Multiagent Protocols with Aggregated Confidence Signals
Pith reviewed 2026-06-27 06:52 UTC · model grok-4.3
The pith
Multiagent protocols aggregate confidence signals from debating agents into one system-level score that discriminates correct answers better than any single agent or standard debate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
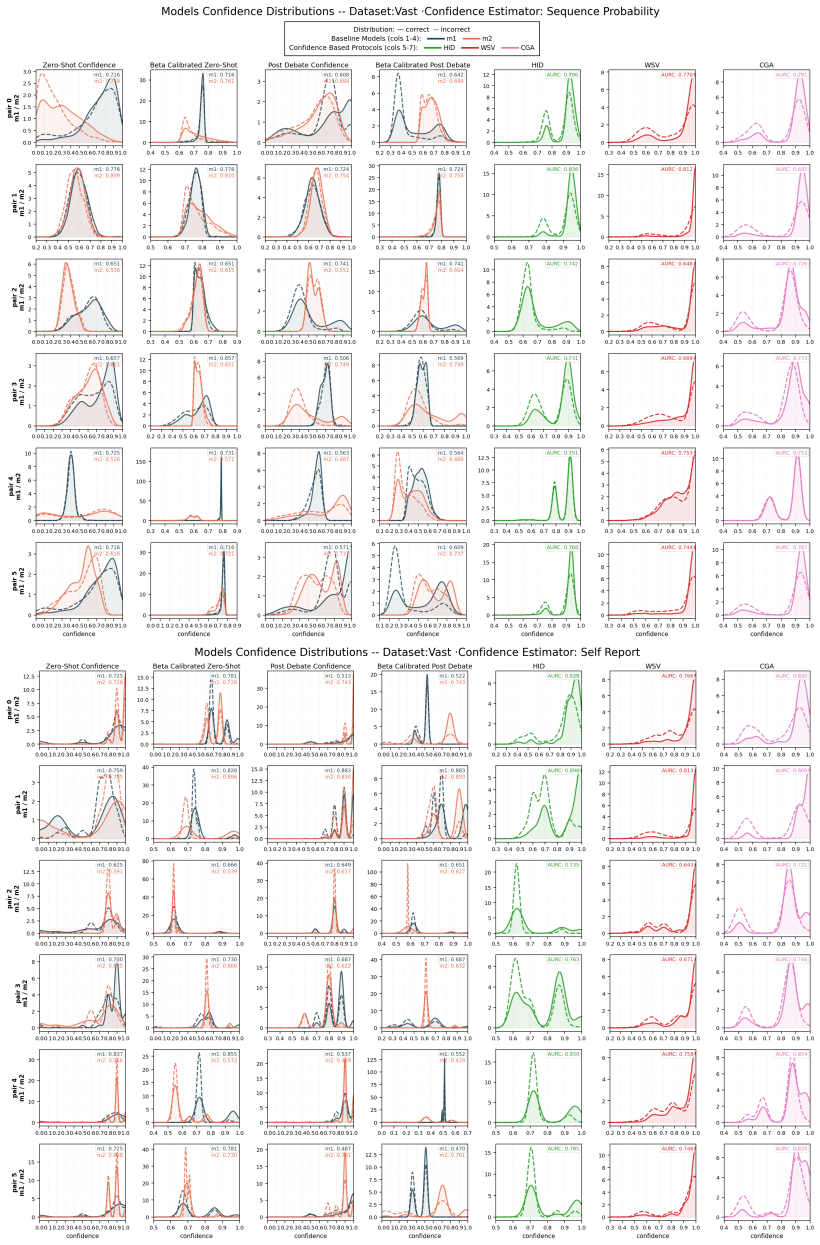
By first transforming raw confidence signals to make them comparable across models and then combining them via soft voting or a probability fusion called Bayesian fusion, the protocols produce a final answer along with a single aggregated confidence that is substantially more discriminative by AUARC than that of the best single agent or the standard debate baselines, while correctness measured by F1-score stays stable and recovers the losses MAD incurs on more ambiguous tasks.
