TeleMorpher: Toward Robust Simultaneous Motion-Location Editing
Pith reviewed 2026-06-26 18:03 UTC · model grok-4.3
The pith
TeleMorpher performs simultaneous motion and location editing in videos through a one-shot pipeline that disentangles the subject and injects warped motion guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
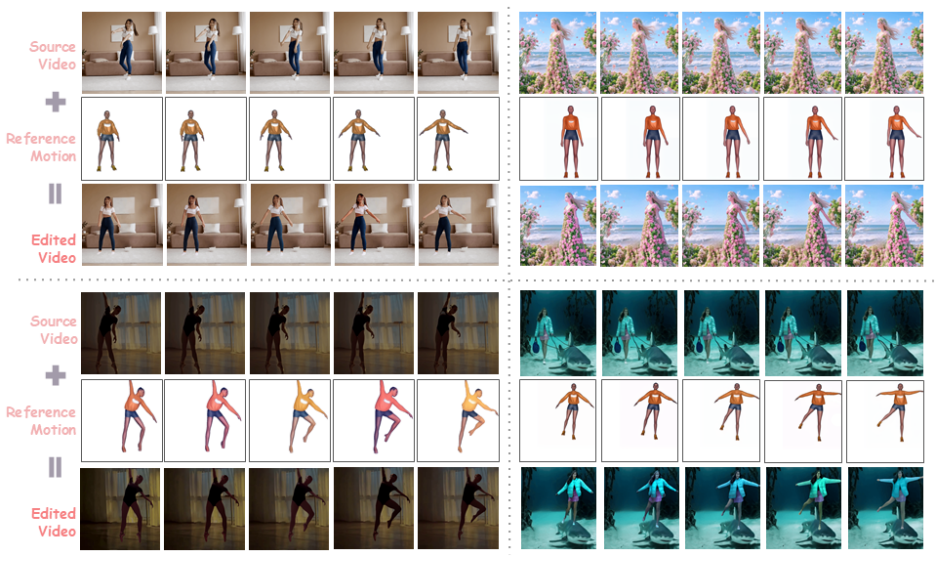
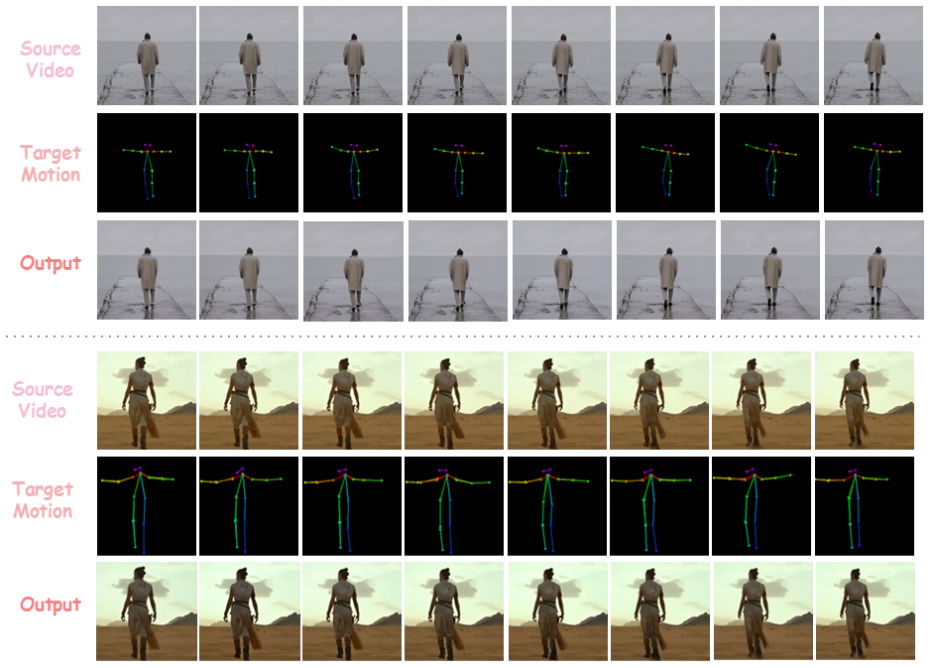
TeleMorpher is a one-shot framework for simultaneous motion-location editing that uses a motion prior from an off-the-shelf generator together with ground-truth motion to guide a training-free pose warping step; the warped output is then injected into a baseline motion editor so that source appearance is preserved while both motion and location are altered in a controllable way.
