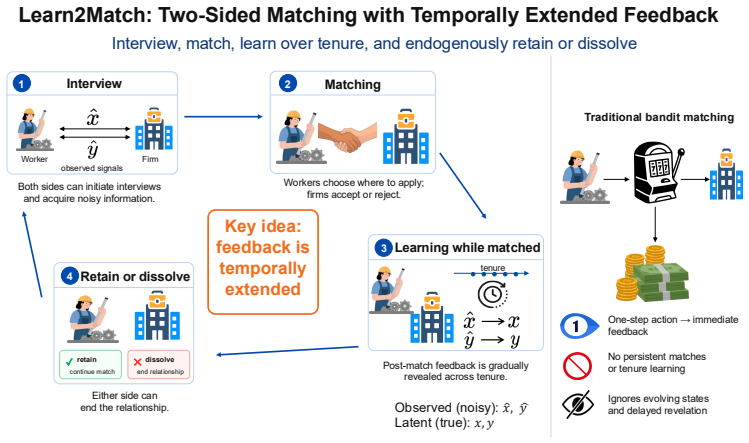
Learn to Match: Two-Sided Matching with Temporally Extended Feedback
Pith reviewed 2026-06-28 02:00 UTC · model grok-4.3
The pith
Reinforcement learning agents achieve higher social welfare and lower regret than bandit methods when matching feedback arrives gradually over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
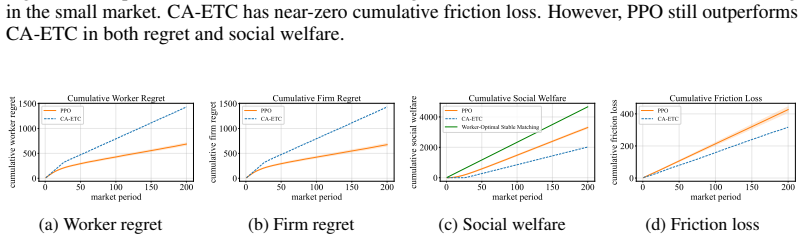
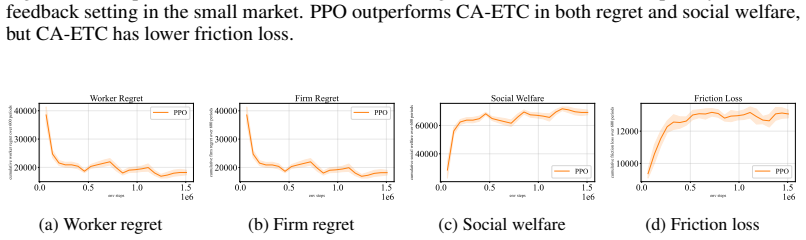
Casting two-sided matching as a partially observable Markov game that incorporates costly pre-match screening, noisy post-match observations, evolving latent profiles, and endogenous continuation or dissolution decisions yields the Learn2Match benchmark. In this benchmark, independent PPO policies attain higher cumulative social welfare and lower cumulative regret than the CA-ETC bandit baseline under temporally extended feedback, while incurring higher information-friction loss that measures the welfare gap from incomplete preference revelation.
What carries the argument
The partially observable Markov game formulation of two-sided matching with temporally extended feedback, implemented as the Learn2Match multi-agent reinforcement learning benchmark.
If this is right
- Decentralized RL policies can improve outcomes in markets where agents must choose whom to interview and when to dissolve matches based on gradually arriving information.
- Bandit algorithms that assume immediate sub-Gaussian feedback may leave welfare on the table once matching decisions affect future observations and continuation values.
- Effective matching algorithms will need to combine the adaptivity of reinforcement learning with the coordinated exploration structure of bandit methods.
- Learn2Match provides a testbed for methods that are adaptive like RL agents, statistically disciplined like bandits, and aware of stability constraints like classical matching theory.
Where Pith is reading between the lines
- The observed information-friction gap suggests that independent learning may miss opportunities for agents to coordinate on which latent attributes to probe first.