What carries the argument
Three protocols that transform raw agent confidence signals into comparable values and fuse them with soft voting or Bayesian fusion to yield a system-level confidence.
Load-bearing premise
Raw confidence signals from different models can be transformed into comparable values and the chosen fusion methods will produce reliable system-level confidence across varied model sizes, homogeneous or heterogeneous pairs, and task types without introducing new biases.
What would settle it
A new benchmark or ambiguous task set where the aggregated confidence yields lower AUARC than the best single agent's confidence after the same transformation and fusion steps.
Figures
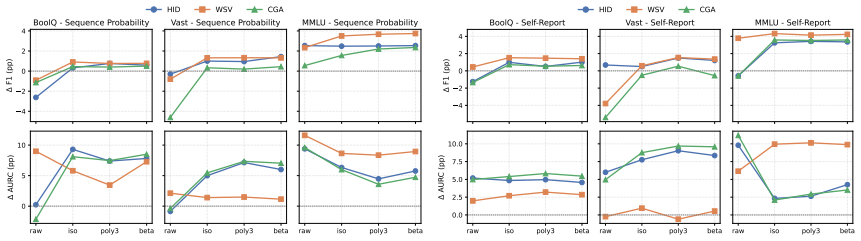
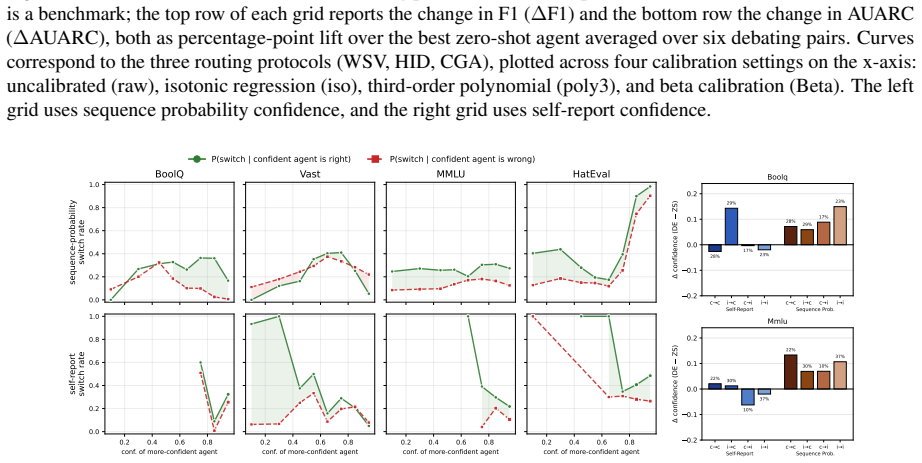
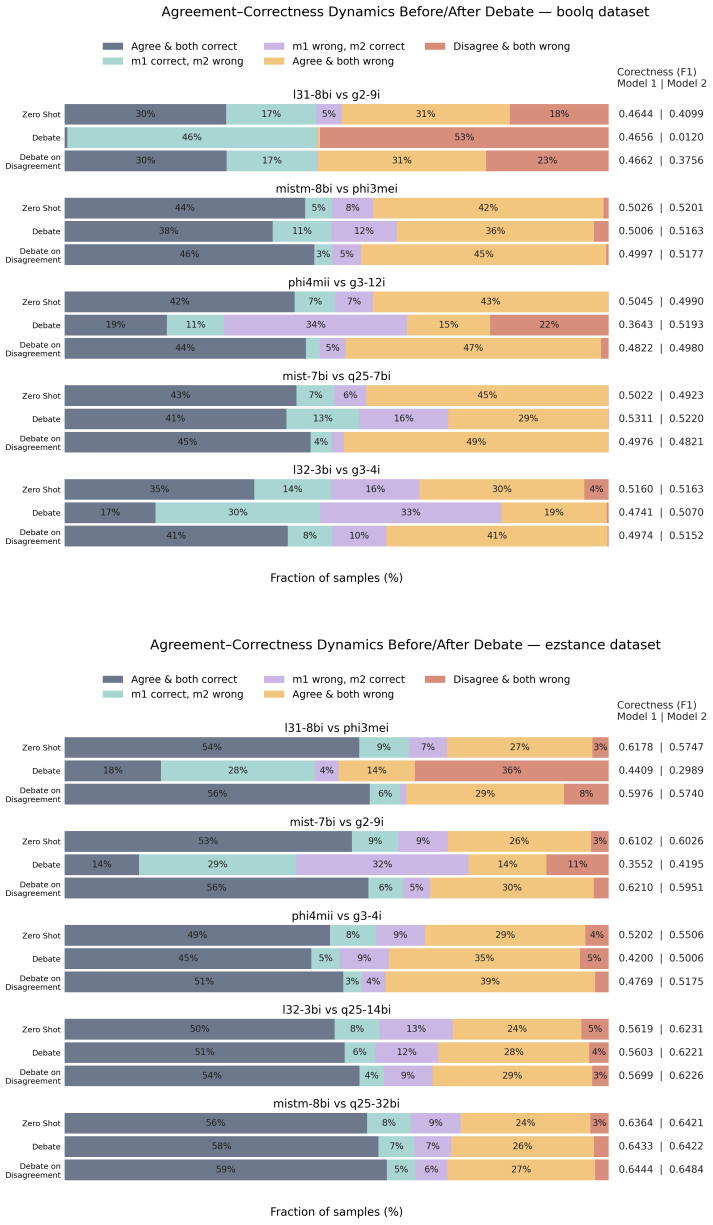
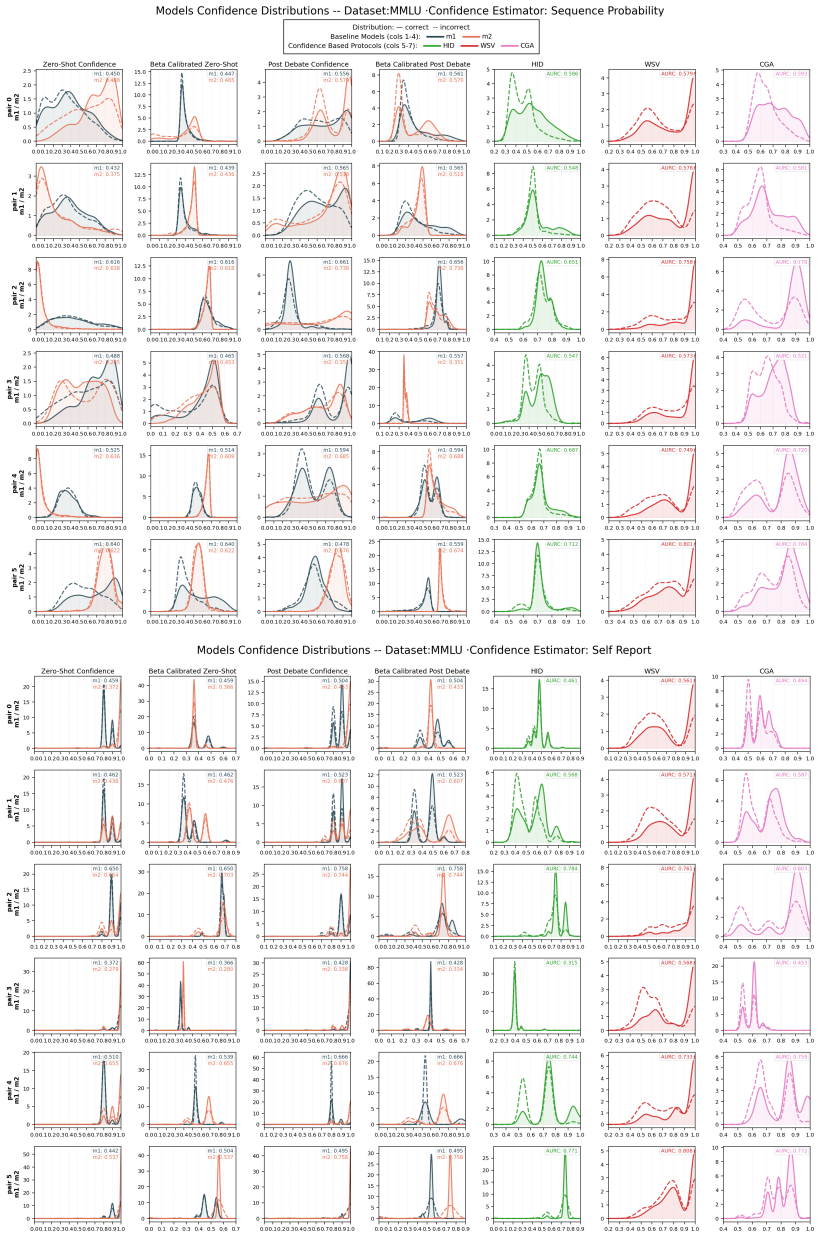
read the original abstract
Confidence is used for reliability, oversight, and a range of downstream decision tasks in Natural Language Processing (NLP), yet no existing method produces or evaluates a confidence for the output of a multiagent system. Prior work uses confidence within multiagent debate (MAD) to weight messages, trigger debate, or calibrate individual agents, but it never aggregates these into a single confidence for the system itself. We introduce three protocols that produce a final answer along with a single aggregated confidence by first transforming raw confidence signals to make them comparable across models, then combining them via soft voting or a probability fusion we call Bayesian fusion. This aggregated confidence is substantially more discriminative (AUARC) than that of the best single agent or the standard debate baselines, while correctness (F1-score) stays stable and recovers the losses MAD incurs on more ambiguous tasks. Analyzing two estimators, sequence probability