CompleteRXN: Toward Completing Open Chemical Reaction Databases
Pith reviewed 2026-07-01 08:00 UTC · model grok-4.3
The pith
A constrained decoder model completes missing chemical reaction components with 99% accuracy on standard splits and 91% on extreme out-of-distribution cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Constrained Reaction Balancer achieves high performance on the CompleteRXN benchmark, with 99.20% equivalence accuracy on random splits and 91.12% on extreme out-of-distribution splits, outperforming other methods like SynRBL in accuracy while producing balanced completions.
What carries the argument
The Constrained Reaction Balancer (CRB), an encoder-decoder model with constrained decoding that enforces atom balance and chemical plausibility in reaction completions.
If this is right
- Performance degrades with increasing incompleteness in reactions.
- Substantial drop occurs when evaluating on full uncurated USPTO data.
- SynRBL produces many balanced and plausible completions but with lower accuracy.
- Future work is motivated to improve practical robustness.
Where Pith is reading between the lines
- If the benchmark holds, similar completion models could improve reliability of reaction databases for downstream ML tasks.
- The drop on uncurated data suggests need for better generalization techniques.
- Mapping to mechanistic reactions may not capture all real-world incompleteness patterns.
Load-bearing premise
That mapping USPTO records to curated mechanistic reactions creates a dataset representative of realistic missing-data conditions in open chemical reaction databases.
What would settle it
If the CRB model fails to achieve above 80% equivalence accuracy on a new set of reactions extracted directly from uncurated USPTO without mapping, the claim of high performance under realistic conditions would be falsified.
Figures
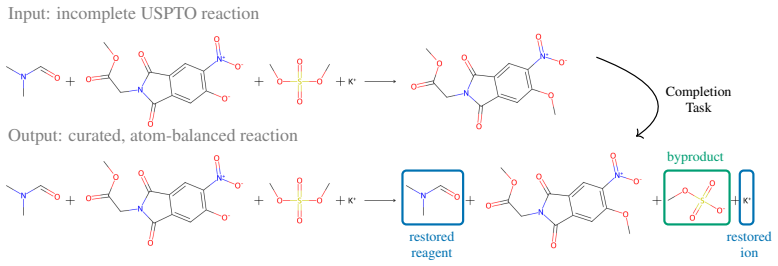
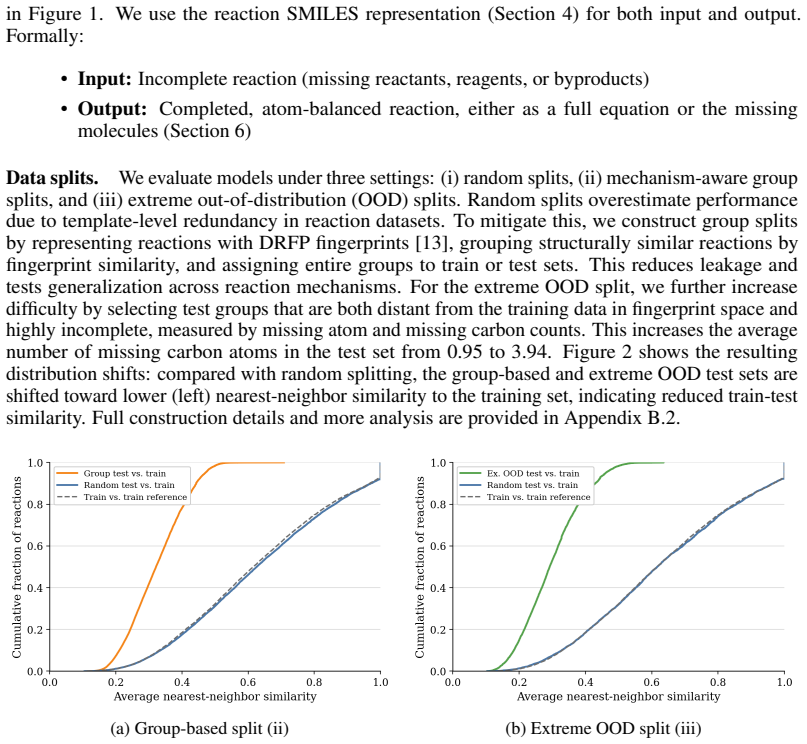
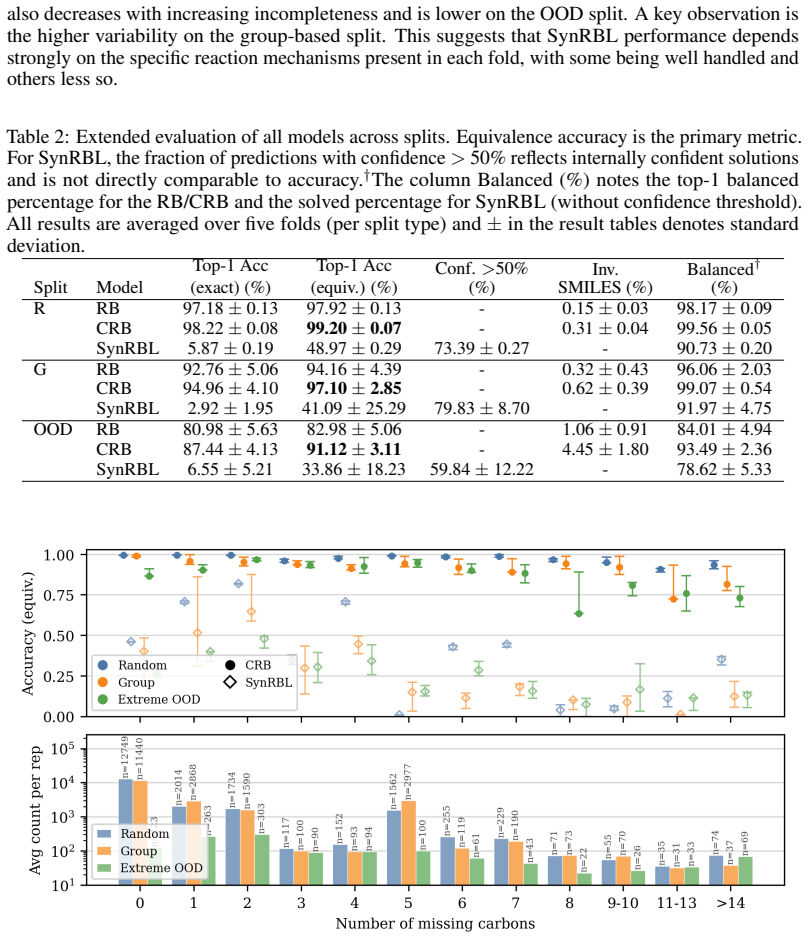
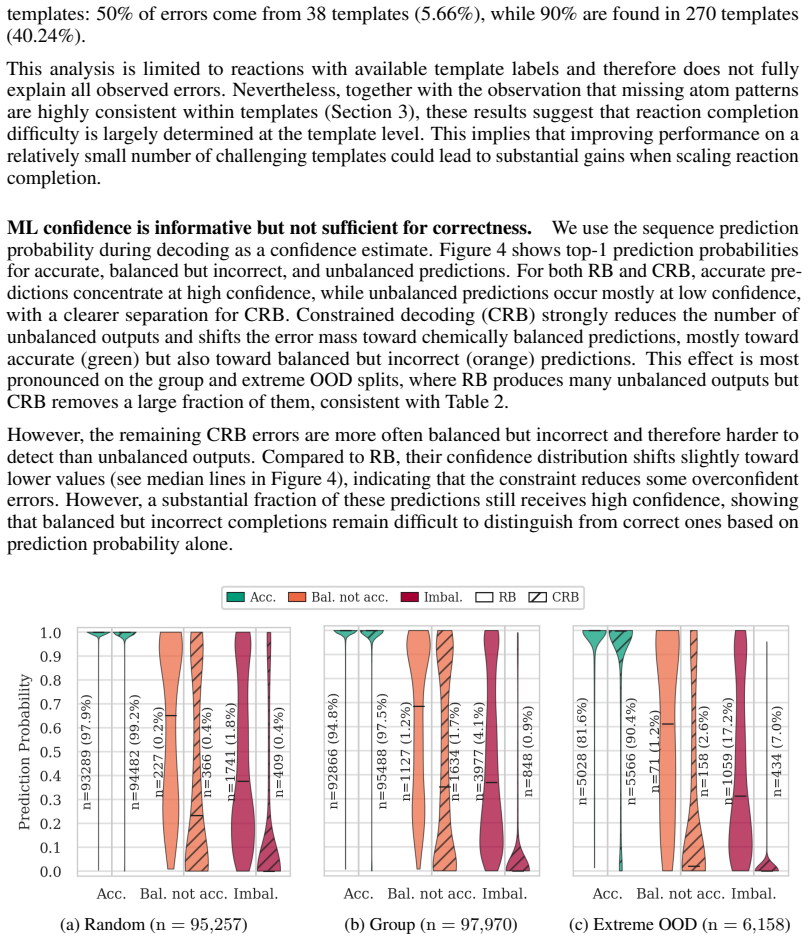
read the original abstract
