UPLOTS: A Unified Pretrained Language Model for Constrained Time-series Generation
Pith reviewed 2026-06-27 13:48 UTC · model grok-4.3
The pith
A single pre-trained transformer generates constrained time series across domains using learned prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UPLOTS is a unified prompt-guided language model framework for constrained time-series generation that employs a single pre-trained transformer backbone guided by learned constraint prompts, with dynamic multi-dataset loss re-weighting and prompt-to-pattern mapping, to enable on-demand generation with precise pattern control across diverse domains.
What carries the argument
learned constraint prompts that map to temporal patterns and steer the single transformer backbone
If this is right
- New combinations of constraints can be handled at inference without retraining the model.
- Generated data can be used to augment scarce real datasets and improve downstream forecasting accuracy.
- The model generalizes to held-out constraint settings not seen during training.
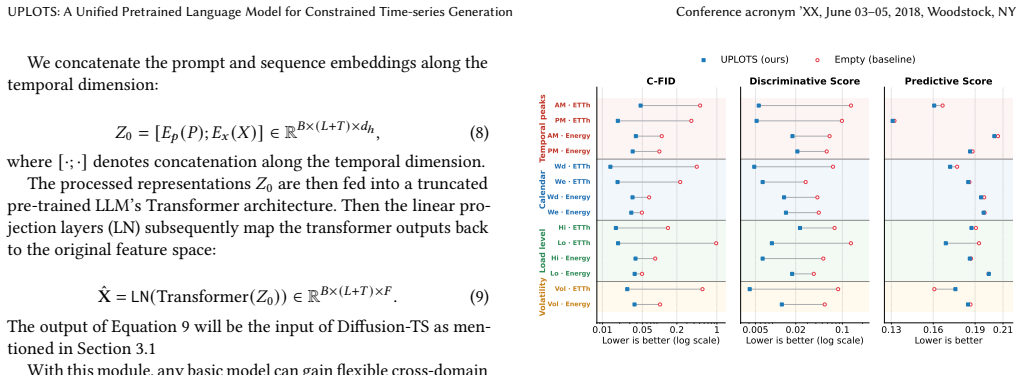
- Evaluation across four real-world benchmarks covers peak-period, calendar, load-level, and volatility patterns.
Where Pith is reading between the lines
- Maintaining one model instead of many per dataset would cut the total storage and retraining cost for organizations that work with multiple time-series sources.
- The prompting approach could be tested on sequential data outside time series, such as event logs or sensor streams that carry similar pattern constraints.
- Running the same architecture on a new domain never seen in the original training sets would test how far the cross-domain transfer actually reaches.
Load-bearing premise
The dynamic loss re-weighting and prompt-to-pattern mapping during training will produce a reliable link between prompts and output patterns at inference time.
What would settle it
Generate a series under a volatility constraint on a held-out dataset and measure that the output shows no increase in variation compared with an unconstrained run.
Figures
read the original abstract
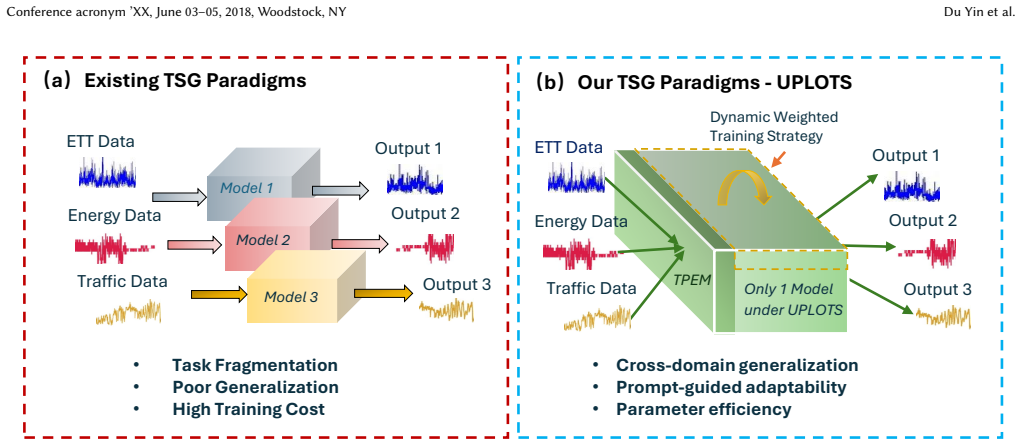
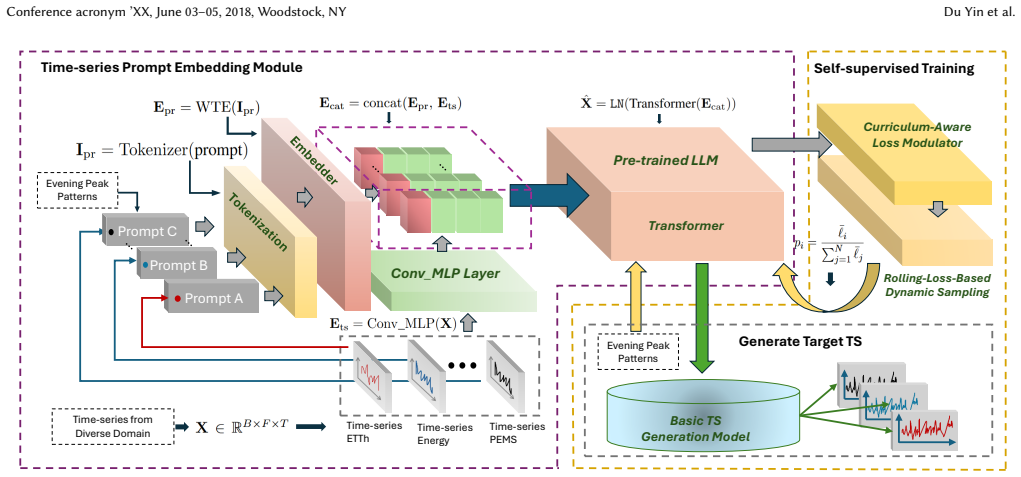
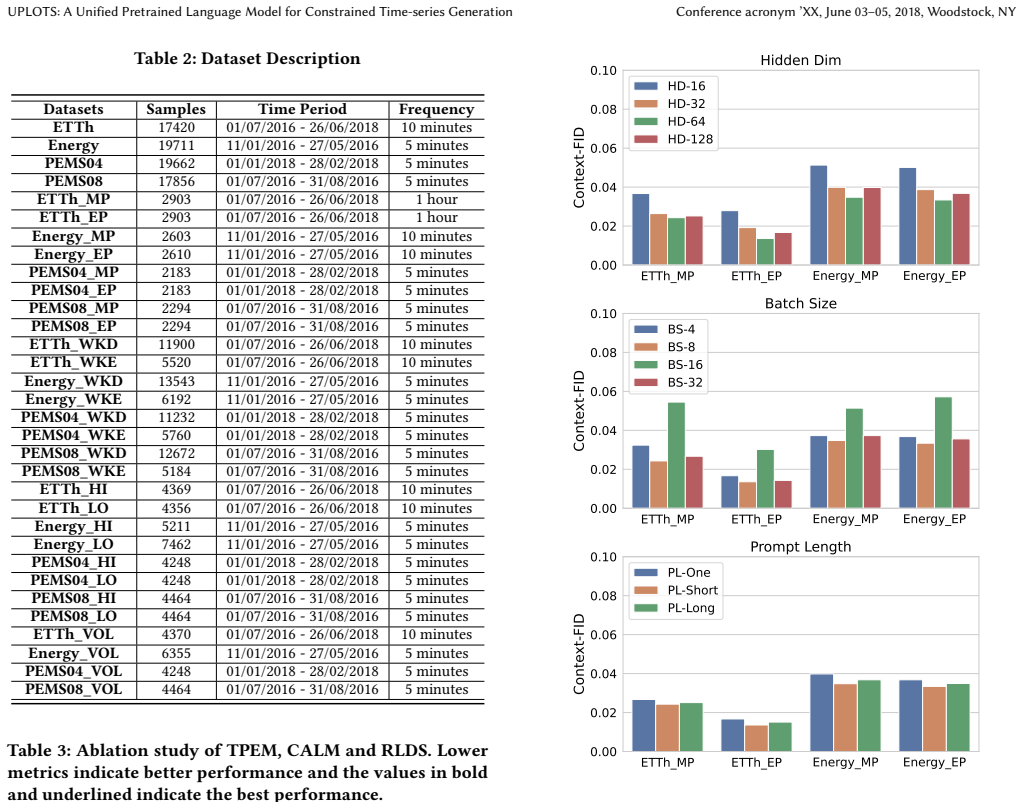
In time-series generation, existing approaches typically handcraft ortrain a separate model for each dataset, which hinders their scalability and fails to leverage shared temporal structures across domains. To address this fragmentation, we propose UPLOTS, a Unified, Prompt-guided Language model framework fOr constrained Time-Series Generation across diverse domains. Instead of building task-specific models, UPLOTS leverages a single pre-trained transformer backbone guided by learned constraint