and self-report, alongside parametric and non-parametric calibrators, we find that calibration improves F1 for both estimators while AUARC is less reliant on it. We evaluate six homogeneous and heterogeneous debating pairs per benchmark, across five benchmarks and four task types, spanning a range of model capabilities and sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces three protocols for multiagent debate systems that first transform raw confidence signals (from sequence-probability or self-report estimators, using parametric or non-parametric calibrators) to make them comparable across models, then aggregate them via soft voting or Bayesian fusion to produce both a final answer and a single system-level confidence. Across five benchmarks and four task types, with six homogeneous/heterogeneous agent pairs, the aggregated confidence yields substantially higher AUARC than the best single agent or standard debate baselines while F1 remains stable and recovers losses seen in MAD on ambiguous tasks.
Significance. If the empirical results hold after verification of the transformation step, the work addresses an important gap by supplying the first methods for system-level confidence in multiagent NLP setups, which could support better reliability, oversight, and downstream decisions. The systematic comparison of two estimators and multiple calibrators, plus the breadth of homogeneous/heterogeneous evaluations, adds value beyond the headline claim.
major comments (2)
- [Method (transformation and fusion protocols)] The headline AUARC improvement claim is load-bearing on the transformation step that renders raw confidences comparable across model sizes and homogeneous/heterogeneous pairs. The manuscript states that parametric/non-parametric calibrators are applied but supplies no rank-correlation diagnostics before/after calibration, per-model calibration curves, or ablation that removes the transformation, leaving open the possibility that fusion inflates AUARC without genuine improvement in discrimination.
