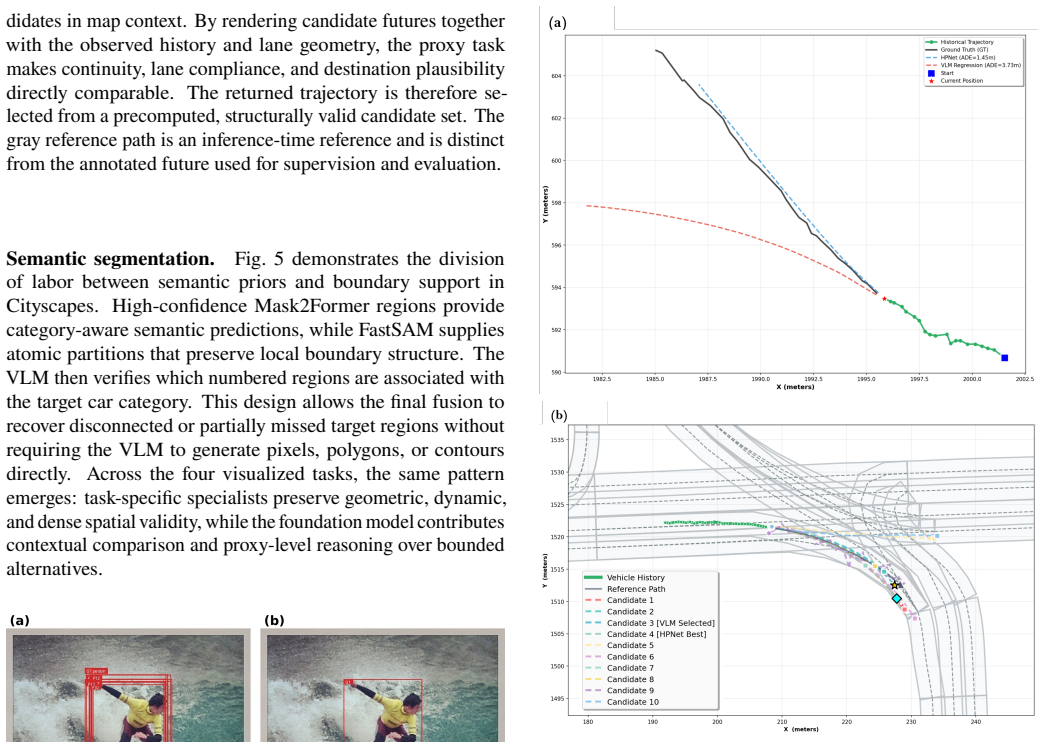
- [Abstract / method description] Abstract and method description: the claim that ProxySelect improves upon specialists requires that the information-space reconstruction step produces multimodal candidates on which the foundation model's bounded proxy task remains effective. No quantitative check (e.g., reconstruction error versus specialist residual error, mode-collapse metrics, or ablation removing the reconstruction stage) is supplied to confirm this assumption does not introduce new errors that outweigh the gains.
- [Abstract] Abstract: performance claims are stated without implementation details, error bars, dataset splits, ablation tables, or statistical significance tests, so the reported improvements across the four tasks cannot be verified from the manuscript text.
minor comments (1)
- The expansion of the acronym FAT is given only in the abstract; a dedicated section or footnote would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method description: the claim that ProxySelect improves upon specialists requires that the information-space reconstruction step produces multimodal candidates on which the foundation model's bounded proxy task remains effective. No quantitative check (e.g., reconstruction error versus specialist residual error, mode-collapse metrics, or ablation removing the reconstruction stage) is supplied to confirm this assumption does not introduce new errors that outweigh the gains.
