Unveiling the Visual Counting Bottleneck in Vision-Language Models
Pith reviewed 2026-06-28 23:29 UTC · model grok-4.3
The pith
Vision-language models fail at visual counting because they cannot map visual magnitudes onto number symbols.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
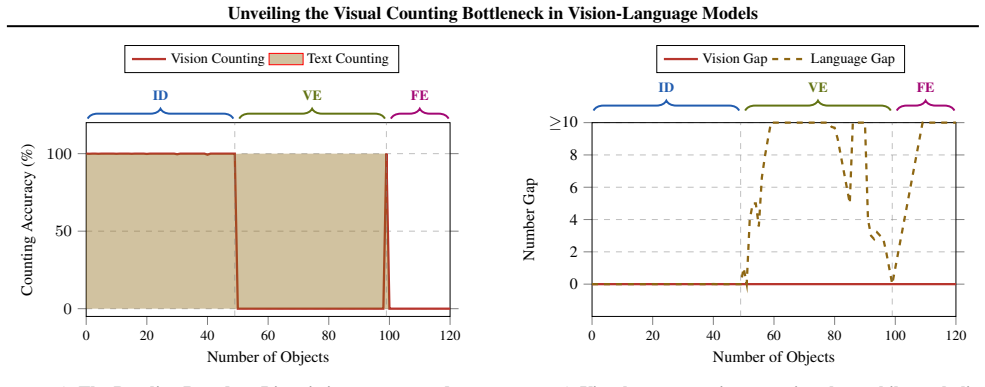
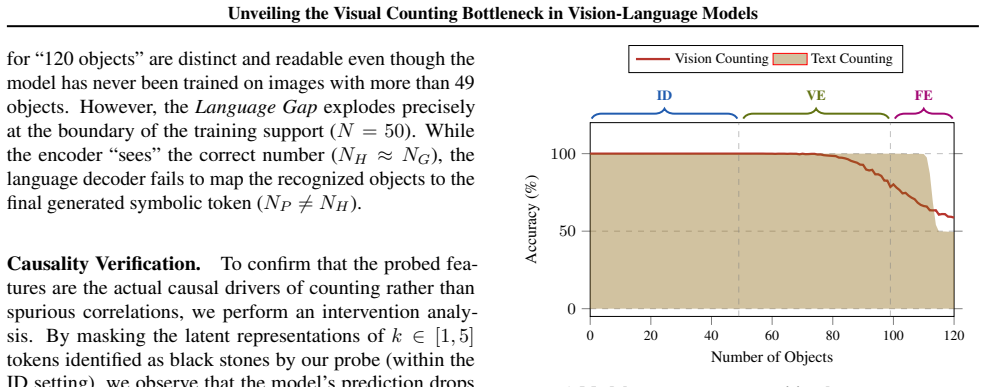
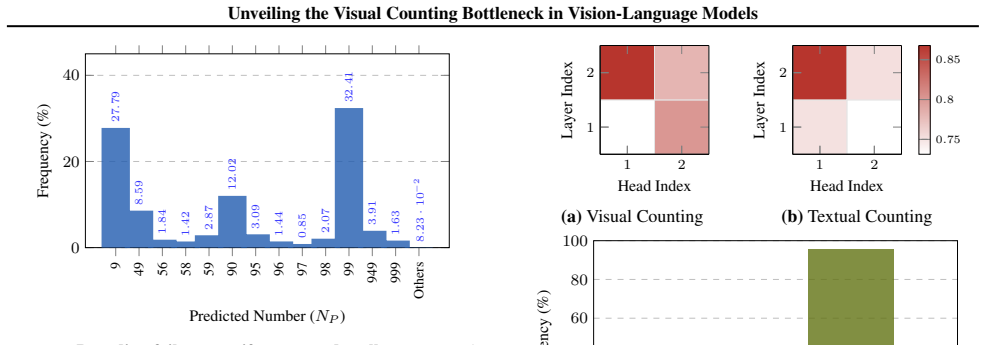
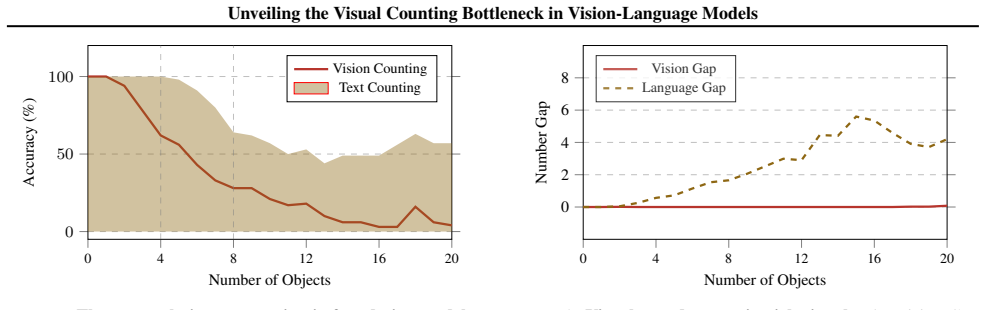
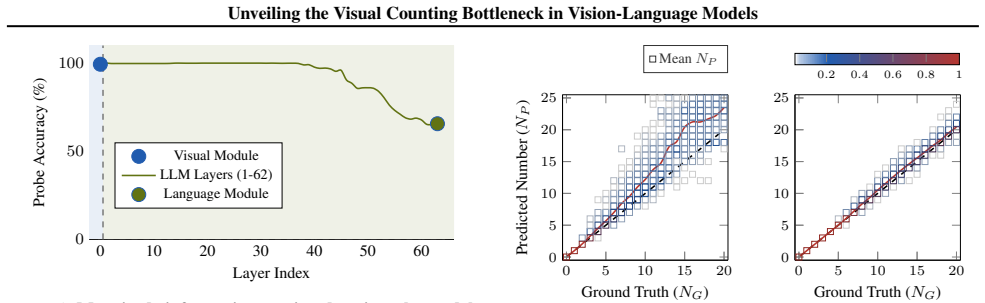
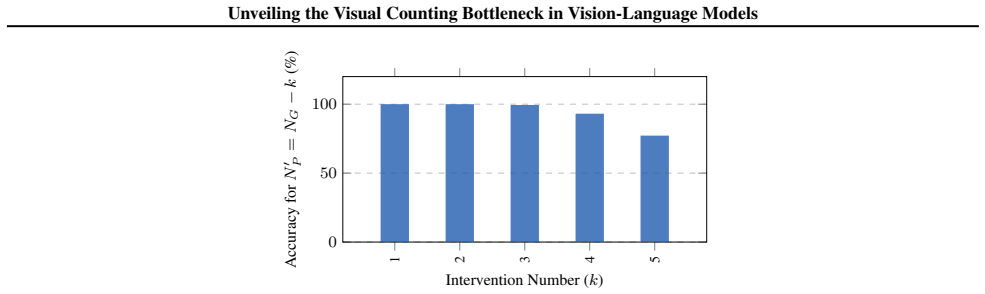
VLMs maintain robust, linearly separable representations of quantity in visual backbones well into the extrapolation regime and retain latent magnitude awareness that supports comparative reasoning, yet they fail to project those visual magnitudes onto symbolic tokens. The collapse at the symbolic mapping stage leads to the fractured magnitude hypothesis that VLMs acquire disjoint, modality-specific statistical manifolds instead of a universal number space, preventing cross-modal grounding for unseen quantities.