prompts, enabling on-demand generation with precise pattern control. One key innovation is our dynamic multi-dataset loss re-weighting and prompt-to-pattern mapping, which allows UPLOTS to internalize diverse temporal structures during training and conditionally generate them at inference. We evaluate UPLOTS on four real-world benchmarks and multiple constraint settings, including peak-period, calendar, load-level, and volatility patterns. Additional held-out constraint-combination and downstream forecasting experiments further demonstrate that UPLOTS generalizes beyond the original peak-pattern setting and improves data augmentation under scarce real-data regimes. Our code and baselines are available at github repo: https://github.com/cruiseresearchgroup/UPLOTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UPLOTS, a unified prompt-guided pretrained language model for constrained time-series generation across domains. It employs a single transformer backbone with learned constraint prompts and a dynamic multi-dataset loss re-weighting scheme (plus prompt-to-pattern mapping) to internalize diverse temporal structures and enable conditional generation at inference for patterns such as peak-period, calendar, load-level, and volatility. The work claims evaluation on four real-world benchmarks, plus held-out constraint-combination and downstream forecasting experiments demonstrating generalization beyond the training patterns and utility for data augmentation under scarce-data regimes.
Significance. If the quantitative results and ablations support the claims, the contribution would be significant: it offers a scalable alternative to per-dataset model training in time-series generation, potentially improving efficiency and cross-domain transfer while providing controllable generation via prompts. The emphasis on held-out generalization and data-augmentation utility would strengthen its practical value if demonstrated with appropriate controls.
major comments (1)
- [Abstract] Abstract: the manuscript states that UPLOTS is evaluated on four benchmarks and held-out settings with improvements in generalization and data augmentation, yet supplies no quantitative metrics, tables, error bars, or baseline comparisons; without these the central empirical claims cannot be assessed.
minor comments (1)
- The GitHub repository link is given but the manuscript should explicitly state which code artifacts (training scripts, pretrained weights, evaluation pipelines) are released to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their feedback. The single major comment concerns the lack of quantitative support in the abstract for our empirical claims. We address this below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that UPLOTS is evaluated on four benchmarks and held-out settings with improvements in generalization and data augmentation, yet supplies no quantitative metrics, tables, error bars, or baseline comparisons; without these the central empirical claims cannot be assessed.