What carries the argument
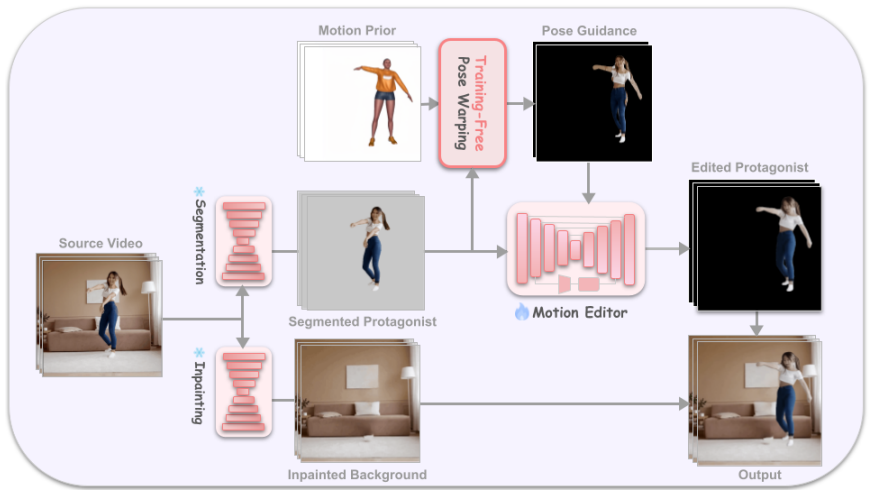
Four-step pipeline of protagonist-background disentanglement via segmentation and inpainting, training-free pose warping guided by a motion-centric target video, direct injection of the warped result into a baseline motion editor, and two new LPIPS-based metrics for background consistency and skeleton fidelity.
If this is right
- Motion and location can be edited together without retraining the underlying diffusion model.
- The method works on real-world videos using only pre-trained components.
- New LPIPS metrics provide a more stable way to score background preservation and motion accuracy.
- Appearance of the source video is maintained while the target motion is followed more closely.
Where Pith is reading between the lines
- The reliance on separate pre-trained models suggests the approach could be combined with other generative tools for additional effects such as style or lighting changes.
- If the injection step scales to longer sequences, the same pipeline might support multi-shot video editing without manual keyframing.
- The emphasis on training-free warping opens a route to adapting the method quickly to new motion priors as better generators appear.
Load-bearing premise
Off-the-shelf segmentation, inpainting, and motion-centric generators will separate the protagonist cleanly enough that later injection can fix any remaining artifacts.
What would settle it
A side-by-side comparison in which the injected output shows persistent background flickering or protagonist distortion that human raters consistently rate lower than the baseline editor alone.
Figures







read the original abstract
Diffusion models have achieved remarkable success in image and video generation and editing. While recent studies have extended these efforts toward motion editing, simultaneously transforming both motion and location-despite its practical importance-remains largely unexplored. To better understand robust motion-location editing, we first analyze the fundamental factors that degrade its quality. Based on this analysis, we propose TeleMorpher, one of the first one-shot frameworks to the best of our knowledge, for simultaneous motion-location editing. Our approach leverages motion priors, a target motion-centric video generated from an off-the-shelf model as motion-editing guidance, and the ground truth motion to enable more controllable and precise motion-location editing. Via this, our framework works as follows: (1) we first disentangle the protagonist and the background via pre-trained segmentation and inpainting models. (2) Then, we introduce a training-free pose warping that edits the protagonist's motion with the motion prior as the guidance. (3) The result of warped motion video is directly injected into a baseline motion editor during inference, mitigating the difference between source and target motions while preserving the appearance of the source video. (4) To enhance the reliability of quantitative evaluations, we propose two new LPIPS-based metrics that measure the background consistency before and after the motion editing and the fidelity of motion editing performance via measuring the difference between the extracted protagonist's skeletons from source and target videos. Experiments with in-the-wild videos and the TaiChi dataset demonstrate that TeleMorpher achieves superior performance across both quantitative and qualitative measurements (real-human evaluation), underscoring its effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TeleMorpher, a one-shot framework for simultaneous motion-location editing in videos. It first analyzes factors degrading quality, then proposes a four-step pipeline: (1) disentangle protagonist/background via pre-trained segmentation/inpainting, (2) training-free pose warping of protagonist motion guided by a motion-centric video from an off-the-shelf generator, (3) direct injection of the warped result into a baseline motion editor at inference time, and (4) two new LPIPS-based metrics measuring background consistency and motion fidelity (via skeleton differences). Experiments on in-the-wild videos and TaiChi dataset report superior quantitative and qualitative (human) performance.