- [Experiments and evaluation] The claim that correctness (F1) stays stable while recovering MAD losses on ambiguous tasks rests on the five-benchmark evaluation. No details are given on how baselines are implemented, how statistical significance of AUARC/F1 differences is assessed, or how data handling avoids leakage when calibrators are fit, making the support for the central empirical claim unverifiable from the presented text.
minor comments (2)
- [Method] Notation for the Bayesian fusion rule is introduced without an explicit equation; adding a numbered equation would clarify how the fused probability is computed from the calibrated inputs.
- [Introduction] The abstract refers to 'three protocols' but the text does not enumerate them with distinct names or pseudocode; a table or numbered list would improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work's significance and for the constructive feedback on the method and experiments. We address each major comment below, agreeing to incorporate additional diagnostics, ablations, and details in a revised version of the manuscript.
read point-by-point responses
-
Referee: [Method (transformation and fusion protocols)] The headline AUARC improvement claim is load-bearing on the transformation step that renders raw confidences comparable across model sizes and homogeneous/heterogeneous pairs. The manuscript states that parametric/non-parametric calibrators are applied but supplies no rank-correlation diagnostics before/after calibration, per-model calibration curves, or ablation that removes the transformation, leaving open the possibility that fusion inflates AUARC without genuine improvement in discrimination.