Authors: We agree that the abstract would be strengthened by including key quantitative results to support the stated claims. In the revised manuscript we will update the abstract to report representative metrics (e.g., generation quality scores, generalization gaps on held-out constraint combinations, and downstream forecasting improvements under data-augmentation regimes) together with brief baseline comparisons and error-bar indications drawn from the experimental tables already present in the full paper. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and high-level description present UPLOTS as a unified transformer backbone with learned constraint prompts and dynamic multi-dataset loss re-weighting, evaluated on external benchmarks. No equations, derivations, or self-citations are supplied that reduce any claimed prediction or result to its own inputs by construction. The central claims rest on empirical generalization and held-out experiments rather than self-referential fitting or imported uniqueness theorems, making the derivation self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beatrice Acciaio, Stephan Eckstein, and Songyan Hou. 2024. Time-Causal VAE: Robust Financial Time Series Generator.arXiv preprint arXiv:2411.02947(2024)
arXiv 2024
-
[2]
Yihao Ang, Qiang Huang, Yifan Bao, Anthony KH Tung, and Zhiyong Huang
-
[3]
TSGBench: Time Series Generation Benchmark.Proceedings of the VLDB Endowment17, 3 (2023), 305–318
2023
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Zhicheng Chen, FENG SHIBO, Zhong Zhang, Xi Xiao, Xingyu Gao, and Peilin Zhao. 2024. SDformer: Similarity-driven Discrete Transformer For Time Series Generation.Advances in Neural Information Processing Systems37 (2024), 132179– 132207
2024
-
[6]
Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel, Aaron C Courville, and Yoshua Bengio. 2015. A recurrent latent variable model for sequential data. Advances in neural information processing systems28 (2015)
2015
-
[7]
Andrea Coletta, Sriram Gopalakrishnan, Daniel Borrajo, and Svitlana Vyetrenko
-
[8]
On the constrained time-series generation problem.Advances in Neural Information Processing Systems36 (2023), 61048–61059
2023
-
[9]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. 2021. Timevae: A variational auto-encoder for multivariate time series generation.arXiv preprint arXiv:2111.08095(2021)
arXiv 2021
-
[10]
Cristóbal Esteban, Stephanie L Hyland, and Gunnar Rätsch. 2017. Real-valued (medical) time series generation with recurrent conditional gans.arXiv preprint arXiv:1706.02633(2017)