What carries the argument
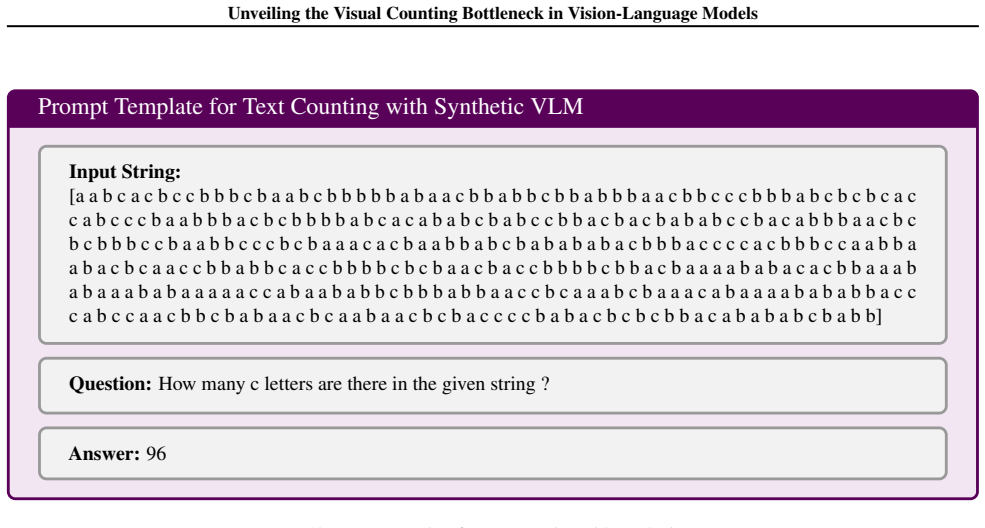
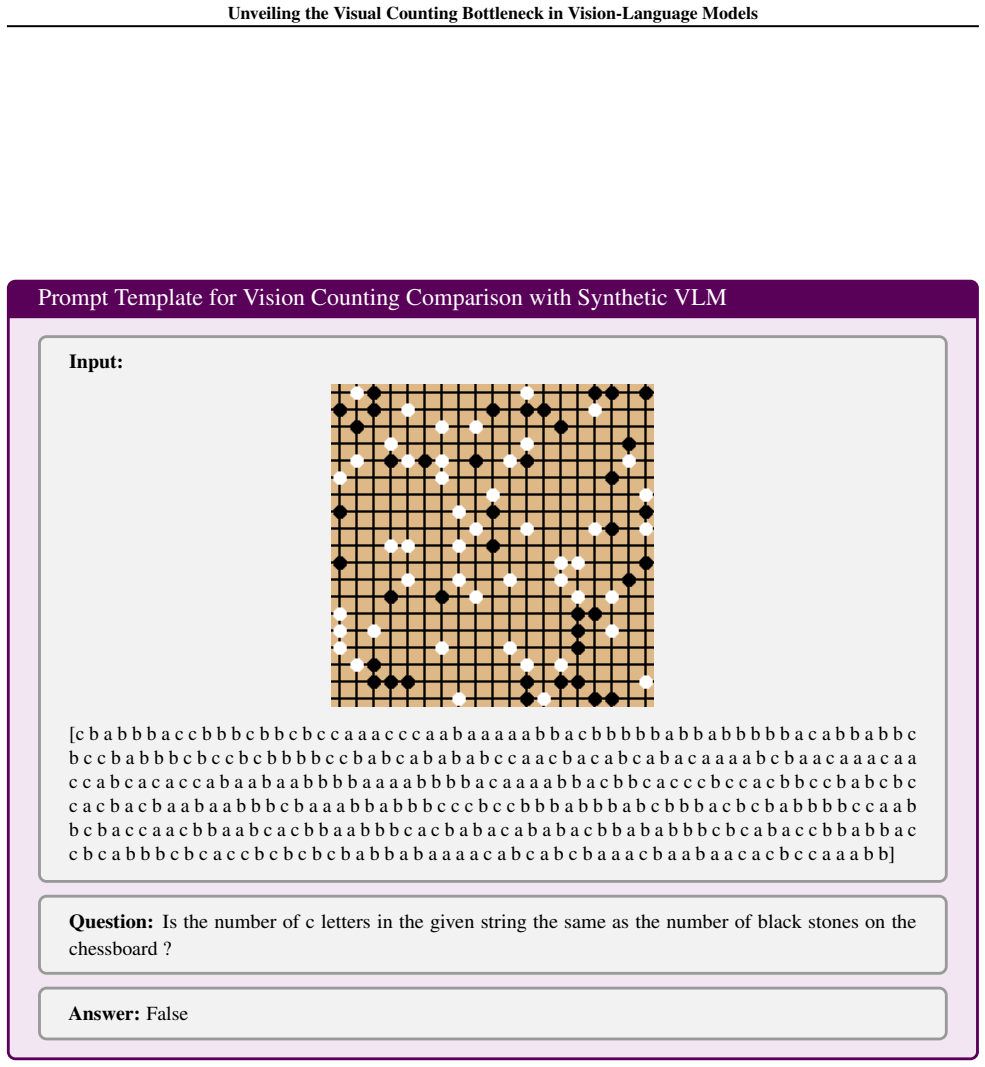
The three-stage decomposition of visual counting (visual individuation, magnitude awareness, symbolic mapping) tested with linear probes on synthetic Go board images.
