STABLEVAL: Disagreement-Aware and Stable Evaluation of AI Systems
Pith reviewed 2026-05-09 16:49 UTC · model grok-4.3
The pith
STABLEVAL models latent item correctness and annotator confusion to produce stable AI system rankings where majority vote fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
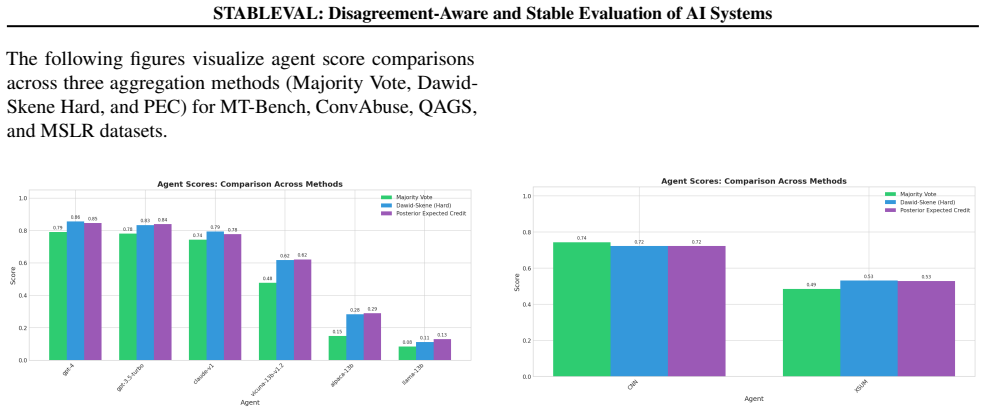
STABLEVAL is a disagreement-aware evaluation framework that models latent item correctness and annotator-specific confusion patterns to produce posterior expected item credit and calibrated agent-level scores. It treats ranking stability as a first-class objective and shows that this approach preserves underlying annotator behavior better than majority vote or label-denoising methods such as Dawid-Skene, resulting in lower score error and more consistent system orderings under controlled heterogeneity and adversarial noise.
What carries the argument
The probabilistic model of latent item correctness together with annotator-specific confusion patterns, which generates posterior expected credits and calibrated scores rather than hard labels.
If this is right
- Majority vote exhibits increasing score error and ranking instability as annotator heterogeneity and adversarial noise grow.
- STABLEVAL produces lower error and more stable system rankings across the same conditions.
- Ranking stability must be treated as an explicit goal separate from recovering individual hard labels.
- Disagreement modeling improves reproducibility of AI evaluations on both synthetic and real human-annotated data.
Where Pith is reading between the lines
- The same modeling approach could be applied to other subjective ranking tasks such as content moderation or creative evaluation to reduce dependence on single annotator pools.
- Quantifying the amount of disagreement that still allows reliable rankings might let practitioners decide when additional annotators are worth the cost.
- If the posteriors prove reliable, evaluation pipelines could report confidence intervals on system scores instead of point estimates.
Load-bearing premise
The chosen probabilistic model of latent item correctness and annotator confusion patterns will produce posteriors that genuinely reflect real-world stability rather than artifacts of the modeling assumptions.
What would settle it
Run the same set of items through multiple independent annotator groups and check whether STABLEVAL system rankings remain consistent across groups while majority-vote rankings flip; reversal of that pattern would falsify the stability advantage.
Figures









read the original abstract
Human evaluation remains the primary standard for assessing modern AI systems, yet annotator disagreement, bias, and variability make system rankings fragile under standard majority vote aggregation. Majority vote discards annotator reliability and item-level ambiguity, often yielding unstable comparisons across annotator subsets. We introduce STABLEVAL, a disagreement-aware evaluation framework that models latent item correctness and annotator-specific confusion patterns to produce posterior expected item credit and calibrated agent-level scores. Unlike label-denoising approaches such as Dawid-Skene, STABLEVAL is explicitly designed for stable and uncertainty-aware system evaluation rather than hard label recovery. We formalize ranking stability as a first-class evaluation objective and analyze how aggregation methods preserve or distort underlying annotator behavior. Across controlled synthetic experiments and multiple real-world human-annotated benchmarks, majority vote exhibits increasing score error and ranking instability under annotator heterogeneity and adversarial noise, while STABLEVAL yields more stable and statistically grounded system rankings. These results demonstrate that modeling disagreement is essential for robust and reproducible AI evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STABLEVAL, a disagreement-aware evaluation framework that models latent item correctness and annotator-specific confusion patterns to produce posterior expected item credit and calibrated agent-level scores. It claims that this leads to more stable and statistically grounded system rankings compared to majority vote, as shown in synthetic experiments and real-world human-annotated benchmarks.