Significance. If the central claims hold, the work addresses an underexplored practical task in video editing by offering a training-free method that combines motion priors with existing models. The proposed LPIPS-based metrics represent a concrete contribution that could improve evaluation standards. The injection technique for mitigating motion differences while preserving appearance has potential applicability beyond the specific setting.
major comments (3)
- [§3.1] §3.1 (pipeline step 1): The framework assumes pre-trained segmentation and inpainting models produce clean protagonist disentanglement on in-the-wild and TaiChi videos. No quantitative robustness analysis, failure-case quantification, or ablation on segmentation error propagation to steps (2)–(3) is provided; this assumption is load-bearing for the 'robust' and 'superior performance' claims.
- [§4] §4 (experiments): Superior performance is asserted across quantitative metrics and real-human evaluation, yet the manuscript provides no ablations isolating the contribution of the motion-prior guidance, the injection step, or the new metrics versus the baseline motion editor alone. Without these, attribution of gains to the proposed components remains unclear.
- [§3.4] §3.4 (new metrics): The two LPIPS-based metrics are defined to measure background consistency and motion fidelity via extracted skeletons, but the precise computation (e.g., region masking for background LPIPS, skeleton extraction method, normalization) is not given in sufficient detail for independent verification or to confirm they avoid trivial correlations with the editing pipeline.
minor comments (2)
- [Abstract] Abstract: The claim that the approach 'mitigates the difference between source and target motions' would benefit from a brief statement of how the injection step interacts with the baseline editor's internal conditioning.
- [§2] §2 (related work): A short comparison table or explicit positioning against the most recent motion-editing diffusion methods would clarify the novelty of the simultaneous motion-location setting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (pipeline step 1): The framework assumes pre-trained segmentation and inpainting models produce clean protagonist disentanglement on in-the-wild and TaiChi videos. No quantitative robustness analysis, failure-case quantification, or ablation on segmentation error propagation to steps (2)–(3) is provided; this assumption is load-bearing for the 'robust' and 'superior performance' claims.
Authors: We agree that the quality of protagonist disentanglement is foundational and that explicit robustness analysis would strengthen the claims. While the pipeline relies on established pre-trained models and our qualitative results on the evaluated datasets indicate reliable performance, we will add a quantitative robustness study (including failure-case examples and propagation analysis) in the revised manuscript. revision: yes
-
Referee: [§4] §4 (experiments): Superior performance is asserted across quantitative metrics and real-human evaluation, yet the manuscript provides no ablations isolating the contribution of the motion-prior guidance, the injection step, or the new metrics versus the baseline motion editor alone. Without these, attribution of gains to the proposed components remains unclear.
Authors: The reported experiments emphasize end-to-end comparisons against baselines. To clarify attribution, we will incorporate ablations that isolate the motion-prior guidance and the direct-injection step (comparing variants against the baseline motion editor) in the revised experimental section. revision: yes
-
Referee: [§3.4] §3.4 (new metrics): The two LPIPS-based metrics are defined to measure background consistency and motion fidelity via extracted skeletons, but the precise computation (e.g., region masking for background LPIPS, skeleton extraction method, normalization) is not given in sufficient detail for independent verification or to confirm they avoid trivial correlations with the editing pipeline.
Authors: We will expand Section 3.4 with the missing implementation details, including the precise region masking procedure for background LPIPS, the skeleton extraction pipeline, and normalization steps. This will enable independent verification and allow readers to assess potential correlations. revision: yes
Circularity Check
No significant circularity; pipeline and evaluation are independent of self-defined quantities.