If this is right
- Visual backbones preserve linearly separable quantity information beyond the training distribution.
- Models succeed at comparative magnitude tasks on quantities they cannot enumerate.
- Symbolic mapping is the specific stage that breaks cross-modal grounding for unseen counts.
- Data scaling alone cannot produce a unified number space across modalities.
- Inductive priors that enforce unified representations across vision and language are required for reliable extrapolation.
Where Pith is reading between the lines
- The same mapping failure may limit performance on other tasks that require precise numerical output from visual input, such as estimating sizes or durations.
- Training methods that force explicit alignment between visual magnitude signals and linguistic number tokens could be tested as a direct remedy.
- The fractured manifold view predicts that VLMs will show similar modality-specific number representations in domains beyond counting, such as basic arithmetic on images.
Load-bearing premise
Linear probes on synthetic Go board images capture the same quantity representations the model uses when counting objects in natural images.
What would settle it
Measure whether improving only the symbolic mapping component on extrapolation examples raises counting accuracy on natural images that contain novel quantities.
Figures






read the original abstract
While Large Vision-Language Models (VLMs) excel at interpolation, they suffer catastrophic failures in systematic generalization, most notably in visual counting. In this work, we investigate this extrapolation bottleneck by deconstructing visual counting into three cognitive stages: visual individuation, magnitude awareness, and symbolic mapping. Using synthetic Go boards and linear probes, we demonstrate that visual backbones maintain robust, linearly separable representations of quantity well into the extrapolation regime, ruling out perceptual failure. Furthermore, models retain latent magnitude awareness, successfully performing comparative reasoning on quantities they fail to enumerate. We pinpoint the collapse to the symbolic mapping stage, where the model fails to project valid visual magnitudes onto symbolic tokens. Our findings support a frac tured magnitude hypothesis: VLMs fail to acquire a universal number space, instead learning disjoint, modality-specific statistical manifolds that prevent cross-modal grounding for unseen quantities. Validated on the state-of-the-art foundation model, our results suggest that bridging this gap requires inductive priors enforcing unified representations, as data scaling alone is insufficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs suffer from a visual counting extrapolation bottleneck that can be isolated to the symbolic mapping stage rather than visual individuation or magnitude awareness. Using linear probes on synthetic Go board images, the authors show that visual backbones retain linearly separable quantity representations even in extrapolation regimes and that models can perform comparative reasoning on quantities they cannot enumerate, supporting a 'fractured magnitude hypothesis' in which VLMs learn disjoint modality-specific statistical manifolds instead of a universal number space. The work concludes that data scaling alone is insufficient and that inductive priors for unified cross-modal representations are needed.
Significance. If the central empirical dissociation holds, the paper offers a useful stage-wise decomposition of counting failures in VLMs and a concrete methodological template (linear probes on controlled synthetic stimuli) for diagnosing where representational collapse occurs. The finding that magnitude awareness persists while symbolic projection fails is potentially actionable for future architecture or training interventions. The explicit contrast between interpolation success and extrapolation failure, together with the comparative-reasoning control, strengthens the diagnostic value of the results.
major comments (2)
- [Abstract / methods] Abstract and methods (linear-probe experiments on synthetic Go boards): the claim that perceptual failure is ruled out rests on the assumption that success of linear probes in this highly regular, non-occluded grid setting implies the same quantity representations are available and used for natural-image counting. The skeptic concern is load-bearing because the paper's real-world extrapolation claim requires this generalization; without additional controls (e.g., probes on natural scenes or ablation of positional cues), the attribution of collapse exclusively to symbolic mapping does not fully follow.
