AutoDojo: Adaptive Black-Box Attacks Reveal the Limits of IPI Defenses and Task-Specification Effects in LLM Agents
Pith reviewed 2026-06-27 04:55 UTC · model grok-4.3
The pith
Adaptive black-box optimization of indirect prompt injections defeats nearly all current IPI defenses on LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
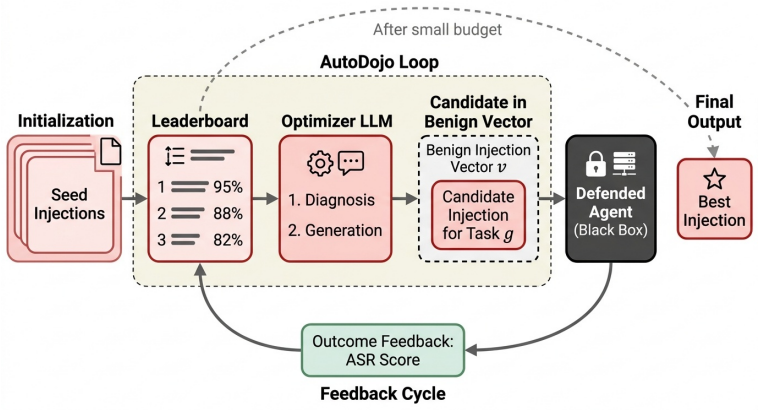
AutoDojo optimizes indirect prompt injections against a given defense through iterative black-box refinement with a frontier LLM. Evaluated across three task suites and five target models, it shows that many defenses offer only limited protection, with attack success rates rising well above static levels against nearly all approaches. Against one filter that reduces static ASR to 0%, AutoDojo recovers 28% overall and 64% on action-open tasks. Prompt-level and filter-based defenses exhibit substantially higher ASR on action-open tasks, where the injection can pose as ordinary data rather than explicit instructions, revealing a structural limit.
What carries the argument
AutoDojo, an adaptive black-box attack that uses iterative optimization by a frontier LLM to tailor indirect prompt injections against a specific defense.
If this is right
- Prompt-based and detection-based defenses provide only limited protection once an attacker can adapt the injection to the defense.
- Attack success rates are structurally higher on action-open tasks because injections can appear as ordinary data rather than instructions.
- Static benchmarks underestimate the robustness required against adaptive threats.
- System-level defenses remain to be tested under the same adaptive regime, but the pattern applies to the evaluated categories.
Where Pith is reading between the lines
- Agent developers should incorporate adaptive attack testing when validating any IPI defense.
- Task designs that delegate actions to untrusted content should be avoided or paired with stronger isolation.
- Defenses may need mechanisms that resist iterative refinement rather than fixed patterns.
- The gap between static and adaptive performance is likely to widen as attacker models improve.
Load-bearing premise
Iterative optimization by a frontier LLM constitutes a realistic and general black-box threat model that existing defenses must withstand.
What would settle it
A defense that maintains near-zero attack success rate when subjected to repeated AutoDojo-style iterative optimization across multiple task suites and models would falsify the limited-protection claim.