full rationale
The paper presents a four-step engineering pipeline relying on off-the-shelf pre-trained models for disentanglement, a training-free pose warping step, direct injection into a baseline editor, and two newly proposed LPIPS-based metrics for evaluation. No equations, fitted parameters, or derivations are described that reduce by construction to their own inputs. The performance claims rest on experimental results using these metrics and human evaluation rather than any self-referential definition or self-citation chain. The central method does not invoke uniqueness theorems or smuggle ansatzes via prior self-work. This is a standard non-circular description of a proposed system.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
2022
-
[3]
Flexible diffusion modeling of long videos.Advances in Neural Information Processing Systems, 35:27953–27965, 2022
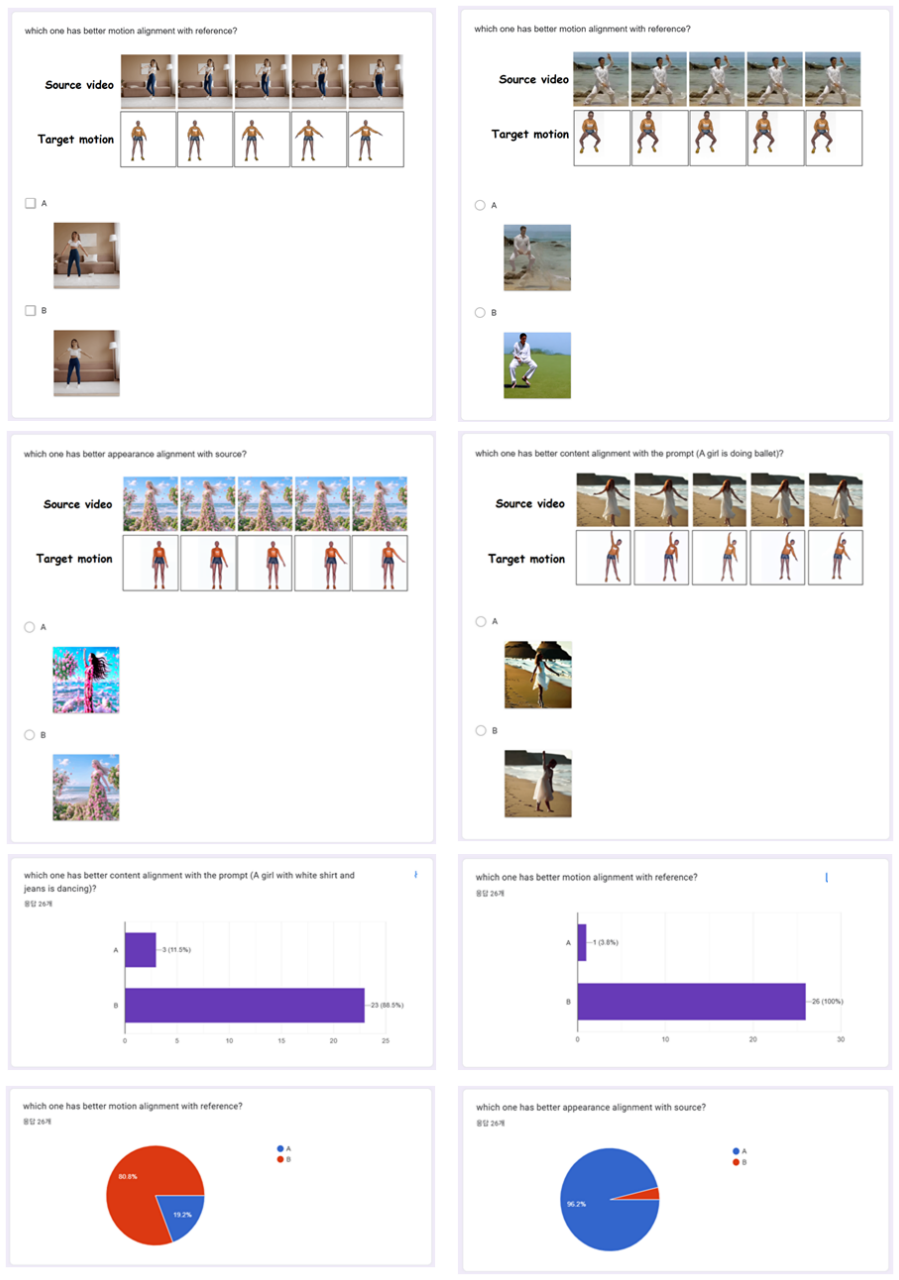
William Harvey, Saeid Naderiparizi, Vaden Masrani, Christian Weilbach, and Frank Wood. Flexible diffusion modeling of long videos.Advances in Neural Information Processing Systems, 35:27953–27965, 2022
2022
-
[4]
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. Fifo-diffusion: Generating infinite videos from text without training.arXiv preprint arXiv:2405.11473, 2024
arXiv 2024
-
[6]
Ccedit: Creative and controllable video editing via diffusion models
Ruoyu Feng, Wenming Weng, Yanhui Wang, Yuhui Yuan, Jianmin Bao, Chong Luo, Zhibo Chen, and Baining Guo. Ccedit: Creative and controllable video editing via diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6712–6722, 2024
2024
-
[8]
Fatezero: Fusing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fusing attentions for zero-shot text-based video editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023
2023
-
[9]
Shuyuan Tu, Qi Dai, Zihao Zhang, Sicheng Xie, Zhi-Qi Cheng, Chong Luo, Xintong Han, Zuxuan Wu, and Yu-Gang Jiang. Motionfollower: Editing video motion via lightweight score-guided diffusion.arXiv preprint arXiv:2405.20325, 2024
arXiv 2024
-
[10]
Diffbody: Diffusion-based pose and shape editing of human images
Yuta Okuyama, Yuki Endo, and Yoshihiro Kanamori. Diffbody: Diffusion-based pose and shape editing of human images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6333–6342, 2024
2024
-
[11]
Zhihong Xu, Dongxia Wang, Peng Du, Yang Cao, and Qing Guo. Truepose: Human-parsing-guided attention diffusion for full-id preserving pose transfer.arXiv preprint arXiv:2502.03426, 2025
arXiv 2025
-
[12]
Deco: Decoupled human-centered diffusion video editing with motion consistency
Xiaojing Zhong, Xinyi Huang, Xiaofeng Yang, Guosheng Lin, and Qingyao Wu. Deco: Decoupled human-centered diffusion video editing with motion consistency. InEuropean Conference on Computer Vision, pages 352–370. Springer, 2024
2024
-
[13]
Motionfollower: Editing video motion via score-guided diffusion
Shuyuan Tu, Qi Dai, Zihao Zhang, Sicheng Xie, Zhi-Qi Cheng, Chong Luo, Xintong Han, Zuxuan Wu, and Yu-Gang Jiang. Motionfollower: Editing video motion via score-guided diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12822–12831, 2025
2025
-
[14]
Motioned- itor: Editing video motion via content-aware diffusion
Shuyuan Tu, Qi Dai, Zhi-Qi Cheng, Han Hu, Xintong Han, Zuxuan Wu, and Yu-Gang Jiang. Motioned- itor: Editing video motion via content-aware diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7882–7891, 2024. 13
2024
-
[16]
Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