Chemical reaction datasets such as USPTO suffer from substantial incompleteness, frequently missing byproducts, co-reactants, and stoichiometric coefficients. This limits their applicability and reliability in downstream applications. Here, we introduce CompleteRXN, a large-scale supervised benchmark for reaction completion under realistic missing-data conditions. We construct a dataset of aligned incomplete and atom-balanced reactions by mapping USPTO records to curated mechanistic reactions. We evaluate representative baselines, including a novel encoder-decoder reaction completion model with constrained decoding, the Constrained Reaction Balancer (CRB), and a recent algorithmic method, SynRBL. On our CompleteRXN benchmark, the CRB achieves high performance across splits of increasing difficulty, reaching 99.20% equivalence accuracy on the random split and 91.12% on the extreme out-of-distribution split. SynRBL produces many balanced and chemically plausible completions, but with lower accuracy on the benchmark test splits. Across all methods, performance degrades with increasing incompleteness. We observe a substantial drop when evaluating on reactions outside the benchmark (full uncurated USPTO), highlighting the gap between benchmark performance and practical robustness and motivating future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CompleteRXN, a supervised benchmark for reaction completion under missing-data conditions. It constructs paired incomplete/atom-balanced reactions by mapping USPTO records onto curated mechanistic reactions, then evaluates baselines including a new encoder-decoder model (Constrained Reaction Balancer, CRB) with constrained decoding and the algorithmic method SynRBL. The central empirical claims are that CRB reaches 99.20% equivalence accuracy on the random split and 91.12% on the extreme out-of-distribution split, that performance degrades with increasing incompleteness, and that a substantial drop occurs when the same models are tested on full uncurated USPTO.