Authors: We agree that the transformation step is central to enabling fair aggregation across agents. While the manuscript describes the calibrators used, we did not provide the requested diagnostics. In the revision, we will include rank-correlation coefficients before and after calibration, per-model calibration curves (e.g., reliability diagrams), and an ablation study comparing aggregated performance with and without the transformation step. This will demonstrate that the improvement stems from better discrimination rather than inflation. We will also clarify why raw signals require transformation due to differing scales. revision: yes
-
Referee: [Experiments and evaluation] The claim that correctness (F1) stays stable while recovering MAD losses on ambiguous tasks rests on the five-benchmark evaluation. No details are given on how baselines are implemented, how statistical significance of AUARC/F1 differences is assessed, or how data handling avoids leakage when calibrators are fit, making the support for the central empirical claim unverifiable from the presented text.
Authors: We acknowledge the need for greater transparency in the experimental setup. In the revised manuscript, we will provide detailed descriptions of baseline implementations (including code-level specifics where possible), specify the statistical tests used for significance (such as bootstrap resampling or paired tests with p-values), and elaborate on the data handling procedures, including the use of separate validation sets for fitting calibrators to prevent leakage from the test data. This will make the results fully reproducible and verifiable. revision: yes
Circularity Check
No significant circularity; empirical protocols evaluated on external benchmarks
full rationale
The paper introduces three new protocols for producing aggregated confidence from multiagent debate outputs. These are constructed by transforming raw signals (via calibrators) then fusing via soft voting or Bayesian fusion, with results measured by AUARC and F1 on five external benchmarks across model pairs and task types. No equations, derivations, or self-citations are presented that reduce the claimed AUARC gains to a fitted parameter, renamed input, or self-referential quantity by construction. The central claims rest on empirical comparison to single-agent and MAD baselines rather than any definitional or load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Raw confidence signals from heterogeneous models can be transformed into comparable values
- domain assumption The five benchmarks and four task types are sufficient to demonstrate general improvement
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, and 1 others. 2024. Phi-4 technical re- port.arXiv preprint arXiv:2412.08905
Pith/arXiv arXiv 2024
-
[2]
Emily Allaway and Kathleen McKeown. 2020. Zero- shot stance detection: A dataset and model using generalized topic representations. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8913– 8931
2020
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, and 1 others. 2023. Qwen tech- nical report.arXiv preprint arXiv:2309.16609
Pith/arXiv arXiv 2023
-
[4]
Yilin Bai. 2024. Confidencecal: Enhancing llms reliability through confidence calibration in multi- agent debate. In2024 10th International Conference on Big Data and Information Analytics (BigDIA), pages 221–226. IEEE
2024
-
[5]
Yavuz Faruk Bakman, Duygu Nur Yaldiz, Baturalp Buyukates, Chenyang Tao, Dimitrios Dimitriadis, and Salman Avestimehr. 2024. MARS: Meaning- aware response scoring for uncertainty estimation in generative LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 7752–7767, Bangkok, Thail...