- [Results] Results on comparative reasoning versus enumeration: while the dissociation is interesting, the manuscript does not report whether the comparative-reasoning probes were performed on the same held-out extrapolation quantities used for the enumeration task, nor whether performance remains high when the visual backbone is frozen versus fine-tuned. This detail is needed to confirm that latent magnitude awareness truly survives in the regime where symbolic mapping fails.
minor comments (2)
- [Abstract] Abstract contains a typographical error: 'frac tured' should be 'fractured'.
- [Discussion] The term 'fractured magnitude hypothesis' is introduced without a formal definition or falsifiable prediction; a short paragraph clarifying its precise empirical content would improve clarity.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive feedback, which helps clarify the scope and limitations of our findings. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract / methods] Abstract and methods (linear-probe experiments on synthetic Go boards): the claim that perceptual failure is ruled out rests on the assumption that success of linear probes in this highly regular, non-occluded grid setting implies the same quantity representations are available and used for natural-image counting. The skeptic concern is load-bearing because the paper's real-world extrapolation claim requires this generalization; without additional controls (e.g., probes on natural scenes or ablation of positional cues), the attribution of collapse exclusively to symbolic mapping does not fully follow.
Authors: We acknowledge that our experiments utilize controlled synthetic stimuli to isolate the cognitive stages of counting. This design choice enables precise manipulation of quantity while minimizing confounding factors present in natural images. While we agree that direct probes on natural scenes would provide stronger evidence for generalization, the success of linear probes in the extrapolation regime demonstrates that the visual backbone can extract quantity information even for unseen magnitudes in a setting where perceptual individuation is feasible. We will revise the manuscript to explicitly discuss this limitation and emphasize that our conclusions pertain to the controlled setting, with the implication that perceptual representations are intact under conditions where visual individuation succeeds. Additionally, we will include an ablation study on positional cues to address this concern. revision: partial
-
Referee: [Results] Results on comparative reasoning versus enumeration: while the dissociation is interesting, the manuscript does not report whether the comparative-reasoning probes were performed on the same held-out extrapolation quantities used for the enumeration task, nor whether performance remains high when the visual backbone is frozen versus fine-tuned. This detail is needed to confirm that latent magnitude awareness truly survives in the regime where symbolic mapping fails.
Authors: The comparative-reasoning experiments were indeed conducted on the same held-out extrapolation quantities as the enumeration task. Furthermore, all linear probes, including those for comparative reasoning, were performed with the visual backbone frozen to evaluate the pre-existing representations without any fine-tuning. We will update the methods and results sections to explicitly report these details, ensuring the dissociation is clearly tied to the extrapolation regime. revision: yes
Circularity Check
No circularity: empirical probe results on synthetic data
full rationale
The paper presents an empirical investigation using linear probes on synthetic Go board images to localize failure to the symbolic mapping stage. All load-bearing claims rest on direct experimental measurements (probe accuracy in extrapolation regime, comparative reasoning success) rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, ansatzes, or uniqueness theorems appear; the fractured magnitude hypothesis is offered as an interpretation of the probe outcomes, not a mathematical reduction to inputs. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes on visual backbone activations can reliably extract and demonstrate the presence of quantity information even in extrapolation regimes.