Significance. If the USPTO-to-mechanistic mapping produces incompleteness patterns that match those actually present in open databases, CompleteRXN and the CRB model would provide a useful supervised signal for improving reaction database completeness. The explicit reporting of the performance drop on uncurated USPTO is a strength that correctly flags the generalization gap.
major comments (2)
- [Dataset construction] Dataset construction (abstract and §3): the claim that the mapping 'produces a dataset that accurately represents realistic missing-data conditions' is load-bearing for the benchmark's utility, yet the manuscript provides no quantitative comparison of the induced distribution of missing byproducts, co-reactants, or stoichiometric omissions against statistics measured directly on uncurated USPTO; the reported substantial drop on full USPTO is consistent with a mismatch.
- [Evaluation protocol] Evaluation protocol (abstract): the extreme out-of-distribution split is described only at a high level; without explicit definitions of how the splits are constructed (e.g., reaction-class or template hold-out criteria) it is impossible to judge whether the 91.12% figure reflects genuine extrapolation or residual leakage from the USPTO-to-mechanistic mapping step.
minor comments (1)
- The abstract states performance numbers to two decimal places but does not report the number of test examples per split or confidence intervals; adding these would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where additional clarity and analysis would strengthen the manuscript. We respond to each below and indicate the revisions we will make.
read point-by-point responses
-
Referee: Dataset construction (abstract and §3): the claim that the mapping 'produces a dataset that accurately represents realistic missing-data conditions' is load-bearing for the benchmark's utility, yet the manuscript provides no quantitative comparison of the induced distribution of missing byproducts, co-reactants, or stoichiometric omissions against statistics measured directly on uncurated USPTO; the reported substantial drop on full USPTO is consistent with a mismatch.
