CompleteRXN: Toward Completing Open Chemical Reaction Databases
Pith reviewed 2026-05-09 20:22 UTC · model grok-4.3
The pith
A new benchmark and constrained model complete missing parts of chemical reactions from open databases at up to 99% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
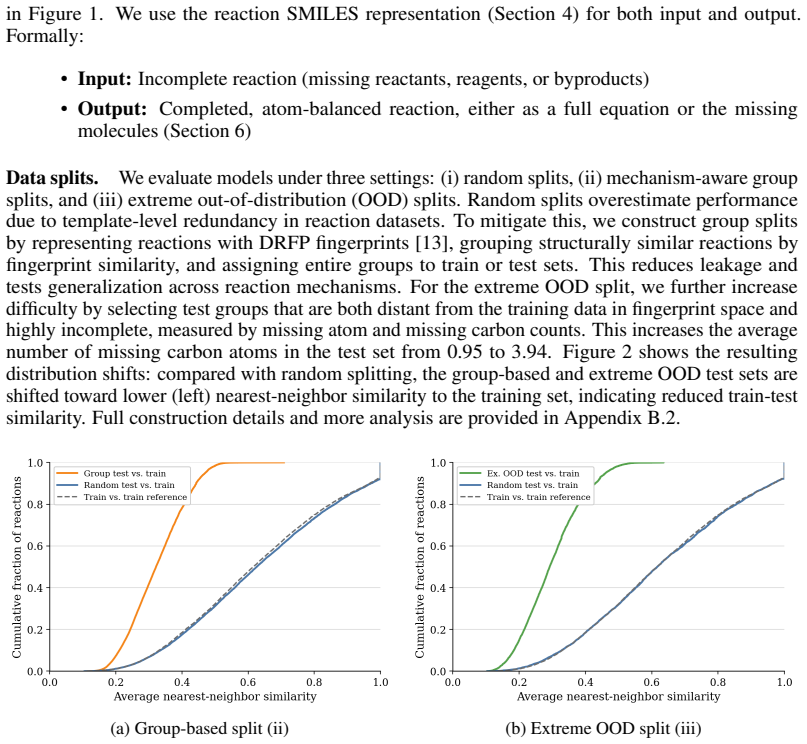
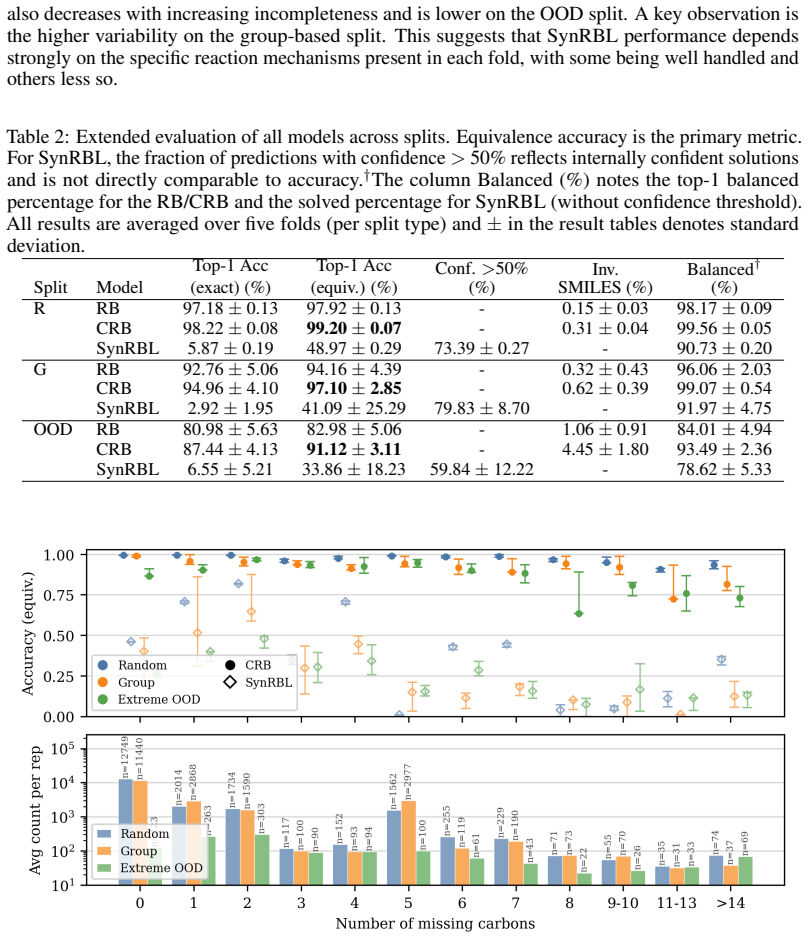
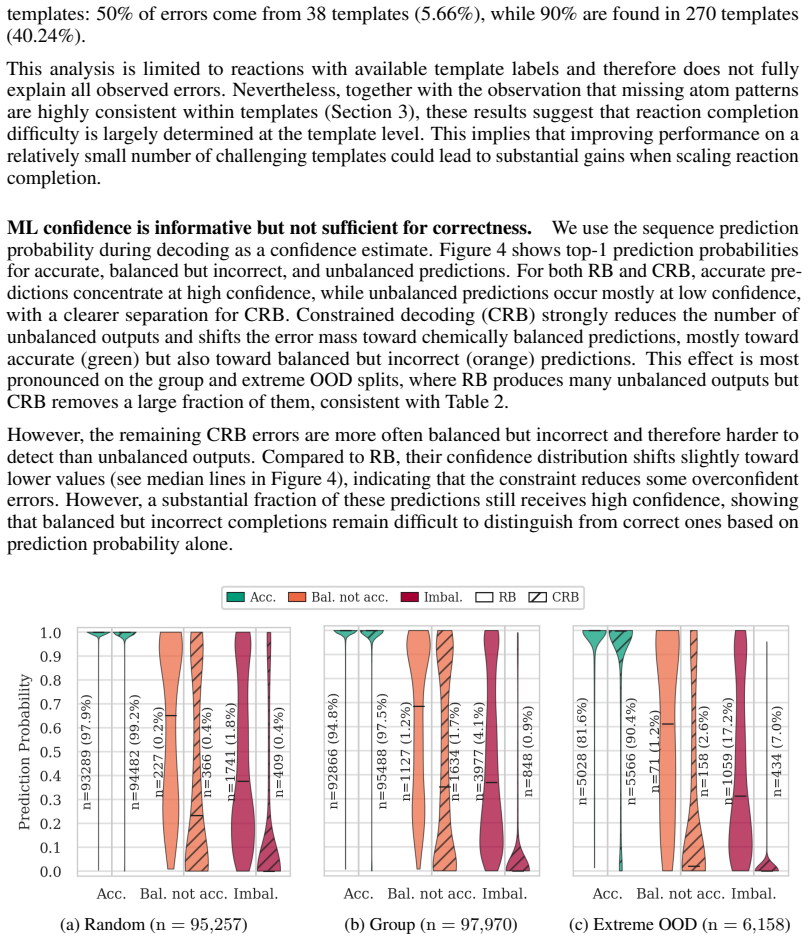
We construct CompleteRXN by mapping USPTO incomplete reactions to curated mechanistic reactions that supply the missing species and stoichiometric coefficients. The Constrained Reaction Balancer achieves 99.20% equivalence accuracy on random test splits and 91.12% on extreme out-of-distribution splits. SynRBL yields many balanced and plausible completions yet lower accuracy on the benchmark splits. All methods degrade with greater incompleteness, and performance declines substantially on the full uncurated USPTO set.
What carries the argument
The Constrained Reaction Balancer (CRB): an encoder-decoder neural network with constrained decoding that forces generated reaction completions to be atom-balanced.
If this is right
- Reaction completion becomes a learnable supervised task when aligned incomplete and balanced reaction pairs are available.
- Accuracy declines steadily as the degree of incompleteness or distributional shift in test reactions increases.