invented entities (1)
-
fractured magnitude hypothesis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fine-grained analysis of sentence embeddings using auxiliary prediction tasks
Adi, Y., Kermany, E., Belinkov, Y., Lavi, O., and Goldberg, Y. Fine-grained analysis of sentence embeddings using auxiliary prediction tasks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL https://openreview.net/forum?id=BJh6Ztuxl
2017
-
[2]
and Bengio, Y
Alain, G. and Bengio, Y. Understanding intermediate layers using linear classifier probes. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Workshop Track Proceedings . OpenReview.net, 2017. URL https://openreview.net/forum?id=HJ4-rAVtl
2017
-
[3]
V., Slone, A., Gur - Ari, G., Dyer, E., and Neyshabur, B
Anil, C., Wu, Y., Andreassen, A., Lewkowycz, A., Misra, V., Ramasesh, V. V., Slone, A., Gur - Ari, G., Dyer, E., and Neyshabur, B. Exploring length generalization in large language models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Inf...
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[5]
Bender, E. M. and Koller, A. Climbing towards NLU: on meaning, form, and understanding in the age of data. In Jurafsky, D., Chai, J., Schluter, N., and Tetreault, J. R. (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020 , pp.\ 5185--5198. Association for Computational Linguist...
-
[6]
Beyer, L., Steiner, A., Pinto, A. S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., Unterthiner, T., Keysers, D., Koppula, S., Liu, F., Grycner, A., Gritsenko, A. A., Houlsby, N., Kumar, M., Rong, K., Eisenschlos, J., Kabra, R., Bauer, M., Bosnjak, M., Chen, X., Minderer, M., Voigtlaender, P., Bica, I....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.07726 2024
-
[7]
The origin of concepts
Carey, S. The origin of concepts. Journal of Cognition and Development, 1 0 (1): 0 37--41, 2000
2000
-
[8]
The devil is in the detail: Simple tricks improve systematic generalization of transformers
Csord \' a s, R., Irie, K., and Schmidhuber, J. The devil is in the detail: Simple tricks improve systematic generalization of transformers. In Moens, M., Huang, X., Specia, L., and Yih, S. W. (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 Nov...
-
[9]
Was sind und was sollen die zahlen? In Was sind und was sollen die Zahlen?
Dedekind, R. Was sind und was sollen die zahlen? In Was sind und was sollen die Zahlen?. Stetigkeit und Irrationale Zahlen, pp.\ 1--47. Springer, 1965
1965
-
[10]
The number sense: How the mind creates mathematics
Dehaene, S. The number sense: How the mind creates mathematics. OUP USA, 2011
2011
-
[11]
K., Catt, E., Cundy, C., Hutter, M., Legg, S., Veness, J., and Ortega, P
Del \' e tang, G., Ruoss, A., Grau - Moya, J., Genewein, T., Wenliang, L. K., Catt, E., Cundy, C., Hutter, M., Legg, S., Veness, J., and Ortega, P. A. Neural networks and the chomsky hierarchy. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023. URL https://openreview.net/f...
2023
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 ...
2021
-
[13]
O ., Abdulkadir, A., Marrakchi, Y., B \
Falk, T., Mai, D., Bensch, R., C i c ek, \"O ., Abdulkadir, A., Marrakchi, Y., B \"o hm, A., Deubner, J., J \"a ckel, Z., Seiwald, K., et al. U-net: deep learning for cell counting, detection, and morphometry. Nature methods, 16 0 (1): 0 67--70, 2019
2019
-
[14]
Fodor, J. A. and Pylyshyn, Z. W. Connectionism and cognitive architecture: A critical analysis. Cognition, 28 0 (1-2): 0 3--71, 1988
1988
-
[15]
Vbench: Comprehensive benchmark suite for video generative models
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., Manocha, D., and Zhou, T. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, Jun...
-
[16]
Guo, X., Huang, Z., Shi, Z., Song, Z., and Zhang, J. Your vision-language model can't even count to 20: Exposing the failures of vlms in compositional counting. CoRR, abs/2510.04401, 2025. doi:10.48550/ARXIV.2510.04401. URL https://doi.org/10.48550/arXiv.2510.04401
-
[17]
Finding neurons in a haystack: Case studies with sparse probing
Gurnee, W., Nanda, N., Pauly, M., Harvey, K., Troitskii, D., and Bertsimas, D. Finding neurons in a haystack: Case studies with sparse probing. Trans. Mach. Learn. Res., 2023, 2023. URL https://openreview.net/forum?id=JYs1R9IMJr
2023
-
[18]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D
Hewitt, J. and Liang, P. Designing and interpreting probes with control tasks. In Inui, K., Jiang, J., Ng, V., and Wan, X. (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019 , pp.\ 2...
