Structural Kolmogorov-Arnold Convolutions: Learnable Function on the Values or the Filter Shape as Parameter-Efficient Alternative to Per-Edge Convolutional KANs
Pith reviewed 2026-06-26 00:33 UTC · model grok-4.3
The pith
Learnable functions on filter shapes or shared values outperform per-edge KANs at one-fifth the parameters on CIFAR tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By organizing convolutional KAN design along the axis of whether the univariate function acts on pixel values or on filter shape, the structural models SV-KAN and RF-KAN show that a shared value function or content-adaptive Morlet-wavelet ridge profiles for filter construction produce higher accuracy than per-edge attachments while using roughly one-fifth the parameters at matched scale.
What carries the argument
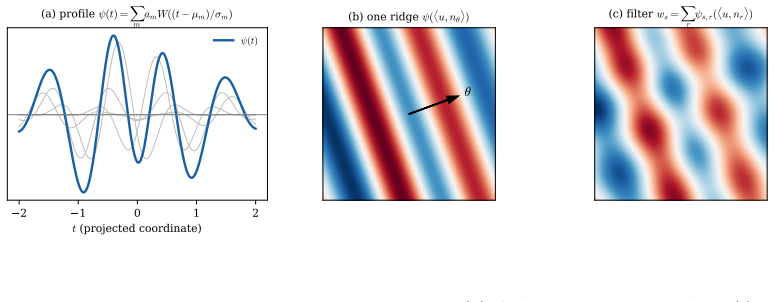
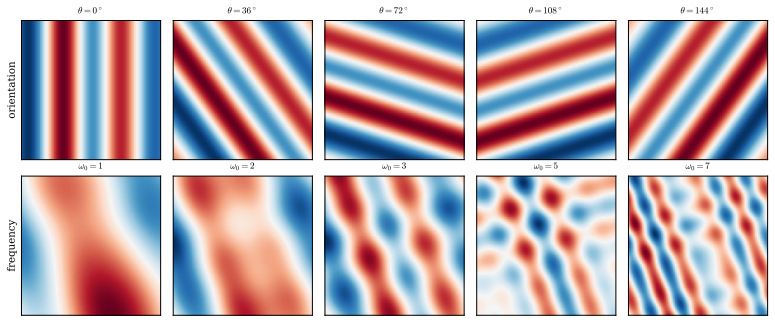
Structural placement of univariate functions, realized either as a shared activation on pixel values (SV-KAN) or as content-adaptive amplitudes modulating oriented ridge profiles in a Morlet wavelet basis for filter shapes (RF-KAN).
If this is right
- RF-KAN reaches 88.47±0.10% on CIFAR-10 and 64.40±0.19% on CIFAR-100 at ~0.4M parameters.
- SV-KAN reaches 88.20±0.31% on CIFAR-10 and 64.57±0.30% on CIFAR-100 at the same scale.
- Both exceed plain convolution and every per-edge KAN tested, including the Gram variant.
- The gain is attributed to an intrinsically localised oscillatory basis together with content adaptivity.
- Removing the learned filter shape entirely collapses accuracy by over forty points.
Where Pith is reading between the lines
- The same structural principle could be tested in residual or attention-based vision backbones to measure parameter savings at larger scales.
- Localized oscillatory bases may yield more interpretable filter visualizations than standard learned kernels.
- Combining the ridge-profile construction with other wavelet families could produce further efficiency gains on tasks with oriented textures.
- The sharp ablation drop suggests the method may generalize best to domains where local oscillatory patterns dominate the signal.
Load-bearing premise
The four-layer protocol with in-run references and three seeds produces a fair comparison in which differences in accuracy can be attributed to the placement of the learnable functions rather than to unstated differences in optimization, initialization, or implementation details.
What would settle it
Training RF-KAN and SV-KAN on a dataset with markedly different spatial statistics or increasing the depth beyond four layers and checking whether the accuracy gap over per-edge KANs reverses or disappears.
