APPO: Agentic Procedural Policy Optimization
Pith reviewed 2026-06-27 10:18 UTC · model grok-4.3
The pith
APPO shifts agentic RL credit assignment from tool-call boundaries to fine-grained decision points in the sequence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
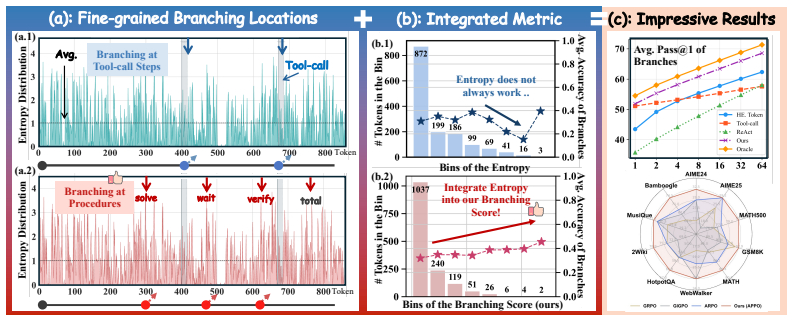
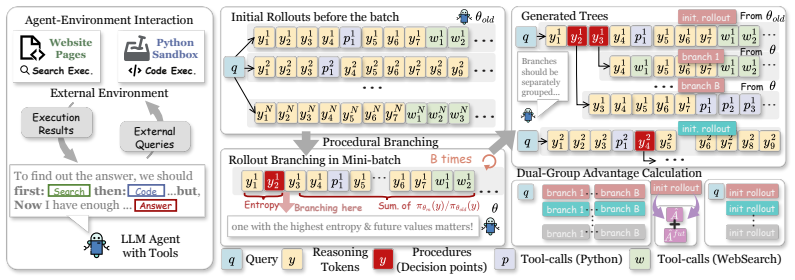
APPO selects branching locations using a Branching Score that combines token uncertainty with policy-induced likelihood gains of subsequent continuations, enabling more targeted exploration while filtering spurious high-entropy positions, and further introduces procedure-level advantage scaling to better distribute credit across branched rollouts.
What carries the argument
The Branching Score, which combines token uncertainty with policy-induced likelihood gains of subsequent continuations to identify fine-grained decision points for branching and credit assignment.
If this is right
- Improves strong agentic RL baselines by nearly 4 points on 13 benchmarks.
- Maintains efficient tool-calls during execution.
- Preserves behavior interpretability of the resulting agents.
- Moves credit assignment from coarse heuristic units like tool calls to fine-grained sequence positions.
Where Pith is reading between the lines
- The approach may extend to sequential decision problems outside tool-using agents where credit must be assigned over long traces.
- It suggests that pure entropy signals for exploration could be systematically augmented with likelihood-gain terms in other policy optimization settings.
- Longer-horizon agent tasks might benefit disproportionately because the method targets distributed rather than boundary-concentrated decisions.
Load-bearing premise
The pilot analysis finding that influential decision points are broadly distributed and that the Branching Score reliably filters spurious high-entropy positions will generalize to the full experimental setting.
What would settle it
Running the 13 benchmarks with APPO's Branching Score and procedure-level scaling disabled or replaced by pure entropy-based branching, and observing no performance gain over the original baselines.
Figures



read the original abstract
Recent advances in agentic Reinforcement Learning (RL) have substantially improved the multi-turn tool-use capabilities of large language model agents. However, most existing methods assign credit over coarse heuristic units, such as tool-call boundaries or fixed workflows, making it difficult to identify which intermediate decisions influence downstream outcomes. In this work, we study agentic RL from two perspectives: \textit{where to branch and how to assign credit after branching}. Our pilot analysis shows that influential decision points are broadly distributed throughout the generated sequence rather than concentrated at tool calls, while token entropy alone does not reliably reflect their impact on final outcomes. Motivated by these observations, we propose \textbf{Agentic Procedural Policy Optimization (APPO)}, which shifts branching and credit assignment from coarse interaction units to fine-grained decision points in the sequence. APPO selects branching locations using a Branching Score that combines token uncertainty with policy-induced likelihood gains of subsequent continuations, enabling more targeted exploration while filtering out spurious high-entropy positions. It further introduces procedure-level advantage scaling to better distribute credit across branched rollouts. Experiments on 13 benchmarks show that APPO consistently improves strong agentic RL baselines by nearly 4 points, while keeping efficient tool-calls and maintaining behavior interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Agentic Procedural Policy Optimization (APPO) for agentic RL with LLMs. It reports a pilot analysis indicating that influential decision points are broadly distributed in sequences (rather than concentrated at tool calls) and that token entropy alone is unreliable for identifying them. APPO introduces a Branching Score (token uncertainty combined with policy-induced likelihood gains of continuations) to select branching locations and procedure-level advantage scaling for credit assignment. It claims consistent ~4-point gains over strong baselines on 13 benchmarks while preserving efficient tool use and interpretability.
