How Post-Training Shapes Biological Reasoning Models
Pith reviewed 2026-07-01 07:46 UTC · model grok-4.3
The pith
Biological reasoning models improve most when post-training stages are composed specifically rather than scaled uniformly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
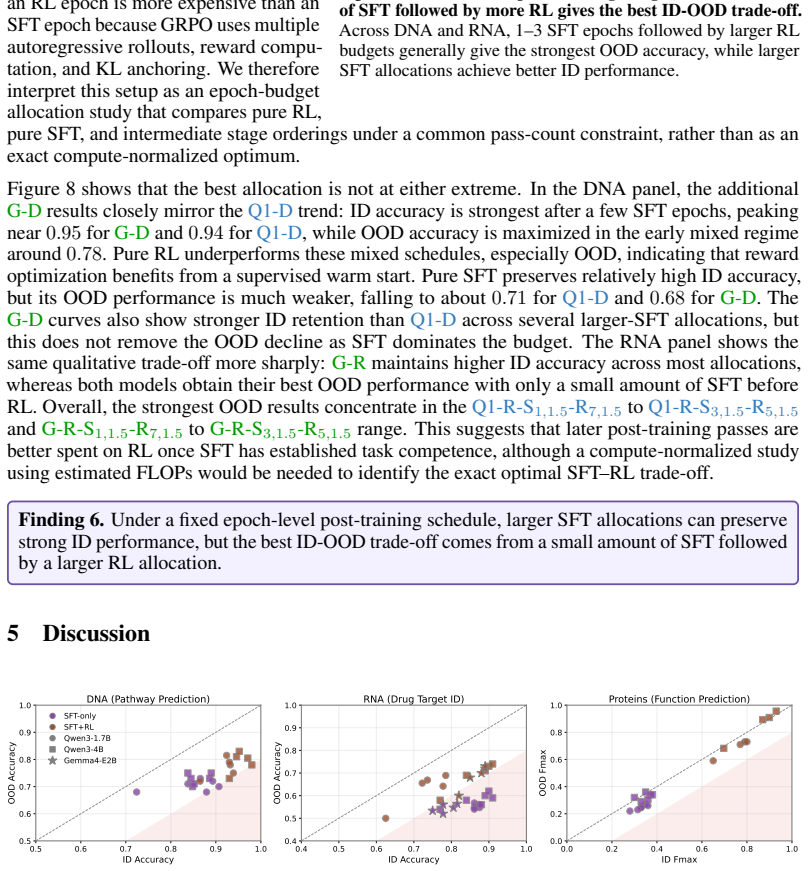
Biological reasoning does not improve monotonically with additional supervision or compute. Instead, performance depends on how training stages are composed. Under fixed post-training budgets, the strongest ID-OOD trade-off comes from brief SFT, larger RL allocations, and asymmetric adaptation capacity across stages.
What carries the argument
Controlled variation of backbone, continued pre-training, supervised fine-tuning, and reinforcement learning while separately tracking in-domain and out-of-domain performance on genomics, transcriptomics, and protein tasks.
If this is right
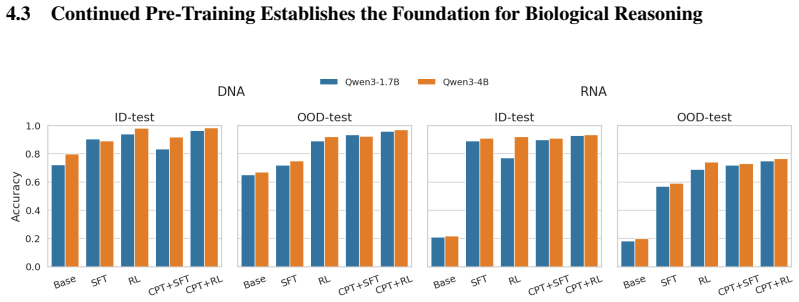
- Continued pre-training improves downstream performance by aligning models with biological language.
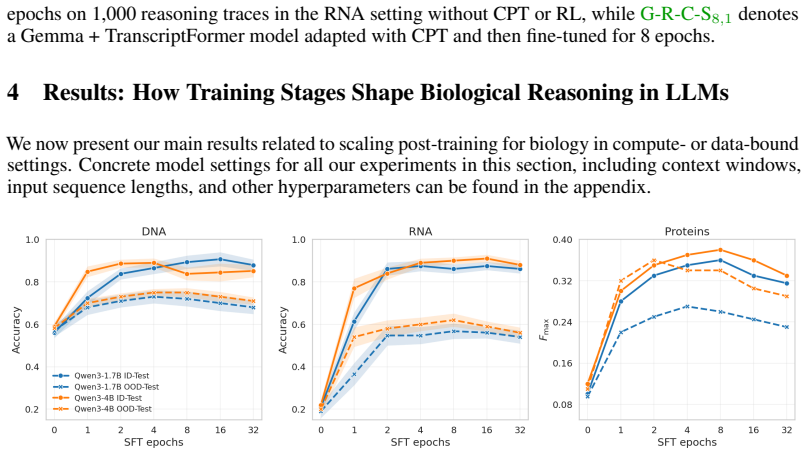
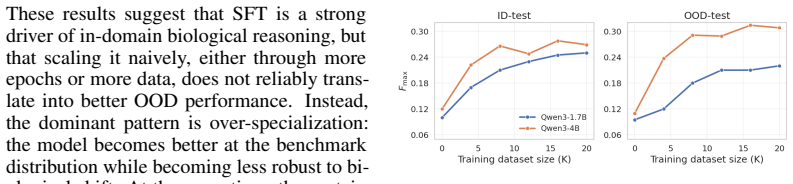
- Supervised fine-tuning consistently increases in-domain performance but causes out-of-domain performance to peak early and decline.
