Online Reward-Punishment Learning from Fixed-Channel Perceptual Event Streams without Environment Rewards
Pith reviewed 2026-06-26 21:33 UTC · model grok-4.3
The pith
An agent can infer reward and punishment from perceptual transitions alone when no environment rewards are provided.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
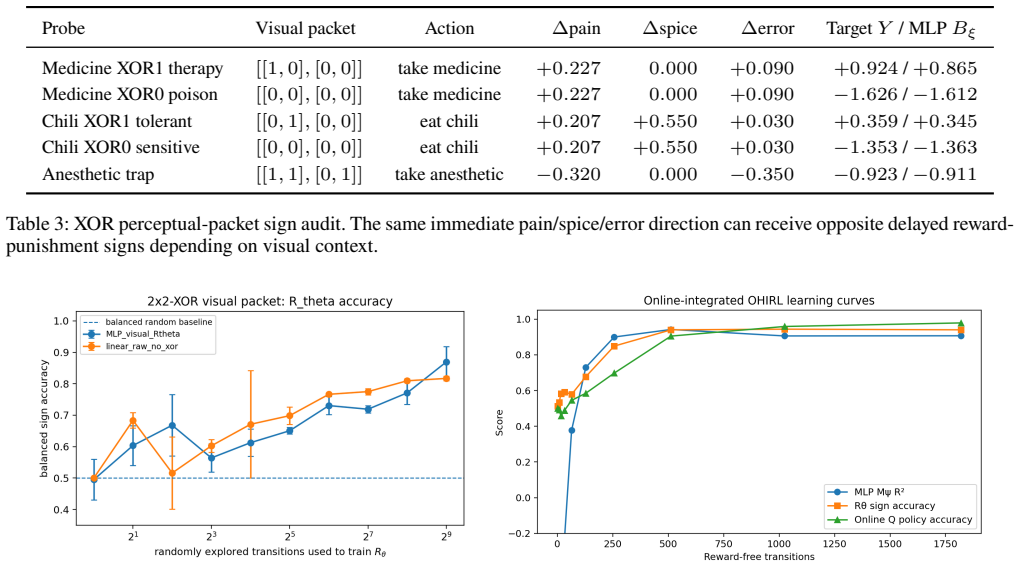
OHIRL separates four roles: M_psi learns next-packet prediction, D_omega models residual dynamics, C_eta is a fixed internal post-transition trajectory evaluator using a recovery-positive and persistence/growth-negative residual-regulation orientation, and B_xi learns to convert the resulting value evidence into policy updates and action scoring. This structure produces 0.952 balanced reward-sign accuracy on 2x2-XOR packets where medicine and chili acquire opposite values under visual contexts, and 0.979 optimal-action accuracy in interleaved online audits, while controls collapse.
What carries the argument
The fixed internal post-transition trajectory evaluator C_eta that applies a recovery-positive and persistence/growth-negative residual-regulation orientation to produce value evidence.
If this is right
- The same perceptual change such as pain or spice increase can be positive or negative depending on consequence structure.
- A coefficient-origin audit shows that equal-unit, raw-equal, and random monotone variants of C_eta preserve more than 92 percent of top-action rankings while sign inversion preserves zero percent.
- Conditional error decomposition isolates B_xi evidence-estimation error from residual policy-optimization error.
- Module-role ablations and public-context no-leakage audits confirm that each component is necessary for the reported accuracies.
Where Pith is reading between the lines
- The fixed-evaluator design could be applied to physical robots where external reward functions are difficult to specify in advance.
- Context-dependent valence inference may generalize to any domain where consistent internal rules can be applied to prediction residuals.
- Extending the protocol to longer-horizon perceptual streams would test whether the current separation of roles scales without additional mechanisms.
Load-bearing premise
The fixed internal evaluator C_eta supplies valid and generalizable value evidence that is not an artifact of its chosen orientation or the specific tasks tested.
What would settle it
Running the same tasks with the sign of C_eta inverted and observing whether B_xi accuracy remains above 0.9 or drops to chance levels while prediction accuracy stays high would directly test whether the evaluator supplies the claimed generalizable evidence.