- Benchmark success does not guarantee high performance on raw, uncurated reaction collections, motivating more robust methods.
- Constrained decoding provides a practical way to enforce chemical validity during generation of completions.
Where Pith is reading between the lines
- Completed reaction data from this approach could serve as cleaner training material for downstream models that predict new reactions or plan syntheses.
- The alignment technique used to build the benchmark could be adapted to fill gaps in other large but incomplete scientific datasets.
- Models trained on CompleteRXN might be tested for robustness by deliberately adding controlled noise or missing entries to existing reaction collections.
Load-bearing premise
Aligning USPTO records with curated mechanistic reactions produces incomplete inputs that accurately reflect the kinds of missing data found in real chemical databases.
What would settle it
Manual chemical validation of many completions generated on the full uncurated USPTO set that shows frequent production of invalid or unbalanced reactions would demonstrate that benchmark results do not generalize to practical conditions.
Figures
read the original abstract
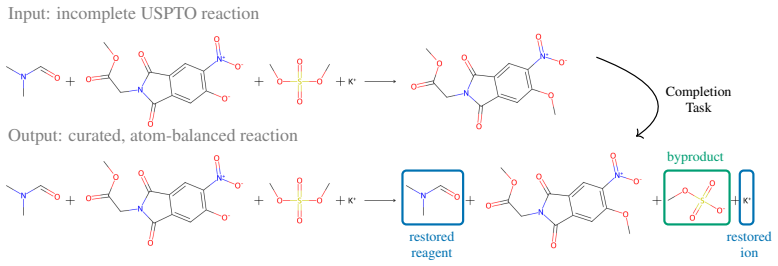
Chemical reaction datasets such as USPTO suffer from substantial incompleteness, frequently missing byproducts, co-reactants, and stoichiometric coefficients. This limits their applicability and reliability in downstream applications. Here, we introduce CompleteRXN, a large-scale supervised benchmark for reaction completion under realistic missing-data conditions. We construct a dataset of aligned incomplete and atom-balanced reactions by mapping USPTO records to curated mechanistic reactions. We evaluate representative baselines, including a novel encoder-decoder reaction completion model with constrained decoding, the Constrained Reaction Balancer (CRB), and a recent algorithmic method, SynRBL. On our CompleteRXN benchmark, the CRB achieves high performance across splits of increasing difficulty, reaching 99.20% equivalence accuracy on the random split and 91.12% on the extreme out-of-distribution split. SynRBL produces many balanced and chemically plausible completions, but with lower accuracy on the benchmark test splits. Across all methods, performance degrades with increasing incompleteness. We observe a substantial drop when evaluating on reactions outside the benchmark (full uncurated USPTO), highlighting the gap between benchmark performance and practical robustness and motivating future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CompleteRXN, a supervised benchmark for chemical reaction completion under missing-data conditions. It is constructed by aligning incomplete USPTO records with curated mechanistic reactions to produce atom-balanced pairs. The authors propose the Constrained Reaction Balancer (CRB), an encoder-decoder model with constrained decoding, and compare it to SynRBL. On the benchmark, CRB achieves 99.20% equivalence accuracy on the random split and 91.12% on the extreme out-of-distribution split, with performance degrading as incompleteness increases. A notable drop is observed when testing on the full uncurated USPTO dataset.
Significance. If the benchmark accurately models realistic incompleteness patterns in open chemical reaction databases, the CRB approach could significantly enhance the completeness and reliability of such datasets for downstream machine learning and chemical applications. The empirical results on increasing difficulty splits demonstrate the model's robustness within the benchmark, and the comparison with SynRBL provides useful baselines. However, the performance gap on uncurated data indicates that further validation is needed for practical impact.
major comments (3)
- Abstract: The construction of the CompleteRXN dataset via mapping USPTO records to curated mechanistic reactions is central to the claim of 'realistic missing-data conditions,' yet no quantitative validation is provided, such as overlap statistics between mapped missing fragments and actual USPTO omissions or inter-annotator agreement on alignments. This is load-bearing for the benchmark's validity.