Significance. If the reported gains are robust and the Branching Score's filtering property generalizes beyond the pilot, the work would advance fine-grained credit assignment in long-horizon agentic settings, offering a more targeted alternative to coarse heuristic units such as tool-call boundaries.
major comments (2)
- [Pilot analysis] Pilot analysis: the central empirical claim of consistent ~4-point gains on 13 benchmarks rests on the assumption that the pilot observations (broad distribution of influential decisions and superiority of the Branching Score over entropy) generalize to the evaluation tasks. No evidence is supplied that the distribution or filtering property holds on those benchmarks; without it, gains could arise from procedure-level advantage scaling or other unablated factors rather than the targeted branching mechanism.
- [Experiments] Experiments: the abstract states empirical gains but supplies no experimental details, baselines, statistical tests, ablation results, or variance measures. This prevents assessment of whether the data actually supports the central claim of consistent improvement attributable to APPO.
minor comments (1)
- The abstract would be clearer if it briefly named the 13 benchmarks or the strong agentic RL baselines used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Pilot analysis: the central empirical claim of consistent ~4-point gains on 13 benchmarks rests on the assumption that the pilot observations (broad distribution of influential decisions and superiority of the Branching Score over entropy) generalize to the evaluation tasks. No evidence is supplied that the distribution or filtering property holds on those benchmarks; without it, gains could arise from procedure-level advantage scaling or other unablated factors rather than the targeted branching mechanism.
Authors: The pilot analysis was performed to identify general characteristics of influential decision points in agentic trajectories and to motivate the Branching Score design. While the exact pilot statistics are not replicated on every one of the 13 benchmarks, the consistent gains across diverse tasks support the utility of the full APPO procedure. To directly address the concern about attribution, we will add an ablation isolating the Branching Score (versus procedure-level scaling alone) together with a verification of its filtering behavior on a representative subset of the evaluation benchmarks. revision: yes
-
Referee: Experiments: the abstract states empirical gains but supplies no experimental details, baselines, statistical tests, ablation results, or variance measures. This prevents assessment of whether the data actually supports the central claim of consistent improvement attributable to APPO.
Authors: The abstract is intentionally concise. Complete experimental details—including the 13 benchmarks, baselines, statistical tests, ablation studies, and variance across random seeds—are reported in Section 4 of the manuscript. We will revise the abstract to include a short clause referencing the evaluation protocol and results section. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper motivates APPO from a pilot analysis of decision-point distribution and Branching Score properties, then reports empirical gains on 13 benchmarks. No equations, fitted parameters, or self-citations are presented that reduce the claimed improvements, Branching Score definition, or procedure-level advantage scaling to tautological inputs by construction. The pilot observations function as external motivation rather than a load-bearing fitted quantity renamed as prediction, and the experimental results stand as independent evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agarwal, N
A. Agarwal, N. Jiang, S. M. Kakade, and W. Sun. Reinforcement learning: Theory and algorithms.CS Dept., UW Seattle, Seattle, WA, USA, Tech. Rep, 32:96, 2019
2019
-
[2]