Authors: We agree that quantitative validation of the reconstruction step is valuable for supporting the core claim. The manuscript provides qualitative examples of multimodal candidate generation, but we will add a dedicated ablation subsection that reports reconstruction fidelity metrics (e.g., error relative to specialist residuals), mode diversity statistics, and performance with the reconstruction stage removed. This will confirm that the step enhances rather than degrades the proxy task effectiveness. revision: yes
-
Referee: [Abstract] Abstract: performance claims are stated without implementation details, error bars, dataset splits, ablation tables, or statistical significance tests, so the reported improvements across the four tasks cannot be verified from the manuscript text.
Authors: The abstract is intentionally concise; full details including dataset splits, error bars, ablation tables, and significance tests appear in Sections 4–5 and Tables 1–4 of the main text. To improve accessibility, we will expand the abstract with a short clause referencing the evaluation protocol and point readers to the detailed results. The claims remain verifiable from the complete manuscript. revision: partial
Circularity Check
No circularity: empirical framework with externally validated gains
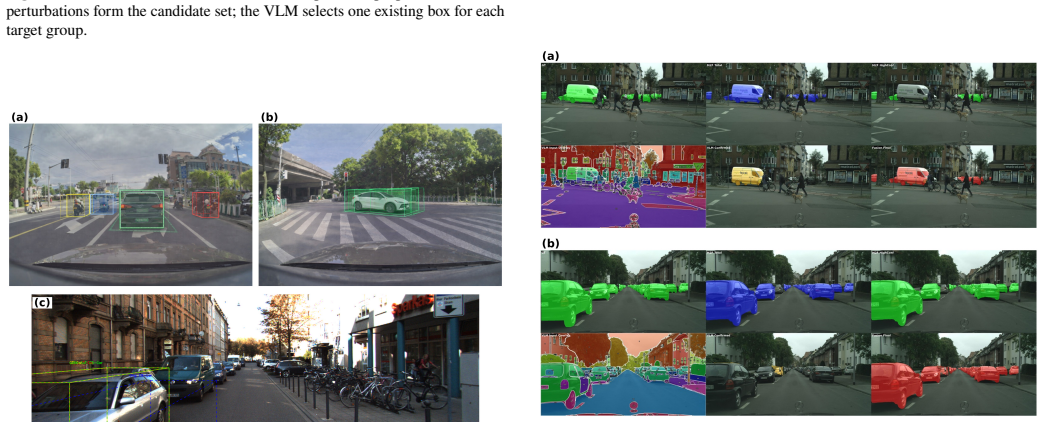
full rationale
The paper describes an empirical collaboration framework (FAT/ProxySelect) that decomposes structured prediction into specialist hypotheses, information-space reconstruction, and bounded FM proxy tasks (selection/verification). Performance gains are reported across four tasks via direct comparison to baselines and direct FM regression, with no equations, fitted parameters renamed as predictions, or self-citation chains invoked to justify the decomposition. The central claims rest on experimental outcomes rather than any derivation that reduces to its own inputs by construction; the method is presented as a testable principle without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Specialized models remain stronger than foundation models at precise geometric and numerical estimation.
- domain assumption Foundation models can reliably execute bounded proxy tasks such as selection or verification once candidates are reconstructed.