- Abstract: The reported equivalence accuracies (99.20% random split, 91.12% extreme OOD) lack accompanying details on the definition of the equivalence metric, statistical significance tests, error bars, or exact rules for data exclusion and split construction, which are necessary to evaluate the reliability of these figures.
- Abstract: The substantial performance drop on the full uncurated USPTO dataset compared to the benchmark splits suggests that the constructed benchmark may not fully capture the distribution of real-world incompleteness, potentially limiting the generalizability of the CRB model's reported strengths.
minor comments (1)
- Abstract: The abstract mentions 'representative baselines' but provides limited details on the CRB architecture and training procedure; expanding this would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript introducing the CompleteRXN benchmark and CRB model. The comments highlight important areas for improving clarity and validation, and we have revised the manuscript accordingly to address them point by point.
read point-by-point responses
-
Referee: Abstract: The construction of the CompleteRXN dataset via mapping USPTO records to curated mechanistic reactions is central to the claim of 'realistic missing-data conditions,' yet no quantitative validation is provided, such as overlap statistics between mapped missing fragments and actual USPTO omissions or inter-annotator agreement on alignments. This is load-bearing for the benchmark's validity.
Authors: We agree that additional quantitative validation strengthens the benchmark. In the revised manuscript, we have expanded Section 3 to include overlap statistics comparing the types and frequencies of missing fragments in our aligned pairs against documented USPTO incompleteness patterns (e.g., missing byproducts and co-reactants). The alignment procedure is deterministic and based on atom mapping plus template matching from the curated mechanistic set; we have added a description of this algorithm along with results from a manual audit of a random sample of alignments to verify quality. We have also clarified that inter-annotator agreement does not apply directly as the process is automated rather than manual annotation. revision: yes
-
Referee: Abstract: The reported equivalence accuracies (99.20% random split, 91.12% extreme OOD) lack accompanying details on the definition of the equivalence metric, statistical significance tests, error bars, or exact rules for data exclusion and split construction, which are necessary to evaluate the reliability of these figures.
Authors: We apologize for the insufficient detail in the abstract. The equivalence metric is defined as the fraction of predictions where the completed reaction matches the ground-truth balanced reaction under canonical SMILES equivalence after atom balancing. In the revision, we have updated the abstract to briefly define the metric and added a new subsection in Methods detailing: (i) exact split construction rules (random 80/10/10, OOD by reaction class, extreme OOD by unseen templates), (ii) data exclusion criteria (invalid mappings, duplicate reactions, reactions with >10 missing atoms), and (iii) statistical reporting (error bars from 5 runs with different seeds and significance tests for method comparisons). revision: yes
-
Referee: Abstract: The substantial performance drop on the full uncurated USPTO dataset compared to the benchmark splits suggests that the constructed benchmark may not fully capture the distribution of real-world incompleteness, potentially limiting the generalizability of the CRB model's reported strengths.
Authors: We agree this performance gap is an important observation and already highlighted it in the original manuscript as motivation for future work. The drop arises because the benchmark uses controlled alignments to curated complete reactions, while uncurated USPTO includes additional noise (erroneous entries, non-standard notations, and omission patterns outside our alignment distribution). In the revised discussion, we have added analysis of error modes on the uncurated set and positioned CompleteRXN explicitly as a controlled testbed for progressive difficulty rather than a complete proxy for all real-world cases. revision: partial
Circularity Check
No circularity: performance claims rest on held-out empirical evaluation of a constructed benchmark
full rationale
The paper constructs CompleteRXN by mapping USPTO records to curated mechanistic reactions, then reports model accuracies on random and OOD splits of that dataset. These metrics are measured on test portions never used for construction or fitting, with no equations, self-citations, or renamings that reduce the reported numbers to the inputs by definition. The derivation chain consists of dataset creation followed by standard supervised evaluation; no load-bearing step collapses into a tautology or self-referential fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption USPTO records can be reliably mapped to curated mechanistic reactions to create aligned incomplete and atom-balanced pairs.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.