2023
-
[17]
Custom 3d avatar.https://www.worldlabs.ai/labs/showcase/custom-3d-avatar,
World Labs. Custom 3d avatar.https://www.worldlabs.ai/labs/showcase/custom-3d-avatar,
-
[18]
Accessed: 2026-06-09
World Labs Community Showcase. Accessed: 2026-06-09
2026
-
[19]
2025.https://hailuoai.video
2025
-
[20]
2025.https://www.pexels.com/ko-kr/
2025
-
[21]
Taichi: A fine-grained action recognition dataset
Shan Sun, Feng Wang, Qi Liang, and Liang He. Taichi: A fine-grained action recognition dataset. InProceedings of the 2017 ACM on International Conference on Multimedia Retrieval, pages 429–433, 2017
2017
-
[22]
Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111, 2024
Wenhao Sun, Rong-Cheng Tu, Jingyi Liao, and Dacheng Tao. Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111, 2024
arXiv 2024
-
[23]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7623–7633, 2023
2023
-
[24]
Towards consistent video editing with text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:58508–58519, 2023
Zicheng Zhang, Bonan Li, Xuecheng Nie, Congying Han, Tiande Guo, and Luoqi Liu. Towards consistent video editing with text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:58508–58519, 2023
2023
-
[25]
Simda: Simple diffusion adapter for efficient video generation
Zhen Xing, Qi Dai, Han Hu, Zuxuan Wu, and Yu-Gang Jiang. Simda: Simple diffusion adapter for efficient video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7827–7839, 2024
2024
-
[26]
Fairy: Fast parallelized instruction-guided video-to-video synthesis
Bichen Wu, Ching-Yao Chuang, Xiaoyan Wang, Yichen Jia, Kapil Krishnakumar, Tong Xiao, Feng Liang, Licheng Yu, and Peter Vajda. Fairy: Fast parallelized instruction-guided video-to-video synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8261– 8270, 2024
2024
-
[27]
Video-p2p: Video editing with cross-attention control
Shaoteng Liu, Yuechen Zhang, Wenbo Li, Zhe Lin, and Jiaya Jia. Video-p2p: Video editing with cross-attention control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8599–8608, 2024
2024
-
[28]
Structure and content-guided video synthesis with diffusion models
Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 7346–7356, 2023
2023
-
[29]
Hyeonho Jeong and Jong Chul Ye. Ground-a-video: Zero-shot grounded video editing using text-to- image diffusion models.arXiv preprint arXiv:2310.01107, 2023
arXiv 2023
-
[30]
Videocomposer: Compositional video synthesis with motion controllability
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. Advances in Neural Information Processing Systems, 36:7594–7611, 2023
2023
-
[31]
Zhihao Hu and Dong Xu. Videocontrolnet: A motion-guided video-to-video translation framework by using diffusion model with controlnet.arXiv preprint arXiv:2307.14073, 2023
arXiv 2023
-
[32]
Motiondirector: Motion customization of text-to-video diffusion models
Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jia-Wei Liu, Weijia Wu, Jussi Keppo, and Mike Zheng Shou. Motiondirector: Motion customization of text-to-video diffusion models. In European Conference on Computer Vision, pages 273–290. Springer, 2024. 14
2024
-
[33]
Dreamix: Video diffusion models are general video editors.arXiv preprint arXiv:2302.01329, 2023
Eyal Molad, Eliahu Horwitz, Dani Valevski, Alex Rav Acha, Yossi Matias, Yael Pritch, Yaniv Leviathan, and Yedid Hoshen. Dreamix: Video diffusion models are general video editors.arXiv preprint arXiv:2302.01329, 2023
arXiv 2023
-