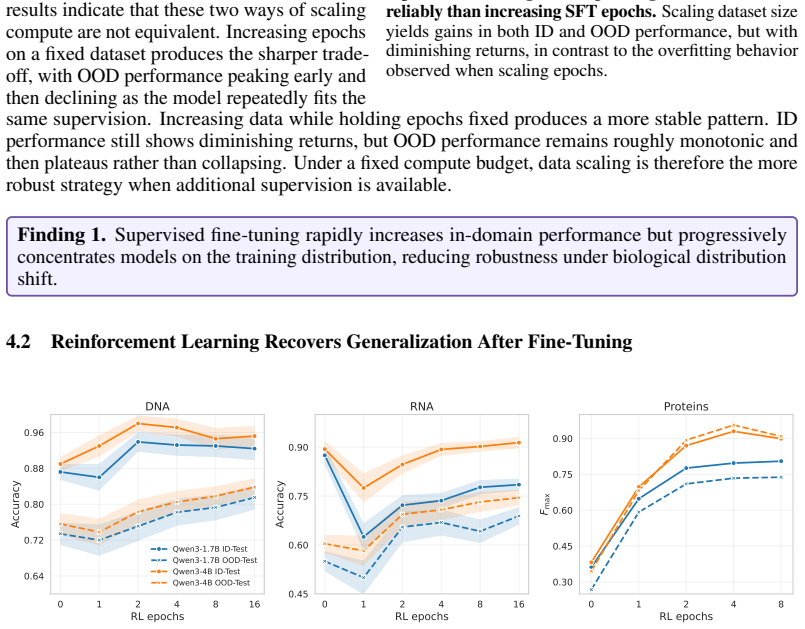
- Reinforcement learning applied to strong supervised fine-tuning checkpoints with aligned rewards improves out-of-domain performance and partially recovers generalization.
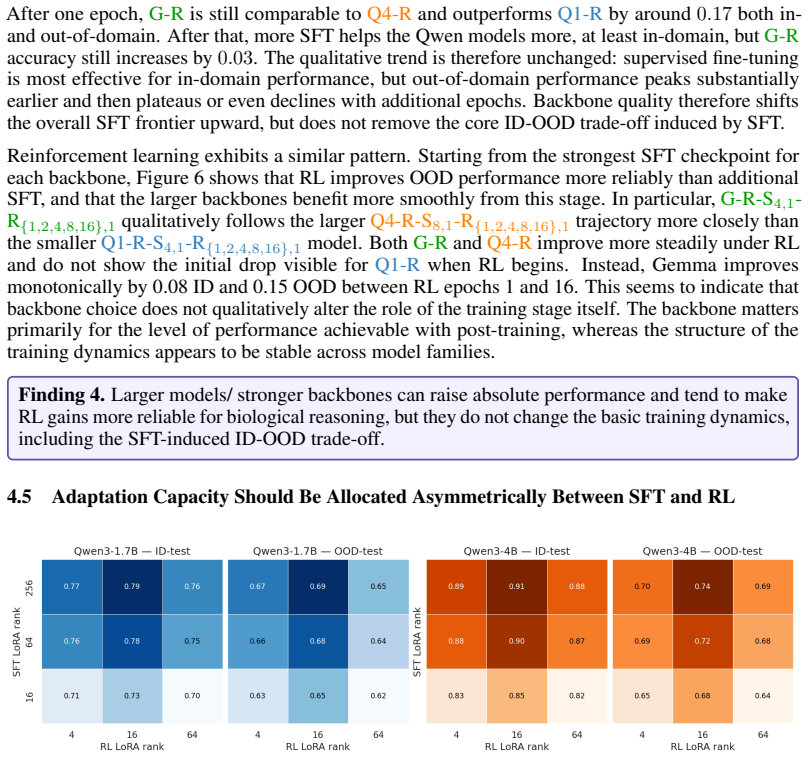
- Under fixed post-training budgets the strongest in-domain to out-of-domain trade-off arises from brief supervised fine-tuning, larger reinforcement learning allocations, and asymmetric adaptation capacity across stages.
Where Pith is reading between the lines
- Stage-ordering effects observed here may appear when building reasoning models for other scientific domains such as chemistry.
- Dynamic switching from supervised fine-tuning to reinforcement learning once out-of-domain metrics stop rising could be tested on models of different sizes.
- Allocating more parameter change in later stages than earlier ones might improve results in other multimodal scientific foundation models.
Load-bearing premise
The chosen in-domain and out-of-domain tasks and performance metrics accurately reflect true biological reasoning capabilities and generalization without being confounded by the specific data distributions, task designs, or evaluation protocols used in the controlled experiments.
What would settle it
Training additional models with prolonged supervised fine-tuning past the observed peak and checking whether out-of-domain scores continue to decline or instead stabilize or recover.