S. Cao, D. Li, F. Zhao, S. Yuan, S. R. Hegde, C. Chen, C. Ruan, T. Griggs, S. Liu, E. Tang, et al. Skyrl-agent: Efficient rl training for multi-turn llm agent.arXiv preprint arXiv:2511.16108, 2025
arXiv 2025
-
[3]
A. Chen, A. Li, B. Gong, B. Jiang, B. Fei, B. Yang, B. Shan, C. Yu, C. Wang, C. Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
Pith/arXiv arXiv 2025
-
[4]
K. Chen, Y . Ren, Y . Liu, X. Hu, H. Tian, T. Xie, F. Liu, H. Zhang, H. Liu, Y . Gong, et al. xbench: Tracking agents productivity scaling with profession-aligned real-world evaluations.arXiv preprint arXiv:2506.13651, 2025
arXiv 2025
-
[5]
X. Chu, H. Huang, X. Zhang, F. Wei, and Y . Wang. GPG: A simple and strong reinforcement learning baseline for model reasoning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[6]
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[7]
T. Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
Pith/arXiv arXiv 2023
-
[8]
G. Dong, L. Bao, Z. Wang, K. Zhao, X. Li, J. Jin, J. Yang, H. Mao, F. Zhang, K. Gai, et al. Agentic entropy-balanced policy optimization.arXiv preprint arXiv:2510.14545, 2025
arXiv 2025
-
[9]
G. Dong, Y . Chen, X. Li, J. Jin, H. Qian, Y . Zhu, H. Mao, G. Zhou, Z. Dou, and J.-R. Wen. Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning.arXiv preprint arXiv:2505.16410, 2025
arXiv 2025
-
[10]
G. Dong, H. Mao, K. Ma, L. Bao, Y . Chen, Z. Wang, Z. Chen, J. Du, H. Wang, F. Zhang, et al. Agentic reinforced policy optimization.arXiv preprint arXiv:2507.19849, 2025
Pith/arXiv arXiv 2025
-
[11]
Dubey, A
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[12]
Ester, H.-P
M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, volume 96, pages 226–231, 1996
1996
-
[13]
J. Feng, S. Huang, X. Qu, G. Zhang, Y . Qin, B. Zhong, C. Jiang, J. Chi, and W. Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
Pith/arXiv arXiv 2025
-
[14]
L. Feng, Z. Xue, T. Liu, and B. An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
Pith/arXiv arXiv 2025
-
[15]
X. Feng, Z. Wan, M. Wen, S. M. McAleer, Y . Wen, W. Zhang, and J. Wang. Alphazero-like tree-search can guide large language model decoding and training.arXiv preprint arXiv:2309.17179, 2023
arXiv 2023
-
[16]
J. Gao, W. Fu, M. Xie, S. Xu, C. He, Z. Mei, B. Zhu, and Y . Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl.arXiv preprint arXiv:2508.07976, 2025
arXiv 2025
-
[17]
Z. Gou, Z. Shao, Y . Gong, Y . Shen, Y . Yang, M. Huang, N. Duan, and W. Chen. Tora: A tool-integrated reasoning agent for mathematical problem solving.arXiv preprint arXiv:2309.17452, 2023
Pith/arXiv arXiv 2023
-
[18]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[19]
Y . Guo, L. Xu, J. Liu, D. Ye, and S. Qiu. Segment policy optimization: Effective segment-level credit assignment in rl for large language models.arXiv preprint arXiv:2505.23564, 2025
arXiv 2025
-
[20]
D. Hafner. Benchmarking the spectrum of agent capabilities.arXiv preprint arXiv:2109.06780, 2021
arXiv 2021
-
[21]
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[22]
Ho, A.-K
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020. 10
2020
-
[23]
Z. Hou, Z. Hu, Y . Li, R. Lu, J. Tang, and Y . Dong. Treerl: Llm reinforcement learning with on-policy tree search. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12355–12369, 2025
2025
-
[24]
J. Hu, J. K. Liu, H. Xu, and W. Shen. Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization.arXiv preprint arXiv:2501.03262, 2025
Pith/arXiv arXiv 2025
- [25]
-
[26]
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[27]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[28]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
Pith/arXiv arXiv 2024
-
[29]
Y . Ji, Z. Ma, Y . Wang, G. Chen, X. Chu, and L. Wu. Tree search for llm agent reinforcement learning. arXiv preprint arXiv:2509.21240, 2025
arXiv 2025
-
[30]
J. Jin, X. Li, G. Dong, Y . Zhang, Y . Zhu, Y . Zhao, H. Qian, and Z. Dou. Hira: A hierarchical reasoning framework for decoupled planning and execution in deep search.arXiv preprint arXiv:2507.02652, 2025