-
[19]
Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality
Hsieh, C., Zhang, J., Ma, Z., Kembhavi, A., and Krishna, R. Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, Ne...
2023
-
[20]
Revisiting Multimodal Positional Encoding in Vision-Language Models
Huang, J., Liu, X., Song, S., Hou, R., Chang, H., Lin, J., and Bai, S. Revisiting multimodal positional encoding in vision-language models. CoRR, abs/2510.23095, 2025. doi:10.48550/ARXIV.2510.23095. URL https://doi.org/10.48550/arXiv.2510.23095
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.23095 2025
-
[21]
Compositionality decomposed: How do neural networks generalise? J
Hupkes, D., Dankers, V., Mul, M., and Bruni, E. Compositionality decomposed: How do neural networks generalise? J. Artif. Intell. Res., 67: 0 757--795, 2020. doi:10.1613/JAIR.1.11674. URL https://doi.org/10.1613/jair.1.11674
-
[22]
Clip-count: Towards text-guided zero-shot object counting
Jiang, R., Liu, L., and Chen, C. Clip-count: Towards text-guided zero-shot object counting. In El - Saddik, A., Mei, T., Cucchiara, R., Bertini, M., Vallejo, D. P. T., Atrey, P. K., and Hossain, M. S. (eds.), Proceedings of the 31st ACM International Conference on Multimedia, MM 2023, Ottawa, ON, Canada, 29 October 2023- 3 November 2023 , pp.\ 4535--4545....
-
[23]
N., Das, P., and Reddy, S
Kazemnejad, A., Padhi, I., Ramamurthy, K. N., Das, P., and Reddy, S. The impact of positional encoding on length generalization in transformers. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS ...
2023
-
[24]
Lake, B. M. and Baroni, M. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. In Dy, J. G. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsm \" a ssan, Stockholm, Sweden, July 10-15, 2018 , volume 80 of Proceedings of Machine Learni...
2018
-
[25]
Lempitsky, V. S. and Zisserman, A. Learning to count objects in images. In Lafferty, J. D., Williams, C. K. I., Shawe - Taylor, J., Zemel, R. S., and Culotta, A. (eds.), Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems 2010. Proceedings of a meeting held 6-9 December 2010, Vancouver, Bri...
2010
-
[26]
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W. X., and Wen, J. Evaluating object hallucination in large vision-language models. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pp.\ 292--305. Association for Computational Lingui...
-
[27]
Marcus, G. F. The algebraic mind: Integrating connectionism and cognitive science. MIT press, 2003
2003
-
[28]
OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023. doi:10.48550/ARXIV.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[29]
Paiss, R., Ephrat, A., Tov, O., Zada, S., Mosseri, I., Irani, M., and Dekel, T. Teaching CLIP to count to ten. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023 , pp.\ 3147--3157. IEEE , 2023. doi:10.1109/ICCV51070.2023.00294. URL https://doi.org/10.1109/ICCV51070.2023.00294
-
[30]
T., Tenenbaum, J
Piantadosi, S. T., Tenenbaum, J. B., and Goodman, N. D. Bootstrapping in a language of thought: A formal model of numerical concept learning. Cognition, 123 0 (2): 0 199--217, 2012
2012
-
[31]
A., and Lewis, M
Press, O., Smith, N. A., and Lewis, M. Train short, test long: Attention with linear biases enables input length extrapolation. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=R8sQPpGCv0
2022
-
[32]
Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., et al. Language models are unsupervised multitask learners. OpenAI blog, 1 0 (8): 0 9, 2019
2019
-
[33]
Rahmanzadehgervi, P., Bolton, L., Taesiri, M. R., and Nguyen, A. T. Vision language models are blind. In Cho, M., Laptev, I., Tran, D., Yao, A., and Zha, H. (eds.), Computer Vision - ACCV 2024 - 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8-12, 2024, Proceedings, Part V , volume 15476 of Lecture Notes in Computer Science, pp.\ 293--...