Figures


read the original abstract
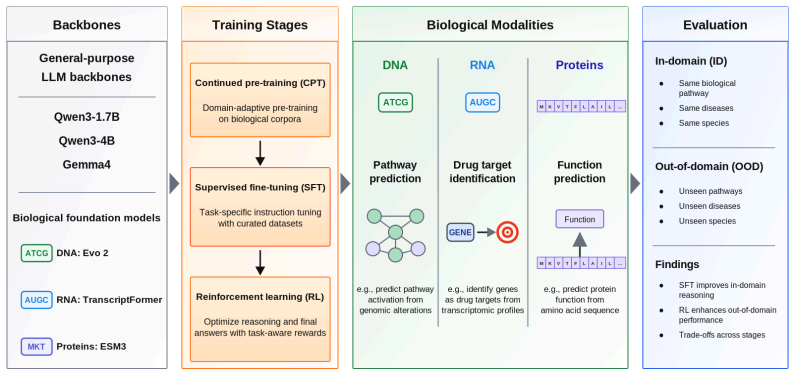
Scientific reasoning models for biology combine language models with foundation models trained on multimodal biological data, including DNA, RNA, and proteins. These models are built through post-training, yet how each stage shapes reasoning and generalization remains poorly understood. We study when post-training improves performance and when it induces over-specialization. Across genomics, transcriptomics, and proteins, we train and evaluate more than 100 biological reasoning models under controlled variation in backbone, continued pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL), measuring both in-domain (ID) and out-of-domain (OOD) performance. We find that each post-training stage reshapes generalization in a distinct way rather than contributing uniform gains. CPT improves downstream performance by aligning models with biological language. SFT consistently increases ID performance but causes OOD performance to peak early and decline as models fit the training distribution. RL, when applied to strong SFT checkpoints with aligned rewards, improves OOD performance and partially recovers generalization. These results show that biological reasoning does not improve monotonically with additional supervision or compute. Instead, performance depends on how training stages are composed. Under fixed post-training budgets, the strongest ID-OOD trade-off comes from brief SFT, larger RL allocations, and asymmetric adaptation capacity across stages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that post-training stages (CPT, SFT, RL) for biological reasoning models (combining LMs with multimodal bio foundation models on DNA/RNA/proteins) reshape ID and OOD generalization distinctly rather than adding uniform gains. CPT aligns models with biological language; SFT boosts ID but causes OOD to peak then decline; RL on strong SFT checkpoints with aligned rewards improves OOD and recovers generalization. Biological reasoning is non-monotonic with supervision/compute; under fixed budgets, best ID-OOD trade-offs arise from brief SFT, larger RL allocations, and asymmetric adaptation. This is supported by controlled experiments training/evaluating >100 models across genomics, transcriptomics, and proteins with variation in backbones and stages.
Significance. If the empirical results hold, the work is significant for highlighting that post-training effects on generalization in biological reasoning models are stage-specific and non-monotonic, rather than simply scaling with more data or compute. This could inform practical training strategies for such models. The scale of controlled experiments across >100 models with explicit stage variations is a clear strength, providing a systematic empirical basis for the claims about composition effects.
major comments (1)
- [Abstract] Abstract and implied experimental design: The central claims—that each stage reshapes generalization distinctly, SFT induces OOD peak-and-decline, and optimal trade-offs come from brief SFT + larger RL—rest entirely on the chosen ID/OOD tasks and metrics faithfully measuring biological reasoning and generalization. No details are provided on how ID/OOD splits were constructed, whether they share latent distributional features, or how metrics were validated to isolate multi-step inference rather than surface pattern matching. This is load-bearing, as confounds in task design or data distributions could artifactually produce the reported non-monotonicity and stage-composition effects.
minor comments (2)
- [Abstract] The abstract and results lack reporting of error bars, exact dataset sizes, full results tables, and precise metric definitions, which are needed to assess reproducibility and support the claims about distinct per-stage effects.
- Notation for ID/OOD performance and stage allocations could be clarified with explicit definitions or a table summarizing the controlled variations across the >100 models.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and the scale of our controlled experiments. We address the major comment on task design and experimental details below, and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and implied experimental design: The central claims—that each stage reshapes generalization distinctly, SFT induces OOD peak-and-decline, and optimal trade-offs come from brief SFT + larger RL—rest entirely on the chosen ID/OOD tasks and metrics faithfully measuring biological reasoning and generalization. No details are provided on how ID/OOD splits were constructed, whether they share latent distributional features, or how metrics were validated to isolate multi-step inference rather than surface pattern matching. This is load-bearing, as confounds in task design or data distributions could artifactually produce the reported non-monotonicity and stage-composition effects.
Authors: We agree this is a substantive point and that the manuscript would benefit from expanded details on task construction to rule out potential confounds. In the revision, we will add a new subsection (Section 3.2) and appendix with: explicit descriptions of ID/OOD split construction for each domain (e.g., holding out specific species, sequence motifs, or functional categories to enforce distributional shift); quantitative checks confirming minimal overlap in latent features (via embedding similarity and motif analysis); and metric validation steps including ablation experiments and expert review to demonstrate that tasks require multi-step inference beyond surface patterns. These additions will directly support the non-monotonicity claims. revision: yes
Circularity Check
No circularity: purely empirical measurements of post-training effects
full rationale
The paper reports results from training and evaluating >100 models under controlled variations in CPT, SFT, and RL stages, directly measuring ID and OOD performance on genomics/transcriptomics/protein tasks. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises exist; the central claims about non-monotonicity and stage-composition effects follow immediately from the reported experimental outcomes without reduction to inputs by construction. The work is self-contained empirical science with no self-definitional, uniqueness-imported, or ansatz-smuggled steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The in-domain and out-of-domain performance metrics validly measure biological reasoning ability and generalization.