Figures

read the original abstract
We study online reward-punishment learning when the environment provides no scalar reward or evaluative label. At each step the agent receives only a fixed-channel perceptual packet, and quantities such as pain, energy, contact, damage, or cognitive error are treated as perceptual dimensions whose valence must be inferred from transition consequences. OHIRL separates four roles: M_psi learns next-packet prediction, D_omega models residual dynamics, C_eta is a fixed internal post-transition trajectory evaluator, and B_xi learns to use the resulting value evidence for later policy updates and action scoring. C_eta uses a recovery-positive and persistence/growth-negative residual-regulation orientation; a coefficient-origin audit shows that equal-unit, raw-equal, and random monotone variants preserve more than 92% of the released top-action rankings, while sign inversion preserves 0%. The reward-free protocol exposes observation transitions while withholding environment rewards, delayed external evaluators, success labels, and action-goodness labels. A conditional error decomposition separates B_xi evidence-estimation error from residual policy-optimization error. In a 2x2-XOR packet task, medicine and chili acquire opposite value under visual XOR contexts, and the same pain or spice increase can be positive or negative depending on consequence structure; B_xi reaches 0.952 balanced reward-sign accuracy. In a full online-interleaved audit, M_psi reaches holdout R2=0.907, B_xi reaches 0.940 sign accuracy, and the policy reaches 0.979 optimal-action accuracy, while immediate packet scores, prediction-error rewards, shuffled targets, zero reward, and error-reduction controls collapse. Hidden-reward CartPole and Taxi controls, public-context no-leakage audits, and module-role ablations further test information boundaries and component necessity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OHIRL, a four-component framework (M_psi for next-packet prediction, D_omega for residual dynamics, fixed C_eta evaluator with recovery-positive/persistence-negative orientation, and B_xi for value-based policy learning) that enables online reward-punishment learning from perceptual packet streams without any environment rewards, labels, or external evaluators. It reports that in a 2x2-XOR packet task B_xi achieves 0.952 balanced reward-sign accuracy, while in a full online-interleaved audit the policy reaches 0.979 optimal-action accuracy (with M_psi at holdout R²=0.907 and B_xi at 0.940 sign accuracy), outperforming controls including immediate packet scores, prediction-error rewards, shuffled targets, zero reward, and error-reduction baselines; additional tests include hidden-reward CartPole/Taxi, no-leakage audits, and module ablations.
Significance. If the fixed C_eta orientation supplies valid, generalizable value evidence from transitions rather than task-specific alignment, the framework would offer a structured route to reward-free policy learning by cleanly separating prediction, residual modeling, internal evaluation, and policy optimization, with the conditional error decomposition and extensive control comparisons providing useful diagnostic tools. The coefficient-origin audit on ranking preservation is a constructive transparency measure.
major comments (3)
- [Abstract (C_eta description and coefficient-origin audit)] Abstract (C_eta description and coefficient-origin audit): the recovery-positive and persistence/growth-negative residual-regulation orientation is hand-specified and justified solely by an internal audit showing that equal-unit/raw-equal/random monotone variants preserve >92% of top-action rankings while sign inversion preserves 0%; this tests sensitivity only within the chosen orientation and does not establish that recovery-positive correctly tracks consequence valence in environments where recovery may be neutral or negative, which is load-bearing for the claim that B_xi accuracies (0.952/0.940) reflect genuine value evidence rather than construction of the 2x2-XOR and CartPole/Taxi tasks.
- [Abstract (performance claims and conditional error decomposition)] Abstract (performance claims and conditional error decomposition): the reported figures (0.952 balanced reward-sign accuracy, 0.979 optimal-action accuracy, 0.940 sign accuracy) are given without equations defining their computation, without dataset sizes or sampling details, without error bars, and without description of whether post-hoc selection occurred, preventing assessment of whether the separation from controls (immediate packet scores, prediction-error rewards, zero reward) is robust or an artifact of the evaluation protocol.