Figures


read the original abstract
Indirect prompt injection (IPI) is a major security threat to LLM-powered agents. Thus, a growing body of work have proposed a variety of defensive approaches against IPI. These can be grouped into three broad categories: 1) prompt-based (using prompting as a way to prevent agents from following malicious instructions), 2) detection-based (identifying and filtering malicious instructions), and 3) system-level (using systems insights, such as control and data isolation, for defense). However, commonly used benchmarks for evaluating defense, such as AgentDojo, are \emph{inherently static}, generating a fixed distribution of IPI attacks. Consequently, static benchmarks do not usefully evaluate defense robustness to adaptive threats. We address this issue by developing AutoDojo, an adaptive extension of AgentDojo that optimizes IPI against a given defense. Using AutoDojo against state-of-the-art IPI defenses across three task suites and five target models, we make two key observations. First, many defenses offer only limited protection: a cheap, black-box adaptive attack using a frontier LLM to iteratively optimize the injection raises attack success rate (ASR) well above the level achieved by static injections against nearly all evaluated defenses. Against a filter that reduces static ASR to 0\%, AutoDojo recovers 28\% overall and 64\% on action-open tasks. Second, for prompt-level and filter-based defenses, ASR is substantially higher on \emph{action-open} tasks -- where the user's request delegates the action itself to attacker-controlled content -- than on precisely specified tasks. This is a structural limit: on such tasks the injection can pose as ordinary data rather than an explicit instruction, bypassing defenses that rely on detecting instruction-like text. AutoDojo is publicly available at https://github.com/xhOwenMa/AutoDojo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AutoDojo, an adaptive black-box extension of the AgentDojo benchmark, that uses iterative optimization by a frontier LLM to generate indirect prompt injections (IPI) tailored to a given defense. It evaluates this against prompt-based, detection-based, and system-level IPI defenses across three task suites and five target models. The central empirical claims are that adaptive attacks raise ASR well above static-injection baselines (recovering 28% overall and 64% on action-open tasks against a filter achieving 0% static ASR) and that prompt-level and filter-based defenses exhibit substantially higher ASR on action-open tasks, where injections can masquerade as ordinary data.
Significance. If the results hold, the work supplies concrete evidence that existing IPI defenses have limited robustness to adaptive adversaries and identifies a structural weakness tied to task specification. The public release of AutoDojo at https://github.com/xhOwenMa/AutoDojo is a clear strength, supporting reproducibility. The findings could usefully inform future defense design in LLM-agent security.
major comments (2)
- [Abstract] Abstract, paragraph on AutoDojo development: the claim that the attack is a 'cheap, black-box' process that demonstrates defenses offer 'only limited protection' is load-bearing, yet no metrics are supplied on median queries to the target per successful optimization, relative strength of the optimizer LLM versus the target, or transferability of optimized injections to unseen defenses; without these the measured ASR gap does not yet establish that the threat model is realistic for plausible black-box adversaries.
- [Experimental evaluation] Experimental evaluation section: the reported ASR figures (28% overall, 64% on action-open tasks) are presented without error bars, number of runs, or the full iterative-optimization protocol (including stopping criteria and prompt templates used by the optimizer), which is necessary to evaluate statistical reliability and reproducibility of the central comparison against static baselines.
minor comments (2)
- [Abstract] Abstract: 'a growing body of work have proposed' contains a subject-verb agreement error and should read 'has proposed'.
- [Experimental evaluation] The manuscript would benefit from an explicit table listing per-defense query budgets or optimizer/target model pairs to make the black-box claim easier to assess at a glance.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate clarifications and additional data in the revised manuscript to strengthen the presentation of the threat model and experimental protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph on AutoDojo development: the claim that the attack is a 'cheap, black-box' process that demonstrates defenses offer 'only limited protection' is load-bearing, yet no metrics are supplied on median queries to the target per successful optimization, relative strength of the optimizer LLM versus the target, or transferability of optimized injections to unseen defenses; without these the measured ASR gap does not yet establish that the threat model is realistic for plausible black-box adversaries.
Authors: We agree that explicit metrics would better ground the 'cheap, black-box' characterization. In revision we will add: (1) median target-model queries per successful optimization run, (2) explicit comparison of optimizer (frontier LLM) versus each of the five target models, and (3) transfer results to held-out defenses where the optimized injections are evaluated without further adaptation. These additions will directly address the realism of the adaptive threat model while preserving the core finding that per-defense optimization recovers substantial ASR. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: the reported ASR figures (28% overall, 64% on action-open tasks) are presented without error bars, number of runs, or the full iterative-optimization protocol (including stopping criteria and prompt templates used by the optimizer), which is necessary to evaluate statistical reliability and reproducibility of the central comparison against static baselines.