Reference graph
Works this paper leans on
-
[1]
Adibvafa Fallahpour, Andrew Magnuson, Purav Gupta, Shihao Ma, Jack Naimer, Arnav Shah, Haonan Duan, Omar Ibrahim, Hani Goodarzi, Chris J Maddison, et al. Bioreason: Incentivizing 10 multimodal biological reasoning within a dna-llm model.arXiv preprint arXiv:2505.23579, 2025
-
[2]
rbio1-training scientific reasoning llms with biological world models as soft verifiers.bioRxiv, pages 2025–08, 2025
Ana-Maria Istrate, Fausto Milletari, Fabrizio Castrotorres, Jakub M Tomczak, Michaela Torkar, Donghui Li, and Theofanis Karaletsos. rbio1-training scientific reasoning llms with biological world models as soft verifiers.bioRxiv, pages 2025–08, 2025
2025
-
[3]
Bioreason-pro: Advancing protein function prediction with multimodal biological reasoning.bioRxiv, pages 2026–03, 2026
Adibvafa Fallahpour, Arman Seyed-Ahmadi, Parsa Idehpour, Omar Ibrahim, Purav Gupta, Jack Naimer, Kevin Zhu, Arnav Shah, Shihao Ma, Abhinav Adduri, et al. Bioreason-pro: Advancing protein function prediction with multimodal biological reasoning.bioRxiv, pages 2026–03, 2026
2026
-
[4]
Evolm: In search of lost language model training dynamics
Zhenting Qi, Fan Nie, Alexandre Alahi, James Zou, Himabindu Lakkaraju, Yilun Du, Eric P Xing, Sham M Kakade, and Hanlin Zhang. Evolm: In search of lost language model training dynamics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[5]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[6]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, et al. Reinforcement learning for reasoning in large language models with one training example.arXiv:2504.20571, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? NeurIPS, 2025
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? NeurIPS, 2025
2025
-
[8]
arXiv preprint arXiv:2507.16812 , year=
Run-Ze Fan, Zengzhi Wang, and Pengfei Liu. Megascience: Pushing the frontiers of post- training datasets for science reasoning.arXiv:2507.16812, 2025
-
[9]
OpenThoughts: data recipes for reasoning models.ICLR, 2026
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. OpenThoughts: data recipes for reasoning models.ICLR, 2026
2026
-
[10]
Scaling large language models for next-generation single-cell analysis.BioRxiv, pages 2025–04, 2026
Syed Asad Rizvi, Daniel Levine, Aakash Patel, Shiyang Zhang, Eric Wang, Curtis Jamison Perry, Ivan Vrkic, Nicole Mayerli Constante, Zirui Fu, Sizhuang He, et al. Scaling large language models for next-generation single-cell analysis.BioRxiv, pages 2025–04, 2026
2025
-
[11]
Chang Yu, Siyuan Li, Zicheng Liu, Jingbo Zhou, Xianglong Guo, Kai Yu, Yuqing Zhou, Ken Li, Zelin Zang, Zhen Lei, and Stan Z. Li. CDBridge: A cross-omics post-training bridge strategy for context-aware biological modeling. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=Hk4Fb6kaYF
2026
-
[12]
Unleashing scientific reasoning for bio-experimental protocol generation via structured component-based reward mechanism.ICLR, 2026
Haoran Sun, Yankai Jiang, Zhenyu Tang, Yaning Pan, Shuang Gu, Zekai Lin, Lilong Wang, Wenjie Lou, Lei Liu, Lei Bai, et al. Unleashing scientific reasoning for bio-experimental protocol generation via structured component-based reward mechanism.ICLR, 2026
2026
-
[13]
Sci-verifier: Scientific verifier with thinking.ICLR, 2026
Shenghe Zheng, Chenyu Huang, Fangchen Yu, Junchi Yao, Jingqi Ye, Tao Chen, Yun Luo, Ning Ding, Lei Bai, Ganqu Cui, et al. Sci-verifier: Scientific verifier with thinking.ICLR, 2026
2026
-
[14]
Cellduality: Un- locking biological reasoning in LLMs with self-supervised RLVR
Yuhang Chen, Zhen Tan, Ruichen Zhang, Mufan Qiu, and Tianlong Chen. Cellduality: Un- locking biological reasoning in LLMs with self-supervised RLVR. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026. URL https://openreview.net/forum?id= I4meJN28Ol
2026
-
[15]
VCWorld: a biological world model for virtual cell simulation.ICLR, 2026
Zhijian Wei, Runze Ma, Zichen Wang, Zhongmin Li, Shuotong Song, and Shuangjia Zheng. VCWorld: a biological world model for virtual cell simulation.ICLR, 2026
2026
-
[16]
Helix: Evolutionary reinforcement learning for open-ended scientific problem solving.ICLR, 2026