Pith/arXiv arXiv 2017
-
[11]
Otto Fabius and Joost R Van Amersfoort. 2014. Variational recurrent auto- encoders.arXiv preprint arXiv:1412.6581(2014)
Pith/arXiv arXiv 2014
-
[12]
Vincent Fortuin, Dmitry Baranchuk, Gunnar Raetsch, and Stephan Mandt. 2020. GP-VAE: Deep Probabilistic Time Series Imputation. InProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (Proceedings of Machine Learning Research, Vol. 108), Silvia Chiappa and Roberto Calandra (Eds.). PMLR, 1651–1661. https://procee...
2020
-
[13]
Marco Fraccaro, Søren Kaae Sønderby, Ulrich Paquet, and Ole Winther. 2016. Sequential neural models with stochastic layers.Advances in neural information processing systems29 (2016)
2016
-
[14]
Asadullah Hill Galib, Pang-Ning Tan, and Lifeng Luo. 2024. FIDE: Frequency- Inflated Conditional Diffusion Model for Extreme-Aware Time Series Generation. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[15]
Hongfan Gao, Wangmeng Shen, Xiangfei Qiu, Ronghui Xu, Jilin Hu, and Bin Yang
-
[16]
Diffimp: Efficient diffusion model for probabilistic time series imputation with bidirectional mamba backbone.arXiv preprint arXiv:2410.13338(2024)
arXiv 2024
-
[17]
Azul Garza, Cristian Challu, and Max Mergenthaler-Canseco. 2023. TimeGPT-1. arXiv preprint arXiv:2310.03589(2023)
arXiv 2023
-
[18]
Yunfeng Ge, Jiawei Li, Yiji Zhao, Haomin Wen, Zhao Li, Meikang Qiu, Hongyan Li, Ming Jin, and Shirui Pan. 2025. T2S: High-resolution Time Series Generation with Text-to-Series Diffusion Models.arXiv preprint arXiv:2505.02417(2025)
arXiv 2025
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[20]
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. 2023. Large language models are zero-shot time series forecasters.Advances in Neural Information Processing Systems36 (2023), 19622–19635
2023
-
[21]
Yu-Hao Huang, Chang Xu, Yueying Wu, Wu-Jun Li, and Jiang Bian. 2025. Timedp: Learning to generate multi-domain time series with domain prompts. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 39. 17520–17527
2025
-
[22]
Paul Jeha, Michael Bohlke-Schneider, Pedro Mercado, Shubham Kapoor, Ra- jbir Singh Nirwan, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. 2022. PSA-GAN: Progressive Self Attention GANs for Synthetic Time Series. InInter- national Conference on Learning Representations
2022
-
[23]
Jinsung Jeon, Jeonghak Kim, Haryong Song, Seunghyeon Cho, and Noseong Park. 2022. GT-GAN: General purpose time series synthesis with generative adversarial networks.Advances in Neural Information Processing Systems35 (2022), 36999–37010
2022
-
[24]
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Zhang, Xiaoming Shi, Pin- Yu Chen, Yuxuan Liang, Yuan-fang Li, Shirui Pan, et al. 2024. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. InInternational Conference on Learning Representations