Authors: We acknowledge that the current presentation omits these details. The revised manuscript will report the number of independent runs, include error bars on all ASR figures, and append the complete optimization protocol (stopping criteria, maximum iteration budget, and the exact prompt templates supplied to the optimizer LLM). The public AutoDojo repository already contains the implementation; the revision will make the experimental configuration fully reproducible from the paper alone. revision: yes
Circularity Check
No circularity; purely empirical evaluation of adaptive attack
full rationale
The paper develops AutoDojo as an empirical adaptive optimizer and reports measured ASR improvements against published defenses on AgentDojo benchmarks. No equations, fitted parameters, uniqueness theorems, or self-citation chains appear in the derivation of the central claims. The observations (adaptive ASR of 28%/64% vs static) rest on direct experimentation rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static benchmarks generate a fixed distribution of IPI attacks and therefore cannot evaluate robustness to adaptive threats.
Reference graph
Works this paper leans on
-
[1]
Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,” inAISec, 2023
2023
-
[2]
Llama Prompt Guard 2,
Meta AI, “Llama Prompt Guard 2,” https://huggingface.co/meta-llama/ Llama-Prompt-Guard-2-86M, 2025
2025
-
[3]
PIGuard: Prompt injection guardrail via mitigating overdefense for free,
H. Li, X. Liu, N. Zhang, and C. Xiao, “PIGuard: Prompt injection guardrail via mitigating overdefense for free,” inACL, 2025
2025
-
[4]
Defending against prompt injection with DataFilter,
Y . Wang, S. Chen, R. Alkhudair, B. Alomair, and D. Wagner, “Defending against prompt injection with DataFilter,”arXiv preprint arXiv:2510.19207, 2025
arXiv 2025
-
[5]
Defending against indirect prompt injection attacks with spotlighting,
K. Hines, G. Lopez, M. Hall, F. Zarfati, Y . Zunger, and E. Kiciman, “Defending against indirect prompt injection attacks with spotlighting,” arXiv preprint arXiv:2403.14720, 2024
Pith/arXiv arXiv 2024
-
[6]
The instruction hierarchy: Training LLMs to prioritize privileged instructions,
E. Wallace, K. Xiao, R. Leike, L. Weng, J. Heidecke, and A. Beutel, “The instruction hierarchy: Training LLMs to prioritize privileged instructions,”arXiv preprint arXiv:2404.13208, 2024
Pith/arXiv arXiv 2024
-
[7]
StruQ: Defending against prompt injection with structured queries,
S. Chen, J. Piet, C. Sitawarin, and D. Wagner, “StruQ: Defending against prompt injection with structured queries,”arXiv preprint arXiv:2402.06363, 2024
arXiv 2024
-
[8]
SecAlign: Defending against prompt injection with preference optimization,
S. Chen, A. Zharmagambetov, S. Mahloujifar, K. Chaudhuri, D. Wag- ner, and C. Guo, “SecAlign: Defending against prompt injection with preference optimization,” inCCS, 2025
2025
-
[9]
Progent: Securing AI agents with privilege control,
T. Shi, J. He, Z. Wang, H. Li, L. Wu, W. Guo, and D. Song, “Progent: Securing AI agents with privilege control,”arXiv preprint arXiv:2504.11703, 2025
Pith/arXiv arXiv 2025
-
[10]
DRIFT: Dynamic rule-based defense with injection isolation for securing LLM agents,
H. Li, X. Liu, H.-C. Chiu, D. Li, N. Zhang, and C. Xiao, “DRIFT: Dynamic rule-based defense with injection isolation for securing LLM agents,” inNeurIPS, 2025
2025
-
[11]