Chang Su, Zhongkai Hao, Zhizhou Zhang, Zeyu Xia, Youjia Wu, Hang Su, and Jun Zhu. Helix: Evolutionary reinforcement learning for open-ended scientific problem solving.ICLR, 2026. 11
2026
-
[17]
Reshaping reasoning in llms: A theoretical analysis of rl training dynamics through pattern selection.ICLR, 2026
Xingwu Chen, Tianle Li, and Difan Zou. Reshaping reasoning in llms: A theoretical analysis of rl training dynamics through pattern selection.ICLR, 2026
2026
-
[18]
Training dynamics impact post- training quantization robustness.ICLR, 2026
Albert Catalan-Tatjer, Niccolò Ajroldi, and Jonas Geiping. Training dynamics impact post- training quantization robustness.ICLR, 2026
2026
-
[19]
The coverage principle: How pre-training enables post-training.ICLR, 2026
Fan Chen, Audrey Huang, Noah Golowich, Sadhika Malladi, Adam Block, Jordan T Ash, Akshay Krishnamurthy, and Dylan J Foster. The coverage principle: How pre-training enables post-training.ICLR, 2026
2026
-
[20]
Benchmarking algorithms for generalizable single-cell perturbation response prediction.Nature Methods, 23(2):451–464, 2026
Zhiting Wei, Yiheng Wang, Yicheng Gao, Shuguang Wang, Ping Li, Duanmiao Si, Yuli Gao, Siqi Wu, Danlu Li, Kejing Dong, et al. Benchmarking algorithms for generalizable single-cell perturbation response prediction.Nature Methods, 23(2):451–464, 2026
2026
-
[21]
A fully automated benchmarking suite to compare macromolecular complexes.Nature Methods, 23(2):387–394, 2026
Gabriel Studer, Xavier Robin, Stefan Bienert, Janani Durairaj, Peter Škrinjar, Gerardo Tauriello, Andrew Mark Waterhouse, and Torsten Schwede. A fully automated benchmarking suite to compare macromolecular complexes.Nature Methods, 23(2):387–394, 2026
2026
-
[22]
PLINDER: the protein-ligand interactions dataset and evaluation resource.BioRxiv, pages 2024–07, 2024
Janani Durairaj, Yusuf Adeshina, Zhonglin Cao, Xuejin Zhang, Vladas Oleinikovas, Thomas Duignan, Zachary McClure, Xavier Robin, Gabriel Studer, Daniel Kovtun, et al. PLINDER: the protein-ligand interactions dataset and evaluation resource.BioRxiv, pages 2024–07, 2024
2024
-
[23]
ProCyon: a multimodal foundation model for protein phenotypes.BioRxiv, pages 2024–12, 2025
Owen Queen, Yepeng Huang, Robert Calef, Valentina Giunchiglia, Tianlong Chen, George Dasoulas, LeAnn Tai, Gianmarco Abbadessa, Owain Howell, Michelle M Li, et al. ProCyon: a multimodal foundation model for protein phenotypes.BioRxiv, pages 2024–12, 2025
2024
-
[24]
Evaluating generalizability of artificial intelligence models for molecular datasets
Yasha Ektefaie, Andrew Shen, Daria Bykova, Maximillian G Marin, Marinka Zitnik, and Maha Farhat. Evaluating generalizability of artificial intelligence models for molecular datasets. Nature Machine Intelligence, 6(12):1512–1524, 2024
2024
-
[25]
Zero-shot evaluation reveals limitations of single-cell foundation models.Genome Biology, 26(1):101, 2025
Kasia Z Kedzierska, Lorin Crawford, Ava P Amini, and Alex X Lu. Zero-shot evaluation reveals limitations of single-cell foundation models.Genome Biology, 26(1):101, 2025
2025
-
[26]
Deep-learning-based gene perturbation effect prediction does not yet outperform simple linear baselines.Nature Methods, 22(8):1657–1661, 2025
Constantin Ahlmann-Eltze, Wolfgang Huber, and Simon Anders. Deep-learning-based gene perturbation effect prediction does not yet outperform simple linear baselines.Nature Methods, 22(8):1657–1661, 2025
2025
-
[27]
LoongRL: reinforcement learning for advanced reasoning over long contexts.ICLR, 2026
Siyuan Wang, Gaokai Zhang, Li Lyna Zhang, Ning Shang, Fan Yang, Dongyao Chen, and Mao Yang. LoongRL: reinforcement learning for advanced reasoning over long contexts.ICLR, 2026
2026
-
[28]
The art of scaling reinforcement learning compute for llms.ICLR, 2026
Devvrit Khatri, Lovish Madaan, Rishabh Tiwari, Rachit Bansal, Sai Surya Duvvuri, Manzil Zaheer, Inderjit S Dhillon, David Brandfonbrener, and Rishabh Agarwal. The art of scaling reinforcement learning compute for llms.ICLR, 2026
2026
-
[29]
Rethinking LLM reasoning: From explicit trajectories to latent representations