arXiv 2025
-
[31]
J. Jin, Y . Zhu, Z. Dou, G. Dong, X. Yang, C. Zhang, T. Zhao, Z. Yang, and J.-R. Wen. Flashrag: A modular toolkit for efficient retrieval-augmented generation research. InCompanion Proceedings of the ACM on Web Conference 2025, pages 737–740, 2025
2025
-
[32]
T. Kaufmann, P. Weng, V . Bengs, and E. Hüllermeier. A survey of reinforcement learning from human feedback.arXiv preprint arXiv:2312.14925, 2023
arXiv 2023
-
[33]
X. Lai, Z. Tian, Y . Chen, S. Yang, X. Peng, and J. Jia. Step-dpo: Step-wise preference optimization for long-chain reasoning of llms.arXiv preprint arXiv:2406.18629, 2024
Pith/arXiv arXiv 2024
-
[34]
H. Lee, S. Phatale, H. Mansoor, K. R. Lu, T. Mesnard, J. Ferret, C. Bishop, E. Hall, V . Carbune, and A. Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. 2023
2023
-
[35]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[36]
P. Li, Z. Gao, B. Zhang, Y . Mi, X. Ma, C. Shi, T. Yuan, Y . Wu, Y . Jia, S.-C. Zhu, et al. Iterative tool usage exploration for multimodal agents via step-wise preference tuning.arXiv preprint arXiv:2504.21561, 2025
Pith/arXiv arXiv 2025
-
[37]
X. Li, G. Dong, J. Jin, Y . Zhang, Y . Zhou, Y . Zhu, P. Zhang, and Z. Dou. Search-o1: Agentic search- enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
2025
-
[38]
X. Li, W. Jiao, J. Jin, G. Dong, J. Jin, Y . Wang, H. Wang, Y . Zhu, J.-R. Wen, Y . Lu, et al. Deepagent: A general reasoning agent with scalable toolsets.arXiv preprint arXiv:2510.21618, 2025
arXiv 2025
-
[39]
X. Li, J. Jin, G. Dong, H. Qian, Y . Wu, J.-R. Wen, Y . Zhu, and Z. Dou. Webthinker: Empowering large reasoning models with deep research capability.arXiv preprint arXiv:2504.21776, 2025
Pith/arXiv arXiv 2025
-
[40]
X. Li, J. Jin, Y . Zhou, Y . Wu, Z. Li, Y . Qi, and Z. Dou. Retrollm: Empowering large language models to retrieve fine-grained evidence within generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16754–16779, 2025
2025
-
[41]
X. Li, H. Zou, and P. Liu. Torl: Scaling tool-integrated rl.arXiv preprint arXiv:2503.23383, 2025
arXiv 2025
-
[42]
Z.-Z. Li, D. Zhang, M.-L. Zhang, J. Zhang, Z. Liu, Y . Yao, H. Xu, J. Zheng, P.-J. Wang, X. Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419, 2025
Pith/arXiv arXiv 2025
-
[43]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023. 11
2023
-
[44]
Z. Liu, C. Chen, W. Li, P. Qi, T. Pang, C. Du, W. S. Lee, and M. Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Pith/arXiv arXiv 2025
-
[45]
K. Lu, C. Chen, X. Wang, B. Cui, Y . Liu, and W. Zhang. Pilotrl: Training language model agents via global planning-guided progressive reinforcement learning.arXiv preprint arXiv:2508.00344, 2025
arXiv 2025
-
[46]
Z. Lu, Z. Yao, J. Wu, C. Han, Q. Gu, X. Cai, W. Lu, J. Xiao, Y . Zhuang, and Y . Shen. Skill0: In-context agentic reinforcement learning for skill internalization.arXiv preprint arXiv:2604.02268, 2026
Pith/arXiv arXiv 2026
-
[47]
C. Ma, S. Yang, K. Huang, J. Lu, H. Meng, S. Wang, B. Ding, S. V osoughi, G. Wang, and J. Zhou. Fipo: Eliciting deep reasoning with future-kl influenced policy optimization.arXiv preprint arXiv:2603.19835, 2026
arXiv 2026
-
[48]
Z. Ma, S. Yang, Y . Ji, X. Wang, Y . Wang, Y . Hu, T. Huang, and X. Chu. Skillclaw: Let skills evolve collectively with agentic evolver.arXiv preprint arXiv:2604.08377, 2026
Pith/arXiv arXiv 2026
-
[49]
L. McInnes, J. Healy, and J. Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
Pith/arXiv arXiv 2018
-
[50]
H. Meng, K. Huang, S. Wei, C. Ma, S. Yang, X. Wang, G. Wang, B. Ding, and J. Zhou. Sparse but critical: A token-level analysis of distributional shifts in rlvr fine-tuning of llms.arXiv preprint arXiv:2603.22446, 2026
arXiv 2026
-
[51]
Mialon, C
G. Mialon, C. Fourrier, T. Wolf, Y . LeCun, and T. Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[52]
Muennighoff, Z
N. Muennighoff, Z. Yang, W. Shi, X. L. Li, L. Fei-Fei, H. Hajishirzi, L. Zettlemoyer, P. Liang, E. Candès, and T. B. Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