Prompt injection attacks on large language models: A survey of attack methods, root causes, and defense strategies,
T. Geng, Z. Xu, Y . Qu, and W. E. Wong, “Prompt injection attacks on large language models: A survey of attack methods, root causes, and defense strategies,”Computers, Materials & Continua, vol. 87, no. 1, 2026
2026
-
[12]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovi ´c, L. Beurer-Kellner, M. Fischer, and F. Tram `er, “AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” inNeurIPS Datasets and Benchmarks Track, 2024
2024
-
[13]
TopicAttack: An indirect prompt injection attack via topic transition,
Y . Chen, H. Li, Y . Li, Y . Liu, Y . Song, and B. Hooi, “TopicAttack: An indirect prompt injection attack via topic transition,”arXiv preprint arXiv:2507.13686, 2025
arXiv 2025
-
[14]
AgentVigil: Generic black-box red-teaming for indirect prompt injection against LLM agents,
Z. Wang, V . Siu, Z. Ye, T. Shi, Y . Nie, X. Zhao, C. Wang, W. Guo, and D. Song, “AgentVigil: Generic black-box red-teaming for indirect prompt injection against LLM agents,” inFindings of EMNLP, 2025
2025
-
[15]
Y . Wen, A. Zharmagambetov, I. Evtimov, N. Kokhlikyan, T. Goldstein, K. Chaudhuri, and C. Guo, “RL is a hammer and LLMs are nails: A simple reinforcement learning recipe for strong prompt injection,” arXiv preprint arXiv:2510.04885, 2025
arXiv 2025
-
[16]
M. Nasr, N. Carlini, C. Sitawarin, S. V . Schulhoff, J. Hayes, M. Ilie, J. Pluto, S. Song, H. Chaudhari, I. Shumailov, A. Thakurta, K. Y . Xiao, A. Terzis, and F. Tram `er, “The attacker moves second: Stronger adaptive attacks bypass defenses against LLM jailbreaks and prompt injections,”arXiv preprint arXiv:2510.09023, 2025
Pith/arXiv arXiv 2025
-
[17]
Ignore previous prompt: Attack techniques for language models,
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” inNeurIPS ML Safety Workshop, 2022
2022
-
[18]
Formalizing and benchmarking prompt injection attacks and defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses,” inUSENIX Security, 2024
2024
-
[19]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” inFindings of ACL, 2024
2024
-
[20]
Benchmarking and defending against indirect prompt injection attacks on large language models,
J. Yi, Y . Xie, B. Zhu, E. Kiciman, G. Sun, X. Xie, and F. Wu, “Benchmarking and defending against indirect prompt injection attacks on large language models,” inKDD, 2025
2025
-
[21]
Agent security bench (ASB): Formalizing and bench- marking attacks and defenses in LLM-based agents,
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (ASB): Formalizing and bench- marking attacks and defenses in LLM-based agents,”arXiv preprint arXiv:2410.02644, 2025
Pith/arXiv arXiv 2025
-
[22]
Fine-tuned DeBERTa-v3-base for prompt injection detection,
ProtectAI.com, “Fine-tuned DeBERTa-v3-base for prompt injection detection,” https://huggingface.co/protectai/ deberta-v3-base-prompt-injection-v2, 2024
2024
-
[23]
Embedding-based classifiers can detect prompt injection attacks,
M. A. Ayub and S. Majumdar, “Embedding-based classifiers can detect prompt injection attacks,”arXiv preprint arXiv:2410.22284, 2024
arXiv 2024
-
[24]
Attention is all you need to defend against indirect prompt injection attacks in LLMs,
Y . Zhong, Q. Miao, Y . Chen, J. Deng, Y . Cheng, and W. Xu, “Attention is all you need to defend against indirect prompt injection attacks in LLMs,”arXiv preprint arXiv:2512.08417, 2025