[34]
Save: Protagonist diversification with s tructure a gnostic v ideo e diting
Yeji Song, Wonsik Shin, Junsoo Lee, Jeesoo Kim, and Nojun Kwak. Save: Protagonist diversification with s tructure a gnostic v ideo e diting. InEuropean Conference on Computer Vision, pages 41–57. Springer, 2024
2024
-
[35]
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023
Pith/arXiv arXiv 2023
-
[36]
Yuren Cong, Mengmeng Xu, Christian Simon, Shoufa Chen, Jiawei Ren, Yanping Xie, Juan-Manuel Perez-Rua, Bodo Rosenhahn, Tao Xiang, and Sen He. Flatten: optical flow-guided attention for con- sistent text-to-video editing.arXiv preprint arXiv:2310.05922, 2023
arXiv 2023
-
[37]
Fresco: Spatial-temporal correspondence for zero-shot video translation
Shuai Yang, Yifan Zhou, Ziwei Liu, and Chen Change Loy. Fresco: Spatial-temporal correspondence for zero-shot video translation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8703–8712, 2024
2024
-
[38]
Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, and Qi Tian. Con- trolvideo: Training-free controllable text-to-video generation.arXiv preprint arXiv:2305.13077, 2023
arXiv 2023
-
[39]
Text2video-zero: Text-to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023
2023
-
[40]
Ernie Chu, Shuo-Yen Lin, and Jun-Cheng Chen. Video controlnet: Towards temporally consis- tent synthetic-to-real video translation using conditional image diffusion models.arXiv preprint arXiv:2305.19193, 2023
arXiv 2023
-
[41]
Rave: Random- ized noise shuffling for fast and consistent video editing with diffusion models
Ozgur Kara, Bariscan Kurtkaya, Hidir Yesiltepe, James M Rehg, and Pinar Yanardag. Rave: Random- ized noise shuffling for fast and consistent video editing with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6507–6516, 2024
2024
-
[42]
Person image synthesis via denoising diffusion model
Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Jorma Laaksonen, Mubarak Shah, and Fahad Shahbaz Khan. Person image synthesis via denoising diffusion model. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5968–5976, 2023
2023
-
[43]
Imagpose: A unified conditional framework for pose-guided person generation
Fei Shen and Jinhui Tang. Imagpose: A unified conditional framework for pose-guided person generation. Advances in neural information processing systems, 37:6246–6266, 2024
2024
-
[44]
Dense intrinsic appearance flow for human pose transfer
Yining Li, Chen Huang, and Chen Change Loy. Dense intrinsic appearance flow for human pose transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3693– 3702, 2019
2019
-
[45]
Controllable person image syn- thesis with pose-constrained latent diffusion
Xiao Han, Xiatian Zhu, Jiankang Deng, Yi-Zhe Song, and Tao Xiang. Controllable person image syn- thesis with pose-constrained latent diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22768–22777, 2023
2023
-
[46]
Fei Shen, Hu Ye, Jun Zhang, Cong Wang, Xiao Han, and Wei Yang. Advancing pose-guided image synthesis with progressive conditional diffusion models.arXiv preprint arXiv:2310.06313, 2023
arXiv 2023
-
[47]
Posecrafter: One-shot personalized video synthesis following flexible pose control
Yong Zhong, Min Zhao, Zebin You, Xiaofeng Yu, Changwang Zhang, and Chongxuan Li. Posecrafter: One-shot personalized video synthesis following flexible pose control. InEuropean Conference on Com- puter Vision, pages 243–260. Springer, 2024. 15
2024
-
[48]
Motioned- itor: Editing video motion via content-aware diffusion