Cong Jiang, Xiaofeng Zhang, Fangzhi Zhu, XiaoWei Chen, Junxiong Zhu, and Zheng Zhang. Rethinking LLM reasoning: From explicit trajectories to latent representations. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=CbK7lYbmv8
2026
-
[30]
CoT-Evo: evolutionary distillation of chain-of-thought for scientific reasoning.ICLR, 2026
Kehua Feng, Keyan Ding, Zhihui Zhu, Lei Liang, Qiang Zhang, and Huajun Chen. CoT-Evo: evolutionary distillation of chain-of-thought for scientific reasoning.ICLR, 2026
2026
-
[31]
scPilot: Large language model reasoning toward automated single-cell analysis and discovery.NeurIPS, 2025
Yiming Gao, Zhen Wang, Jefferson Chen, Mark Antkowiak, Mengzhou Hu, JungHo Kong, Dexter Pratt, Jieyuan Liu, Enze Ma, Zhiting Hu, et al. scPilot: Large language model reasoning toward automated single-cell analysis and discovery.NeurIPS, 2025
2025
-
[32]
AI-researcher: autonomous scientific innovation.NeurIPS, 2025
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. AI-researcher: autonomous scientific innovation.NeurIPS, 2025
2025
-
[33]
Training a scientific reasoning model for chemistry.NeurIPS, 2025
Siddharth M Narayanan, James D Braza, Ryan-Rhys Griffiths, Albert Bou, Geemi Wellawatte, Mayk Caldas Ramos, Ludovico Mitchener, Samuel G Rodriques, and Andrew D White. Training a scientific reasoning model for chemistry.NeurIPS, 2025. 12
2025
-
[34]
Language models for biological research: a primer.Nature Methods, 21(8):1422–1429, 2024
Elana Simon, Kyle Swanson, and James Zou. Language models for biological research: a primer.Nature Methods, 21(8):1422–1429, 2024
2024
-
[35]
Dnabert: pre-trained bidirectional encoder representations from transformers model for dna-language in genome.Bioinformatics, 37(15):2112–2120, 2021
Yanrong Ji, Zhihan Zhou, Han Liu, and Ramana V Davuluri. Dnabert: pre-trained bidirectional encoder representations from transformers model for dna-language in genome.Bioinformatics, 37(15):2112–2120, 2021
2021
-
[36]
Zhihan Zhou, Yanrong Ji, Weijian Li, Pratik Dutta, Ramana Davuluri, and Han Liu. Dnabert- 2: Efficient foundation model and benchmark for multi-species genome.arXiv preprint arXiv:2306.15006, 2023
-
[37]
Sequence modeling and design from molecular to genome scale with evo.Science, 386(6723):eado9336, 2024
Eric Nguyen, Michael Poli, Matthew G Durrant, Brian Kang, Dhruva Katrekar, David B Li, Liam J Bartie, Armin W Thomas, Samuel H King, Garyk Brixi, et al. Sequence modeling and design from molecular to genome scale with evo.Science, 386(6723):eado9336, 2024
2024
-
[38]
Genome modelling and design across all domains of life with evo 2.Nature, pages 1–13, 2026
Garyk Brixi, Matthew G Durrant, Jerome Ku, Mohsen Naghipourfar, Michael Poli, Gwanggyu Sun, Greg Brockman, Daniel Chang, Alison Fanton, Gabriel A Gonzalez, et al. Genome modelling and design across all domains of life with evo 2.Nature, pages 1–13, 2026
2026
-
[39]
Nucleotide transformer: building and evaluating robust foundation models for human genomics.Nature Methods, 22(2):287–297, 2025
Hugo Dalla-Torre, Liam Gonzalez, Javier Mendoza-Revilla, Nicolas Lopez Carranza, Adam Henryk Grzywaczewski, Francesco Oteri, Christian Dallago, Evan Trop, Bernardo P De Almeida, Hassan Sirelkhatim, et al. Nucleotide transformer: building and evaluating robust foundation models for human genomics.Nature Methods, 22(2):287–297, 2025
2025
-
[40]
Alphagenome: advancing regulatory variant effect prediction with a unified dna sequence model.BioRxiv, pages 2025–06, 2025
Žiga Avsec, Natasha Latysheva, Jun Cheng, Guido Novati, Kyle R Taylor, Tom Ward, Clare Bycroft, Lauren Nicolaisen, Eirini Arvaniti, Joshua Pan, et al. Alphagenome: advancing regulatory variant effect prediction with a unified dna sequence model.BioRxiv, pages 2025–06, 2025
2025
-
[41]
The omg dataset: An open metagenomic corpus for mixed-modality genomic language modeling.bioRxiv, pages 2024–08, 2024
Andre Cornman, Jacob West-Roberts, Antonio Pedro Camargo, Simon Roux, Martin Bera- cochea, Milot Mirdita, Sergey Ovchinnikov, and Yunha Hwang. The omg dataset: An open metagenomic corpus for mixed-modality genomic language modeling.bioRxiv, pages 2024–08, 2024
2024
-
[42]
PhageBench: Can LLMs Understand Raw Bacteriophage Genomes?