arXiv 2025
-
[25]
Mitigating indirect prompt injection via instruction-following intent analysis,
M. Kang, C. Xiang, S. Kariyappa, C. Xiao, B. Li, and E. Suh, “Mitigating indirect prompt injection via instruction-following intent analysis,”arXiv preprint arXiv:2512.00966, 2025
arXiv 2025
-
[26]
PromptLocate: Localizing prompt injection attacks,
Y . Jia, Y . Liu, Z. Shao, J. Jia, and N. Gong, “PromptLocate: Localizing prompt injection attacks,”arXiv preprint arXiv:2510.12252, 2025
arXiv 2025
-
[27]
CausalArmor: Efficient indirect prompt injection guardrails via causal attribution,
M. Kim, M. Parmar, P. Wallis, L. Miculicich, K. Jung, K. D. Dvijotham, L. T. Le, and T. Pfister, “CausalArmor: Efficient indirect prompt injection guardrails via causal attribution,”arXiv preprint arXiv:2602.07918, 2026
arXiv 2026
-
[28]
PromptArmor: Simple yet effective prompt injection defenses,
T. Shi, K. Zhu, Z. Wang, Y . Jia, W. Cai, W. Liang, H. Wang, H. Alzahrani, J. Lu, K. Kawaguchi, B. Alomair, X. Zhao, W. Y . Wang, N. Z. Gong, W. Guo, and D. Song, “PromptArmor: Simple yet effective prompt injection defenses,”arXiv preprint arXiv:2507.15219, 2025
arXiv 2025
-
[29]
Defeating prompt injections by design,
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tram`er, “Defeating prompt injections by design,”arXiv preprint arXiv:2503.18813, 2025
Pith/arXiv arXiv 2025
-
[30]
F. Wu, E. Cecchetti, and C. Xiao, “System-level defense against indi- rect prompt injection attacks: An information flow control perspective,” arXiv preprint arXiv:2409.19091, 2024
arXiv 2024
-
[31]
ACE: A security architecture for LLM-integrated app systems,
E. Li, T. Mallick, E. Rose, W. Robertson, A. Oprea, and C. Nita-Rotaru, “ACE: A security architecture for LLM-integrated app systems,” in NDSS, 2026
2026
-
[32]
Securing AI agents with information-flow control,
M. Costa, B. K ¨opf, A. Kolluri, A. Paverd, M. Russinovich, A. Salem, S. Tople, L. Wutschitz, and S. Zanella-B ´eguelin, “Securing AI agents with information-flow control,”arXiv preprint arXiv:2505.23643, 2025
Pith/arXiv arXiv 2025
-
[33]
Permissive information-flow analysis for large language models,
S. A. Siddiqui, R. Gaonkar, B. K ¨opf, D. Krueger, A. Paverd, A. Salem, S. Tople, L. Wutschitz, M. Xia, and S. Zanella-B ´eguelin, “Permissive information-flow analysis for large language models,”arXiv preprint arXiv:2410.03055, 2026
arXiv 2026
-
[34]
IsolateGPT: An execution isolation architecture for LLM-based agentic systems,
Y . Wu, F. Roesner, T. Kohno, N. Zhang, and U. Iqbal, “IsolateGPT: An execution isolation architecture for LLM-based agentic systems,” arXiv preprint arXiv:2403.04960, 2025
arXiv 2025
-
[35]
Prompt flow integrity to prevent privilege escalation in LLM agents,
J. Kim, W. Choi, and B. Lee, “Prompt flow integrity to prevent privilege escalation in LLM agents,”arXiv preprint arXiv:2503.15547, 2025
arXiv 2025
-
[36]
AgentArmor: Enforcing program analysis on agent runtime trace to defend against prompt injection,
P. Wang, Y . Liu, Y . Lu, Y . Cai, H. Chen, Q. Yang, J. Zhang, J. Hong, and Y . Wu, “AgentArmor: Enforcing program analysis on agent runtime trace to defend against prompt injection,”arXiv preprint arXiv:2508.01249, 2025
arXiv 2025
-
[37]
T. Zhang, Y . Xu, J. Wang, K. Guo, X. Xu, B. Xiao, Q. Guan, J. Fan, J. Liu, Z. Liu, and H. Hu, “AgentSentry: Mitigating indirect prompt injection in LLM agents via temporal causal diagnostics and context purification,”arXiv preprint arXiv:2602.22724, 2026