2024
-
[25]
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. 2021. DiffWave: A Versatile Diffusion Model for Audio Synthesis. InInternational Conference on Learning Representations
2021
-
[26]
Daesoo Lee, Sara Malacarne, and Erlend Aune. 2023. Vector Quantized Time Series Generation with a Bidirectional Prior Model. InInternational Conference on Artificial Intelligence and Statistics. PMLR, 7665–7693
2023
-
[27]
Hao Li, Yu-Hao Huang, Chang Xu, Viktor Schlegel, Ren-He Jiang, Riza Batista- Navarro, Goran Nenadic, and Jiang Bian. 2025. Bridge: Bootstrapping text to control time-series generation via multi-agent iterative optimization and diffusion modelling.arXiv preprint arXiv:2503.02445(2025)
arXiv 2025
-
[28]
Yang Li, Han Meng, Zhenyu Bi, Ingolv T. Urnes, and Haipeng Chen. 2025. Population Aware Diffusion for Time Series Generation.Proceedings of the AAAI Conference on Artificial Intelligence39, 17 (Apr. 2025), 18520–18529. doi:10.1609/aaai.v39i17.34038
-
[29]
Shengsheng Lin, Weiwei Lin, Wentai Wu, Haojun Chen, and Junjie Yang. 2024. SparseTSF: Modeling Long-term Time Series Forecasting with* 1k* Parameters. InInternational Conference on Machine Learning. PMLR, 30211–30226
2024
-
[30]
Xu Liu, Junfeng Hu, Yuan Li, Shizhe Diao, Yuxuan Liang, Bryan Hooi, and Roger Zimmermann. 2024. Unitime: A language-empowered unified model for cross- domain time series forecasting. InProceedings of the ACM Web Conference 2024. 4095–4106
2024
-
[31]
Olof Mogren. 2016. C-RNN-GAN: Continuous recurrent neural networks with adversarial training.arXiv preprint arXiv:1611.09904(2016)
Pith/arXiv arXiv 2016
-
[32]
Abdulmajid Murad and Massimiliano Ruocco. 2025. Synthetic Aircraft Trajectory Generation Using Time-Based VQ-VAE.arXiv preprint arXiv:2504.09101(2025)
arXiv 2025
-
[33]
Ilan Naiman, Nimrod Berman, Itai Pemper, Idan Arbiv, Gal Fadlon, and Omri Azencot. 2024. Utilizing image transforms and diffusion models for generative modeling of short and long time series.Advances in Neural Information Processing Systems37 (2024), 121699–121730
2024
-
[34]
Ilan Naiman, N Benjamin Erichson, Pu Ren, Michael W Mahoney, and Omri Azencot. 2024. GENERATIVE MODELING OF REGULAR AND IRREGULAR TIME SERIES DATA VIA KOOPMAN VAES. In12th International Conference on Learning Representations, ICLR 2024
2024
-
[35]
Yiming Niu, Jinliang Deng, and Yongxin Tong. 2025. PhaseFormer: From Patches to Phases for Efficient and Effective Time Series Forecasting.arXiv preprint arXiv:2510.04134(2025)
arXiv 2025
-
[36]