Yusen Hou, Weicai Long, Haitao Hu, Houcheng Su, Junning Feng, and Yanlin Zhang. Phagebench: Can llms understand raw bacteriophage genomes?arXiv preprint arXiv:2604.05775, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Orthrus: toward evolutionary and functional rna foundation models.Nature Methods, pages 1–11, 2026
Philip Fradkin, Ruian “Ian” Shi, Taykhoom Dalal, Keren Isaev, Brendan J Frey, Leo J Lee, Quaid Morris, and Bo Wang. Orthrus: toward evolutionary and functional rna foundation models.Nature Methods, pages 1–11, 2026
2026
-
[44]
Jiayang Chen, Zhihang Hu, Siqi Sun, Qingxiong Tan, Yixuan Wang, Qinze Yu, Licheng Zong, Liang Hong, Jin Xiao, Tao Shen, et al. Interpretable rna foundation model from unannotated data for highly accurate rna structure and function predictions.arXiv preprint arXiv:2204.00300, 2022
-
[45]
A cross-species generative cell atlas across 1.5 billion years of evolution: The transcriptformer single-cell model.bioRxiv, pages 2025–04, 2025
James D Pearce, Sara E Simmonds, Gita Mahmoudabadi, Lakshmi Krishnan, Giovanni Palla, Ana-Maria Istrate, Alexander Tarashansky, Benjamin Nelson, Omar Valenzuela, Donghui Li, et al. A cross-species generative cell atlas across 1.5 billion years of evolution: The transcriptformer single-cell model.bioRxiv, pages 2025–04, 2025
2025
-
[46]
scgpt: toward building a foundation model for single-cell multi-omics using generative ai
Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. scgpt: toward building a foundation model for single-cell multi-omics using generative ai. Nature methods, 21(8):1470–1480, 2024
2024
-
[47]
Transfer learning enables predictions in network biology.Nature, 618(7965):616–624, 2023
Christina V Theodoris, Ling Xiao, Anant Chopra, Mark D Chaffin, Zeina R Al Sayed, Matthew C Hill, Helene Mantineo, Elizabeth M Brydon, Zexian Zeng, X Shirley Liu, et al. Transfer learning enables predictions in network biology.Nature, 618(7965):616–624, 2023
2023
-
[48]
Predicting cellular responses to perturbation across diverse contexts with state.BioRxiv, pages 2025–06, 2025
Abhinav K Adduri, Dhruv Gautam, Beatrice Bevilacqua, Alishba Imran, Rohan Shah, Mohsen Naghipourfar, Noam Teyssier, Rajesh Ilango, Sanjay Nagaraj, Mingze Dong, et al. Predicting cellular responses to perturbation across diverse contexts with state.BioRxiv, pages 2025–06, 2025. 13
2025
-
[49]
Large-scale foundation model on single-cell transcriptomics.Nature methods, 21(8):1481–1491, 2024
Minsheng Hao, Jing Gong, Xin Zeng, Chiming Liu, Yucheng Guo, Xingyi Cheng, Taifeng Wang, Jianzhu Ma, Xuegong Zhang, and Le Song. Large-scale foundation model on single-cell transcriptomics.Nature methods, 21(8):1481–1491, 2024
2024
-
[50]
scgenept: Is language all you need for modeling single-cell perturbations?bioRxiv, pages 2024–10, 2024
Ana-Maria Istrate, Donghui Li, and Theofanis Karaletsos. scgenept: Is language all you need for modeling single-cell perturbations?bioRxiv, pages 2024–10, 2024
2024
-
[51]
Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, et al. Evolutionary-scale prediction of atomic-level protein structure with a language model.Science, 379(6637):1123–1130, 2023
2023
-
[52]
Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
Thomas Hayes, Roshan Rao, Halil Akin, Nicholas J Sofroniew, Deniz Oktay, Zeming Lin, Robert Verkuil, Vincent Q Tran, Jonathan Deaton, Marius Wiggert, et al. Simulating 500 million years of evolution with a language model.Science, 387(6736):850–858, 2025
2025
-
[53]
Progen2: exploring the boundaries of protein language models.Cell systems, 14(11):968–978, 2023
Erik Nijkamp, Jeffrey A Ruffolo, Eli N Weinstein, Nikhil Naik, and Ali Madani. Progen2: exploring the boundaries of protein language models.Cell systems, 14(11):968–978, 2023
2023
-
[54]
Unified rational protein engineering with sequence-based deep representation learning
Ethan C Alley, Grigory Khimulya, Surojit Biswas, Mohammed AlQuraishi, and George M Church. Unified rational protein engineering with sequence-based deep representation learning. Nature methods, 16(12):1315–1322, 2019
2019
-
[55]
Multimodal learning enables chat-based exploration of single-cell data.Nature Biotechnology, pages 1–11, 2025
Moritz Schaefer, Peter Peneder, Daniel Malzl, Salvo Danilo Lombardo, Mihaela Peycheva, Jake Burton, Anna Hakobyan, Varun Sharma, Thomas Krausgruber, Celine Sin, et al. Multimodal learning enables chat-based exploration of single-cell data.Nature Biotechnology, pages 1–11, 2025
2025
-
[56]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[57]
D-cpt law: Domain-specific continual pre-training scaling law for large language models.Advances in Neural Information Processing Systems, 37:90318–90354, 2024
Haoran Que, Jiaheng Liu, Ge Zhang, Chenchen Zhang, Xingwei Qu, Yinghao Ma, Feiyu Duan, Zhiqi Bai, Jiakai Wang, Yuanxing Zhang, et al. D-cpt law: Domain-specific continual pre-training scaling law for large language models.Advances in Neural Information Processing Systems, 37:90318–90354, 2024