- The framework could be used to test whether adding explicit stability constraints to the RL objective reduces regret without sacrificing welfare gains.
- Scaling the benchmark to larger numbers of agents would reveal whether the current performance advantage persists when market thickness increases.
Load-bearing premise
Real two-sided matching markets can be faithfully represented as a partially observable Markov game whose state tracks evolving latent profiles, costly screening, noisy observations, and endogenous match continuation decisions.
What would settle it
A run of the Learn2Match benchmark in which independent PPO produces neither higher cumulative social welfare nor lower cumulative regret than the CA-ETC baseline under the same temporally extended feedback conditions.
Figures



read the original abstract
Two-sided matching markets often involve information that unfolds over time through interviews, repeated interaction, learning, and separation. Existing matching models typically reduce this process to immediate sub-Gaussian feedback about fixed preferences, missing settings where payoff-relevant information is revealed gradually and changes future matching decisions. We introduce a framework with temporally extended feedback, that formulates two-sided matching as a partially observable Markov game with costly pre-match screening, noisy post-match observations, evolving latent profiles, and endogenous continuation or dissolution. We instantiate this framework in Learn2Match, a multi-agent reinforcement-learning benchmark for dynamic matching markets. Learn2Match supports decentralized decision making over whom to interview, whom to match with, and when to dissolve a match, while evaluating policies using regret, social welfare, and an information-friction loss that measures the welfare gap caused by incomplete revelation of latent preferences. We find that independent PPO achieves higher cumulative social welfare and lower cumulative regret than the bandit-style CA-ETC baseline under temporally extended feedback, demonstrating the promise of MARL for dynamic matching markets. However, PPO still incurs higher information-friction loss, revealing that end-to-end MARL does not yet provide the coordinated exploration structure of matching-bandit methods. These results position Learn2Match as a benchmark for developing the next generation of matching-market algorithms: methods that are adaptive like RL agents, statistically disciplined like bandit algorithms, and structurally aware like stable-matching mechanisms. Please refer to https://sites.google.com/view/learn-to-match/home for the official website and the code link.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework modeling two-sided matching markets with temporally extended feedback as a partially observable Markov game (POMG) that incorporates costly pre-match screening, noisy post-match observations, evolving latent profiles, and endogenous continuation or dissolution. It instantiates this in the Learn2Match benchmark for decentralized MARL decisions on interviewing, matching, and dissolving, and reports that independent PPO achieves higher cumulative social welfare and lower cumulative regret than a bandit-style CA-ETC baseline under this setting, while incurring higher information-friction loss; the work positions Learn2Match as a benchmark for algorithms combining RL adaptability, bandit statistical discipline, and stable-matching structure.
Significance. If the empirical comparison is shown to use equivalent information structures and rigorous protocols, the work would establish a useful new benchmark at the intersection of MARL and dynamic matching markets, highlighting both the promise of decentralized RL and the remaining gap in coordinated exploration relative to bandit methods. The explicit information-friction loss metric and support for endogenous decisions are strengths that could drive follow-on research.
major comments (2)
- [Abstract] Abstract: the central empirical claim that independent PPO outperforms CA-ETC on welfare and regret supplies no experimental details on run count, hyperparameter search, statistical tests, or benchmark construction; without these the claim cannot be evaluated and is load-bearing for the paper's contribution.
- [framework description] Framework description (and abstract): the adaptation of the CA-ETC baseline to the POMG with latent-profile evolution, costly screening, noisy observations, and endogenous dissolution is not specified. If the baseline does not receive the same information structure and action space as the RL agents, any performance gap could be an artifact of an under-powered baseline rather than evidence for MARL.
minor comments (1)
- [Abstract] Abstract: the website and code link are mentioned but the manuscript should include a permanent reference or DOI for the benchmark to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer experimental details and baseline specification. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that independent PPO outperforms CA-ETC on welfare and regret supplies no experimental details on run count, hyperparameter search, statistical tests, or benchmark construction; without these the claim cannot be evaluated and is load-bearing for the paper's contribution.