Reference graph
Works this paper leans on
-
[1]
Envisioning the Future of Transportation: Inspiration of ChatGPT and Large Models
X. Qu, H. Lin, and Y. Liu. “Envisioning the Future of Transportation: Inspiration of ChatGPT and Large Models”. In:Communications in TransportationResearch3(2023),p.100103.doi: 10.1016/j.commtr. 2023.100103
-
[2]
S.Kuang,Y.Liu,X.Wang,X.Wu,andY.Wei.“HarnessingMultimodal Large Language Models for Traffic Knowledge Graph Generation and Decision-Making”. In:Communications in Transportation Research4.4 (2024), p. 100146.doi:10.1016/j.commtr.2024.100146
-
[3]
Multimodal Large-Language Model Empowering Next-Generation Autonomous Driving Systems
Z. Hu, M. Xu, and Q. Cheng. “Multimodal Large-Language Model Empowering Next-Generation Autonomous Driving Systems”. In:Jour- nal of Intelligent and Connected Vehicles8.2 (2025), p. 9210059.doi: 10.26599/JICV.2025.9210059
-
[4]
Vision language models in autonomous driving: A survey and outlook
X.Zhou,M.Liu,E.Yurtsever,B.L.Zagar,W.Zimmer,H.Cao,andA.C. Knoll. “Vision language models in autonomous driving: A survey and outlook”. In:IEEE Transactions on Intelligent Vehicles(2024), pp. 1–20. doi:10.1109/TIV.2024.3402136
-
[5]
DriveVLM: The convergence of autonomous driving and largevision–languagemodels
X. Tian, J. Gu, B. Li, Y. Liu, Y. Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao. “DriveVLM: The convergence of autonomous driving and largevision–languagemodels”.In:Proceedingsofthe8thConferenceon Robot Learning. Vol. 270. Proceedings of Machine Learning Research. PMLR, 2025, pp. 4698–4726
2025
-
[6]
Embodied large language models enable robots to complete complex tasks in unpredictable environments
R. Mon-Williams, G. Li, R. Long, W. Du, and C. G. Lucas. “Embodied large language models enable robots to complete complex tasks in unpredictable environments”. In:Nature Machine Intelligence7 (2025), pp. 592–601.doi:10.1038/s42256-025-01005-x
- [7]
-
[8]
VLM-AD:End-to-endautonomousdriving through vision–language model supervision
Y. Xu, Y. Hu, Z. Zhang, G. P. Meyer, S. K. Mustikovela, S. Srinivasa, E.M.Wolff,andX.Huang.“VLM-AD:End-to-endautonomousdriving through vision–language model supervision”. In:Proceedings of the 9th Conference on Robot Learning. Vol. 305. Proceedings of Machine Learning Research. PMLR, 2025, pp. 3778–3803
2025
-
[9]
H. Lin, S. Ming, Y. Liu, and X. Qu. “AEFusion: An Attention-Based EnsembleLearningApproachforBEVFusionPerceptioninAutonomous Modular Buses”. In:IEEE Transactions on Intelligent Vehicles10.5 (2025), pp. 3468–3480.doi:10.1109/TIV.2024.3454288
-
[10]
H. Lin, Y. Liu, L. Wang, and X. Qu. “A High-Precision Calibration and Evaluation Method Based on Binocular Cameras and LiDAR for Intelligent Vehicles”. In:IEEE Transactions on Vehicular Technology 74.5 (2025), pp. 7404–7415.doi:10.1109/TVT.2025.3530479
-
[11]
Few- Shot Learning for Novel Object Detection in Autonomous Driving
Y. Zhuang, P. Liu, H. Yang, K. Zhang, Y. Wang, and Z. Pu. “Few- Shot Learning for Novel Object Detection in Autonomous Driving”. In: Communications in Transportation Research5.3 (2025), p. 100194.doi: 10.1016/j.commtr.2025.100194
-
[12]
Use of cumulants to quantify uncertainties in the HBT measurements of the homogeneity regions
P.Liu,H.Lin,Y.Zhao,Y.Liu,andX.Qu.“DesEAD:EnhancingEnd-to- EndAutonomousDrivingwithSceneDescriptions”.In:2025IEEE28th International Conference on Intelligent Transportation Systems. 2025, pp. 2906–2912.doi:10.1109/ITSC60802.2025.11423106
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/itsc60802.2025.11423106 2025
-
[13]
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Z. Yang et al. “The dawn of LMMs: Preliminary explorations with GPT-4V(ision)”. In:arXiv preprint arXiv:2309.17421(2023). arXiv: 2309.17421 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