Authors: We agree that a quantitative comparison of incompleteness patterns would strengthen the claim. In the revised manuscript we will add a new subsection (or appendix) that reports the empirical distributions of missing byproducts, co-reactants, and stoichiometric omissions in CompleteRXN and directly compares them to the same statistics computed on the full uncurated USPTO. This analysis will also discuss the observed performance drop on uncurated data in light of any distributional differences. revision: yes
-
Referee: Evaluation protocol (abstract): the extreme out-of-distribution split is described only at a high level; without explicit definitions of how the splits are constructed (e.g., reaction-class or template hold-out criteria) it is impossible to judge whether the 91.12% figure reflects genuine extrapolation or residual leakage from the USPTO-to-mechanistic mapping step.
Authors: The construction details for all splits, including the extreme out-of-distribution split (reaction-class and template hold-out criteria), appear in §4 of the full manuscript. To address the concern that the abstract is insufficiently explicit, we will expand the abstract to include a concise but precise description of the split criteria and will add a short dedicated paragraph (with pseudocode) in §4 that makes the hold-out rules fully explicit, thereby allowing readers to assess potential leakage. revision: yes
Circularity Check
No significant circularity; empirical benchmark construction with no self-referential derivations.
full rationale
The paper presents an empirical benchmark (CompleteRXN) built by mapping USPTO records to curated mechanistic reactions, then evaluates models including a novel CRB on random and OOD splits. No equations, parameter fits, or derivations are described that reduce to author-defined inputs by construction. The central claims are performance numbers on the constructed benchmark and a noted drop on uncurated USPTO; these are falsifiable measurements rather than tautological predictions. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. This is a standard empirical evaluation whose validity rests on external data realism, not internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption USPTO records can be reliably mapped to curated mechanistic reactions to produce aligned incomplete and atom-balanced pairs that represent real missing-data conditions.
Reference graph
Works this paper leans on
-
[1]
Blanco, N
C. Blanco, N. Pauliks, F. Donati, N. Engberg, and J. Weber. Machine learning to support prospective life cycle assessment of emerging chemical technologies.Current Opinion in Green and Sustainable Chemistry, 50:100979, 2024
2024
- [2]
-
[3]
C. W. Coley, R. Barzilay, T. S. Jaakkola, W. H. Green, and K. F. Jensen. Prediction of organic reaction outcomes using machine learning.ACS central science, 3(5):434–443, 2017
2017
-
[4]
C. W. Coley, L. Rogers, W. H. Green, and K. F. Jensen. Computer-assisted retrosynthesis based on molecular similarity.ACS central science, 3(12):1237–1245, 2017
2017
-
[5]
Y . Du, A. R. Jamasb, J. Guo, T. Fu, C. Harris, Y . Wang, C. Duan, P. Liò, P. Schwaller, and T. L. Blundell. Machine learning-aided generative molecular design.Nature Machine Intelligence, 6(6):589–604, 2024
2024
-
[6]
Ioannou, S
I. Ioannou, S. C. D’Angelo, Á. Galán-Martín, C. Pozo, J. Pérez-Ramírez, and G. Guillén- Gosálbez. Process modelling and life cycle assessment coupled with experimental work to shape the future sustainable production of chemicals and fuels.Reaction Chemistry & Engineering, 6(7):1179–1194, 2021
2021
-
[7]