Significance. If the empirical findings are robust, STABLEVAL could improve the reliability of human evaluations in AI, addressing a key challenge in reproducible research. The emphasis on ranking stability as a primary objective is a notable contribution to the field of evaluation methodologies.
major comments (2)
- [Synthetic Experiments] Synthetic Experiments section: The synthetic data appears to be generated from a latent model similar to the one used in STABLEVAL, raising the possibility that the reported improvements in stability are due to model alignment rather than general applicability. This is load-bearing for the claim of robustness under annotator heterogeneity.
- [Real-world Benchmarks] Real-world Benchmarks section: There is no independent ground-truth measure of ranking stability provided for the human-annotated datasets, making it challenging to verify that the reductions in score error are not artifacts of the probabilistic modeling assumptions.
minor comments (2)
- [Abstract] Abstract: The phrase 'statistically grounded system rankings' should be clarified with specific statistical measures or tests used to support the claims.
- [Related Work] Related Work: Consider adding a more detailed comparison table with Dawid-Skene and other label aggregation methods to highlight the differences in objectives.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating planned revisions where appropriate to improve clarity and robustness.
read point-by-point responses
-
Referee: [Synthetic Experiments] Synthetic Experiments section: The synthetic data appears to be generated from a latent model similar to the one used in STABLEVAL, raising the possibility that the reported improvements in stability are due to model alignment rather than general applicability. This is load-bearing for the claim of robustness under annotator heterogeneity.
Authors: We agree that the synthetic data generation shares structural elements with STABLEVAL to enable controlled simulation of annotator confusion and heterogeneity with known ground truth. This design choice isolates the impact of aggregation methods rather than testing recovery of the exact generative process. To strengthen the claim, we will add experiments using synthetic data generated from alternative models (e.g., independent per-annotator error rates without shared latent structure and non-probabilistic noise models) and report results in a revised Synthetic Experiments section. revision: partial
-
Referee: [Real-world Benchmarks] Real-world Benchmarks section: There is no independent ground-truth measure of ranking stability provided for the human-annotated datasets, making it challenging to verify that the reductions in score error are not artifacts of the probabilistic modeling assumptions.
Authors: We acknowledge that real-world human annotations lack direct ground truth for system rankings, as item correctness is latent by nature. Stability is assessed via proxies including ranking variance across random annotator subsets and degradation under injected adversarial noise, which are standard for evaluating robustness in the absence of oracle labels. We will revise the Real-world Benchmarks section to more explicitly describe these proxies, include sensitivity checks to modeling assumptions, and discuss their limitations as indirect measures. revision: partial
Circularity Check
No significant circularity; claims rest on empirical validation of a distinct modeling framework
full rationale
The paper introduces STABLEVAL as a new disagreement-aware framework that models latent item correctness and annotator confusion patterns to produce posterior expected credits and calibrated scores, explicitly distinguishing it from label-recovery methods like Dawid-Skene. It formalizes ranking stability as an objective and supports claims via controlled synthetic experiments plus real-world human-annotated benchmarks showing reduced score error and instability under heterogeneity. No equations, derivations, or self-citations are shown that reduce outputs to inputs by construction, fitted parameters renamed as predictions, or ansatz smuggling. The central results depend on external benchmark comparisons rather than internal definitional equivalence or load-bearing self-references, making the derivation self-contained against the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Annotator responses arise from latent item correctness combined with annotator-specific confusion patterns
- domain assumption Modeling disagreement explicitly improves ranking stability over majority vote
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.