arXiv 2026
-
[38]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,”arXiv preprint arXiv:2310.08419, 2023
Pith/arXiv arXiv 2023
-
[39]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[40]
Automatic and universal prompt injection attacks against large language models,
X. Liu, Z. Yu, Y . Zhang, N. Zhang, and C. Xiao, “Automatic and universal prompt injection attacks against large language models,” arXiv preprint arXiv:2403.04957, 2024
arXiv 2024
-
[41]
Neural exec: Learning (and learning from) execution triggers for prompt injection attacks,
D. Pasquini, M. Strohmeier, and C. Troncoso, “Neural exec: Learning (and learning from) execution triggers for prompt injection attacks,” inAISec, 2024
2024
-
[42]
Imprompter: Tricking LLM agents into improper tool use,
X. Fu, S. Li, Z. Wang, Y . Liu, R. K. Gupta, T. Berg-Kirkpatrick, and E. Fernandes, “Imprompter: Tricking LLM agents into improper tool use,”arXiv preprint arXiv:2410.14923, 2024
arXiv 2024
-
[43]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples,
A. Athalye, N. Carlini, and D. Wagner, “Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples,” inICML, 2018
2018
-
[44]
On adaptive attacks to adversarial example defenses,
F. Tramer, N. Carlini, W. Brendel, and A. Madry, “On adaptive attacks to adversarial example defenses,” inNeurIPS, 2020
2020
-
[45]
Towards evaluating the robustness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” inIEEE S&P, 2017
2017
-
[46]
On evaluating adversarial robustness,
N. Carlini, A. Athalye, N. Papernot, W. Brendel, J. Rauber, D. Tsipras, I. Goodfellow, A. Madry, and A. Kurakin, “On evaluating adversarial robustness,”arXiv preprint arXiv:1902.06705, 2019
Pith/arXiv arXiv 1902
-
[47]
De- fenses against prompt attacks learn surface heuristics,
S. Li, C. Yu, Z. Ni, H. Li, C. Peris, C. Xiao, and Y . Zhao, “De- fenses against prompt attacks learn surface heuristics,”arXiv preprint arXiv:2601.07185, 2026
arXiv 2026
-
[48]
W. Zhu, X. Dong, X. Chen, R. Cai, P. Qiu, Z. Wang, O. Frunza, S. Tang, J. Gu, and Y . Wang, “Your agent is more brittle than you think: Uncovering indirect injection vulnerabilities in agentic LLMs,” arXiv preprint arXiv:2604.03870, 2026
Pith/arXiv arXiv 2026
-
[49]
AgentDyn: Are your agent security defenses deployable in real-world dynamic environments?
H. Li, R. Wen, S. Shi, N. Zhang, Y . V orobeychik, and C. Xiao, “AgentDyn: Are your agent security defenses deployable in real-world dynamic environments?”arXiv preprint arXiv:2602.03117, 2026
Pith/arXiv arXiv 2026
-
[50]
The task shield: Enforcing task alignment to defend against indirect prompt injection in LLM agents,
F. Jia, T. Wu, X. Qin, and A. Squicciarini, “The task shield: Enforcing task alignment to defend against indirect prompt injection in LLM agents,” inACL, 2025
2025
-
[51]
ASPI: Seeking ambiguity clarification ampli- fies prompt injection vulnerability in LLM agents,
U. M. Sehwag, Z. Shan, H. Liu, D. Lakshan, J. Brandifino, and M. Fenkell, “ASPI: Seeking ambiguity clarification ampli- fies prompt injection vulnerability in LLM agents,”arXiv preprint arXiv:2605.17324, 2026. Appendix A. Optimizer Prompts The AutoDojo loop uses two prompts (§4.1): ananalyzer that reads the leaderboard and proposes optimization strate- gi...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.