Authors: We agree the abstract is too high-level on this point. Full details appear in Section 5 (20 independent runs, grid-search hyperparameter tuning, paired t-tests at p<0.05) and Section 4 (benchmark construction). In revision we will append a concise experimental clause to the abstract. revision: yes
-
Referee: [framework description] Framework description (and abstract): the adaptation of the CA-ETC baseline to the POMG with latent-profile evolution, costly screening, noisy observations, and endogenous dissolution is not specified. If the baseline does not receive the same information structure and action space as the RL agents, any performance gap could be an artifact of an under-powered baseline rather than evidence for MARL.
Authors: Section 3.3 and Appendix C already describe the extension: CA-ETC maintains belief distributions over evolving latent profiles, uses identical screening and dissolution actions, and receives the same noisy observations. To eliminate ambiguity we will insert an explicit equivalence statement in the main text. revision: yes
Circularity Check
No significant circularity in empirical benchmark results
full rationale
The paper defines a POMG framework for matching with temporally extended feedback, instantiates it as the Learn2Match benchmark, and reports simulation outcomes comparing independent PPO against a CA-ETC baseline on welfare, regret, and information-friction loss. These metrics are computed directly from environment rollouts rather than being algebraically equivalent to any fitted parameters, self-cited uniqueness theorems, or ansatzes inside the paper's own equations. The central empirical claim is therefore an observed simulation result, not a quantity forced by construction or by a self-citation chain; the provided code link further allows external reproduction outside the manuscript's fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Two-sided matching markets can be represented as partially observable Markov games with costly pre-match screening, noisy post-match observations, evolving latent profiles, and endogenous continuation or dissolution.
invented entities (1)
-
Learn2Match benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
School choice: A mechanism design approach
Atila Abdulkadiro ˘glu and Tayfun Sönmez. School choice: A mechanism design approach. American economic review, 93(3):729–747, 2003
2003
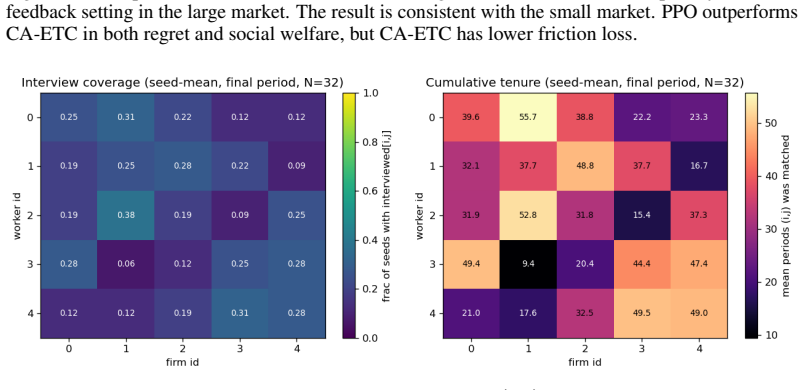
-
[2]
From signaling to interviews in random matching markets
Maxwell Allman, Itai Ashlagi, Amin Saberi, and Sophie H Yu. From signaling to interviews in random matching markets. InProceedings of the 57th Annual ACM Symposium on Theory of Computing, pages 1556–1567, 2025
2025
-
[3]
Employer learning and statistical discrimination.The quarterly journal of economics, 116(1):313–350, 2001
Joseph G Altonji and Charles R Pierret. Employer learning and statistical discrimination.The quarterly journal of economics, 116(1):313–350, 2001
2001
-
[4]
Stable matching with inter- views
Itai Ashlagi, Jiale Chen, Mohammad Roghani, and Amin Saberi. Stable matching with inter- views. In16th Innovations in Theoretical Computer Science Conference (ITCS 2025), pages 12–1. Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2025
2025
-
[5]
Andreas Athanasopoulos, Anne-Marie George, and Christos Dimitrakakis. Probably correct op- timal stable matching for two-sided markets under uncertainty.arXiv preprint arXiv:2501.03018, 2025
-
[6]
A better match for drivers and riders: Reinforcement learning at lyft.INFORMS Journal on Applied Analytics, 54(1):71–83, 2024