- [Abstract (task construction)] Abstract (task construction): the 2x2-XOR packet task and hidden-reward CartPole/Taxi controls are constructed such that the C_eta recovery-positive orientation aligns with the hidden consequence structure (e.g., medicine/chili acquiring opposite value under XOR contexts), leaving open whether the reported performance gap versus controls would persist under an orientation mismatch; this directly affects the generalizability of the reward-free claim.
minor comments (1)
- [Abstract] The abstract refers to 'conditional error decomposition' and 'module-role ablations' without naming the relevant sections or equations where these are formalized.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We respond point-by-point to the major comments below, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: Abstract (C_eta description and coefficient-origin audit): the recovery-positive and persistence/growth-negative residual-regulation orientation is hand-specified and justified solely by an internal audit showing that equal-unit/raw-equal/random monotone variants preserve >92% of top-action rankings while sign inversion preserves 0%; this tests sensitivity only within the chosen orientation and does not establish that recovery-positive correctly tracks consequence valence in environments where recovery may be neutral or negative, which is load-bearing for the claim that B_xi accuracies (0.952/0.940) reflect genuine value evidence rather than construction of the 2x2-XOR and CartPole/Taxi tasks.
Authors: The recovery-positive orientation is motivated by the perceptual packet setting, in which recovery from adverse states supplies the primary source of positive value evidence when no external rewards are available. The coefficient-origin audit shows robustness to scaling and randomization provided the sign orientation is held fixed, but we agree that it does not test environments in which recovery itself is neutral or negative. This is a genuine scope limitation of the fixed C_eta design. We will revise the abstract and add a limitations paragraph clarifying the assumption and its implications for generalizability. revision: partial
-
Referee: Abstract (performance claims and conditional error decomposition): the reported figures (0.952 balanced reward-sign accuracy, 0.979 optimal-action accuracy, 0.940 sign accuracy) are given without equations defining their computation, without dataset sizes or sampling details, without error bars, and without description of whether post-hoc selection occurred, preventing assessment of whether the separation from controls (immediate packet scores, prediction-error rewards, zero reward) is robust or an artifact of the evaluation protocol.
Authors: Equations for balanced reward-sign accuracy, optimal-action accuracy, sign accuracy, and the conditional error decomposition appear in Sections 3.2 and 4.1. Dataset sizes, sampling procedures, and results with standard deviations over five independent seeds are reported in Section 5 and the appendices; no post-hoc selection was performed. We will insert a short clause in the abstract directing readers to these definitions and the evaluation protocol. revision: yes
-
Referee: Abstract (task construction): the 2x2-XOR packet task and hidden-reward CartPole/Taxi controls are constructed such that the C_eta recovery-positive orientation aligns with the hidden consequence structure (e.g., medicine/chili acquiring opposite value under XOR contexts), leaving open whether the reported performance gap versus controls would persist under an orientation mismatch; this directly affects the generalizability of the reward-free claim.
Authors: The tasks are deliberately constructed to exhibit context-dependent valence, which is the central difficulty the framework addresses. Performance is expected to degrade under deliberate orientation mismatch, as the audit already indicates that sign inversion destroys ranking preservation. We will add a discussion paragraph on the dependence of the reward-free claim on appropriate orientation alignment and identify learned or adaptive evaluators as future work. revision: partial
Circularity Check
Derivation self-contained with no circular reductions
full rationale
The paper explicitly defines C_eta as a fixed, hand-specified internal evaluator with a chosen recovery-positive orientation, and B_xi learns policy updates from its outputs. This is a modeling choice, not a derivation that reduces to itself by construction. The coefficient-origin audit tests sensitivity of rankings to coefficient variants but does not make the reported accuracies (0.952, 0.979) tautological with the inputs. No self-citations, no fitted parameters renamed as predictions, and no uniqueness theorems imported from prior author work. Performance separation from controls (immediate scores, zero reward, etc.) is shown empirically on tasks with hidden consequence structure. The chain from perceptual packets through M_psi/D_omega/C_eta to B_xi policy is independent of the target metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- C_eta orientation rule
axioms (1)
- domain assumption Perceptual packets contain sufficient information to infer valence from transition consequences
invented entities (1)
-
C_eta fixed evaluator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI Gym. arXiv:1606.01540. Chevalier-Boisvert, M.; Dai, B.; Towers, M.; Perez-Vicente, R.; Willems, L.; Lahlou, S.; Pal, S.; Castro, P. S.; and Terry, J
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Diversity Is All You Need: Learning Skills without a Reward Function. In ICLR. Friston,K.2010.TheFree-EnergyPrinciple:AUnifiedBrainThe- ory?Nature Reviews Neuroscience, 11(2): 127–138. Friston, K.; FitzGerald, T.; Rigoli, F.; Schwartenbeck, P.; and Pez- zulo,G.2017.ActiveInference:AProcessTheory.NeuralCompu- tation, 29(1): 1–49. Hafner, D.; Pasukonis, J.;...