Figures
read the original abstract
Convolutional Kolmogorov--Arnold Networks (KANs) replace the fixed weights of a convolutional kernel with learnable univariate functions. The dominant formulation attaches one such function to every kernel entry and lets it act on pixel values, expressive but parameter-heavy and prone to overfitting. We argue that the learnable functions are better placed in the \emph{structure} of the convolution than on each edge, and we organise the design space along a single axis: whether the function acts on the pixel \emph{values} or on the filter \emph{shape}. We study three realisations. SV-KAN applies one shared univariate function to the values and leaves the spatial filter free and static, aa classical convolution with a single learnable shared activation. AG-KAN keeps the shared value function but supplies the spatial structure through a content-adaptive Gaussian gate. RF-KAN instead moves the learnable functions onto the filter shape, building each filter from oriented ridge profiles expanded in a localised oscillatory (Morlet) wavelet basis with content-adaptive amplitudes. Under a matched four-layer protocol with in-run references and three seeds, RF-KAN and SV-KAN reach $88.47\pm0.10\%$ and $88.20\pm0.31\%$ on CIFAR-10 and $64.40\pm0.19\%$ and $64.57\pm0.30\%$ on CIFAR-100, at about $0.4$M parameters. At this matched scale the shape model and the simplest value model meet at the top, both above a plain convolution and every per-edge KAN we tested, including the official Gram variant, at roughly a fifth of the parameters. A controlled study attributes the RF-KAN gain to an intrinsically localised oscillatory basis and to content adaptivity, and an ablation that removes the learned shape entirely, leaving only the shared value function, collapses accuracy by over forty points, identifying the learned shape as the load-bearing ingredient at this scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Structural Kolmogorov-Arnold Convolutions as a parameter-efficient alternative to per-edge convolutional KANs. It organizes the design space by whether learnable univariate functions act on pixel values (SV-KAN: shared value function with static filter; AG-KAN: with content-adaptive Gaussian gate) or on filter shape (RF-KAN: filters built from content-adaptive Morlet wavelet ridge profiles). Under a four-layer protocol, RF-KAN and SV-KAN are reported to reach 88.47% and 88.20% on CIFAR-10 and 64.40% and 64.57% on CIFAR-100 at ~0.4M parameters, outperforming plain convolutions and per-edge KANs; an ablation is used to attribute gains to the learned shape.
Significance. If the empirical claims and attribution hold, the work would demonstrate that relocating learnable functions from per-edge to filter shape (via localized oscillatory bases) can match or exceed value-based variants while using far fewer parameters than per-edge KANs, offering a new axis for efficient convolutional designs.
major comments (1)
- [Abstract] Abstract: The ablation claim that 'an ablation that removes the learned shape entirely, leaving only the shared value function, collapses accuracy by over forty points' is inconsistent with the reported SV-KAN accuracy of 88.20±0.31% on CIFAR-10. SV-KAN is defined in the same paragraph as the model that applies one shared univariate function to the values while leaving the spatial filter static. This numerical mismatch directly falsifies the attribution of performance gains to the learned shape as the load-bearing ingredient.
minor comments (1)
- [Abstract] Abstract: 'aa classical convolution' appears to be a typographical error for 'a classical convolution'.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying the inconsistency in the abstract. We address the point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The ablation claim that 'an ablation that removes the learned shape entirely, leaving only the shared value function, collapses accuracy by over forty points' is inconsistent with the reported SV-KAN accuracy of 88.20±0.31% on CIFAR-10. SV-KAN is defined in the same paragraph as the model that applies one shared univariate function to the values while leaving the spatial filter static. This numerical mismatch directly falsifies the attribution of performance gains to the learned shape as the load-bearing ingredient.