Xabi Azagirre, Akshay Balwally, Guillaume Candeli, Nicholas Chamandy, Benjamin Han, Alona King, Hyungjun Lee, Martin Loncaric, Sébastien Martin, Vijay Narasiman, et al. A better match for drivers and riders: Reinforcement learning at lyft.INFORMS Journal on Applied Analytics, 54(1):71–83, 2024
2024
-
[7]
Efficient interview scheduling for stable matching.arXiv preprint arXiv:2602.20358, 2026
Moshe Babaioff, Rotem Gil, and Assaf Romm. Efficient interview scheduling for stable matching.arXiv preprint arXiv:2602.20358, 2026
-
[8]
Employer search, training, and vacancy duration.Economic inquiry, 35(1):167–192, 1997
John M Barron, Mark C Berger, and Dan A Black. Employer search, training, and vacancy duration.Economic inquiry, 35(1):167–192, 1997
1997
-
[9]
Beyond log2(t) regret for decentralized bandits in matching markets
Soumya Basu, Karthik Abinav Sankararaman, and Abishek Sankararaman. Beyond log2(t) regret for decentralized bandits in matching markets. InInternational Conference on Machine Learning, pages 705–715. PMLR, 2021
2021
-
[10]
The costs of hiring skilled workers
Marc Blatter, Samuel Muehlemann, and Samuel Schenker. The costs of hiring skilled workers. European Economic Review, 56(1):20–35, 2012
2012
-
[11]
Recruitment policies, job-filling rates, and matching efficiency.Journal of the European Economic Association, 21(6):2413–2459, 2023
Carlos Carrillo-Tudela, Hermann Gartner, and Leo Kaas. Recruitment policies, job-filling rates, and matching efficiency.Journal of the European Economic Association, 21(6):2413–2459, 2023
2023
-
[12]
Common learning
Martin W Cripps, Jeffrey C Ely, George J Mailath, and Larry Samuelson. Common learning. Econometrica, 76(4):909–933, 2008
2008
-
[13]
Aggregate demand management in search equilibrium.Journal of political Economy, 90(5):881–894, 1982
Peter A Diamond. Aggregate demand management in search equilibrium.Journal of political Economy, 90(5):881–894, 1982
1982
-
[14]
Learning and wage dynamics.The Quarterly Journal of Economics, 111(4):1007–1047, 1996
Henry S Farber and Robert Gibbons. Learning and wage dynamics.The Quarterly Journal of Economics, 111(4):1007–1047, 1996
1996
-
[15]
College admissions and the stability of marriage.The American mathematical monthly, 69(1):9–15, 1962
David Gale and Lloyd S Shapley. College admissions and the stability of marriage.The American mathematical monthly, 69(1):9–15, 1962
1962
-
[16]
The u-shapes of occupational mobility.The Review of Economic Studies, 82(2):659–692, 2015
Fane Groes, Philipp Kircher, and Iourii Manovskii. The u-shapes of occupational mobility.The Review of Economic Studies, 82(2):659–692, 2015
2015
-
[17]
We know what you want: An advertising strategy recommender system for online advertising
Liyi Guo, Junqi Jin, Haoqi Zhang, Zhenzhe Zheng, Zhiye Yang, Zhizhuang Xing, Fei Pan, Lvyin Niu, Fan Wu, Haiyang Xu, et al. We know what you want: An advertising strategy recommender system for online advertising. InProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, pages 2919–2927, 2021
2021
-
[18]
Hitsch, Ali Hortaçsu, and Dan Ariely
Günter J. Hitsch, Ali Hortaçsu, and Dan Ariely. Matching and sorting in online dating.American Economic Review, 100(1):130–163, 2010. 10
2010
-
[19]
Putting gale & shapley to work: Guaranteeing stability through learning.Advances in Neural Information Processing Systems, 37:69043– 69068, 2024
Hadi Hosseini, Sanjukta Roy, and Duohan Zhang. Putting gale & shapley to work: Guaranteeing stability through learning.Advances in Neural Information Processing Systems, 37:69043– 69068, 2024