Shuyuan Tu, Qi Dai, Zhi-Qi Cheng, Han Hu, Xintong Han, Zuxuan Wu, and Yu-Gang Jiang. Motioned- itor: Editing video motion via content-aware diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7882–7891, 2024
2024
-
[49]
Yi Zuo, Lingling Li, Licheng Jiao, Fang Liu, Xu Liu, Wenping Ma, Shuyuan Yang, and Yuwei Guo. Edit-your-motion: Space-time diffusion decoupling learning for video motion editing.arXiv preprint arXiv:2405.04496, 2024
arXiv 2024
-
[50]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[51]
Inpaint anything: Segment anything meets image inpainting.arXiv preprint arXiv:2304.06790, 2023
Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting.arXiv preprint arXiv:2304.06790, 2023
arXiv 2023
-
[52]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
2023
-
[53]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[54]
springer New York, 1978
Carl De Boor and Carl De Boor.A practical guide to splines, volume 27. springer New York, 1978
1978
-
[55]
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Ying Shan, Xiu Li, and Qifeng Chen. Follow your pose: Pose-guided text-to-video generation using pose-free videos.arXiv preprint arXiv:2304.01186, 2023
arXiv 2023
-
[56]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international conference on computer vision, pages 22560–22570, 2023
2023
-
[57]
Motiondirector: Motion customization of text-to-video diffusion models
Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jia-Wei Liu, Weijia Wu, Jussi Keppo, and Mike Zheng Shou. Motiondirector: Motion customization of text-to-video diffusion models. In European Conference on Computer Vision, pages 273–290. Springer, 2024
2024
-
[58]
2025.https://www.fotor.com/
2025
-
[59]
Openpose: Realtime multi- person 2d pose estimation using part affinity fields.IEEE transactions on pattern analysis and machine intelligence, 43(1):172–186, 2019
Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Openpose: Realtime multi- person 2d pose estimation using part affinity fields.IEEE transactions on pattern analysis and machine intelligence, 43(1):172–186, 2019
2019
-
[60]
2025.https://www.text2motion.ai/
2025
-
[61]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[62]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[63]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 16 A Appendix B Problem Definition We conducted a seri...
2021
-
[64]
Case A represents the video with the blue background, and Case B represents the video with the girl in the white dress
The videos used are not ambiguous and have less information amounts. Case A represents the video with the blue background, and Case B represents the video with the girl in the white dress. 1 and 2 indicate the first and second motion editing for each video from top to bottom. similarity (Level 2), and a large motion gap (Level 2), making it a highly chall...
-
[65]
The videos used have relatively large amounts of information compared to Figure 5, Figure 6, and Figure
-
[66]
The text prompt for the CLIP score is ”A girl is performing ballet”
Case A is the case at the top of the Figure 9, and Case B indicates the two cases below with the same source video. The text prompt for the CLIP score is ”A girl is performing ballet”. 21 Figure 7: Motion editing results with two resolutions, which are (512 x 512) and (256 x 256). The ”Output (1)” is the edited video with a resolution of (512 x 512), wher...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.