2024
-
[58]
Understanding the effects of RLHF on LLM generalisation and diversity
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of RLHF on LLM generalisation and diversity. InInternational Conference on Learning Representations, 2024
2024
-
[59]
Don’t stop pretraining: Adapt language models to domains and tasks
Suchin Gururangan, Ana Marasovi´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 8342–8360, 2020
2020
-
[60]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[61]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[62]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, 2023
2023
-
[63]
When scaling meets LLM finetuning: The effect of data, model and finetuning method
Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. When scaling meets LLM finetuning: The effect of data, model and finetuning method. InInternational Conference on Learning Representations, 2024. 14
2024
-
[64]
arXiv preprint arXiv:2308.04014 , year=
Kshitij Gupta, Dan Iter, and Daniel Hershcovich. Continual pre-training of large language models: How to (re)warm your model?arXiv preprint arXiv:2308.04014, 2023
-
[65]
arXiv preprint arXiv:2403.08763 , year=
Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats L Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, and Irina Rish. Simple and scalable strategies to continually pre-train large language models.arXiv preprint arXiv:2403.08763, 2024
-
[66]
arXiv preprint arXiv:2407.07263 , year=
Jupinder Parmar, Sanjev Prabhu, Suchin Gururangan, Hailey Awadalla, Shaden Smith, and Niklas Muennighoff. Reuse, don’t retrain: A recipe for continued pretraining of language models.arXiv preprint arXiv:2407.07263, 2024
-
[67]
Continual pre-training of language models
Zixuan Ke, Yijia Shao, Haowei Lin, Tatsuya Konishi, Gyuhak Kim, and Bing Liu. Continual pre-training of language models. InInternational Conference on Learning Representations, 2023
2023
-
[68]
Adapting large language models via reading comprehension.arXiv preprint arXiv:2309.09530, 2024
Daixuan Cheng, Shaohan Huang, and Furu Wei. Adapting large language models via reading comprehension.arXiv preprint arXiv:2309.09530, 2024
-
[69]
Composer 2 technical report, 2026
Cursor Research et al. Composer 2 technical report, 2026. URL https://arxiv.org/abs/2603. 24477
2026
-
[70]
Sft memorizes, rl generalizes: A comparative study of foundation model post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. InInternational Conference on Machine Learning, pages 10818–10838. PMLR, 2025
2025
-
[71]
Gene-r1: Reasoning with data- augmented lightweight llms for gene set analysis
Zhizheng Wang, Yifan Yang, Qiao Jin, and Zhiyong Lu. Gene-r1: Reasoning with data- augmented lightweight llms for gene set analysis. InBiocomputing 2026: Proceedings of the Pacific Symposium, pages 494–507. World Scientific, 2025
2026
-
[72]
Ming Yin, Yuanhao Qu, Ling Yang, Le Cong, and Mengdi Wang. Toward scientific rea- soning in llms: Training from expert discussions via reinforcement learning.arXiv preprint arXiv:2505.19501, 2025
-
[73]
Medea: An omics ai agent for therapeutic discovery.bioRxiv, pages 2026–01, 2026
Pengwei Sui, Michelle M Li, Shanghua Gao, Wanxiang Shen, Valentina Giunchiglia, Andrew Shen, Yepeng Huang, Zhenglun Kong, and Marinka Zitnik. Medea: An omics ai agent for therapeutic discovery.bioRxiv, pages 2026–01, 2026
2026
-
[74]
Interpro in 2022.Nucleic acids research, 51(D1):D418–D427, 2023
Typhaine Paysan-Lafosse, Matthias Blum, Sara Chuguransky, Tiago Grego, Beatriz Lázaro Pinto, Gustavo A Salazar, Maxwell L Bileschi, Peer Bork, Alan Bridge, Lucy Colwell, et al. Interpro in 2022.Nucleic acids research, 51(D1):D418–D427, 2023
2022
-
[75]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Google DeepMind. Gemma 4. https://deepmind.google/models/gemma/gemma-4/, 2026. Accessed 2026-05-04
2026
-
[77]
FineFineWeb: A comprehensive study on fine- grained domain web corpus
M-A-P, Ge Zhang, Xinrun Du, Zhimiao Yu, Zili Wang, Zekun Wang, Shuyue Guo, Tianyu Zheng, Kang Zhu, Jerry Liu, Shawn Yue, Binbin Liu, Zhongyuan Peng, Yifan Yao, Jack Yang, Ziming Li, Bingni Zhang, Minghao Liu, Tianyu Liu, Yang Gao, Wenhu Chen, Xiaohuan Zhou, Qian Liu, Taifeng Wang, and Wenhao Huang. FineFineWeb: A comprehensive study on fine- grained domai...
-
[78]
Version v0.1.0; Hugging Face dataset
-
[79]
KEGG: Kyoto encyclopedia of genes and genomes
Minoru Kanehisa and Susumu Goto. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Research, 28(1):27–30, 2000. doi: 10.1093/nar/28.1.27
-
[80]
Minoru Kanehisa, Yoko Sato, Miho Furumichi, Kanae Morishima, and Mao Tanabe. New approach for understanding genome variations in KEGG.Nucleic Acids Research, 47(D1): D590–D595, 2019. doi: 10.1093/nar/gky962. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.