Chao Pang, Xinzhuo Jiang, Nishanth Parameshwar Pavinkurve, Krishna S Kalluri, Elise L Minto, Jason Patterson, Linying Zhang, George Hripcsak, Gamze Gürsoy, Noémie Elhadad, et al. 2024. CEHR-GPT: Generating electronic health records with chronological patient timelines.arXiv preprint arXiv:2402.04400(2024)
arXiv 2024
-
[37]
Hengzhi Pei, Kan Ren, Yuqing Yang, Chang Liu, Tao Qin, and Dongsheng Li
-
[38]
In2021 IEEE International Conference on Data Mining (ICDM)
Towards generating real-world time series data. In2021 IEEE International Conference on Data Mining (ICDM). IEEE, 469–478
-
[39]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners.Ope- nAI Blog1, 8 (2019). https://cdn.openai.com/better-language-models/language_ models_are_unsupervised_multitask_learners.pdf
2019
-
[40]
Aditya Shankar, Lydia Y Chen, Arie van Deursen, and Rihan Hai. 2025. WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models.arXiv preprint arXiv:2503.06231(2025). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Du Yin et al
arXiv 2025
-
[41]
Namjoon Suh, Yuning Yang, Din-Yin Hsieh, Qitong Luan, Shirong Xu, Shix- iang Zhu, and Guang Cheng. 2024. TimeAutoDiff: Combining Autoencoder and Diffusion model for time series tabular data synthesizing.arXiv preprint arXiv:2406.16028(2024)
arXiv 2024
-
[42]
Chenxi Sun, Hongyan Li, Yaliang Li, and Shenda Hong. 2024. TEST: Text Pro- totype Aligned Embedding to Activate LLM’s Ability for Time Series. InThe Twelfth International Conference on Learning Representations
2024
-
[43]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
Pith/arXiv arXiv 2023
-
[44]
Tianlin Xu, Li Kevin Wenliang, Michael Munn, and Beatrice Acciaio. 2020. Cot- gan: Generating sequential data via causal optimal transport.Advances in neural information processing systems33 (2020), 8798–8809
2020
-
[45]
Tijin Yan, Hengheng Gong, He Yongping, Yufeng Zhan, and Yuanqing Xia. 2024. Probabilistic time series modeling with decomposable denoising diffusion model. InForty-first International Conference on Machine Learning
2024
-
[46]
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. 2019. Time-series generative adversarial networks.Advances in neural information processing systems32 (2019)
2019
-
[47]
Xinyu Yuan and Yan Qiao. 2024. Diffusion-TS: Interpretable Diffusion for General Time Series Generation. InThe Twelfth International Conference on Learning Representations
2024
-
[48]
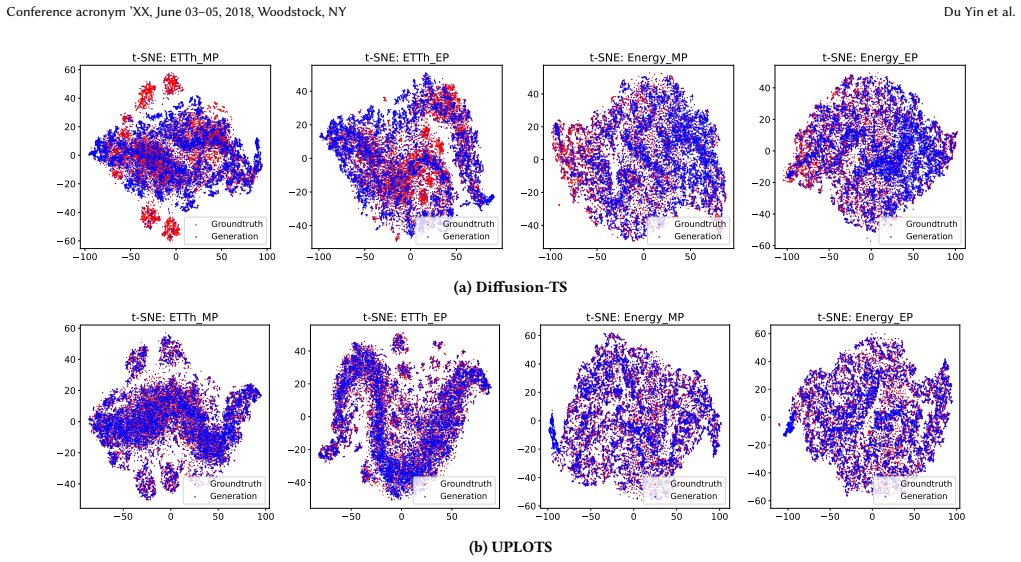
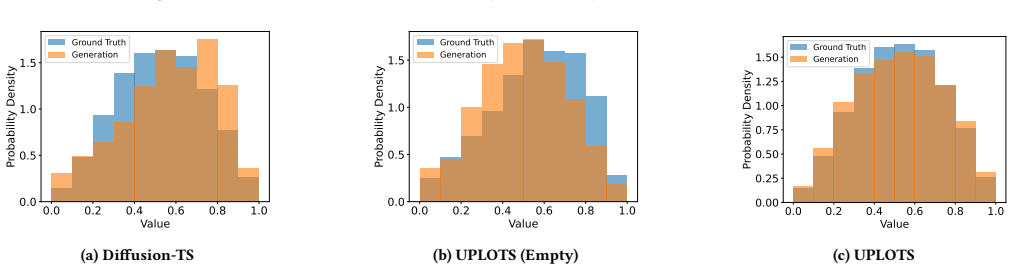
Tian Zhou, Peisong Niu, Liang Sun, Rong Jin, et al . 2023. One fits all: Power general time series analysis by pretrained lm.Advances in neural information processing systems36 (2023), 43322–43355. A Appendix A.1 Results To complement the main results, the Appendix reports additional quantitative comparisons under alternative generation lengths and evalua...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.