2010
-
[3]
Mastering Diverse Domains through World Models
Mastering Diverse Domains through World Models.arXiv:2301.04104. Haarnoja,T.;Zhou,A.;Abbeel,P.;andLevine,S.2018.SoftActor- Critic: Off-Policy Maximum Entropy Deep Reinforcement Learn- ing with a Stochastic Actor. InICML. Henaff, M.; Raileanu, R.; Jiang, M.; and Rocktaschel, T
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
InNeurIPS
Exploration via Elliptical Episodic Bonuses. InNeurIPS. Juechems,K.;andSummerfield,C.2019.WhereDoesValueCome From?Trends in Cognitive Sciences, 23(10): 836–850. Keramati, M.; and Gutkin, B
2019
-
[5]
Laskin,M.;Yarats,D.;Liu,H.;Lee,K.;Zhan,A.;Lu,K.;Cang,C.; Pinto,L.;andAbbeel,P.2021.URLB:UnsupervisedReinforcement Learning Benchmark
A Reinforcement Learning TheoryforHomeostaticRegulation.PsychologicalReview,118(4): 604–644. Laskin,M.;Yarats,D.;Liu,H.;Lee,K.;Zhan,A.;Lu,K.;Cang,C.; Pinto,L.;andAbbeel,P.2021.URLB:UnsupervisedReinforcement Learning Benchmark. InNeurIPS Datasets and Benchmarks. Pathak, D.; Agrawal, P.; Efros, A. A.; and Darrell, T
2021
-
[6]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms. arXiv:1707.06347. Sekar, R.; Rybkin, O.; Daniilidis, K.; Abbeel, P.; Hafner, D.; and Pathak, D
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MuJoCo: A Physics Engine for Model-Based Control. InIROS. Abbeel,P.;andNg,A.Y.2004.ApprenticeshipLearningviaInverse Reinforcement Learning. InICML. Bellemare,M.G.;Srinivasan,S.;Ostrovski,G.;Schaul,T.;Saxton, D.; and Munos, R
2004
-
[8]
Curiosity-Critic: Cumulative Prediction Error Improvement as a Tractable Intrinsic Reward for World Model Training.arXiv:2604.18701. Christiano, P. F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; and Amodei,D.2017.DeepReinforcementLearningfromHumanPref- erences. InNeurIPS. Du, Y.; Winnicki, A.; Dalal, G.; Mannor, S.; and Srikant, R
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Exploration-Driven Policy Optimization in RLHF: Theoretical In- sights on Efficient Data Utilization.arXiv:2402.10342. Hou,Z.;An,Z.;andDu,W.2025.BeyondNoisy-TVs:Noise-Robust Exploration via Learning Progress Monitoring.arXiv:2509.25438. Kearns, M.; and Singh, S
-
[10]
Puterman, M
Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research, 12: 2825–2830. Puterman, M. L. 1994.Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley. Schmidhuber, J
1994
-
[11]
Sutton, R
A Possibility for Implementing Curiosity andBoredominModel-BuildingNeuralControllers.InProc.SAB. Sutton, R. S.; and Barto, A. G. 2018.Reinforcement Learning: An Introduction. MIT Press, 2nd edition. Tang,H.;Houthooft,R.;Foote,D.;Stooke,A.;Chen,X.;Duan,Y.; Schulman, J.; De Turck, F.; and Abbeel, P
2018
-
[12]
Wagenmaker, A.; Chen, Y.; Simchowitz, M.; Du, S
Intrinsic Rewards for ExplorationwithoutHarmfromObservationalNoise:ASimulation Study Based on the Free Energy Principle.arXiv:2405.07473. Wagenmaker, A.; Chen, Y.; Simchowitz, M.; Du, S. S.; and Jamieson, K
-
[13]
Reward-Free RL is No Harder Than Reward- Aware RL in Linear Markov Decision Processes. InCOLT. Yuan,M.;Castanyer,R.C.;Li,B.;Jin,X.;Berseth,G.;andZeng,W. 2024.RLeXplore:AcceleratingResearchinIntrinsically-Motivated Reinforcement Learning.arXiv:2405.19548. Ziebart, B. D.; Maas, A.; Bagnell, J. A.; and Dey, A. K
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.