S. Bai et al. “Qwen2.5-VL technical report”. In:arXiv preprint arXiv:2502.13923(2025). arXiv:2502.13923 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Grounding DINO: Marrying DINO with grounded pre- training for open-set object detection
S. Liu et al. “Grounding DINO: Marrying DINO with grounded pre- training for open-set object detection”. In:Computer Vision – ECCV
-
[16]
Vol. 15118. Lecture Notes in Computer Science. Springer, 2024, pp. 38–55.doi:10.1007/978-3-031-72970-6_3
-
[17]
Pix2Seq: A Language Modeling Framework for Object Detection
T. Chen, S. Saxena, L. Li, D. J. Fleet, and G. Hinton. “Pix2Seq: A Language Modeling Framework for Object Detection”. In:International Conference on Learning Representations. 2022. 8
2022
-
[18]
LISA: ReasoningSegmentationviaLargeLanguageModel
X. Lai, Z. Tian, Y. Chen, Y. Li, Y. Yuan, S. Liu, and J. Jia. “LISA: ReasoningSegmentationviaLargeLanguageModel”.In:Proceedingsof the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024
2024
-
[19]
MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction
Y. Chai, B. Sapp, M. Bansal, and D. Anguelov. “MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction”. In:Proceedings of the Conference on Robot Learning. 2019
2019
-
[20]
CoverNet: Multimodal Behavior Prediction Using Trajectory Sets
J. Philion, A. Kar, S. Fidler, and M. Behl. “CoverNet: Multimodal Behavior Prediction Using Trajectory Sets”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020
2020
-
[21]
HPNet: Dynamic trajectory forecasting with historical prediction attention
X. Tang, M. Kan, S. Shan, Z. Ji, J. Bai, and X. Chen. “HPNet: Dynamic trajectory forecasting with historical prediction attention”. In:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 15261–15270
2024
-
[22]
H.Lin,Y.Liu,S.Li,andX.Qu.“HowGenerativeAdversarialNetworks Promote the Development of Intelligent Transportation Systems: A Survey”. In:IEEE/CAA Journal of Automatica Sinica10.9 (2023), pp. 1781–1796.doi:10.1109/JAS.2023.123744
-
[23]
S. Zhang, H. Lin, M. Wang, B. Wei, Y. Liu, and X. Qu. “A Dynamic Prompting and Scenario Generation Method for Autonomous Driving Perception via Large-Model Optimization”. In:Transportation Research Part C: Emerging Technologies188 (2026), p. 105672.doi:10.1016/ j.trc.2026.105672
-
[24]
Risk-Controllable Multi-View Diffusion for Driving Scenario Generation
H. Lin, W. Shi, H. Huang, D. Zhuang, S. Zhang, Y. Liu, X. Qu, and J. Zhao. “Risk-Controllable Multi-View Diffusion for Driving Scenario Generation”.In:ProceedingsoftheIEEE/CVFConferenceonComputer Vision and Pattern Recognition Workshops. June 2026, pp. 5169–5178
2026
-
[25]
Training language models to follow instructions with human feedback
L. Ouyang et al. “Training language models to follow instructions with human feedback”. In:Advances in Neural Information Processing Systems. Vol. 35. 2022, pp. 27730–27744
2022
-
[26]
A meta- analysis on the reliability of comparative judgement
S. Verhavert, R. Bouwer, V. Donche, and S. De Maeyer. “A meta- analysis on the reliability of comparative judgement”. In:Assessment in Education: Principles, Policy & Practice26.5 (2019), pp. 541–562.doi: 10.1080/0969594X.2019.1602027
-
[27]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. “LoRA: Low-Rank Adaptation of Large Language Models”. In:International Conference on Learning Representations. 2022
2022
-
[28]
DETRs beat YOLOs on real-time object detection
Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y. Liu, and J. Chen. “DETRs beat YOLOs on real-time object detection”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 16965–16974
2024
-
[29]
3D-MOOD: Lifting 2D to 3D for monocular open- set object detection
Y.-H.Yang,L.Piccinelli,M.Segu,S.Li,R.Huang,Y.Fu,M.Pollefeys,H. Blum, and Z. Bauer. “3D-MOOD: Lifting 2D to 3D for monocular open- set object detection”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025, pp. 7429–7439