2024
-
[20]
Employee screening: theory and evidence, 2006
Fali Huang and Peter Cappelli. Employee screening: theory and evidence, 2006
2006
-
[21]
Designing approxi- mately optimal search on matching platforms
Nicole Immorlica, Brendan Lucier, Vahideh Manshadi, and Alexander Wei. Designing approxi- mately optimal search on matching platforms. InProceedings of the 22nd ACM Conference on Economics and Computation, pages 632–633, 2021
2021
-
[22]
Learn- ing equilibria in matching markets from bandit feedback.Advances in Neural Information Processing Systems, 34:3323–3335, 2021
Meena Jagadeesan, Alexander Wei, Yixin Wang, Michael Jordan, and Jacob Steinhardt. Learn- ing equilibria in matching markets from bandit feedback.Advances in Neural Information Processing Systems, 34:3323–3335, 2021
2021
-
[23]
Occupational mobility and wage inequality.The Review of Economic Studies, 76(2):731–759, 2009
Gueorgui Kambourov and Iourii Manovskii. Occupational mobility and wage inequality.The Review of Economic Studies, 76(2):731–759, 2009
2009
-
[24]
Seth Karten, Wenzhe Li, Zihan Ding, Samuel Kleiner, Yu Bai, and Chi Jin. Llm economist: Large population models and mechanism design in multi-agent generative simulacra.arXiv preprint arXiv:2507.15815, 2025
-
[25]
Player-optimal stable regret for bandit learning in matching markets
Fang Kong and Shuai Li. Player-optimal stable regret for bandit learning in matching markets. InProceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1512–1522. SIAM, 2023
2023
-
[26]
Bandit learning in matching markets with indifference
Fang Kong, Jingqi Tang, Mingzhu Li, Pinyan Lu, John CS Lui, and Shuai Li. Bandit learning in matching markets with indifference. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
The speed of employer learning.Journal of Labor Economics, 25(1):1–35, 2007
Fabian Lange. The speed of employer learning.Journal of Labor Economics, 25(1):1–35, 2007
2007
-
[28]
A survey on bandit learning in matching markets
Shuai Li, Zilong Wang, and Fang Kong. A survey on bandit learning in matching markets. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 10546–10554, 2025
2025
-
[29]
Tight regret bounds for infinite-armed linear contextual bandits
Yingkai Li, Yining Wang, Xi Chen, and Yuan Zhou. Tight regret bounds for infinite-armed linear contextual bandits. InInternational Conference on Artificial Intelligence and Statistics, pages 370–378. PMLR, 2021
2021
-
[30]
Dynamic matching bandit for two-sided online markets.arXiv preprint arXiv:2205.03699, 2022
Yuantong Li, Chi-hua Wang, Guang Cheng, and Will Wei Sun. Dynamic matching bandit for two-sided online markets.arXiv preprint arXiv:2205.03699, 2022
-
[31]
Bandit learning in decentralized matching markets.Journal of Machine Learning Research, 22(211):1–34, 2021
Lydia T Liu, Feng Ruan, Horia Mania, and Michael I Jordan. Bandit learning in decentralized matching markets.Journal of Machine Learning Research, 22(211):1–34, 2021
2021
-
[32]
Welfare maximiza- tion in competitive equilibrium: Reinforcement learning for markov exchange economy
Zhihan Liu, Miao Lu, Zhaoran Wang, Michael Jordan, and Zhuoran Yang. Welfare maximiza- tion in competitive equilibrium: Reinforcement learning for markov exchange economy. In International Conference on Machine Learning, pages 13870–13911. PMLR, 2022
2022
-
[33]
Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems, 30, 2017
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems, 30, 2017
2017
-
[34]
Economics of information and job search.The Quarterly Journal of Economics, 84(1):113–126, 1970