2025
-
[53]
L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, et al. Humanity’s last exam.arXiv preprint arXiv:2501.14249, 2025
Pith/arXiv arXiv 2025
-
[54]
Press, M
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, and M. Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
2023
-
[55]
C. Qian, E. C. Acikgoz, Q. He, H. Wang, X. Chen, D. Hakkani-Tür, G. Tur, and H. Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
Pith/arXiv arXiv 2025
-
[56]
C. Qian, E. C. Acikgoz, H. Wang, X. Chen, A. Sil, D. Hakkani-Tur, G. Tur, and H. Ji. Smart: Self-aware agent for tool overuse mitigation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 4604–4621, 2025
2025
-
[57]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[58]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference opti- mization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[59]
Rasley, S
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506, 2020
2020
-
[60]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[61]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[62]
L. Shen, Y . Zhang, C. K. Ling, X. Zhao, and T.-S. Chua. Carl: Critical action focused reinforcement learning for multi-step agent.arXiv preprint arXiv:2512.04949, 2025
Pith/arXiv arXiv 2025
-
[63]
Sheng, C
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 12
2025
-
[64]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[65]
M. Shridhar, X. Yuan, M.-A. Côté, Y . Bisk, A. Trischler, and M. Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
Pith/arXiv arXiv 2010
-
[66]
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[67]
H. Su, S. Diao, X. Lu, M. Liu, J. Xu, X. Dong, Y . Fu, P. Belcak, H. Ye, H. Yin, et al. Toolorchestra: Elevating intelligence via efficient model and tool orchestration.arXiv preprint arXiv:2511.21689, 2025
arXiv 2025
-
[68]
Z. Su, L. Pan, X. Bai, D. Liu, G. Dong, J. Huang, M. Lv, W. Hu, F. Zhang, K. Gai, et al. Klear-reasoner: Advancing reasoning capability via gradient-preserving clipping policy optimization.arXiv preprint arXiv:2508.07629, 2025
arXiv 2025
-
[69]
K. Team, Y . Bai, Y . Bao, Y . Charles, C. Chen, G. Chen, H. Chen, H. Chen, J. Chen, N. Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
Pith/arXiv arXiv 2025
-
[70]
K. Team, A. Du, B. Gao, B. Xing, C. Jiang, C. Chen, C. Li, C. Xiao, C. Du, C. Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
Pith/arXiv arXiv 2025
-
[71]
M. L. Team, B. Li, B. Lei, B. Wang, B. Rong, C. Wang, C. Zhang, C. Gao, C. Zhang, C. Sun, et al. Longcat-flash technical report.arXiv preprint arXiv:2509.01322, 2025
arXiv 2025
-
[72]
Q. Team. Qwq: Reflect deeply on the boundaries of the unknown, 2024
2024
-
[73]
Trivedi, N
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[74]
H. Wang, C. Qian, M. Li, J. Qiu, B. Xue, M. Wang, H. Ji, and K.-F. Wong. Toward a theory of agents as tool-use decision-makers.arXiv preprint arXiv:2506.00886, 2025
Pith/arXiv arXiv 2025
-
[75]
L. Wang, W. Xu, Y . Lan, Z. Hu, Y . Lan, R. K.-W. Lee, and E.-P. Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 2609–2634, 2023
2023
-
[76]
P. Wang, S. Xu, J. Li, Y . Luo, D. Li, J. Hao, and M. Zhang.Re 2: Unlocking llm reasoning via reinforcement learning with re-solving.arXiv preprint arXiv:2603.07197, 2026
arXiv 2026
-
[77]
S. Wang, L. Yu, C. Gao, C. Zheng, S. Liu, R. Lu, K. Dang, X. Chen, J. Yang, Z. Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939, 2025
Pith/arXiv arXiv 2025
-
[78]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[79]
S. Welleck, A. Bertsch, M. Finlayson, H. Schoelkopf, A. Xie, G. Neubig, I. Kulikov, and Z. Harchaoui. From decoding to meta-generation: Inference-time algorithms for large language models.arXiv preprint arXiv:2406.16838, 2024
arXiv 2024
-
[80]
D. Wu, D. S. Sachan, W.-t. Yih, and M. Chen. Procedural knowledge at scale improves reasoning.arXiv preprint arXiv:2604.01348, 2026
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.