2024
-
[6]
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. Chateval: Towards better llm-based evalu- ators through multi-agent debate.arXiv e-prints
2023
-
[7]
Hyeong Kyu Choi, Jerry Zhu, and Sharon Li. 2025. Debate or vote: Which yields better decisions in multi-agent large language models? InThe Thirty- ninth Annual Conference on Neural Information Pro- cessing Systems
2025
-
[8]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions. InNAACL
2019
-
[9]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. 2024. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st In- ternational Conference on Machine Learning, pages 11733–11763
2024
-
[10]
Sugyeong Eo, Hyeonseok Moon, Evelyn Hayoon Zi, Chanjun Park, and Heuiseok Lim. 2025. Debate only when necessary: Adaptive multiagent collab- oration for efficient llm reasoning.arXiv preprint arXiv:2504.05047
arXiv 2025
-
[11]
Wei Fan, JinYi Yoon, and Bo Ji. 2026. imad: Intelli- gent multi-agent debate for efficient and accurate llm inference. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29403– 29411
2026
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[13]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR
2017
-
[14]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Stein- hardt. 2021. Measuring massive multitask language understanding.Proceedings of the International Con- ference on Learning Representations (ICLR)
2021
-
[15]
Ari Holtzman, Peter West, Vered Shwartz, Yejin Choi, and Luke Zettlemoyer. 2021. Surface form competition: Why the highest probability answer 9 isn’t always right. InProceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pages 7038–7051, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics
2021
-
[16]
Zachary Kenton, Noah Y Siegel, János Kramár, Jonah Brown-Cohen, Samuel Albanie, Jannis Bu- lian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D Goodman, and 1 others. 2024. On scalable oversight with weak llms judging strong llms.Ad- vances in Neural Information Processing Systems, 37:75229–75276
2024
-
[17]
Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R Bowman, Tim Rocktäschel, and Ethan Perez. 2024. Debating with more persua- sive llms leads to more truthful answers. InProceed- ings of the 41st International Conference on Machine Learning, pages 23662–23733
2024
-
[18]
Meelis Kull, Telmo Silva Filho, and Peter Flach
-
[19]
InArtificial intelligence and statis- tics, pages 623–631
Beta calibration: a well-founded and easily implemented improvement on logistic calibration for binary classifiers. InArtificial intelligence and statis- tics, pages 623–631. PMLR
-
[20]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging divergent thinking in large language models through multi-agent debate. InProceedings of the 2024 conference on empiri- cal methods in natural language processing, pages 17889–17904
2024
-
[21]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun
-
[22]
Generating with confidence: Uncertainty quan- tification for black-box large language models.Trans- actions on Machine Learning Research
-
[23]
Zijie Lin and Bryan Hooi. 2025. Enhancing multi- agent debate system performance via confidence ex- pression.arXiv preprint arXiv:2509.14034
arXiv 2025
-
[24]
Chen Ling, Xujiang Zhao, Xuchao Zhang, Wei Cheng, Yanchi Liu, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Jie Ji, Guangji Bai, Liang Zhao, and Haifeng Chen. 2024. Uncertainty quan- tification for in-context learning of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational L...
2024
-
[25]
Yuhan Liu, Juntian Zhang, Yichen Wu, Martin Takac, Salem Lahlou, Xiuying Chen, and Nils Lukas
-
[26]
Breaking the martingale curse: Multi-agent de- bate via asymmetric cognitive potential energy.arXiv preprint arXiv:2603.06801
-
[27]
Qing Lyu, Kumar Shridhar, Chaitanya Malaviya, Li Zhang, Yanai Elazar, Niket Tandon, Marianna Apidianaki, Mrinmaya Sachan, and Chris Callison- Burch. 2025. Calibrating large language models with sample consistency. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 39, pages 19260–19268
2025
-
[28]
Gustavo Henrique Paetzold, Marcos Zampieri, and Shervin Malmasi. 2019. UTFPR at SemEval-2019 task 5: Hate speech identification with recurrent neu- ral networks. InProceedings of the 13th Interna- tional Workshop on Semantic Evaluation, pages 519– 523, Minneapolis, Minnesota, USA. Association for Computational Linguistics
2019
-
[29]
Ayush Pandey, Jai Bardhan, Ishita Jain, Ramya S Hebbalaguppe, Rohan Raju Dhanakshirur, and Lovekesh Vig. 2026. Refine and align: Confidence calibration through multi-agent interaction in vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 37810–37819
2026
-
[30]
Fabian Pedregosa and 1 others. 2011–. Scikit-learn: Machine learning in python
2011
-
[31]
Dan Qiao, Binbin Chen, Fengyu Cai, Jianlong Chen, Wenhao Li, Fuxin Jiang, Zuzhi Chen, Hongyuan Zha, Tieying Zhang, and Baoxiang Wang. 2026. Epis- temic gain, aleatoric cost: Uncertainty decomposi- tion in multi-agent debate for math reasoning.arXiv preprint arXiv:2603.01221
Pith/arXiv arXiv 2026
-
[32]
Ali Razghandi, Seyed Mohammad Hadi Hosseini, and Mahdieh Soleymani Baghshah. 2025. Cer: Con- fidence enhanced reasoning in llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7918–7938
2025
-
[33]
Yiliu Sun, Zicheng Zhao, Sheng Wan, and Chen Gong. 2025. Cortexdebate: Debating sparsely and equally for multi-agent debate. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 9503–9523
2025
-
[34]
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. 2025. Confidence improves self-consistency in llms. InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 20090–20111
2025
-
[35]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupati- raju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, and 1 others. 2024. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118
Pith/arXiv arXiv 2024
-
[36]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. 2023. Just ask for cali- bration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing...