John Joseph McCall. Economics of information and job search.The Quarterly Journal of Economics, 84(1):113–126, 1970
1970
-
[35]
Job matching and occupational choice.Journal of Political economy, 92(6): 1086–1120, 1984
Robert A Miller. Job matching and occupational choice.Journal of Political economy, 92(6): 1086–1120, 1984
1984
-
[36]
Learn to match with no regret: Reinforcement learning in markov matching markets.Advances in Neural Information Processing Systems, 35:19956–19970, 2022
Yifei Min, Tianhao Wang, Ruitu Xu, Zhaoran Wang, Michael Jordan, and Zhuoran Yang. Learn to match with no regret: Reinforcement learning in markov matching markets.Advances in Neural Information Processing Systems, 35:19956–19970, 2022
2022
-
[37]
Schooling and earnings
Jacob A Mincer. Schooling and earnings. InSchooling, experience, and earnings, pages 41–63. NBER, 1974. 11
1974
-
[38]
Two-Sided Time-Independent Regret for Matching Markets with Limited Interviews
Amirmahdi Mirfakhar, Xuchuang Wang, Mengfan Xu, Hedyeh Beyhaghi, and Moham- mad Hajiesmaili. Bandit learning in matching markets with interviews.arXiv preprint arXiv:2602.12224, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Job creation and job destruction in the theory of unemployment.The review of economic studies, 61(3):397–415, 1994
Dale T Mortensen and Christopher A Pissarides. Job creation and job destruction in the theory of unemployment.The review of economic studies, 61(3):397–415, 1994
1994
-
[40]
Wage growth and the theory of turnover.Journal of Labor Economics, 18 (2):204–220, 2000
Lalith Munasinghe. Wage growth and the theory of turnover.Journal of Labor Economics, 18 (2):204–220, 2000
2000
-
[41]
Two-sided bandit learning in fully-decentralized matching markets
Tejas Pagare and Avishek Ghosh. Two-sided bandit learning in fully-decentralized matching markets. InICML 2023 Workshop The Many Facets of Preference-Based Learning, 2023
2023
-
[42]
Explore-then-commit algorithms for decentralized two-sided matching markets
Tejas Pagare and Avishek Ghosh. Explore-then-commit algorithms for decentralized two-sided matching markets. In2024 IEEE International Symposium on Information Theory (ISIT), pages 2092–2097. IEEE, 2024
2092
-
[43]
Competing bandits in decentralized contextual matching markets.arXiv preprint arXiv:2411.11794, 2024
Satush Parikh, Soumya Basu, Avishek Ghosh, and Abishek Sankararaman. Competing bandits in decentralized contextual matching markets.arXiv preprint arXiv:2411.11794, 2024
-
[44]
MIT press, 2000
Christopher A Pissarides.Equilibrium unemployment theory. MIT press, 2000
2000
-
[45]
Gaurab Pokharel and Sanmay Das. Converging to stability in two-sided bandits: The case of unknown preferences on both sides of a matching market.arXiv preprint arXiv:2302.06176, 2023
-
[46]
Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
2020
-
[47]
The national residency matching program as a labor market.JAMA, 275(13): 1054–1056, 1996
Alvin E Roth. The national residency matching program as a labor market.JAMA, 275(13): 1054–1056, 1996
1996
-
[48]
Two-sided matching.Handbook of game theory with economic applications, 1:485–541, 1992
Alvin E Roth and Marilda Sotomayor. Two-sided matching.Handbook of game theory with economic applications, 1:485–541, 1992
1992
-
[49]
Testing for asymmetric employer learning.Journal of Labor Economics, 25(4): 651–691, 2007
Uta Schönberg. Testing for asymmetric employer learning.Journal of Labor Economics, 25(4): 651–691, 2007
2007
-
[50]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[51]