-
[34]
U-net: Convolutional networks for biomedical image segmentation
Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Navab, N., Hornegger, J., III, W. M. W., and Frangi, A. F. (eds.), Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015 - 18th International Conference Munich, Germany, October 5 - 9, 2015, Proceedings, Part III , volume 9351 ...
-
[35]
Gemini: A Family of Highly Capable Multimodal Models
Team, G. Gemini: A family of highly capable multimodal models. CoRR, abs/2312.11805, 2023. doi:10.48550/ARXIV.2312.11805. URL https://doi.org/10.48550/arXiv.2312.11805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[36]
Team, G. Gemma 3 technical report. CoRR, abs/2503.19786, 2025. doi:10.48550/ARXIV.2503.19786. URL https://doi.org/10.48550/arXiv.2503.19786
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[37]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
Tenney, I., Das, D., and Pavlick, E. BERT rediscovers the classical NLP pipeline. In Korhonen, A., Traum, D. R., and M \` a rquez, L. (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers , pp.\ 4593--4601. Association for Computational Linguis...
-
[39]
Thrush, T., Jiang, R., Bartolo, M., Singh, A., Williams, A., Kiela, D., and Ross, C. Winoground: Probing vision and language models for visio-linguistic compositionality. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 , pp.\ 5228--5238. IEEE , 2022 b . doi:10.1109/CVPR52688.2022.00517. ...
-
[40]
Do NLP models know numbers? probing numeracy in embeddings
Wallace, E., Wang, Y., Li, S., Singh, S., and Gardner, M. Do NLP models know numbers? probing numeracy in embeddings. In Inui, K., Jiang, J., Ng, V., and Wan, X. (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong K...
-
[41]
H., Le, Q
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Proces...
2022
-
[42]
Xu, J., Le, H., Nguyen, V., Ranjan, V., and Samaras, D. Zero-shot object counting. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023 , pp.\ 15548--15557. IEEE , 2023. doi:10.1109/CVPR52729.2023.01492. URL https://doi.org/10.1109/CVPR52729.2023.01492
-
[43]
u ksekg \
Y \" u ksekg \" o n \" u l, M., Bianchi, F., Kalluri, P., Jurafsky, D., and Zou, J. When and why vision-language models behave like bags-of-words, and what to do about it? In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023 a . URL https://openreview.net/forum?id=KRLUvxh8uaX
2023
-
[44]
u ksekg \
Y \" u ksekg \" o n \" u l, M., Bianchi, F., Kalluri, P., Jurafsky, D., and Zou, J. When and why vision-language models behave like bags-of-words, and what to do about it? In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023 b . URL https://openreview.net/forum?id=KRLUvxh8uaX
2023
-
[45]
D., Tigges, C., Zhang, Z., Biderman, S., Raginsky, M., and Ringer, T
Zhang, S. D., Tigges, C., Zhang, Z., Biderman, S., Raginsky, M., and Ringer, T. Transformer-based models are not yet perfect at learning to emulate structural recursion. Trans. Mach. Learn. Res., 2024, 2024. URL https://openreview.net/forum?id=Ry5CXXm1sf
2024
-
[46]
Single-image crowd counting via multi-column convolutional neural network
Zhang, Y., Zhou, D., Chen, S., Gao, S., and Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016 , pp.\ 589--597. IEEE Computer Society, 2016. doi:10.1109/CVPR.2016.70. URL https://doi.org/10.1109/CVPR.2016.70
-
[47]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., and Smola, A. Multimodal chain-of-thought reasoning in language models. CoRR, abs/2302.00923, 2023. doi:10.48550/ARXIV.2302.00923. URL https://doi.org/10.48550/arXiv.2302.00923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.00923 2023
-
[48]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.