W. Jin, C. Coley, R. Barzilay, and T. Jaakkola. Predicting organic reaction outcomes with weisfeiler-lehman network.Advances in neural information processing systems, 30, 2017
2017
-
[8]
J. F. Joung, M. H. Fong, N. Casetti, J. P. Liles, N. S. Dassanayake, and C. W. Coley. Electron flow matching for generative reaction mechanism prediction.Nature, 645(8079):115–123, 2025
2025
-
[9]
D. M. Lowe.Extraction of chemical structures and reactions from the literature. PhD thesis, 2012
2012
-
[10]
NameRxn, 2026
NextMove Software. NameRxn, 2026. Accessed: 2026-04-05
2026
-
[11]
Phan, N.-N
T.-L. Phan, N.-N. Nguyen Song, and P. F. Stadler. Synrxn: An open benchmark and curated dataset for computational reaction modeling.Scientific Data, 13(1):625, 2026
2026
-
[12]
T.-L. Phan, K. Weinbauer, T. Gärtner, D. Merkle, J. L. Andersen, R. Fagerberg, and P. F. Stadler. Reaction rebalancing: a novel approach to curating reaction databases.Journal of Cheminformatics, 16(1):82, 2024. 10
2024
-
[13]
Probst, P
D. Probst, P. Schwaller, and J.-L. Reymond. Reaction classification and yield prediction using the differential reaction fingerprint drfp.Digital discovery, 1(2):91–97, 2022
2022
-
[14]
Schneider, D
N. Schneider, D. M. Lowe, R. A. Sayle, and G. A. Landrum. Development of a novel fingerprint for chemical reactions and its application to large-scale reaction classification and similarity. Journal of chemical information and modeling, 55(1):39–53, 2015
2015
-
[15]
Schneider, N
N. Schneider, N. Stiefl, and G. A. Landrum. What’s what: The (nearly) definitive guide to reaction role assignment.Journal of chemical information and modeling, 56(12):2336–2346, 2016
2016
-
[16]
found in translation
P. Schwaller, T. Gaudin, D. Lanyi, C. Bekas, and T. Laino. “found in translation”: predicting outcomes of complex organic chemistry reactions using neural sequence-to-sequence models. Chemical science, 9(28):6091–6098, 2018
2018
-
[17]
Schwaller, T
P. Schwaller, T. Laino, T. Gaudin, P. Bolgar, C. A. Hunter, C. Bekas, and A. A. Lee. Molecular transformer: a model for uncertainty-calibrated chemical reaction prediction.ACS central science, 5(9):1572–1583, 2019
2019
-
[18]
Schwaller, D
P. Schwaller, D. Probst, A. C. Vaucher, V . H. Nair, D. Kreutter, T. Laino, and J.-L. Reymond. Mapping the space of chemical reactions using attention-based neural networks.Nature Machine Intelligence, 3(2):144–152, 2021
2021
-
[19]
M. H. Segler and M. P. Waller. Neural-symbolic machine learning for retrosynthesis and reaction prediction.Chemistry–A European Journal, 23(25):5966–5971, 2017
2017
-
[20]
van Wijngaarden, G
M. van Wijngaarden, G. V ogel, and J. M. Weber. Completing partial reaction equations with rule and language model-based methods. InComputer Aided Chemical Engineering, volume 53, pages 3139–3144. Elsevier, 2024
2024
-
[21]
J. M. Weber, Z. Guo, C. Zhang, A. M. Schweidtmann, and A. A. Lapkin. Chemical data intelligence for sustainable chemistry.Chemical Society Reviews, 50(21):12013–12036, 2021
2021
-
[22]
Zhang, A
C. Zhang, A. Arun, and A. A. Lapkin. Completing and balancing database excerpted chemical reactions with a hybrid mechanistic-machine learning approach.ACS omega, 9(16):18385– 18399, 2024
2024
-
[23]
Zipoli, Z
F. Zipoli, Z. Ayadi, P. Schwaller, T. Laino, and A. C. Vaucher. Completion of partial chemical equations.Machine Learning: Science and Technology, 5(2):025071, 2024. 11 A Details of Data Analysis of USPTO The USPTO reaction dataset is highly incomplete: across commonly used subsets, fewer than 10% of reactions are atom- and charge-balanced. Missing inform...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.