2023
-
[37]
Haolun Wu, Zhenkun Li, and Lingyao Li. 2025. Can llm agents really debate? a controlled study of multi-agent debate in logical reasoning.arXiv preprint arXiv:2511.07784
arXiv 2025
-
[38]
Andrea Wynn, Harsh Satija, and Gillian Hadfield
-
[39]
Talk isn’t always cheap: Understanding fail- ure modes in multi-agent debate.arXiv preprint arXiv:2509.05396
-
[40]
Zhiqiu Xia, Jinxuan Xu, Yuqian Zhang, and Hang Liu. 2025. A survey of uncertainty estimation meth- ods on large language models. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 21381–21396, Vienna, Austria. Association for Computational Linguistics
2025
-
[41]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. 2024. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InThe Twelfth Inter- national Conference on Learning Representations
2024
-
[42]
Ruixin Yang, Dheeraj Rajagopal, Shirley Anugrah Hayati, Bin Hu, and Dongyeop Kang. 2024. Con- fidence calibration and rationalization for llms via multi-agent deliberation. InICLR 2024 Workshop on Reliable and Responsible Foundation Models
2024
-
[43]
Zhe Yang, Yichang Zhang, Yudong Wang, Ziyao Xu, Junyang Lin, and Zhifang Sui. 2025. Confidence vs critique: A decomposition of self-correction ca- pability for llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 3998–4014
2025
-
[44]
Luke Yoffe, Alfonso Amayuelas, and William Yang Wang. 2025. DebUnc: Improving large language model agent communication with uncertainty metrics. InFindings of the Association for Computational Lin- guistics: EMNLP 2025, pages 23299–23315, Suzhou, China. Association for Computational Linguistics
2025
-
[45]
Bianca Zadrozny and Charles Elkan. 2002. Trans- forming classifier scores into accurate multiclass probability estimates. InProceedings of the eighth ACM SIGKDD international conference on Knowl- edge discovery and data mining, pages 694–699
2002
-
[46]
Yuting Zeng, Weizhe Huang, Lei Jiang, Tongxuan Liu, Xitai Jin, Chen Tianying Tiana, Jing Li, and Xi- aohua Xu. 2025. S2-mad: Breaking the token barrier to enhance multi-agent debate efficiency. InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (Volu...
2025
-
[47]
Chenye Zhao and Cornelia Caragea. 2024. EZ- STANCE: A large dataset for English zero-shot stance detection. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15697– 15714, Bangkok, Thailand. Association for Compu- tational Linguistics
2024
-
[48]
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improv- ing few-shot performance of language models. In International conference on machine learning, pages 12697–12706. Pmlr
2021
-
[49]
Xiaochen Zhu, Caiqi Zhang, Yizhou Chi, Tom Stafford, Nigel Collier, and Andreas Vlachos
-
[50]
Demystifying multi-agent debate: The role of confidence and diversity.arXiv preprint arXiv:2601.19921. A Reproducibility Details A.1 Computational Budget and Infrastructure All of our experiments are inference-only; we do not perform any model training or fine-tuning. The only learning step is the lightweight optimiza- tion of per-stream calibrators and r...
Pith/arXiv arXiv 1973
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.