A multiagent reinforcement learning framework for off-policy evaluation in two-sided markets.The Annals of Applied Statistics, 17(4):2701–2722, 2023
Chengchun Shi, Runzhe Wan, Ge Song, Shikai Luo, Hongtu Zhu, and Rui Song. A multiagent reinforcement learning framework for off-policy evaluation in two-sided markets.The Annals of Applied Statistics, 17(4):2701–2722, 2023
2023
-
[52]
Optimal match recommendations in two-sided marketplaces with endogenous prices
Peng Shi. Optimal match recommendations in two-sided marketplaces with endogenous prices. Management Science, 71(9):7431–7448, 2025
2025
-
[53]
The cyclical behavior of equilibrium unemployment and vacancies.American economic review, 95(1):25–49, 2005
Robert Shimer. The cyclical behavior of equilibrium unemployment and vacancies.American economic review, 95(1):25–49, 2005
2005
-
[54]
Labor turnover costs and the cyclical behavior of vacancies and unemployment.Macroeconomic Dynamics, 13(S1):76–96, 2009
José Ignacio Silva and Manuel Toledo. Labor turnover costs and the cyclical behavior of vacancies and unemployment.Macroeconomic Dynamics, 13(S1):76–96, 2009
2009
-
[55]
Job mobility and the careers of young men.The Quarterly Journal of Economics, 107(2):439–479, 1992
Robert H Topel and Michael P Ward. Job mobility and the careers of young men.The Quarterly Journal of Economics, 107(2):439–479, 1992
1992
-
[56]
Online dating recommendations: matching markets and learning preferences
Kun Tu, Bruno Ribeiro, David Jensen, Don Towsley, Benyuan Liu, Hua Jiang, and Xiaodong Wang. Online dating recommendations: matching markets and learning preferences. In Proceedings of the 23rd international conference on world wide web, pages 787–792, 2014
2014
-
[57]
Interview choice reveals your preference on the market: To improve job-resume matching through profiling memories
Rui Yan, Ran Le, Yang Song, Tao Zhang, Xiangliang Zhang, and Dongyan Zhao. Interview choice reveals your preference on the market: To improve job-resume matching through profiling memories. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 914–922, 2019. 12
2019
-
[58]
The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
2022
-
[59]
Multi-agent reinforcement learning: A selective overview.Foundations and Trends in Machine Learning, 2021
Kaiqing Zhang et al. Multi-agent reinforcement learning: A selective overview.Foundations and Trends in Machine Learning, 2021
2021
-
[60]
Decentralized two-sided bandit learning in matching market
YiRui Zhang and Zhixuan Fang. Decentralized two-sided bandit learning in matching market. InThe 40th Conference on Uncertainty in Artificial Intelligence, 2024
2024
-
[61]
Stephan Zheng, Alexander Trott, Sunil Srinivasa, Nikhil Naik, Melvin Gruesbeck, David C Parkes, and Richard Socher. The ai economist: Improving equality and productivity with ai-driven tax policies.arXiv preprint arXiv:2004.13332, 2020. 13 A Implementation details A.1 PPO implementation details Both small and large markets use an outside-option penalty of...
-
[62]
We prove that we are able to show that we can cover exactly the same CA-ETC results under some parameter setting
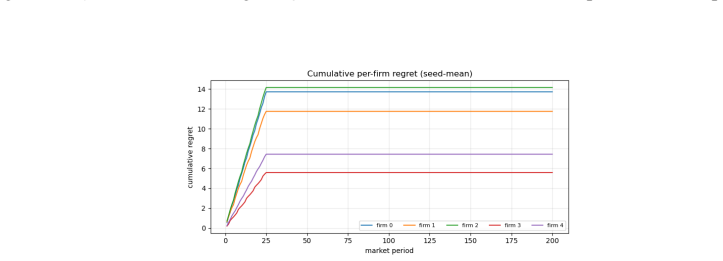
Figures 7 and 8 show that cumulative per-worker and per-firm regret rise during the initial exploration block and then flatten as the algorithm commits to its empirical Gale–Shapley matching, reproducing the structure reported in [ 42]. We prove that we are able to show that we can cover exactly the same CA-ETC results under some parameter setting. Figure...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.