Authors: We agree that the abstract wording is inconsistent and erroneous. The reported SV-KAN result (88.20% on CIFAR-10) shows that the shared-value model performs competitively, so the sentence claiming a >40-point collapse when 'removing the learned shape entirely, leaving only the shared value function' cannot refer to SV-KAN and misstates the ablation. The controlled studies and attribution of gains to the learned oscillatory basis and content adaptivity are internal to the RF-KAN family; the abstract sentence conflates this with the SV-KAN definition. We will remove or rewrite the offending sentence in the abstract (and any parallel phrasing in the main text) to eliminate the mismatch and correctly describe the ablation results. revision: yes
Circularity Check
No significant circularity; claims are direct empirical measurements
full rationale
The paper proposes architectural variants (SV-KAN, AG-KAN, RF-KAN) and reports test-set accuracies plus one ablation under a fixed four-layer protocol. These are direct experimental outcomes on held-out CIFAR data, not quantities derived from equations or parameters fitted inside the same model. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text; the design choices are presented as alternatives to be evaluated, not as theorems reducing to their own inputs. The reported numbers therefore stand as independent evidence rather than tautological restatements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljacic, T. Hou, M. Tegmark, Kan: Kolmogorov–arnold networks, in: International con- ference on learning representations, Vol. 2025, 2025, pp. 70367–70413
2025
-
[2]
Z. Li, Kolmogorov-arnold networks are radial basis function networks, arXiv preprint arXiv:2405.06721 (2024)
arXiv 2024
-
[3]
Z. Bozorgasl, H. Chen, Wav-kan: Wavelet kolmogorov-arnold networks, arXiv preprint arXiv:2405.12832 (2024)
arXiv 2024
-
[4]
A.Bodner, A.Tepsich, J.Spolski, S.Pourteau, Convolutionalkolmogorov- arnold networks, arXiv preprint arXiv:2406.13155 (06 2024).doi:10. 48550/arXiv.2406.13155
arXiv 2024
-
[5]
I. Drokin, Kolmogorov-arnold convolutions: Design principles and empir- ical studies, arXiv preprint arXiv:2407.01092 (2024)
arXiv 2024
-
[6]
T. Ji, Y. Hou, D. Zhang, A comprehensive survey on kolmogorov arnold networks (kan), arXiv e-prints (2024) arXiv–2407
2024
-
[7]
Y. Cang, L. Shi, et al., Can kan work? exploring the potential of kolmogorov-arnold networks in computer vision, arXiv preprint arXiv:2411.06727 (2024)
arXiv 2024
- [8]
-
[9]
Z. Yang, J. Zhang, X. Luo, X. Wu, Z. Lu, L. Shen, Medkan: An advanced kolmogorov-arnold network for medical image classification, in: 2025 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), IEEE, 2025, pp. 3090–3097
2025
- [10]
-
[11]
Jamali, S
A. Jamali, S. K. Roy, D. Hong, B. Lu, P. Ghamisi, How to learn more? exploring kolmogorov–arnold networks for hyperspectral image classifica- tion, Remote Sensing 16 (21) (2024) 4015
2024
-
[12]
V. Lobanov, N. Firsov, E. Myasnikov, R. Khabibullin, A. Nikonorov, Hyperkan: Kolmogorov-arnold networks make hyperspectral image clas- sificators smarter, arXiv preprint arXiv:2407.05278 (2024)
arXiv 2024
-
[13]
M. Cheon, Kolmogorov-arnold network for satellite image classification in remote sensing, arXiv preprint arXiv:2406.00600 (2024)
arXiv 2024
-
[14]
A. Cacciatore, V. Morelli, F. Paganica, E. Frontoni, L. Migliorelli, D. Be- rardini, A preliminary study on continual learning in computer vision us- ing kolmogorov-arnold networks, arXiv preprint arXiv:2409.13550 (2024)
arXiv 2024
-
[15]
Z. Zhao, J. Shu, D. Meng, Z. Xu, Improving memory efficiency for training kans via meta learning, arXiv preprint arXiv:2506.07549 (2025)
arXiv 2025
-
[16]
P. Yi, W. Li, X. Chen, J. Zhang, L. Liu, Y. Liu, Light-reskan: A parameter-sharing lightweight kan with gram polynomials for efficient sar image recognition, IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 19 (2026) 12445–12460.doi:10.1109/ jstars.2026.3678852
arXiv 2026
-
[17]
Z. Wang, Z. Miao, J. Hu, Q. Qiu, Adaptive convolutions with per-pixel dynamic filter atom, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 12302–12311
2021
-
[18]
H. X. Nam, T. N. Hoa, B. T. Thanh, B. P. Loc, V. Q. Tuyen, A. Nguyen, A positional encoding-enhanced kolmogorov-arnold convolutional network for structural health monitoring, in: Structures, Vol. 89, Elsevier, 2026, p. 111970
2026
-
[19]
Z. Zhou, Z. Xu, Y. Liu, S. Wang, askan: Active subspace embedded kolmogorov-arnold network, Neural Networks (2025) 108280. 15
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.