2025
-
[30]
Masked- attention mask transformer for universal image segmentation
B.Cheng,I.Misra,A.G.Schwing,A.Kirillov,andR.Girdhar.“Masked- attention mask transformer for universal image segmentation”. In:Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, pp. 1290–1299
2022
-
[31]
X. Zhao, W. Ding, Y. An, Y. Du, T. Yu, M. Li, M. Tang, and J. Wang. “Fast Segment Anything”. In:arXiv preprint arXiv:2306.12156(2023). arXiv:2306.12156 [cs.CV]
-
[32]
In: Eu- ropean Conference on Computer Vision (2020),https://doi.org/10.1007/978- 3-030-58452-8_241
T.-Y. Lin et al. “Microsoft COCO: Common objects in context”. In: Computer Vision – ECCV 2014. Vol. 8693. Lecture Notes in Computer Science. Springer, 2014, pp. 740–755.doi:10.1007/978- 3- 319- 10602-1_48
-
[33]
Vision meets robotics: The KITTI dataset
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun. “Vision meets robotics: The KITTI dataset”. In:The International Journal of Robotics Research 32.11 (2013), pp. 1231–1237.doi:10.1177/0278364913491297
-
[34]
Argoverse: 3D tracking and forecasting with rich maps
M.-F. Chang et al. “Argoverse: 3D tracking and forecasting with rich maps”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, pp. 8748–8757
2019
-
[35]
The Cityscapes dataset for semantic urban scene understanding
M.Cordts,M.Omran,S.Ramos,T.Rehfeld,M.Enzweiler,R.Benenson, U. Franke, S. Roth, and B. Schiele. “The Cityscapes dataset for semantic urban scene understanding”. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016, pp. 3213–3223
2016
-
[36]
J. Wu, Z. Huang, Z. Hu, and C. Lv. “Toward Human-in-the-Loop AI: Enhancing Deep Reinforcement Learning via Real-Time Human GuidanceforAutonomousDriving”.In:Engineering21.2(2023),pp.75– 91.doi:10.1016/j.eng.2022.05.017. 9 Appendix Thisappendixreportsthecompletetask-specificmetricsandabsoluteinferencecostsomittedfromthecompactmain-textcomparison, followed b...
-
[37]
Analyze the position of each candidate (horizontal and vertical alignment)
-
[38]
Analyze the size and aspect ratio of each candidate
-
[39]
Evaluate the overlap (IoU) with the target object
-
[40]
Verify the class accuracy of each candidate
-
[41]
Select the most suitable candidate based on comprehensive analysis Finally answer: Candidate X is the best choice. 3D object detection – selection prompt Analyze the following 3D bounding box candidates and select the most accurate one through step−by−step analysis of each candidate's characteristics: Candidate 0: class xx, location x y z, dimensions w h ...
-
[42]
Analyze the position characteristics of each candidate
-
[43]
Analyze the size characteristics of each candidate
-
[44]
Analyze the orientation characteristics of each candidate
-
[45]
11 Trajectory prediction – selection prompt You are analyzing a trajectory prediction scenario
Based on the above analysis, select the most suitable candidate Finally answer: Candidate X is the best choice. 11 Trajectory prediction – selection prompt You are analyzing a trajectory prediction scenario. The image shows: −Green solid line with dots: vehicle historical trajectory −Gray lines: road lane boundaries and centerlines −Gray line: reference t...
-
[46]
Visual Continuity: Does it smoothly continue from the historical path?
-
[47]
Endpoint Accuracy: Does it reach a reasonable destination based on the reference?
-
[48]
Driving Realism: Would a human driver naturally follow this path?
-
[49]
Candidate 3
Road Compliance: Does it follow the road structure shown in gray? Select the candidate that best balances these criteria. Respond with ONLY the number (e.g., "Candidate 3" or "3"). Semantic segmentation – selection prompt Query category: <TARGET_CATEGORY> The image shows N candidate masks outlined in different colors and numbered 1−N. Select all masks tha...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.